Ideias de soluções
Este artigo descreve uma ideia de solução. Seu arquiteto de nuvem pode usar essa orientação para ajudar a visualizar os principais componentes para uma implementação típica dessa arquitetura. Use este artigo como ponto de partida para projetar uma solução bem arquitetada que se alinhe aos requisitos específicos de sua carga de trabalho.
Esse exemplo é sobre como executar um carregamento incremental em um pipeline ELT (extrair-carregar-transformar). Ela usa o Azure Data Factory para automatizar o pipeline ELT. O pipeline move incrementalmente os dados de OLTP mais recentes de um banco de dados do SQL Server local para o Azure Synapse. Os dados transacionais são transformados em um modelo de tabela para análise.
Arquitetura

Baixe um Arquivo Visio dessa arquitetura.
Essa arquitetura é compilada naquela mostrada em Enterprise BI com o Azure Synapse, mas também adiciona alguns recursos que são importantes para cenários de data warehouse de dados da empresa.
- Automação do pipeline usando o Data Factory.
- Carregamento incremental.
- Integrando várias fontes de dados.
- Carregando dados binários como imagens e dados geoespaciais.
Workflow
A arquitetura consiste nos seguintes serviços e componentes.
Fontes de dados
SQL Server local. A fonte de dados está localizada em um banco de dados SQL Server local. Para simular o ambiente local. O banco de dados de exemplo de OLTP de World Wide Importers é usado como o banco de dados de origem.
Dados externos. Um cenário comum para data warehouses é integrar várias fontes de dados. Essa arquitetura de referência carrega um conjunto de dados externos que contém as populações de cidade por ano e integra-se aos dados do banco de dados OLTP. Você pode usar esses dados para insights, como: “O crescimento das vendas em cada região corresponde ou excede o crescimento demográfico?”
Ingestão e armazenamento de dados
Armazenamento de Blobs. O armazenamento de blobs é usado como uma área de preparo dos dados de origem antes de carregá-los no Azure Synapse.
Azure Synapse. O Azure Synapse é um sistema distribuído projetado para executar análises em dados grandes. Ele dá suporte a MPP (processamento altamente paralelo), que o torna adequado para executar análise de alto desempenho.
Azure Data Factory. O Data Factory é um serviço gerenciado que orquestra e automatiza a movimentação e a transformação de dados. Nessa arquitetura, ele coordena os diversos estágios do processo de ELT.
Análise e relatórios
Azure Analysis Services. O Analysis Services é um serviço totalmente gerenciado que fornece recursos de modelagem de dados. O modelo semântico é carregado no Analysis Services.
Power BI. O Power BI é um conjunto de ferramentas de análise de negócios para analisar dados a fim de obter informações comerciais. Nessa arquitetura, ele consulta o modelo semântico armazenado no Analysis Services.
Autenticação
A ID do Microsoft Entra autentica os usuários que se conectam ao servidor do Analysis Services pelo Power BI.
O Data Factory também pode usar o Microsoft Entra ID para autenticação no Azure Synapse por meio de uma entidade de serviço ou uma MSI (Identidade de Serviço Gerenciada).
Componentes
- Armazenamento de Blobs do Azure
- Azure Synapse Analytics
- Fábrica de dados do Azure
- Azure Analysis Services
- Power BI
- Microsoft Entra ID
Detalhes do cenário
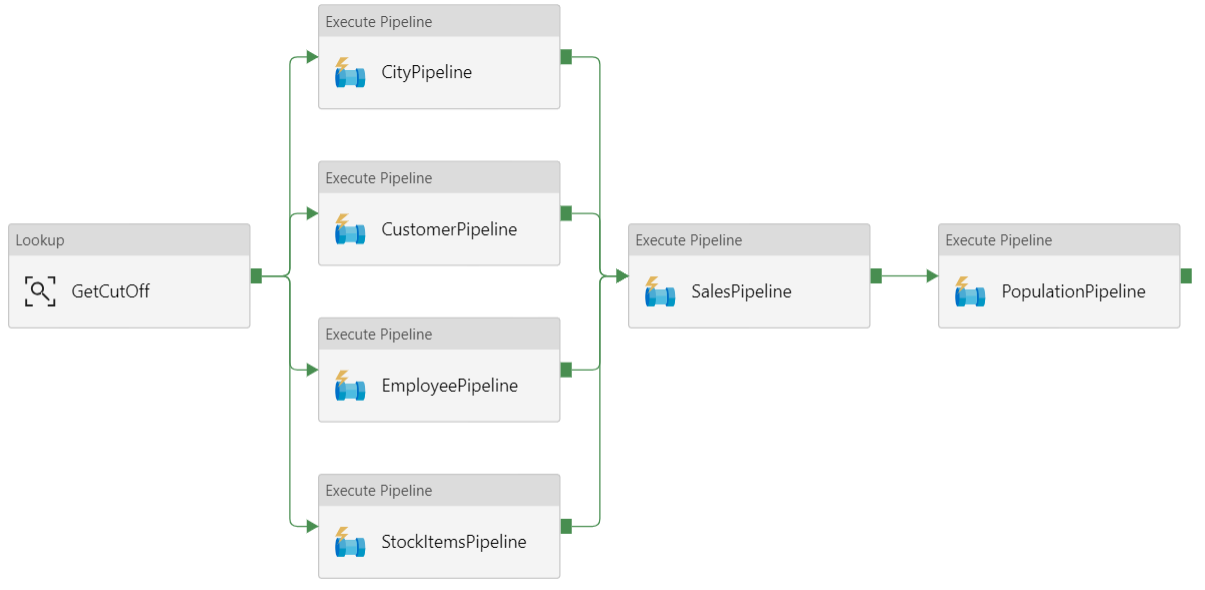
Pipeline de dados
No Azure Data Factory, um pipeline é um agrupamento lógico de atividades usadas para coordenar uma tarefa — nesse caso, carregando e transformando dados no Azure Synapse.
Essa arquitetura de referência define um pipeline pai que executa uma sequência de pipelines filho. Cada pipeline filho carrega dados em uma ou mais tabelas do data warehouse.
Recomendações
Carregamento incremental
Quando você executa um processo automatizado de ETL ou ELT, é mais eficiente carregar apenas os dados alterados desde a execução anterior. Isso é chamado de carregamento incremental em vez de um carregamento completo que carrega todos os dados. Para executar um carregamento incremental, você precisa de uma maneira de identificar quais dados foram alterados. A abordagem mais comum é usar um valor alto de marca d'água, o que significa acompanhar o valor mais recente de alguma coluna na tabela de origem, uma coluna de data e hora ou uma coluna de inteiro exclusivo.
Começando com o SQL Server 2016, você pode usar tabelas temporais. Tratam-se de tabelas com versão do sistema que mantêm um histórico completo das alterações de dados. O mecanismo de banco de dados registra automaticamente o histórico de todas as alterações em uma tabela de histórico separada. Você pode consultar os dados históricos com a adição de uma cláusula FOR SYSTEM_TIME para uma consulta. Internamente, o mecanismo de banco de dados consulta a tabela do histórico, mas isso é transparente ao aplicativo.
Observação
Para versões anteriores do SQL Server, você pode usar a CDC (Captura de Dados de Alterações). Essa abordagem é menos conveniente do que as tabelas temporais porque você tem de consultar uma tabela separada, e as alterações são controladas por um número de sequência de log em vez de um carimbo de data/hora.
Tabelas temporais são úteis para dados de dimensão, os quais podem ser alterados ao longo do tempo. Tabelas de fatos geralmente representam uma transação imutável, como uma venda, caso em que não faz sentido manter o histórico de versão do sistema. Em vez disso, as transações normalmente contam com uma coluna que representa a data da transação, que pode ser usada como o valor de marca d'água. Por exemplo, no banco de dados OLTP da Wide World Importers, as tabelas Sales.Invoices e Sales.InvoiceLines têm um campo LastEditedWhen que é padrão para sysdatetime().
Aqui está o fluxo geral para o pipeline ELT:
Para cada tabela no banco de dados de origem, acompanhe o tempo de corte quando o último trabalho ELT foi executado. Armazene essas informações no data warehouse. (Durante a instalação inicial, todas as horas são definidas como '1-1-1900'.)
Durante a etapa de exportação de dados, a hora de corte é passada como um parâmetro para um conjunto de procedimentos armazenados no banco de dados de origem. Esses procedimentos armazenados consultam todos os registros que foram alterados ou criados após a hora de corte. Para a tabela de fatos de Vendas, é usada a coluna
LastEditedWhen. Para os dados de dimensão, são usadas tabelas temporais com versão do sistema.Quando a migração de dados for concluída, atualize a tabela que armazena os tempos de corte.
Também é útil registrar uma linhagem para cada execução de ELT. Para um determinado registro, a linhagem associa esse registro com a execução de ELT que produziu os dados. Para cada execução de ETL, um novo registro de linhagem é criado para cada tabela, mostrando os tempos de carregamento iniciais e finais. As chaves de linhagem para cada registro são armazenadas nas tabelas de dimensões e de fatos.
Depois que um novo lote de dados for carregado no warehouse, atualize o modelo de tabela do Analysis Services. Consulte Atualização assíncrona com a API REST.
Limpeza de dados
A limpeza de dados deve ser parte do processo de ELT. Nessa arquitetura de referência, uma fonte de dados incorretos é a tabela de população da cidade, em que algumas cidades apresentam zero população, talvez porque nenhum dado estivesse disponível. Durante o processamento, o pipeline ELT remove essas cidades da tabela de população da cidade. Execute a limpeza de dados em tabelas de preparo em vez de tabelas externas.
Fontes de dados externas
Os data warehouses geralmente consolidam dados de várias fontes. Por exemplo, uma fonte de dados externa que contém dados demográficos. Esse conjunto de dados está disponível no armazenamento de blobs do Azure como parte do exemplo WorldWideImportersDW.
O Azure Data Factory pode copiar diretamente do armazenamento de blob usando o conector do armazenamento de blobs. No entanto, o conector requer uma cadeia de conexão ou uma assinatura de acesso compartilhado para que não possa ser usado para copiar um blob com acesso de leitura público. Como alternativa, você pode usar o PolyBase para criar uma tabela externa no armazenamento de blobs e depois copiar as tabelas externas para o Azure Synapse.
Manipulação de dados binários grandes
Por exemplo, no banco de dados de origem, uma tabela Cidade possui uma coluna Local que contém um tipo de dados espaciais de geografia. O Azure Synapse não dá suporte ao tipo geografia nativamente, portanto, esse campo é convertido em um tipo varbinary durante o carregamento. (Consulte Soluções alternativas para tipos de dados sem suporte.)
No entanto, o PolyBase dá suporte a um tamanho máximo de coluna de varbinary(8000), que significa que alguns dados podem ser truncados. Uma solução alternativa para esse problema é dividir os dados em partes durante a exportação e remontar as partes, da seguinte maneira:
Crie uma tabela de preparo temporária para a coluna Local.
Para cada cidade, divida os dados de localização em partes de 8000 bytes, resultando em 1 – N linhas para cada cidade.
Para remontar as partes, use o operador T-SQL PIVOT para converter linhas em colunas e depois concatenar os valores de coluna para cada cidade.
O desafio é que cada cidade será dividida em um número diferente de linhas, dependendo do tamanho dos dados de geografia. Para que o operador PIVOT funcione, cada cidade deve ter o mesmo número de linhas. Para isso funcionar, a consulta T-SQL realiza alguns truques para preencher as linhas com valores em branco, de modo que cada cidade tenha o mesmo número de colunas após a dinamização. A consulta resultante acaba sendo muito mais rápida do que executar o loop pelas linhas uma por vez.
A mesma abordagem é usada para dados de imagem.
Dimensões de alteração lenta
Dados de dimensão são relativamente estáticos, mas isso pode mudar. Por exemplo, um produto pode ser reatribuído a uma categoria de produto diferente. Há várias abordagens para o tratamento de dimensões de alteração lenta. Uma técnica comum, chamada Tipo 2, é adicionar um novo registro sempre que uma dimensão for alterada.
Para implementar a abordagem Tipo 2, as tabelas de dimensões precisam de colunas adicionais que especifiquem o intervalo de datas efetivas para um determinado registro. Além disso, as chaves primárias do banco de dados de origem serão duplicadas, portanto, a tabela de dimensão deve ter uma chave primária artificial.
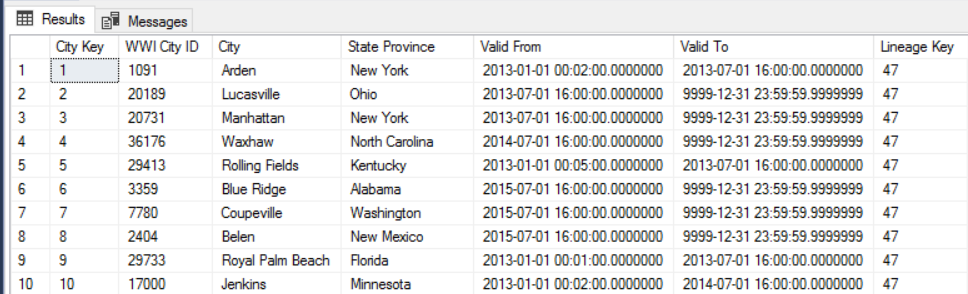
Por exemplo, a imagem a seguir mostra a tabela Dimension.City. A coluna WWI City ID é a chave primária do banco de dados de origem. A coluna City Key é uma chave artificial gerada durante o pipeline ETL. Além disso, observe que a tabela tem as colunas Valid From e Valid To, que definem o intervalo de quando cada linha era válida. Os valores atuais têm um Valid To igual a “9999-12-31”.
A vantagem dessa abordagem é que ela preserva os dados históricos, que podem ser valiosos para análise. No entanto, também significa que haverá várias linhas para a mesma entidade. Por exemplo, aqui estão os registros que correspondem a WWI City ID = 28561:
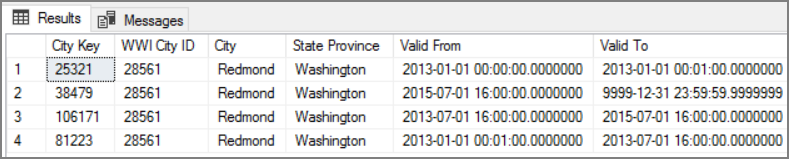
Para cada fato de Vendas, você associa o fato a uma única linha na tabela de dimensões Cidade, correspondente à data da nota fiscal.
Considerações
Estas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios de orientação que podem ser usados para aprimorar a qualidade de uma carga de trabalho. Para obter mais informações, confira Microsoft Azure Well-Architected Framework.
Segurança
A segurança fornece garantias contra ataques deliberados e o abuso de seus dados e sistemas valiosos. Para obter mais informações, consulte Lista de verificação de revisão de design parade segurança.
Para obter mais segurança, você pode usar pontos de extremidade de serviço de rede Virtual para proteger os recursos de serviço do Azure apenas na sua rede virtual. Isso remove totalmente o acesso público via Internet a esses recursos, permitindo o tráfego somente da sua rede virtual.
Com essa abordagem, você cria uma VNet no Azure e, em seguida, cria pontos de extremidade de serviço privados para serviços do Azure. Esses serviços são então restringidos ao tráfego de rede virtual. Você também pode alcançá-los a partir da sua rede local por meio de um gateway.
Esteja ciente das seguintes limitações:
Se os pontos de extremidade de serviço estão habilitados para o Armazenamento do Azure, o PolyBase não pode copiar dados do armazenamento no Azure Synapse. Há uma mitigação para esse problema. Para obter mais informações, consulte Impacto de usar pontos de extremidade de serviço de VNet com Armazenamento do Azure.
Para mover dados do local para o Armazenamento do Azure, você precisará permitir endereços IP públicos do seu local ou ExpressRoute. Para obter detalhes, consulte Protegendo serviços do Azure em redes virtuais.
Para habilitar o Analysis Services a ler dados do Azure Synapse, implante uma VM do Windows para a rede virtual que contém o ponto de extremidade de serviço do Azure Synapse. Instale Gateway de Dados Local do Azure nessa VM. Depois conecte seu serviço do Azure Analysis para o gateway de dados.
Otimização de custos
A Otimização de Custos trata-se de procurar maneiras de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Lista de verificação de revisão de design parade Otimização de Custos.
Use a Calculadora de Preços do Azure para estimar os custos. Confira algumas considerações sobre os serviços usados nesta arquitetura de referência.
Fábrica de dados do Azure
O Azure Data Factory automatiza o pipeline ELT. O pipeline move os dados de um banco de dados do SQL Server local para o Azure Synapse. Os dados são então transformados em um modelo de tabela para análise. Para esse cenário, o preço começa em US$ 0,001 por execuções de atividade por mês, o que inclui execuções de atividade, gatilho e depuração. Esse preço é a taxa base somente para orquestração. Você também é cobrado por atividades de execução, como cópia de dados, pesquisa e atividades externas. Cada atividade tem um preço individual. Além disso, você é cobrado por pipelines sem gatilhos ou execuções associadas dentro do mês. Todas as atividades são distribuídas proporcionalmente por minuto e arredondadas para cima.
Exemplo de análise de custo
Considere um caso de uso em que há duas atividades de pesquisa de duas origens diferentes. Uma leva 1 minuto e 2 segundos (arredondados até 2 minutos) e a outra leva 1 minuto, resultando em tempo total de 3 minutos. Uma atividade de cópia de dados leva 10 minutos. Uma atividade de procedimento armazenado leva 2 minutos. A atividade total é executada por 4 minutos. O custo é calculado da seguinte maneira:
Execuções de atividade: 4 * US$ 0,001 = US$ 0,004
Pesquisas: 3 * (US$ 0,005/60) = US$ 0,00025
Procedimento armazenado: 2 * (US$ 0,00025/60) = US$ 0,000008
Cópia de dados: 10 * (US$ 0,25/60) * 4 DIU (unidade de integração de dados) = US$ 0,167
- Custo total por execução de pipeline: US$ 0,17.
- Executar uma vez por dia por 30 dias: US$ 5,1 por mês.
- Executar uma vez por dia por 100 tabelas por 30 dias: US$ 510
Cada atividade tem um custo associado. Entenda o modelo de preços e use a calculadora de preços do ADF para obter uma solução otimizada não apenas para desempenho, mas também para custo. Gerencie seus custos iniciando, parando, pausando e dimensionando seus serviços.
Azure Synapse
O Azure Synapse é ideal para cargas de trabalho intensivas, com maior desempenho de consulta e necessidades de escalabilidade de computação. Você pode escolher o modelo pago conforme o uso ou usar planos reservados de um ano (economia de 37%) ou 3 anos (economia de 65%).
O armazenamento de dados é cobrado separadamente. Outros serviços, como recuperação de desastre e detecção de ameaças, também são cobrados separadamente.
Para obter mais informações, confira Preços do Azure Synapse.
Analysis Services
O preço do Azure Analysis Services depende da camada. A implementação de referência dessa arquitetura usa a camada Desenvolvedor, que é recomendada para cenários de avaliação, desenvolvimento e teste. Outras camadas incluem a camada Básica, que é recomendada para um ambiente de produção pequeno, e a camada Standard, para aplicativos de produção críticos. Para obter mais informações, confira A camada certa quando você precisa dela.
Nenhuma cobrança se aplica quando você pausa a instância.
Para mais informações, consulte Preços do Azure Analysis Services.
Armazenamento de Blobs
Considere usar o recurso de capacidade reservada do Armazenamento do Microsoft Azure para reduzir o custo do armazenamento. Com esse modelo, você receberá um desconto se puder se comprometer com a reserva para a capacidade de armazenamento fixa por um ou três anos. Para obter mais informações, confira Otimizar custos do Armazenamento de Blobs com capacidade reservada.
Para obter mais informações, confira a seção de custo em Microsoft Azure Well-Architected Framework.
Excelência Operacional
A Excelência Operacional abrange os processos de operações que implantam um aplicativo e o mantêm em execução em produção. Para obter mais informações, consulte Lista de verificação de revisão de design parade Excelência Operacional.
Crie grupos de recursos separados para ambientes de produção, desenvolvimento e teste. Ter grupos de recursos separados facilita o gerenciamento de implantações, a exclusão de implantações de teste a atribuição de direitos de acesso.
Coloque cada carga de trabalho em um modelo de implantação separado e armazene os recursos em sistemas de controle do código-fonte. É possível implantar os modelos juntos ou individualmente como parte de um processo de CI/CD, facilitando o processo de automação.
Nesta arquitetura, há três cargas de trabalho principais:
- O servidor de data warehouse, o Analysis Services e os recursos relacionados.
- Azure Data Factory.
- Um cenário simulado do local para a nuvem.
Cada tipo de instância tem um modelo de implantação próprio.
O servidor de data warehouse é configurado usando comandos da CLI do Azure que seguem a abordagem imperativa da prática de IaC. Considere usar scripts de implantação e integrá-los no processo de automação.
Considere preparar suas cargas de trabalho. Implante em várias fases e execute verificações de validação em cada uma antes de passar para a próxima. Desse modo, é possível efetuar push de atualizações para ambientes de produção de maneira altamente controlada, além de minimizar problemas de implantação inesperados. Use as estratégias de implantação azul-verde e as versões Canary para atualizar ambientes de produção dinâmicos.
Tenha uma boa estratégia de reversão para lidar com implantações com falha. Por exemplo, é possível reimplantar automaticamente uma implantação anterior bem-sucedida com base em seu histórico de implantações. Confira o parâmetro --rollback-on-error flag na CLI do Azure.
O Azure Monitor é a opção recomendada para analisar o desempenho do data warehouse e de toda a plataforma de análise do Azure para uma experiência de monitoramento integrada. O Azure Synapse Analytics oferece uma experiência de monitoramento no portal do Azure para mostrar insights sobre a carga de trabalho do data warehouse. O portal do Azure é a ferramenta recomendada ao monitorar seu data warehouse, pois ele fornece períodos de retenção configuráveis, alertas, recomendações e gráficos e painéis personalizáveis para métricas e logs.
Próximas etapas
- Introdução ao Azure Synapse Analytics
- Introdução ao Azure Synapse Analytics
- Introdução ao Azure Data Factory
- O que é o Azure Data Factory?
- Tutoriais do Azure Data Factory
Recursos relacionados
O ideal é examinar os seguintes cenários de exemplo do Azure, que demonstram soluções específicas usando algumas das mesmas tecnologias: