Usar o Resource Health para solucionar problemas de conectividade da Instância Gerenciada de SQL do Azure
Aplica-se a: ![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
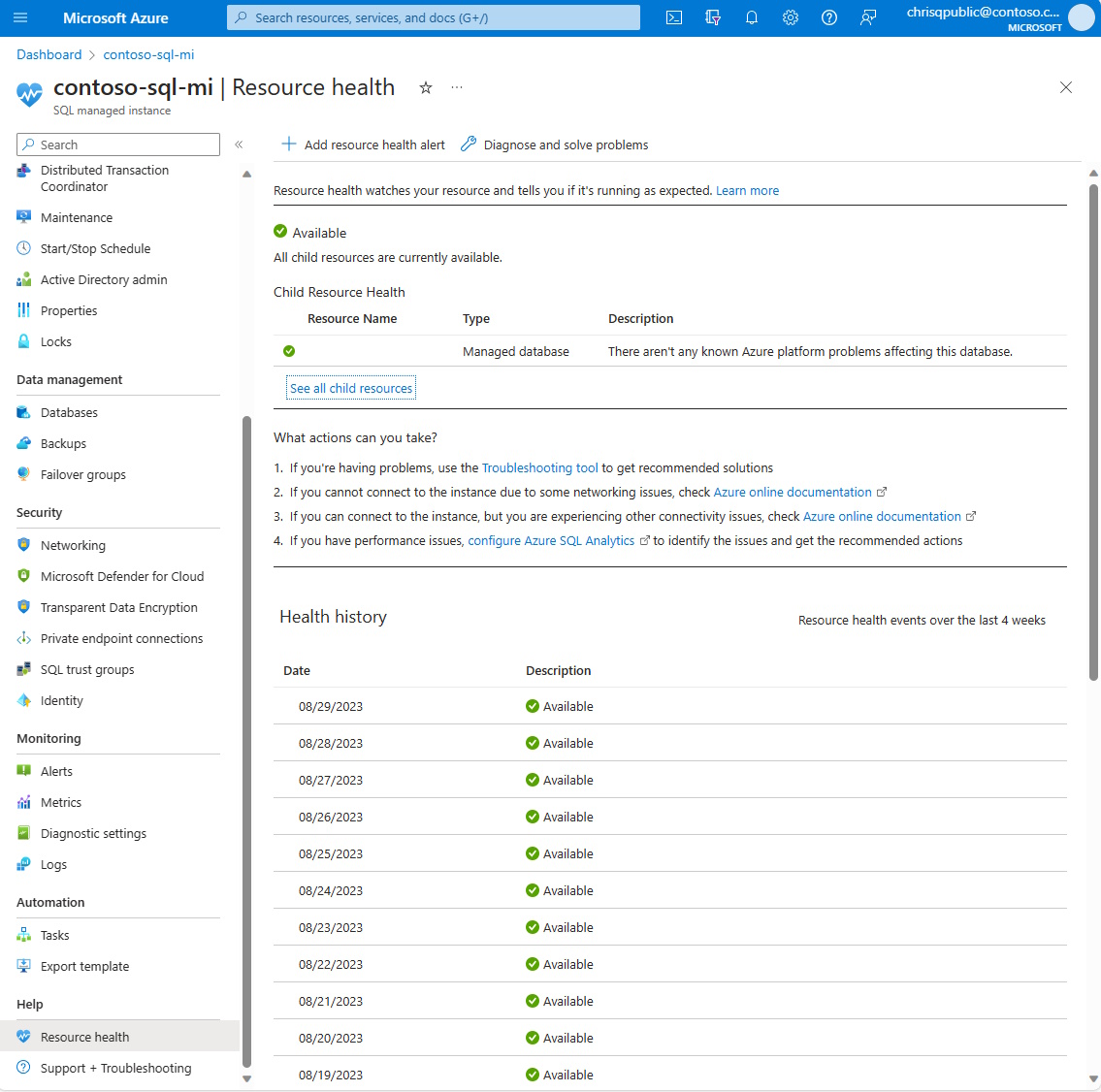
O Resource Health para a Instância Gerenciada de SQL do Azure, ajuda a diagnosticar e obter suporte quando um problema do Azure afeta seus recursos. Ele informa sobre a integridade atual e anterior de seus recursos e ajuda a reduzir os problemas. A página Resource health fornece suporte técnico quando você precisa de ajuda com problemas de serviço do Azure.
Verificações de integridade
O Resource health determina a integridade da sua Instância Gerenciada de SQL examinando o êxito e a falha de logons no recurso. Atualmente, o Resource health para sua Instância Gerenciada de SQL examina somente falhas de logon devido a erro do sistema e não erro do usuário. O status da integridade é atualizado a cada 1 ou 2 minutos.
Estados de integridade
Disponível
Um status Disponível significa que o Resource Health não detectou falhas de logon devido a erros do sistema na sua Instância Gerenciada de SQL.
Degradado
Um status Degradado significa que o Resource health detectou a maioria dos logons bem-sucedidos, mas também algumas falhas. Esses são erros de logon transitório mais prováveis. Para reduzir o impacto de problemas de conexão causados por erros de login temporários, implemente lógica de nova tentativa em seu código.
Indisponível
Um status não disponível significa que o Resource health detectou falhas de logon consistentes na sua Instância Gerenciada de SQL. Se o recurso permanecer nesse estado por um período prolongado, entre em contato com o suporte.
Unknown
O status da integridade Desconhecido indica que o Resource health não recebeu informações sobre esse recurso por mais de 10 minutos. Embora esse status não seja uma indicação definitiva sobre o estado do recurso, é um ponto de dados importante no processo de solução de problemas. Se o seu recurso permanecer nesse estado por um período prolongado, entre em contato com o suporte. Se você está tendo problemas com o recurso, o status de integridade Desconhecido pode sugerir que um evento na plataforma está afetando o recurso.
Informações de histórico
Você pode acessar até 30 dias de histórico de saúde na seção Histórico de saúde do Resource health. A seção também conterá o motivo (quando disponível) para os tempos de inatividade. Atualmente, o Azure mostra o tempo de inatividade do seu recurso em uma granularidade de dois minutos. Provavelmente, o tempo real de inatividade é inferior a um minuto. A média é de 8 segundos.
Motivos de tempo de inatividade
Quando sua Instância Gerenciada de SQL sofre um tempo de inatividade, a análise é executada para determinar um motivo. Quando disponível, o motivo do tempo de inatividade é relatado na seção Histórico de saúde do Resource health. Razões de tempo de inatividade são normalmente publicadas 45 minutos após um evento.
Selecionar uma janela de manutenção
Você pode configurar sua janela de manutenção para tornar eventos de manutenção impactantes previsíveis e menos prejudiciais para sua carga de trabalho. O recurso de janela de manutenção ajuda você a planejar atualizações previsíveis ou manutenção agendada. As notificações antecipadas estão disponíveis para todas as Instâncias Gerenciadas de SQL. As notificações antecipadas permitem que os clientes configurem notificações para serem enviadas até 24 horas antes de qualquer evento planejado.
Manutenção planejada
A infraestrutura do Azure executa periodicamente a manutenção planejada – atualização de componentes de hardware ou software no datacenter. Enquanto o banco de dados passa por manutenção, o SQL do Azure pode terminar algumas conexões existentes e recusar novas. As falhas de logon ocorridas durante a manutenção planejada normalmente são transitórias e a lógica de nova tentativa para erros ocasionais de rede ajuda a reduzir o impacto. Se você continuar a experimentar erros de logon, contate o suporte.
Reconfiguração
As reconfigurações são consideradas condições transitórias e são esperadas de tempos em tempos. Esses eventos podem ser acionados por balanceamento de carga ou falhas de software/hardware. Qualquer aplicação de produção de cliente que se conecta a um banco de dados em nuvem deve implementar uma lógica de nova tentativa para erros transitórios com conexão robusta, pois isso ajudaria a mitigar essas situações e, geralmente, tornaria os erros transparentes para o usuário final.
Próximas etapas
- Saiba mais sobre nova lógica para erros transitórios.
- Solucionar problemas, diagnosticar e evitar erros de conexão do SQL.
- Saiba mais sobre configuração de alertas do Resource Health.
- Obtenha uma visão geral do Resource Health.
- Revisão de Perguntas frequentes sobre o Azure Resource Health.
- Configure uma janela de manutenção e notificações antecipadas.