Dicas de desempenho para o SDK do Java v4 do Azure Cosmos DB
APLICA-SE A: ![]() NoSQL
NoSQL
Importante
As dicas de desempenho neste artigo são apenas para o SDK do Java v4 do Azure Cosmos DB. Confira as Notas sobre a versão do SDK do Java v4 do Azure Cosmos DB, o repositório do Maven, o Guia de solução de problemas do SDK do Java v4 do Azure Cosmos DB para saber mais. Se você estiver usando uma versão mais antiga do que a v4, confira o guia Migrar para o SDK do Java v4 do Azure Cosmos DB para obter ajuda na atualização para a v4.
O Azure Cosmos DB é um banco de dados distribuído rápido e flexível que pode ser dimensionado perfeitamente com garantia de latência e produtividade. Você não precisa fazer grandes alterações de arquitetura nem escrever códigos complexos para dimensionar seu banco de dados com o Azure Cosmos DB. Aumentar e reduzir é tão fácil quanto fazer uma única chamada à API ou uma chamada ao método do SDK. No entanto, como o Azure Cosmos DB é acessado por meio de chamadas de rede, há otimizações do lado do cliente que você pode fazer para obter o desempenho máximo ao usar o SDK do Java v4 do Azure Cosmos DB.
Assim, se você estiver se perguntando "Como posso melhorar o desempenho do meu banco de dados?", considere as seguintes opções:
Rede
Coloque os clientes na mesma região do Azure para aumentar o desempenho
Quando possível, coloque aplicativos que chamam o Azure Cosmos DB na mesma região do banco de dados do Azure Cosmos DB. Para obter uma comparação aproximada, as chamadas para o Azure Cosmos DB na mesma região são concluídas de 1 a 2 ms, mas a latência entre a Costa Leste e a Oeste dos EUA é maior que >50 ms. Provavelmente, essa latência pode variar entre as solicitações dependendo da rota seguida pela solicitação conforme ela passa do cliente para o limite de datacenter do Azure. A menor latência possível é alcançada garantindo que o aplicativo de chamada está localizado na mesma região do Azure do ponto de extremidade do Azure Cosmos DB provisionado. Para obter uma lista de regiões disponíveis, consulte Regiões do Azure.
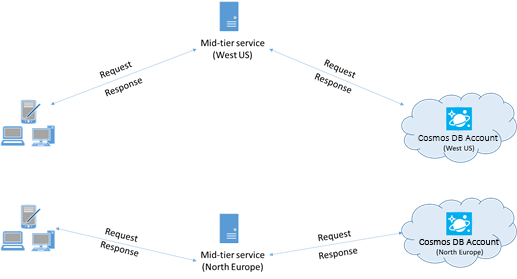
Um aplicativo que interage com uma conta do Azure Cosmos DB de várias regiões precisa configurar locais preferenciais para garantir que as solicitações sejam feitas para uma região posicionada.
Habilitar a rede acelerada para reduzir a latência e a tremulação da CPU
É altamente recomendável seguir as instruções para habilitar a Rede Acelerada na VM do Azure do Windows (selecione para obter instruções) ou Linux (selecione para obter instruções), para maximizar o desempenho, reduzindo a latência e o jitter da CPU.
Sem a rede acelerada, a E/S que transita entre a VM do Azure e outros recursos do Azure pode ser encaminhada por meio de um host e um comutador virtual situados entre a VM e sua placa de rede. Ter o host e o comutador virtual embutidos no caminho de dados não apenas aumenta a latência e a tremulação no canal de comunicação, ele também rouba ciclos de CPU da VM. Com a rede acelerada, a VM interfaces diretamente com a NIC sem intermediários. Todos os detalhes da política de rede são tratados no hardware na NIC, ignorando o host e o comutador virtual. Geralmente, você pode esperar uma latência mais baixa e uma taxa de transferência mais alta, bem como uma latência mais consistente e menor utilização da CPU quando você habilita a rede acelerada.
Limitações: a rede acelerada deve ter suporte no sistema operacional da VM e só pode ser habilitada quando a VM é interrompida e desalocada. A VM não pode ser implantada com o Azure Resource Manager. O Serviço de Aplicativo não tem a rede acelerada habilitada.
Para obter mais informações, consulte as instruções do Windows e do Linux.
Alta disponibilidade
Para obter orientações gerais sobre como configurar a alta disponibilidade no Azure Cosmos DB, consulte Alta disponibilidade no Azure Cosmos DB.
Além de uma boa configuração fundamental na plataforma de banco de dados, há técnicas específicas que podem ser implementadas no próprio SDK do Java, o que pode ajudar em cenários de interrupção. Duas estratégias notáveis são a estratégia de disponibilidade baseada em limite e o interruptor de circuito no nível da partição.
Essas técnicas fornecem mecanismos avançados para lidar com desafios específicos de latência e disponibilidade, indo além dos recursos de repetição entre regiões que são integrados ao SDK por padrão. Ao gerenciar proativamente possíveis problemas nos níveis de solicitação e partição, estas estratégias podem melhorar significativamente a resiliência e o desempenho do aplicativo, especialmente em condições de alta carga ou degradadas.
Estratégia de disponibilidade baseada em limite
A estratégia de disponibilidade baseada em limite pode melhorar a latência e a disponibilidade final enviando solicitações de leitura paralelas para regiões secundárias e aceitando a resposta mais rápida. Essa abordagem pode reduzir drasticamente o impacto de interrupções regionais ou condições de alta latência no desempenho do aplicativo. Além disso, o gerenciamento proativo de conexões pode ser empregado para melhorar ainda mais o desempenho, aquecendo conexões e caches na região de leitura atual e nas regiões remotas preferidas.
Exemplo de configuração:
// Proactive Connection Management
CosmosContainerIdentity containerIdentity = new CosmosContainerIdentity("sample_db_id", "sample_container_id");
int proactiveConnectionRegionsCount = 2;
Duration aggressiveWarmupDuration = Duration.ofSeconds(1);
CosmosAsyncClient clientWithOpenConnections = new CosmosClientBuilder()
.endpoint("<account URL goes here")
.key("<account key goes here>")
.endpointDiscoveryEnabled(true)
.preferredRegions(Arrays.asList("sample_region_1", "sample_region_2"))
.openConnectionsAndInitCaches(new CosmosContainerProactiveInitConfigBuilder(Arrays.asList(containerIdentity))
.setProactiveConnectionRegionsCount(proactiveConnectionRegionsCount)
//setting aggressive warmup duration helps in cases where there is a high no. of partitions
.setAggressiveWarmupDuration(aggressiveWarmupDuration)
.build())
.directMode()
.buildAsyncClient();
CosmosAsyncContainer container = clientWithOpenConnections.getDatabase("sample_db_id").getContainer("sample_container_id");
int threshold = 500;
int thresholdStep = 100;
CosmosEndToEndOperationLatencyPolicyConfig config = new CosmosEndToEndOperationLatencyPolicyConfigBuilder(Duration.ofSeconds(3))
.availabilityStrategy(new ThresholdBasedAvailabilityStrategy(Duration.ofMillis(threshold), Duration.ofMillis(thresholdStep)))
.build();
CosmosItemRequestOptions options = new CosmosItemRequestOptions();
options.setCosmosEndToEndOperationLatencyPolicyConfig(config);
container.readItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
// Write operations can benefit from threshold-based availability strategy if opted into non-idempotent write retry policy
// and the account is configured for multi-region writes.
options.setNonIdempotentWriteRetryPolicy(true, true);
container.createItem("id", new PartitionKey("pk"), options, JsonNode.class).block();
Como funciona:
Solicitação inicial: no momento T1, uma solicitação de leitura é feita para a região primária (por exemplo, Leste dos EUA). O SDK aguarda uma resposta de até 500 milissegundos (o valor
threshold).Segunda solicitação: se não houver resposta da região primária dentro de 500 milissegundos, uma solicitação paralela será enviada para a próxima região preferencial (por exemplo, Leste dos EUA 2).
Terceira solicitação: se nem a região primária nem a secundária responderem dentro de 600 milissegundos (500ms + 100ms, o valor
thresholdStep), o SDK enviará outra solicitação paralela para a terceira região preferencial (por exemplo, Oeste dos EUA).A resposta mais rápida vence: qualquer região que responda primeiro, essa resposta é aceita e as outras solicitações paralelas são ignoradas.
O gerenciamento proativo de conexões ajuda a aquecer conexões e caches para contêineres nas regiões preferidas, reduzindo a latência de inicialização a frio para cenários de failover ou gravações em configurações multirregionais.
Essa estratégia pode melhorar significativamente a latência em cenários em que uma determinada região está lenta ou temporariamente indisponível, mas pode incorrer em mais custos em termos de unidades de solicitação quando solicitações entre regiões paralelas são necessárias.
Observação
Se a primeira região preferencial retornar um código de status de erro não transitório (por exemplo, documento não encontrado, erro de autorização, conflito etc.), a operação em si falhará rapidamente, pois a estratégia de disponibilidade não teria nenhum benefício nesse cenário.
Interruptor de circuito de nível de partição
O interruptor de circuito no nível da partição aprimora a latência da cauda e a disponibilidade de gravação acompanhando e solicitações de curto-circuito para partições físicas não íntegras. Ele melhora o desempenho evitando partições problemáticas conhecidas e redirecionando solicitações para regiões mais saudáveis.
Exemplo de configuração:
Para habilitar o interruptor de circuito no nível da partição:
System.setProperty(
"COSMOS.PARTITION_LEVEL_CIRCUIT_BREAKER_CONFIG",
"{\"isPartitionLevelCircuitBreakerEnabled\": true, "
+ "\"circuitBreakerType\": \"CONSECUTIVE_EXCEPTION_COUNT_BASED\","
+ "\"consecutiveExceptionCountToleratedForReads\": 10,"
+ "\"consecutiveExceptionCountToleratedForWrites\": 5,"
+ "}");
Para definir a frequência do processo em segundo plano para verificar regiões indisponíveis:
System.setProperty("COSMOS.STALE_PARTITION_UNAVAILABILITY_REFRESH_INTERVAL_IN_SECONDS", "60");
Para definir a duração para a qual uma partição pode permanecer indisponível:
System.setProperty("COSMOS.ALLOWED_PARTITION_UNAVAILABILITY_DURATION_IN_SECONDS", "30");
Como funciona:
Falhas de acompanhamento: o SDK rastreia falhas de terminal (por exemplo, 503s, 500s, tempos limite) para partições individuais em regiões específicas.
Marcando como indisponível: se uma partição em uma região exceder um limite configurado de falhas, ela será marcada como "Indisponível". As solicitações subsequentes para essa partição são de curto-circuito e redirecionadas para outras regiões mais íntegras.
Recuperação automatizada: um thread em segundo plano verifica periodicamente partições indisponíveis. Após uma determinada duração, essas partições são marcadas provisoriamente como "HealthyTentative" e submetidas a solicitações de teste para validar a recuperação.
Promoção/rebaixamento de Integridade: com base no êxito ou falha dessas solicitações de teste, o status da partição é promovido de volta para "Íntegro" ou rebaixado mais uma vez para "Indisponível".
Esse mecanismo ajuda a monitorar continuamente a integridade da partição e garante que as solicitações sejam atendidas com latência mínima e disponibilidade máxima, sem serem atoladas por partições problemáticas.
Observação
O interruptor de circuito aplica-se apenas a contas de gravação de várias regiões, como quando uma partição é marcada como Unavailable, as leituras e gravações são movidas para a próxima região preferencial. Isso é para impedir que leituras e gravações de regiões diferentes sejam atendidas da mesma instância do cliente, pois isso seria um anti-padrão.
Importante
Você deverá estar usando a versão 4.63.0 do SDK do Java ou superior para ativar o Interruptor de Circuito de Nível de Partição.
Comparar otimizações de disponibilidade
Estratégia de disponibilidade baseada em limite:
- Benefício: reduz a latência final, enviando solicitações de leitura paralelas para regiões secundárias e aprimora a disponibilidade com solicitações de pré-codificação que resultarão em tempos limite de rede.
- Compensação: incorre em custos extras de RU (Unidades de Solicitação) em comparação com o disjuntor, devido a solicitações paralelas adicionais entre regiões (embora somente durante períodos em que os limites são violados).
- Caso de uso: ideal para cargas de trabalho de leitura pesada, em que a redução da latência é crítica e algum custo adicional (tanto em termos de carga de RU quanto de pressão da CPU do cliente) é aceitável. As operações de gravação também podem se beneficiar, se optarem pela política de repetição de gravação não idempotente e a conta tiver gravações de várias regiões.
Interruptor de circuito de nível de partição:
- Benefício: aprimora a disponibilidade e a latência de gravação, evitando partições não íntegras, garantindo que as solicitações sejam roteadas para regiões mais íntegras.
- Compensação: não incorre em custos adicionais de RU, mas ainda pode permitir alguma perda de disponibilidade inicial para solicitações que resultarão em tempos limite de rede.
- Caso de uso: ideal para cargas de trabalho pesadas ou mistas em que o desempenho consistente é essencial, especialmente ao lidar com partições que podem se tornar intermitentemente não íntegras.
Ambas as estratégias podem ser usadas em conjunto para aprimorar a disponibilidade de leitura e gravação e reduzir a latência final. O interruptor de circuito de nível de partição pode lidar com uma variedade de cenários de falha transitória, incluindo aqueles que podem resultar em réplicas de desempenho lento, sem a necessidade de executar solicitações paralelas. Além disso, adicionar a Estratégia de Disponibilidade baseada em Limite minimizará ainda mais a latência final e eliminará a perda de disponibilidade, se o custo adicional de RU for aceitável.
Ao implementar essas estratégias, os desenvolvedores podem garantir que seus aplicativos permaneçam resilientes, manter alto desempenho e fornecer uma melhor experiência do usuário mesmo durante interrupções regionais ou condições de alta latência.
Consistência da sessão no escopo da região
Visão geral
Para obter mais informações sobre as configurações de consistência em geral, consulte os Níveis de consistência no Azure Cosmos DB. O SDK do Java fornece uma otimização para consistência de sessão para contas de gravação de várias regiões, permitindo que ele tenha escopo de região. Isso aprimora o desempenho mitigando a latência de replicação entre regiões, minimizando as tentativas do lado do cliente. Isso é feito gerenciando tokens de sessão no nível da região em vez de globalmente. Se a consistência em seu aplicativo puder ser definida para um número menor de regiões, implementando a consistência de sessão com escopo de região, você poderá obter melhor desempenho e confiabilidade para operações de leitura e gravação em contas de várias gravações minimizando atrasos e repetições de replicação entre regiões.
Benefícios
- Latência reduzida: ao localizar a validação do token de sessão para o nível da região, as chances de novas tentativas inter-regionais dispendiosa são reduzidas.
- Desempenho melhorado: minimiza o impacto do failover regional e do atraso de replicação, oferecendo maior consistência de leitura/gravação e menor utilização da CPU.
- Utilização otimizada de recursos: reduz a sobrecarga da CPU e da rede em aplicativos cliente limitando a necessidade de novas tentativas e chamadas entre regiões, otimizando assim o uso de recursos.
- Alta disponibilidade: mantendo tokens de sessão com escopo de região, os aplicativos podem continuar operando sem problemas, mesmo que determinadas regiões experimentem maior latência ou falhas temporárias.
- Garantias de consistência: garante que as garantias de consistência da sessão (ler sua gravação, leitura monotônica) sejam atendidas de forma mais confiável sem novas tentativas desnecessárias.
- Eficiência de custo: reduz o número de chamadas entre regiões, reduzindo potencialmente os custos associados às transferências de dados entre regiões.
- Escalabilidade: permite que os aplicativos sejam dimensionados com mais eficiência, reduzindo a contenção e a sobrecarga associadas à manutenção de um token de sessão global, especialmente em configurações de várias regiões.
Compensações
- Aumento do uso de memória: o filtro de bloom e o armazenamento de token de sessão específico da região exigem memória adicional, o que pode ser uma consideração para aplicativos com recursos limitados.
- Complexidade de configuração: ajustar a contagem de inserção esperada e a taxa de falso positivo para o filtro de bloom adiciona uma camada de complexidade ao processo de configuração.
- Potencial para falsos positivos: embora o filtro de bloom minimize as novas tentativas entre regiões, ainda há uma pequena chance de falsos positivos afetarem a validação do token de sessão, embora a taxa possa ser controlada. Um falso positivo significa que o token de sessão global é resolvido, aumentando assim a chance de novas tentativas entre regionais se a região local não tiver se atualizado para esta sessão global. As garantias de sessão são atendidas mesmo na presença de falsos positivos.
- Aplicabilidade: esse recurso é mais benéfico para aplicativos com alta cardinalidade de partições lógicas e reinicializações regulares. Aplicativos com menos partições lógicas ou reinicializações pouco frequentes podem não ver benefícios significativos.
Como ele funciona
Definir o token de sessão
- Conclusão da solicitação: depois que uma solicitação é concluída, o SDK captura o token de sessão e o associa à região e à chave de partição.
- Armazenamento em nível de região: os tokens de sessão são armazenados em um aninhado
ConcurrentHashMapque mantém mapeamentos entre intervalos de chaves de partição e progresso no nível da região. - Filtro de bloom: um filtro de bloom mantém o controle de quais regiões foram acessadas por cada partição lógica, ajudando a localizar a validação do token de sessão.
Resolver o token de sessão
- Inicialização da solicitação: antes de uma solicitação ser enviada, o SDK tenta resolver o token de sessão para a região apropriada.
- Verificação de token: o token é verificado em relação aos dados específicos da região para garantir que a solicitação seja roteada para a réplica mais atualizada.
- Lógica de repetição: se o token de sessão não for validado na região atual, o SDK tentará novamente com outras regiões, mas dado o armazenamento localizado, isso será menos frequente.
Usar o SDK do
Veja como inicializar o CosmosClient com consistência de sessão com escopo de região:
CosmosClient client = new CosmosClientBuilder()
.endpoint("<your-endpoint>")
.key("<your-key>")
.consistencyLevel(ConsistencyLevel.SESSION)
.buildClient();
// Your operations here
Habilitar a consistência da sessão no escopo da região
Para habilitar a captura de sessão com escopo de região em seu aplicativo, defina a seguinte propriedade do sistema:
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
Configurar filtro de bloom
Ajuste o desempenho configurando as inserções esperadas e a taxa de falso positivo para o filtro de bloom:
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "5000000"); // adjust as needed
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.001"); // adjust as needed
System.setProperty("COSMOS.SESSION_CAPTURING_TYPE", "REGION_SCOPED");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_INSERTION_COUNT", "1000000");
System.setProperty("COSMOS.PK_BASED_BLOOM_FILTER_EXPECTED_FFP_RATE", "0.01");
Implicações de memória
Abaixo está o tamanho retido (tamanho do objeto e o que ele depender) do contêiner de sessão interna (gerenciado pelo SDK) com inserções esperadas variadas no filtro de bloom.
| Inserções esperadas | Taxa de falsos positivos | Tamanho retido |
|---|---|---|
| 10.000 | 0,001 | 21 KB |
| 100.000 | 0,001 | 183 KB |
| 1 milhão | 0,001 | 1,8 MB |
| 10 milhões | 0,001 | 17,9 MB |
| 100 milhões | 0,001 | 179 MB |
| 1 bilhão | 0,001 | 1,8 GB |
Importante
Você deverá estar usando a versão 4.60.0 do SDK do Java ou superior para ativar a consistência da sessão no escopo da região.
Ajuste da configuração de conexão direta e de gateway
Para otimizar as configurações de conexão no modo de gateway e direto, confira como ajustar as configurações de conexão para o SDK v4 do Java.
Uso do SDK
- Instalar o SDK mais recente
Os SDKs do Azure Cosmos DB estão constantemente sendo aprimorados para fornecer o melhor desempenho. Para determinar as melhorias mais recentes do SDK, visite o SDK do Azure Cosmos DB.
- Use um cliente de banco de dados individual do Azure Cosmos DB para obter o tempo de vida do aplicativo
Cada instância do cliente do Azure Cosmos DB tem um thread-safe e realiza um gerenciamento de conexão eficiente e o cache de endereço. Para permitir o gerenciamento de conexões eficiente e o melhor desempenho pelo cliente do Azure Cosmos DB, é altamente recomendável usar uma única instância do cliente do Azure Cosmos DB durante a vida útil do aplicativo.
Quando você cria um CosmosClient, a consistência padrão usada se não for definido explicitamente é Sessão. Se a consistência de Sessão não for exigida pela lógica do aplicativo, defina a Consistência como Eventual. Observação: é recomendável usar pelo menos a consistência de Sessão em aplicativos que empregam o processador do feed de alterações do Azure Cosmos DB.
- Usar a API assíncrona para obter a taxa de transferência máxima provisionada
O SDK do Java v4 do Azure Cosmos DB agrupa duas APIs, síncrona e assíncrona. Em termos gerais, a API assíncrona implementa a funcionalidade do SDK, enquanto que a API síncrona é um wrapper fino que faz chamadas de bloqueio para a API assíncrona. Isso significa que, em contraste com o SDK do Java v2 do Azure Cosmos DB antigo, que era somente assíncrono e para o SDK do Java v2 síncrono mais antigo do Azure Cosmos DB, que era somente síncrono e tinha uma implementação separada.
A escolha da API é determinada durante a inicialização do cliente; um CosmosAsyncClient dá suporte à API assíncrona enquanto um CosmosClient dá suporte à API síncrona.
A API assíncrona implementa E/S sem bloqueio e é a melhor opção se sua meta for obter a taxa de transferência máxima ao emitir solicitações para o Azure Cosmos DB.
O uso da API síncrona pode ser a escolha certa se você quiser ou precisar de uma API, que bloqueie a resposta a cada solicitação, ou se a operação síncrona for o paradigma dominante no aplicativo. Por exemplo, você pode querer a API síncrona quando estiver mantendo dados para o Azure Cosmos DB em um aplicativo de microsserviço, desde que a taxa de transferência fornecida não seja crítica.
Observe que a taxa de transferência da API síncrona é reduzida com tempo de resposta de solicitação crescente, enquanto a API assíncrona pode saturar os recursos completos de largura de banda do seu hardware.
A colocação geográfica pode fornecer uma taxa de transferência maior e mais consistente ao usar a API de sincronização (consulte Posicionar clientes na mesma região do Azure para melhorar o desempenho), mas ainda não deve exceder a taxa de transferência obtida da API assíncrona.
Alguns usuários também podem não estar familiarizados com o Project Reactor, a estrutura da Reactive Streams usada para implementar a API assíncrona do SDK do Java v4 do Azure Cosmos DB. Se isso for uma preocupação, recomendamos que você leia nosso Guia de introdução de padrão do Reactor e, em seguida, dê uma olhada em Introdução à programação da Reactive para se familiarizar. Se você já tiver usado o Azure Cosmos DB com uma interface assíncrona e o SDK usado foi o SDK de Java v2 Assíncrono do Azure Cosmos DB, talvez esteja familiarizado com ReactiveX/RxJava, mas não sabe o que mudou no Project Reactor. Nesse caso, dê uma olhada em nosso Guia Reactor. versus RxJava para se familiarizar.
Os trechos de código a seguir mostram como inicializar seu cliente do Azure Cosmos DB para a API assíncrona ou a operação de API de sincronização, respectivamente:
API assíncrona do SDK do Java V4 (Maven com.azure::azure-cosmos)
CosmosAsyncClient client = new CosmosClientBuilder()
.endpoint(HOSTNAME)
.key(MASTERKEY)
.consistencyLevel(CONSISTENCY)
.buildAsyncClient();
- Escalar horizontalmente sua carga de trabalho do cliente
Se você estiver testando em altos níveis da taxa de transferência, o aplicativo cliente poderá tornar-se o gargalo devido à limitação do computador na utilização da CPU ou da rede. Se você chegar a este ponto, poderá continuar aumentando a conta do Azure Cosmos DB ainda mais distribuindo seus aplicativos cliente entre vários servidores.
Uma boa regra geral é não exceder >50% de utilização de CPU em qualquer servidor para manter a latência baixa.
- Usar o Agendador Apropriado (Evitar roubo de threads Netty de E/S Eventloop)
A funcionalidade assíncrona do SDK do Java do Azure Cosmos DB baseia-se na E/S sem bloqueio de netty. O SDK usa um número fixo de threads de eventloop netty de E/S (como muitos núcleos de CPU que seu computador possui) para executar operações de E/S. O Fluxo retornado pela API emite o resultado em um dos threads de loop event loop netty de E/S compartilhados. Portanto, é importante não bloquear os threads de netty eventloop de E/S compartilhados. Realizar tarefas intensivas de CPU ou operações de bloqueio no thread de loop de eventos de E/S do Netty pode causar deadlock ou reduzir significativamente a taxa de transferência do SDK.
Por exemplo, o seguinte código executa um trabalho com uso intensivo de CPU no thread do Netty de E/S do loop de eventos:
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub.subscribe(
itemResponse -> {
//this is executed on eventloop IO netty thread.
//the eventloop thread is shared and is meant to return back quickly.
//
// DON'T do this on eventloop IO netty thread.
veryCpuIntensiveWork();
});
Depois que o resultado for recebido, você deverá evitar fazer qualquer trabalho intensivo de CPU no resultado no thread de E/S do Netty loop de eventos. Em vez disso, você pode oferecer o próprio Agendador para fornecer o próprio thread para executar seu trabalho, conforme mostrado abaixo (requer import reactor.core.scheduler.Schedulers).
Mono<CosmosItemResponse<CustomPOJO>> createItemPub = asyncContainer.createItem(item);
createItemPub
.publishOn(Schedulers.parallel())
.subscribe(
itemResponse -> {
//this is now executed on reactor scheduler's parallel thread.
//reactor scheduler's parallel thread is meant for CPU intensive work.
veryCpuIntensiveWork();
});
Com base no tipo de seu trabalho, use o Agendador de Reator existente apropriado para seu trabalho. Leia aqui Schedulers.
Para entender melhor o modelo de threading e de agendamento do projeto Reactor, consulte esta postagem no blog do Project Reactor.
Para saber mais sobre o SDK v4 do Java do Azure Cosmos DB, confira o Diretório do Azure Cosmos DB do SDK do Azure para o repositório único do Java no GitHub.
- Otimizar as configurações de log em seu aplicativo
Por vários motivos, você deverá adicionar log em um thread que está gerando alta taxa de transferência de solicitação. Se seu objetivo for saturar completamente a taxa de transferência provisionada de um contêiner com solicitações geradas por essa thread, as otimizações de log poderão melhorar significativamente o desempenho.
- Configurar um agente assíncrono
A latência de um agente síncrono é necessariamente um dos fatores do cálculo de latência geral da sua thread de geração de solicitação. Um agente assíncrono, como log4j2, é recomendado para desacoplar a sobrecarga de log de suas threads de aplicativos de alto desempenho.
- Desabilitar o log do netty
O registro em log da biblioteca Netty é verborrágico e precisa ser desativado (suprimir o log na configuração talvez não seja suficiente) para evitar custos adicionais de CPU. Se você não estiver no modo de depuração, desabilite o registro em log do netty completamente. Portanto, se estiver usando Log4j para remover os custos adicionais de CPU devidos pelo org.apache.log4j.Category.callAppenders() do Netty, adicione a seguinte linha à sua base de código:
org.apache.log4j.Logger.getLogger("io.netty").setLevel(org.apache.log4j.Level.OFF);
- Limite de recursos de arquivos abertos do SO
Alguns sistemas Linux (como Red Hat) têm um limite superior no número de arquivos abertos e, portanto no número total de conexões. Execute o seguinte para exibir os limites atuais:
ulimit -a
O número de arquivos abertos (nofile) deve ser grande o suficiente para ter espaço para o tamanho do pool de conexão configurado e outros arquivos abertos pelo SO. Isso pode ser modificado para permitir um maior tamanho de pool de conexão.
Abra o arquivo limits.conf:
vim /etc/security/limits.conf
Adicione/modifique as linhas a seguir:
* - nofile 100000
- Especificar chave de partição em gravações de ponto
Para melhorar o desempenho das gravações de ponto, especifique a chave de partição do item na chamada à API de gravação de ponto, conforme mostrado abaixo:
API assíncrona do SDK do Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item,new PartitionKey(pk),new CosmosItemRequestOptions()).block();
Em vez de fornecer apenas a instância do item, conforme mostrado abaixo:
API assíncrona do SDK do Java V4 (Maven com.azure::azure-cosmos)
asyncContainer.createItem(item).block();
Há suporte para o último, mas isso adicionará latência ao seu aplicativo; o SDK deve analisar o item e extrair a chave de partição.
Operações de consulta
Para operações de consulta, consulte as dicas de desempenho para consultas.
Política de indexação
- Excluir caminhos não utilizados da indexação para ter gravações mais rápidas
A política de indexação do Azure Cosmos DB permite que você especifique quais caminhos de documentos devem ser incluídos ou excluídos da indexação usando os caminhos de indexação (setIncludedPaths e setExcludedPaths). O uso dos caminhos de indexação pode oferecer um melhor desempenho de gravação e menor armazenamento de índices para os cenários nos quais os padrões da consulta são conhecidos com antecedência, pois os custos da indexação estão correlacionados diretamente com o número de caminhos exclusivos indexados. Por exemplo, o código a seguir mostra como incluir e excluir seções inteiras dos documentos (também conhecida como subárvore) da indexação usando o curinga "*".
CosmosContainerProperties containerProperties = new CosmosContainerProperties(containerName, "/lastName");
// Custom indexing policy
IndexingPolicy indexingPolicy = new IndexingPolicy();
indexingPolicy.setIndexingMode(IndexingMode.CONSISTENT);
// Included paths
List<IncludedPath> includedPaths = new ArrayList<>();
includedPaths.add(new IncludedPath("/*"));
indexingPolicy.setIncludedPaths(includedPaths);
// Excluded paths
List<ExcludedPath> excludedPaths = new ArrayList<>();
excludedPaths.add(new ExcludedPath("/name/*"));
indexingPolicy.setExcludedPaths(excludedPaths);
containerProperties.setIndexingPolicy(indexingPolicy);
ThroughputProperties throughputProperties = ThroughputProperties.createManualThroughput(400);
database.createContainerIfNotExists(containerProperties, throughputProperties);
CosmosAsyncContainer containerIfNotExists = database.getContainer(containerName);
Para obter mais informações, consulte Políticas de indexação do Azure Cosmos DB.
Produtividade
- Medir e ajustar para o uso mais baixo de unidades/segundo da solicitação
O Azure Cosmos DB oferece um conjunto avançado de operações do banco de dados, incluindo consultas relacionais e hierárquicas com UDFs, procedimentos armazenados e gatilhos – todos operando nos documentos em uma coleção de banco de dados. O custo associado a cada uma dessas operações varia com base na CPU, E/S e memória necessárias para concluir a operação. Em vez de pensar em e gerenciar recursos de hardware, você pode pensar em uma RU (unidade de solicitação) como uma medida única para os recursos necessários para realizar várias operações de bancos de dados e atender a uma solicitação do aplicativo.
A taxa de transferência é provisionada com base no número de unidades de solicitação definidas para cada contêiner. O consumo da unidade de solicitação é avaliado em termos de taxa por segundo. Os aplicativos que excedem a taxa das unidades de solicitação provisionada para seu contêiner serão limitados até que a taxa fique abaixo do nível reservado para o contêiner. Caso o aplicativo exija um nível mais alto de taxa de transferência, é possível aumentar a taxa de transferência provisionando unidades de solicitação adicionais.
A complexidade de uma consulta afeta a quantidade de unidades de solicitação consumida para uma operação. O número de predicados, natureza dos predicados, número de UDFs e tamanho do conjunto de dados de origem influenciam o custo das operações de consulta.
Para medir a sobrecarga de qualquer operação (criar, atualizar ou excluir), examine o cabeçalho x-ms-request-charge para medir o número de unidades de solicitação consumidas por essas operações. Você também pode examinar a propriedade RequestCharge equivalente em ResourceResponse<T> ou FeedResponse<T>.
API assíncrona do SDK do Java V4 (Maven com.azure::azure-cosmos)
CosmosItemResponse<CustomPOJO> response = asyncContainer.createItem(item).block();
response.getRequestCharge();
A carga de solicitação retornada nesse cabeçalho é uma fração de sua taxa de transferência provisionada. Por exemplo, se você tem 2 mil RUs/s provisionados e se a consulta anterior retornar mil documentos de 1 KB, o custo da operação será mil. Assim, em um segundo, o servidor mantém apenas duas dessas solicitações antes de limitar as solicitações subsequentes. Para saber mais, consulte Unidades de solicitação e a calculadora das unidades de solicitação.
- Lidar com uma limitação da taxa/taxa de solicitação muito grande
Quando um cliente tentar exceder a taxa de transferência reservada para uma conta, não haverá nenhuma degradação de desempenho no servidor e nenhum uso da capacidade da taxa além do nível reservado. O servidor encerrará antecipadamente a solicitação com RequestRateTooLarge (código de status HTTP 429) e retornará o cabeçalho x-ms-retry-after-ms indicando a quantidade de tempo, em milissegundos, que o usuário deve aguardar antes de tentar novamente a solicitação.
HTTP Status 429,
Status Line: RequestRateTooLarge
x-ms-retry-after-ms :100
Os SDKs irão capturar implicitamente essa resposta, respeitarão o cabeçalho server-specified retry-after e repetirão a solicitação. A menos que sua conta esteja sendo acessada simultaneamente por vários clientes, a próxima tentativa será bem-sucedida.
Se você tiver mais de um cliente operando cumulativamente de forma consistente acima da taxa de solicitação, a contagem de repetição padrão atualmente definida internamente pelo cliente como 9 poderá não ser suficiente. Nesse caso, o cliente gera uma exceção CosmosClientException com o código de status 429 para o aplicativo. A contagem de repetição padrão pode ser alterada usando setMaxRetryAttemptsOnThrottledRequests() na instância ThrottlingRetryOptions. Por padrão, o CosmosClientException com o código de status 429 será retornada após uma espera cumulativa de 30 segundos se a solicitação continuar a operar acima da taxa de solicitação. Isso ocorre mesmo quando a contagem de repetição atual é menor que a contagem de repetição máxima, seja o padrão 9 seja um valor definido pelo usuário.
Embora o comportamento de repetição automática ajude a melhorar a resiliência e a utilidade da maioria dos aplicativos, ela pode entrar em conflito ao fazer comparações de desempenho, especialmente ao medir a latência. A latência observada pelo cliente terá um pico se o teste atingir a limitação do servidor e fizer com que o SDK do cliente repita silenciosamente. Para evitar picos de latência durante os testes de desempenho, meça o custo retornado por cada operação e verifique se as solicitações estão operando abaixo da taxa de solicitação reservada. Para saber mais, consulte Unidades de solicitação.
- Design de documentos menores para uma maior taxa de transferência
O custo da solicitação (o custo de processamento da solicitação) de uma determinada operação está correlacionado diretamente com o tamanho do documento. As operações em documentos grandes custam mais que as operações de documentos pequenos. O ideal é arquitetar seu aplicativo e os fluxos de trabalho para que o tamanho do item seja aproximadamente 1 KB ou uma ordem de magnitude semelhante. Para aplicativos com detecção de latência, itens grandes devem ser evitados: documentos com vários MB tornam o seu aplicativo mais lento.
Próximas etapas
Para saber mais sobre como projetar seu aplicativo para escala e alto desempenho, consulte Particionamento e escala no Azure Cosmos DB.
Tentando fazer um planejamento de capacidade para uma migração para o Microsoft Azure Cosmos DB? Você pode usar informações sobre o cluster de banco de dados existente para fazer isso.
- Se você sabe apenas o número de vCores e servidores do cluster de banco de dados existente, leia sobre como estimar unidades de solicitação com vCores ou vCPUs
- Se souber as taxas de solicitação típicas da carga de trabalho do banco de dados atual, leia sobre como estimar unidades de solicitação usando o planejador de capacidade do Azure Cosmos DB