Filtragem de conteúdo do Estúdio de IA do Azure
Importante
Alguns dos recursos descritos nesse artigo podem estar disponíveis apenas na versão prévia. Essa versão prévia é fornecida sem um contrato de nível de serviço e não recomendamos isso para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
A IA do Azure Studio inclui um sistema de filtragem de conteúdo que funciona junto com modelos principais e modelos de geração de imagens DALL-E.
Importante
O sistema de filtragem de conteúdo não é aplicado a prompts e conclusões processados pelo modelo Whisper no Serviço OpenAI do Azure. Saiba mais sobre o modelo Whisper no OpenAI do Azure.
Como ele funciona
Esse sistema de filtragem de conteúdo é desenvolvido com IA do Azure Content Safety e funciona executando a entrada imediata e a saída de conclusão por meio de um conjunto de modelos de classificação destinados a detectar e prevenir a saída de conteúdo prejudicial. As variações nas configurações de API e no design do aplicativo podem afetar os preenchimentos e, portanto, o comportamento de filtragem.
Com as implantação de modelo Azure OpenAI, pode utilizar o filtro de conteúdo padrão ou criar o seu próprio filtro de conteúdo (descrito mais tarde). O filtro de conteúdo padrão também está disponível para outros modelos de texto selecionados pela IA do Azure no catálogo de modelos, mas os filtros de conteúdo personalizados ainda não estão disponíveis para esses modelos. Os modelos disponíveis por meio de Modelos como serviço têm a filtragem de conteúdo habilitada por padrão e não podem ser configurados.
Suporte ao idioma
Os modelos de filtragem de conteúdo foram treinados e testados nos seguintes idiomas: inglês, alemão, japonês, espanhol, francês, italiano, português e chinês. Contudo, o serviço pode funcionar em muitos outros idiomas, mas a qualidade poderá variar. Em todos os casos, você deve fazer seus próprios testes para garantir que ele funcione no seu aplicativo.
Crie um filtro de conteúdo
Para qualquer implantação de modelo no Estúdio de IA do Azure, você pode usar diretamente o filtro de conteúdo padrão, mas talvez queira ter mais controle. Por exemplo, você pode tornar um filtro mais estrito ou mais brando ou habilitar recursos mais avançados, como proteções de prompt e detecção de material protegido.
Siga essas etapas para criar um filtro de conteúdo:
Acesse o Estúdio de IA e navegue até o hub. Em seguida, selecione a guia Filtros de conteúdo na navegação esquerda e clique no botão Criar filtro de conteúdo.

Na página Informações básicas, insira um nome para o seu filtro de conteúdo. Selecione uma conexão para associar ao filtro de conteúdo. Em seguida, selecione Avançar.

Na página Filtros de entrada, você pode definir o filtro para o prompt de entrada. Defina a ação e o limite de nível de severidade para cada tipo de filtro. Você configura os filtros padrão e outros (como o Prompt Shields para ataques de jailbreak) nesta página. Em seguida, selecione Avançar.
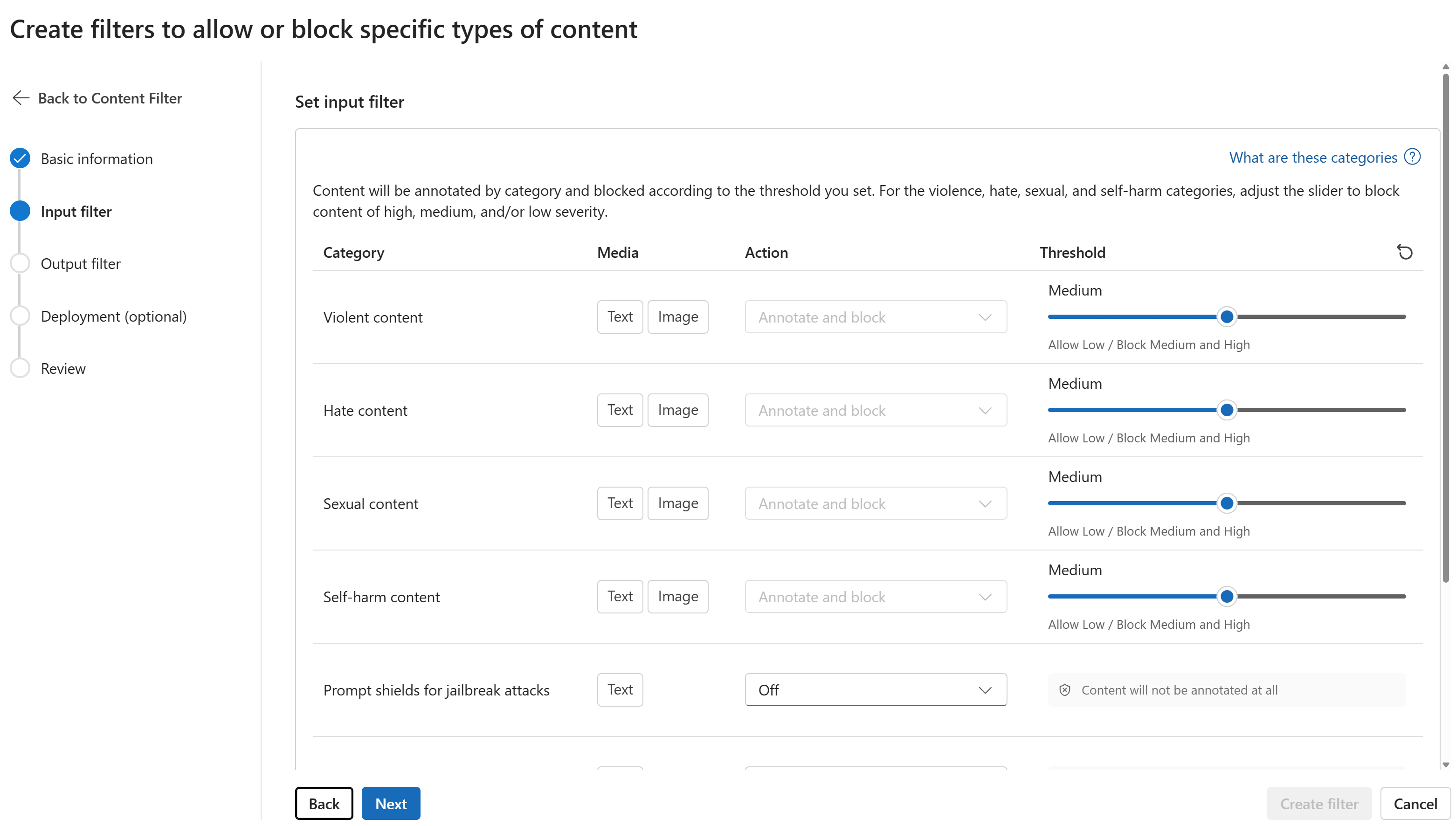
O conteúdo será anotado por categoria e bloqueado de acordo com o limite que você definir. Para as categorias violência, ódio, sexual e automutilação, ajuste o controle deslizante para bloquear conteúdo de gravidade alta, média ou baixa.
Na página Filtros de saída, você pode configurar o filtro de saída, que será aplicado a todo o conteúdo de saída gerado pelo seu modelo. Configure os filtros individuais como antes. Esta página também fornece a opção de modo Streaming, que permite filtrar o conteúdo quase em tempo real conforme ele é gerado pelo modelo, reduzindo a latência. Quando terminar, selecione Avançar.
O conteúdo será anotado por cada categoria e bloqueado de acordo com o limite. Para conteúdo violento, conteúdo de ódio, conteúdo sexual e categoria de conteúdo de automutilação, ajuste o limite para bloquear conteúdo prejudicial com níveis de gravidade iguais ou superiores.
Opcionalmente, na página Implantação, você pode associar o filtro de conteúdo a uma implantação. Se uma implantação selecionada já tiver um filtro anexado, você deverá confirmar se deseja substituí-la. Você também pode associar o filtro de conteúdo a uma implantação posteriormente. Selecione Criar.
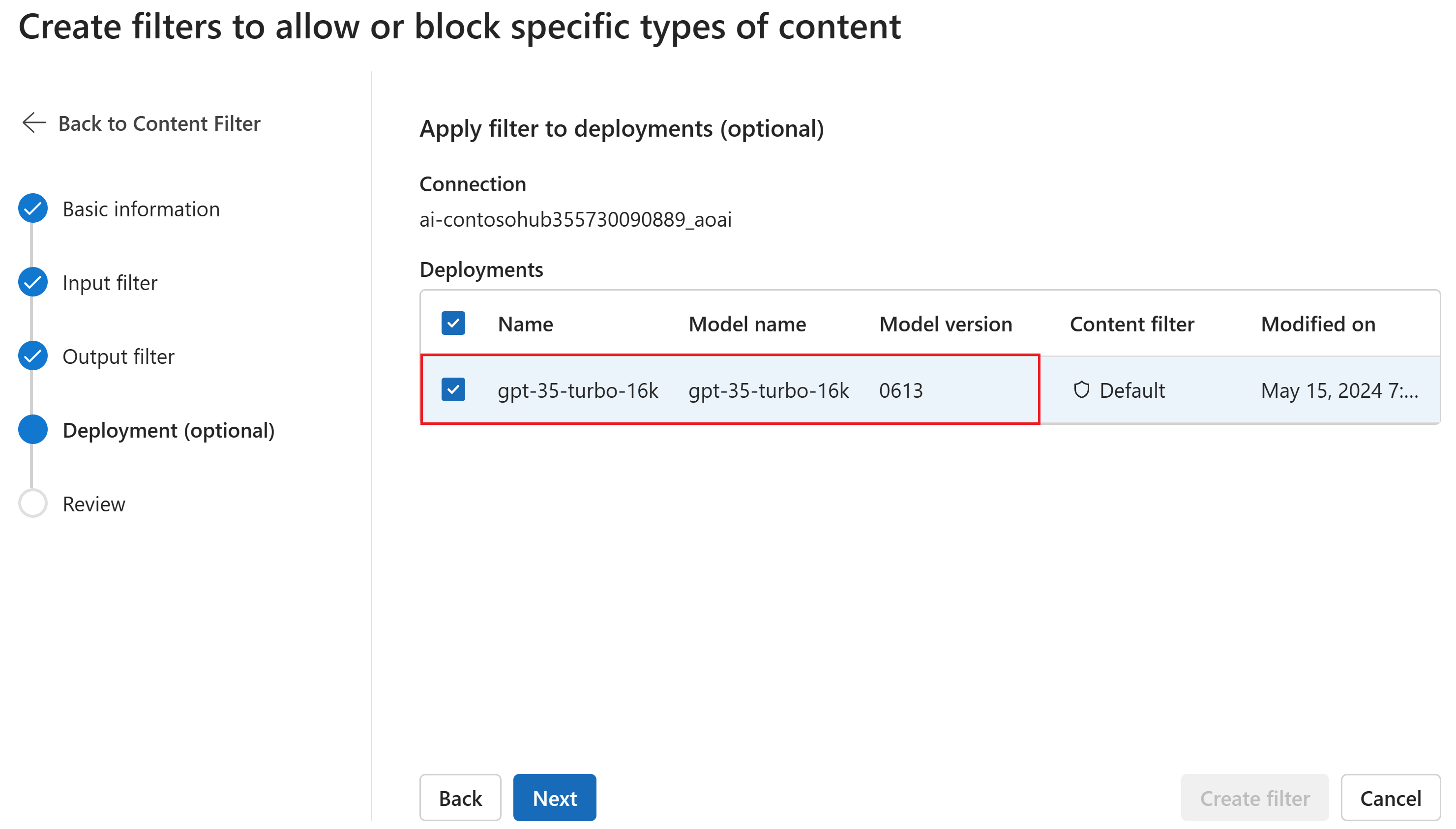
As configurações de filtragem de conteúdo são criadas no nível do hub no AI Studio. Saiba mais sobre configurabilidade nos documentos do Azure OpenAI.
Na página Revisar, revise as configurações e selecione Criar filtro.




Usar uma lista de bloqueados como um filtro
Você pode aplicar uma lista de bloqueios como um filtro de entrada ou de saída ou ambos. Habilite a opção Lista de bloqueio na página Filtro de entrada e/ou Filtro de saída. Selecione uma ou mais listas de bloqueio na lista suspensa ou use a lista de bloqueio interna de palavrões. Você pode combinar várias listas de bloqueio no mesmo filtro.
Aplicar um filtro de conteúdo
O processo de criação de filtro oferece a opção de aplicar o filtro às implantações desejadas. Você também pode alterar ou remover filtros de conteúdo de suas implantações a qualquer momento.
Siga essas etapas para aplicar um filtro de conteúdo a uma implantação:
Vá para AI Studio e selecione um projeto.
Selecione Implantação e escolha uma de suas implantações e selecione Editar.

Na janela Atualizar implantação, selecione o filtro de conteúdo que deseja aplicar à implantação.
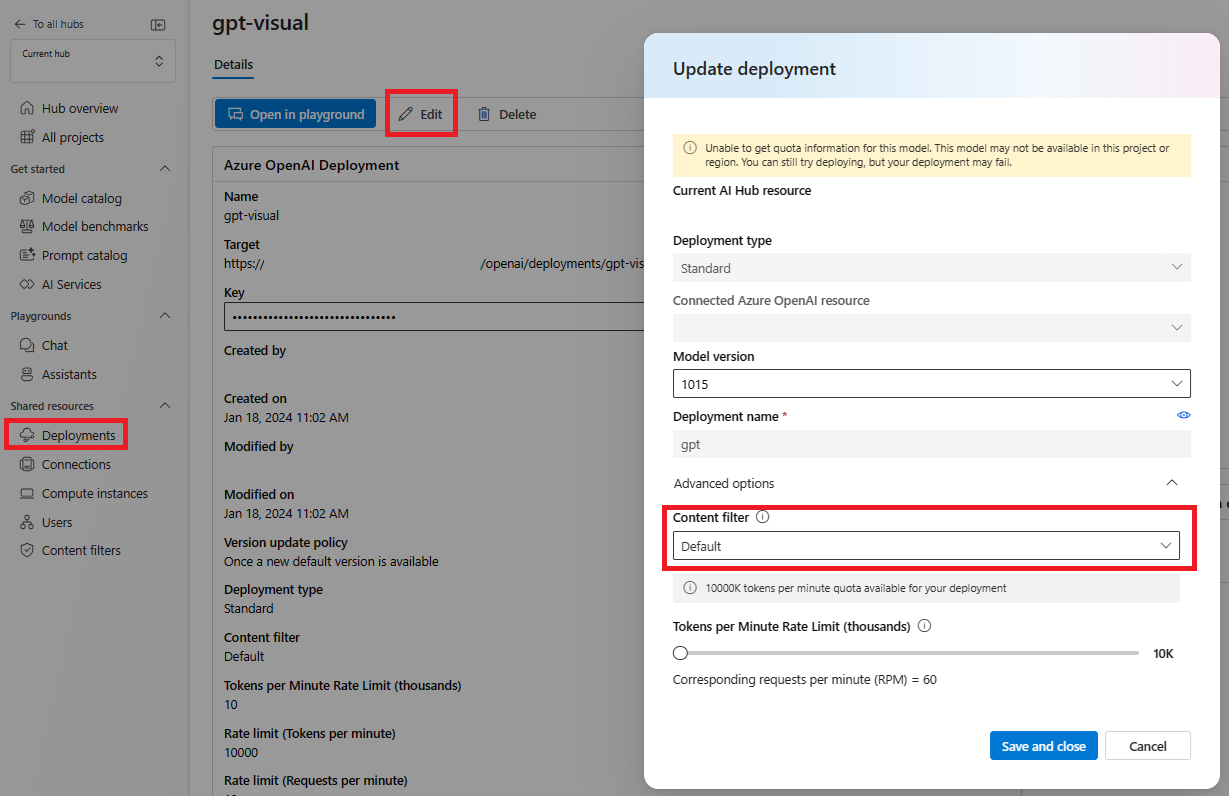


Agora, você pode acessar o playground para testar se o filtro de conteúdo funciona conforme o esperado.
Categorias
| Categoria | Descrição |
|---|---|
| Ódio | A categoria de ódio descreve ataques ou usos de linguagem que incluem linguagem pejorativa ou discriminatória com referência a uma pessoa ou a um grupo de identidade de acordo com certos atributos de diferenciação desses grupos, incluindo, entre outros, raça, etnia, nacionalidade, identidade e expressão de gênero, orientação sexual, religião, status de imigração, status de capacidade, aparência pessoal e tamanho do corpo. |
| Sexual | A categoria sexual descreve linguagem relacionada a órgãos anatômicos e genitais, relacionamentos românticos, atos retratados em termos eróticos ou afetuosos, atos sexuais físicos, incluindo aqueles retratados como uma agressão ou um ato violento sexual forçado contra a vontade de alguém, prostituição, pornografia e abuso. |
| Violência | A categoria de violência descreve linguagem relacionada a ações físicas destinadas a ferir, machucar, danificar ou matar alguém ou algo; descreve armas, etc. |
| Automutilação | A categoria de automutilação descreve linguagem relacionada a ações físicas destinadas a machucar, ferir ou causar danos ao corpo de alguém ou se suicidar. |
Níveis de severidade
| Categoria | Descrição |
|---|---|
| Safe | O conteúdo pode estar relacionado às categorias de violência, automutilação, sexual ou ódio, mas os termos são usados em contextos profissionais gerais, jornalísticos, científicos, médicos e similares, que são apropriados para a maioria dos públicos. |
| Baixo | Conteúdo que expressa opiniões preconceituosas, críticas ou opinativas, inclui o uso de linguagem ofensiva, estereótipos, casos de uso explorando um mundo fictício (por exemplo, jogos e literatura) e representações em baixa intensidade. |
| Médio | Conteúdo que usa linguagem ofensiva, insultante, zombadora, intimidante ou humilhante em relação a grupos de identidade específicos, inclui representações de busca e execução de instruções prejudiciais, fantasias, glorificação e promoção de danos em média intensidade. |
| Alto | Conteúdos que exibem instruções, ações, danos ou abusos perigosos explícitos e graves; incluem endosso, glorificação ou promoção de atos perigosos graves, formas extremas ou ilegais de danos, radicalização ou troca ou abuso de poder não consensual. |
Configurabilidade (versão prévia)
A configuração padrão de filtragem de conteúdo para a série de modelos GPT é definida para filtrar no limite de gravidade médio para todas as quatro categorias de conteúdo prejudicial (ódio, violência, sexual e automutilação) e se aplica a ambos os prompts (texto, texto multimodal/ imagem) e conclusões (texto). Isso significa que o conteúdo detectado no nível de gravidade médio ou alto é filtrado, enquanto o conteúdo detectado no nível de gravidade baixo não é filtrado pelos filtros de conteúdo. Para DALL-E, o limite de gravidade padrão é definido como baixo para prompts (texto) e conclusões (imagens), para que o conteúdo detectado em níveis de gravidade baixo, médio ou alto seja filtrado.
O recurso de configurabilidade permite que os clientes ajustem as configurações, separadamente para prompts e conclusões, para filtrar o conteúdo de cada categoria de conteúdo em diferentes níveis de gravidade, conforme descrito na tabela abaixo:
| Gravidade filtrada | Configurável para prompts | Configurável para conclusões | Descrições |
|---|---|---|---|
| Baixo, médio ou alto | Sim | Sim | Configuração de filtragem mais rigorosa. O conteúdo detectado nos níveis de gravidade baixo, médio e alto é filtrado. |
| Médio, alto | Sim | Yes | O conteúdo detectado no nível de severidade baixo não é filtrado, enquanto o conteúdo nos níveis médio e alto é filtrado. |
| Alto | Sim | Yes | O conteúdo detectado nos níveis de gravidade baixo e médio não será filtrado. Somente o conteúdos com nível de gravidade alto serão filtrados. Exige aprovação1. |
| Nenhum filtro | Se aprovado1 | Se aprovado1 | nenhum conteúdo será filtrado, independentemente do nível de gravidade detectado. Exige aprovação1. |
1 No caso dos modelos do OpenAI do Azure, somente os clientes que foram aprovados para filtragem de conteúdo modificado têm controle completo sobre a filtragem de conteúdo, incluindo a configuração dos filtros de conteúdo apenas no nível de severidade alto ou a desativação dos filtros de conteúdo. Aplique filtros de conteúdo modificados por meio deste formulário: Revisão de Acesso Limitado do OpenAI do Azure: Filtros de Conteúdo Modificados e Monitoramento de Abuso (microsoft.com)
Os clientes são responsáveis por garantir que os aplicativos que integram o OpenAI do Azure estejam em conformidade com o Código de conduta.
Outros filtros de entrada
Você também pode habilitar filtros especiais para cenários de IA generativos:
- Ataques de jailbreak: Os ataques de jailbreak são avisos do usuário projetados para provocar o modelo de IA generativa a exibir comportamentos que foi treinado para evitar ou para quebrar as regras definidas na mensagem do sistema.
- Ataques indiretos: Ataques indiretos, também conhecidos como ataques de prompt indireto ou ataques de injeção de prompt entre domínios, são uma vulnerabilidade potencial onde terceiros colocam instruções maliciosas dentro de documentos que o sistema de IA generativa pode acessar e processar.
Outros filtros de saída
Você também pode habilitar os seguintes filtros de saída especiais:
- Material protegido para texto: O texto do material protegido descreve conteúdo de texto conhecido (por exemplo, letras de músicas, artigos, receitas e conteúdo da web selecionado) que pode ser gerado por grandes modelos de linguagem.
- Material protegido para código: O código de material protegido descreve o código-fonte que corresponde a um conjunto de código-fonte de repositórios públicos, que pode ser gerado por grandes modelos de linguagem sem a devida citação dos repositórios-fonte.
- Aterramento: O filtro de detecção de aterramento detecta se as respostas de texto de grandes modelos de linguagem (LLMs) são fundamentadas nos materiais de origem fornecidos pelos usuários.
Próximas etapas
- Saiba mais sobre os modelos subjacentes que alimentam o OpenAI do Azure.
- A filtragem de conteúdo do Estúdio de IA do Azure é um recurso da plataforma Segurança de Conteúdo de IA do Azure.
- Saiba mais sobre como entender e mitigar riscos associados ao seu aplicativo: Visão geral das práticas de IA responsável para modelos do OpenAI do Azure.