O NLP (processamento de linguagem natural) tem muitos usos: análise de sentimento, detecção de tópicos, detecção de idioma, extração de frases-chave e categorização de documentos.
Especificamente, você pode usar o NLP para:
- Classificar documentos. Por exemplo, você pode rotular documentos como confidenciais ou spam.
- Fazer processamento ou pesquisas subsequentes. Você pode usar a saída NLP para essas finalidades.
- Resumir texto identificando as entidades presentes no documento.
- Marcar documentos com palavras-chave. Para as palavras-chave, o NLP pode usar entidades identificadas.
- Fazer pesquisa e recuperação baseadas em conteúdo. A marcação possibilita essa funcionalidade.
- Resumir os tópicos importantes de um documento. O NLP pode combinar entidades identificadas em tópicos.
- Categorizar documentos para navegação. Para essa finalidade, o NLP usa tópicos detectados.
- Enumerar documentos relacionados com base em um tópico selecionado. Para essa finalidade, o NLP usa tópicos detectados.
- Pontuar texto para sentimento. Usando essa funcionalidade, você pode avaliar o tom positivo ou negativo de um documento.
Apache®, Apache Spark e o logotipo da chama são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. O uso desta marca não implica aprovação por parte da Apache Software Foundation.
Possíveis casos de uso
Os cenários de negócios que podem se beneficiar do NLP personalizado incluem:
- Informação de Documentos para documentos manuscritos ou criados por computador em finanças, saúde, varejo, governo e outros setores.
- Tarefas de NLP independentes do setor para processamento de texto, como NER (reconhecimento de entidade nomeada), classificação, resumo e extração de relação. Essas tarefas automatizam o processo de recuperação, identificação e análise de informações do documento, como texto e dados não estruturados. Exemplos dessas tarefas incluem modelos de estratificação de risco, classificação de ontologia e resumos de varejo.
- Recuperação de informações e criação de grafo de conhecimento para pesquisa semântica. Essa funcionalidade possibilita criar grafos de conhecimento médico que dão suporte à descoberta de medicamentos e ensaios clínicos.
- Tradução de texto para sistemas de IA conversacional em aplicativos voltados para o cliente em varejo, finanças, viagens e outros setores.
Apache Spark como uma estrutura NLP personalizada
O Apache Spark é uma estrutura de processamento paralelo que dá suporte ao processamento na memória para melhorar o desempenho de aplicativos de análise de Big Data. O Azure Synapse Analytics, o Azure HDInsight e o Azure Databricks oferecem acesso ao Spark e aproveitam o poder de processamento dele.
Para cargas de trabalho NLP personalizadas, o Spark NLP serve como uma estrutura eficiente para processar uma grande quantidade de texto. Esta biblioteca NLP de código aberto fornece bibliotecas Python, Java e Scala que oferecem toda a funcionalidade de bibliotecas NLP tradicionais, como spaCy, NLTK, Stanford CoreNLP e Open NLP. O Spark NLP também oferece funcionalidades como verificação ortográfica, análise de sentimento e classificação de documentos. O Spark NLP aprimora os esforços anteriores fornecendo velocidade, escalabilidade e precisão de última geração.
Parâmetros de comparação públicos recentes mostram o Spark NLP como 38 e 80 vezes mais rápido que o spaCy, com precisão comparável para treinamento de modelos personalizados. O Spark NLP é a única biblioteca de código aberto que pode usar um cluster Spark distribuído. O Spark NLP é uma extensão nativa do Spark ML que opera diretamente em quadros de dados. Como resultado, as acelerações em um cluster resultam em outra ordem de magnitude do ganho de desempenho. Como cada pipeline do Spark NLP é um pipeline do Spark ML, o Spark NLP é adequado para a criação de pipelines unificados de NLP e machine learning, como classificação de documentos, previsão de riscos e pipelines de recomendação.
Além do excelente desempenho, o Spark NLP também oferece precisão de última geração para um número cada vez maior de tarefas de NLP. A equipe do Spark NLP lê regularmente os últimos artigos acadêmicos relevantes e implementa modelos de última geração. Nos últimos dois ou três anos, os modelos com melhor desempenho usaram aprendizado profundo. A biblioteca vem com modelos de aprendizado profundo predefinidos para reconhecimento de entidade nomeada, classificação de documentos, detecção de sentimentos e emoções e detecção de sentenças. A biblioteca também inclui dezenas de modelos de linguagem pré-treinados que incluem suporte para inserções de palavras, partes, frases e documentos.
A biblioteca tem builds otimizados para CPUs, GPUs e os chips Intel Xeon mais recentes. Você pode escalar processos de treinamento e inferência para aproveitar os clusters do Spark. Esses processos podem ser executados em produção em todas as plataformas de análise populares.
Desafios
- O processamento de uma coleção de documentos de texto de forma livre requer uma quantidade significativa de recursos computacionais. O processamento também é demorado. Esses processos geralmente envolvem a implantação de computação de GPU.
- Sem um formato de documento padronizado, pode ser difícil obter resultados consistentemente precisos quando se usa o processamento de texto de forma livre para extrair fatos específicos de um documento. Por exemplo, pense em uma representação de texto de uma fatura. Pode ser difícil criar um processo que extraia corretamente o número da fatura e a data em que as faturas são de vários fornecedores.
Principais critérios de seleção
No Azure, serviços do Spark como o Azure Databricks, o Azure Synapse Analytics e o Azure HDInsight fornecem funcionalidade NLP ao usá-los com o Spark NLP. Os serviços de IA do Azure são outra opção para a funcionalidade NLP. Para decidir qual serviço usar, considere estas perguntas:
Deseja usar modelos predefinidos ou pré-treinados? Se sim, considere o uso das APIs oferecidas pelos serviços de IA do Azure. Ou baixe seu modelo de escolha por meio do Spark NLP.
Você precisa treinar modelos personalizados em um corpo grande de dados de texto? Se sim, considere usar o Azure Databricks, o Azure Synapse Analytics ou o Azure HDInsight com o Spark NLP.
Você precisa de funcionalidades de NLP de baixo nível como geração de tokens, lematização e TF/IDF (frequência de termo/frequência de documento inverso)? Se sim, considere usar o Azure Databricks, o Azure Synapse Analytics ou o Azure HDInsight com o Spark NLP. Ou use uma biblioteca de software de código aberto em sua ferramenta de processamento de escolha.
Você precisa de funcionalidades de NLP simples e de alto nível, como identificação de entidade e intenção, detecção de tópico, verificação ortográfica ou análise de sentimento? Se sim, considere o uso das APIs oferecidas pelos serviços de IA do Azure. Ou baixe seu modelo de escolha por meio do Spark NLP.
Matriz de funcionalidades
As tabelas a seguir resumem as principais diferenças nos recursos dos serviços NLP.
Funcionalidades gerais
| Recurso | Serviço Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) com o Spark NLP | Serviços de IA do Azure |
|---|---|---|
| Fornece modelos pré-treinados como serviço | Sim | Yes |
| REST API | Sim | Yes |
| Programação | Python, Scala | Para idiomas com suporte, confira Recursos Adicionais |
| Dá suporte ao processamento de conjuntos de Big Data e documentos grandes | Sim | Não |
Capacidades do NLP de baixo nível
| Capacidade de anotadores | Serviço Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) com o Spark NLP | Serviços de IA do Azure |
|---|---|---|
| Detector de sentenças | Sim | Não |
| Detector de sentenças profundas | Sim | Yes |
| Gerador de token | Sim | Yes |
| Gerador de N-grama | Sim | Não |
| Segmentação de palavras | Sim | Yes |
| Lematizador | Sim | Não |
| Lematizador | Sim | Não |
| Marcação de parte do discurso | Sim | Não |
| Analisador de dependência | Sim | Não |
| Tradução | Sim | Não |
| Limpador de palavras irrelevantes | Sim | Não |
| Correção ortográfica | Sim | Não |
| Normalizer | Sim | Yes |
| Correspondente de texto | Sim | Não |
| TF/IDF | Sim | Não |
| Correspondente de expressão regular | Sim | Inserido no LUIS (Serviço de Reconhecimento Vocal). Não há suporte na CLU (Compreensão da Linguagem Coloquial), que está substituindo o LUIS. |
| Correspondente de data | Sim | Possível no LUIS e na CLU por meio de reconhecedores de DateTime |
| Chunker | Sim | Não |
Capacidades do NLP de alto nível
| Recurso | Serviço Spark (Azure Databricks, Azure Synapse Analytics, Azure HDInsight) com o Spark NLP | Serviços de IA do Azure |
|---|---|---|
| Verificação ortográfica | Sim | Não |
| Resumo | Sim | Yes |
| Respostas às perguntas | Sim | Yes |
| Detecção de sentimento | Sim | Yes |
| Detecção de Emoções | Sim | Dá suporte à mineração de opiniões |
| Classificação de token | Sim | Sim, por meio de modelos personalizados |
| Classificação de texto | Sim | Sim, por meio de modelos personalizados |
| Representação de texto | Sim | Não |
| NER | Sim | Sim. A análise de texto fornece um conjunto de NER e os modelos personalizados estão no reconhecimento de entidade |
| Reconhecimento de entidade | Sim | Sim, por meio de modelos personalizados |
| Detecção de idioma | Sim | Yes |
| Dá suporte a idiomas além do inglês | Sim, dá suporte a mais de 200 idiomas | Sim, dá suporte a mais de 97 idiomas |
Configurar o Spark NLP no Azure
Para instalar o Spark NLP, use o código a seguir, mas substitua <version> pelo número de versão mais recente. Para obter mais informações, confira a documentação do Spark NLP.
# Install Spark NLP from PyPI.
pip install spark-nlp==<version>
# Install Spark NLP from Anacodna or Conda.
conda install -c johnsnowlabs spark-nlp
# Load Spark NLP with Spark Shell.
spark-shell --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with PySpark.
pyspark --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP with Spark Submit.
spark-submit --packages com.johnsnowlabs.nlp:spark-nlp_<version>
# Load Spark NLP as an external JAR after compiling and building Spark NLP by using sbt assembly.
spark-shell --jars spark-nlp-assembly-3 <version>.jar
Desenvolver pipelines NLP
Para a ordem de execução de um pipeline de NLP, o Spark NLP segue o mesmo conceito de desenvolvimento dos modelos de machine learning tradicionais do Spark ML. No entanto, o Spark NLP aplica as técnicas de NLP.
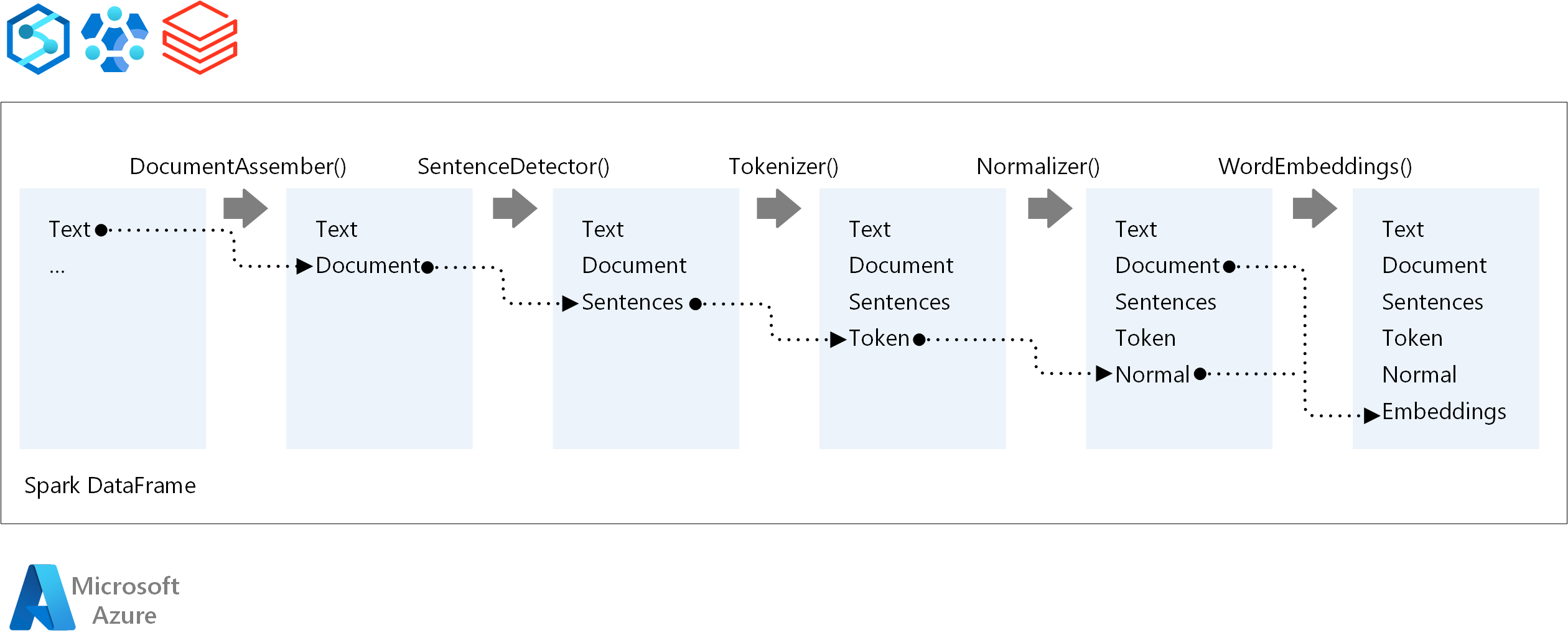
Os principais componentes de um pipeline do Spark NLP são:
DocumentAssembler: um transformador que prepara dados alterando-os em um formato que o Spark NLP pode processar. Essa fase é o ponto de entrada para cada pipeline do Spark NLP. O DocumentAssembler pode ler uma coluna
Stringou umArray[String]. Você pode usarsetCleanupModepara pré-processar o texto. Por padrão, esse modo está desativado.SentenceDetector: um anotador que detecta limites de sentença usando a abordagem fornecida. Esse anotador pode retornar cada frase extraída em um
Array. Ele também pode retornar cada frase em uma linha diferente, se você definirexplodeSentencescomo true.Tokenizer: um anotador que separa o texto bruto em tokens ou unidades como palavras, números e símbolos e retorna os tokens em uma estrutura
TokenizedSentence. Essa classe não é adaptada. Se você ajustar um tokenizer, oRuleFactoryinterno usará a configuração de entrada para configurar regras de token. O tokenizer usa padrões abertos para identificar tokens. Se as configurações padrão não atenderem às suas necessidades, você poderá adicionar regras para personalizar o Tokenizer.Normalizer: um anotador que limpa tokens. O Normalizer requer hastes. O Normalizer usa expressões regulares e um dicionário para transformar texto e remover caracteres sujos.
WordEmbeddings: anotações de pesquisa que mapeiam tokens para vetores. Você pode usar
setStoragePathpara especificar um dicionário de pesquisa de token personalizado para inserções. Cada linha do dicionário precisa conter um token e sua representação de vetor, separados por espaços. Se um token não for encontrado no dicionário, o resultado será um vetor zero da mesma dimensão.
O Spark NLP usa pipelines do Spark MLlib, aos quais o MLflow dá suporte nativo. O MLflow é uma plataforma de código aberto para o ciclo de vida do aprendizado de máquina. Seus componentes incluem:
- Acompanhamento do MLflow: registra experimentos e fornece uma maneira de consultar os resultados.
- Projetos do MLflow: possibilita a execução do código de ciência de dados em qualquer plataforma.
- Modelos do MLflow: implanta modelos em ambientes diversos.
- Registro de Modelo: gerencia modelos armazenados em um repositório central.
O MLflow é integrado ao Azure Databricks. Você pode instalar o MLflow em qualquer outro ambiente baseado em Spark para acompanhar e gerenciar seus experimentos. Você também pode usar o Registro de Modelo do MLflow para disponibilizar modelos para fins de produção.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Principais autores:
- Moritz Steller | Arquiteto Sênior de Soluções de Nuvem
- Zoiner Tejada | CEO e Arquiteto
Próximas etapas
Documentação do Spark NLP:
Componentes do Azure:
Saiba mais sobre os recursos:
Recursos relacionados
- Processamento de linguagem natural personalizado em grande escala no Azure
- Escolher uma tecnologia de serviços de IA do Microsoft Azure
- Comparar os produtos e tecnologias de machine learning da Microsoft
- MLflow e Azure Machine Learning
- Enriquecimento de IA com processamento de imagem e linguagem natural no Azure Cognitive Search
- Analisar news feeds com a análise quase em tempo real usando o processamento de imagem e linguagem natural