Usando padrões de coluna nos fluxos de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Várias transformações de fluxos de dados de mapeamento permitem que você faça referência a colunas de modelo com base em padrões em vez de nomes de coluna codificados diretamente. Essa correspondência é conhecida como padrões de coluna. Você pode definir padrões para corresponder colunas com base no nome, tipo de dados, fluxo, origem ou posição, em vez de exigir nomes de campo exatos. Há dois cenários em que os padrões de coluna são úteis:
- Se os campos de origem de entrada forem alterados com frequência, como o caso de alteração de colunas em arquivos de texto ou bancos de dados NoSQL. Esse cenário é conhecido como descompasso de esquema.
- Se você quiser fazer uma operação comum em um grande grupo de colunas. Por exemplo, deseja converter cada coluna que tem 'total' em seu nome de coluna em um duplo.
Padrões de coluna em coluna derivada e agregação
Para adicionar um padrão de coluna em uma transformação coluna, agregação ou janela derivada, clique em Adicionar acima da lista de colunas ou no ícone de adição ao lado de uma coluna derivada existente. Escolha Adicionar padrão da coluna.
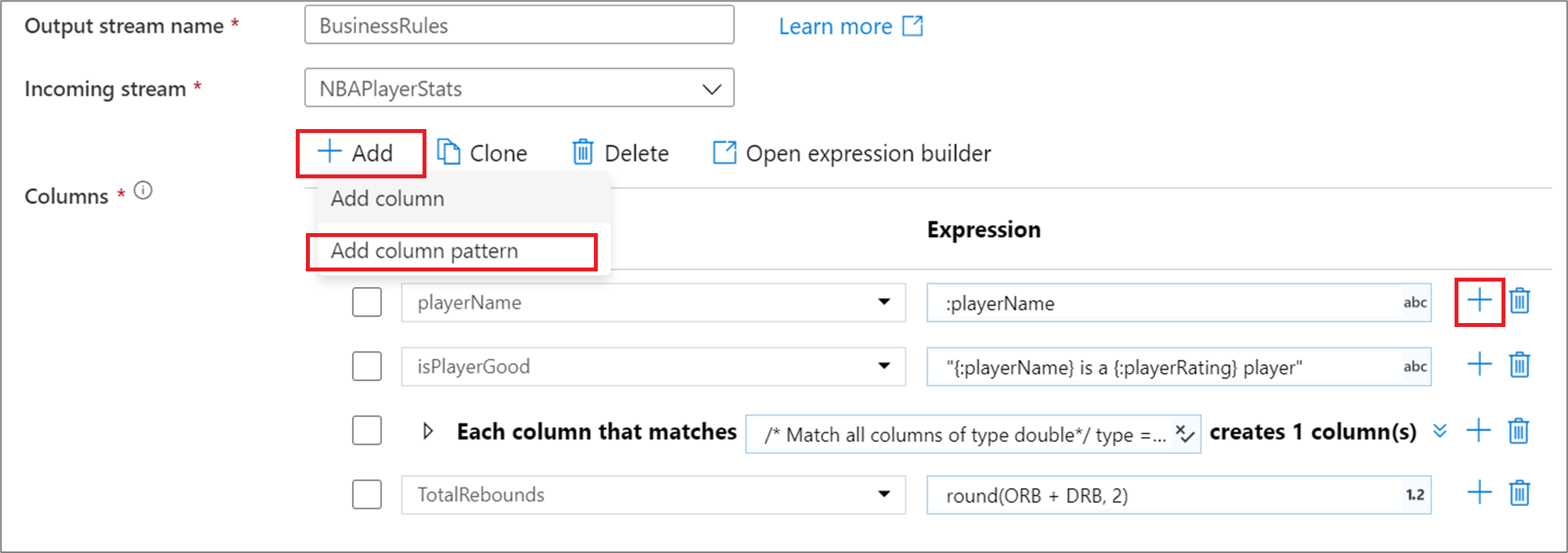
Use o Construtor de Expressões para entrar na condição de correspondência. Crie uma expressão booliana que corresponda a colunas com base em name, type, stream, origin e position da coluna. O padrão afetará qualquer coluna, descompasso ou definida, em que a condição retorna true.
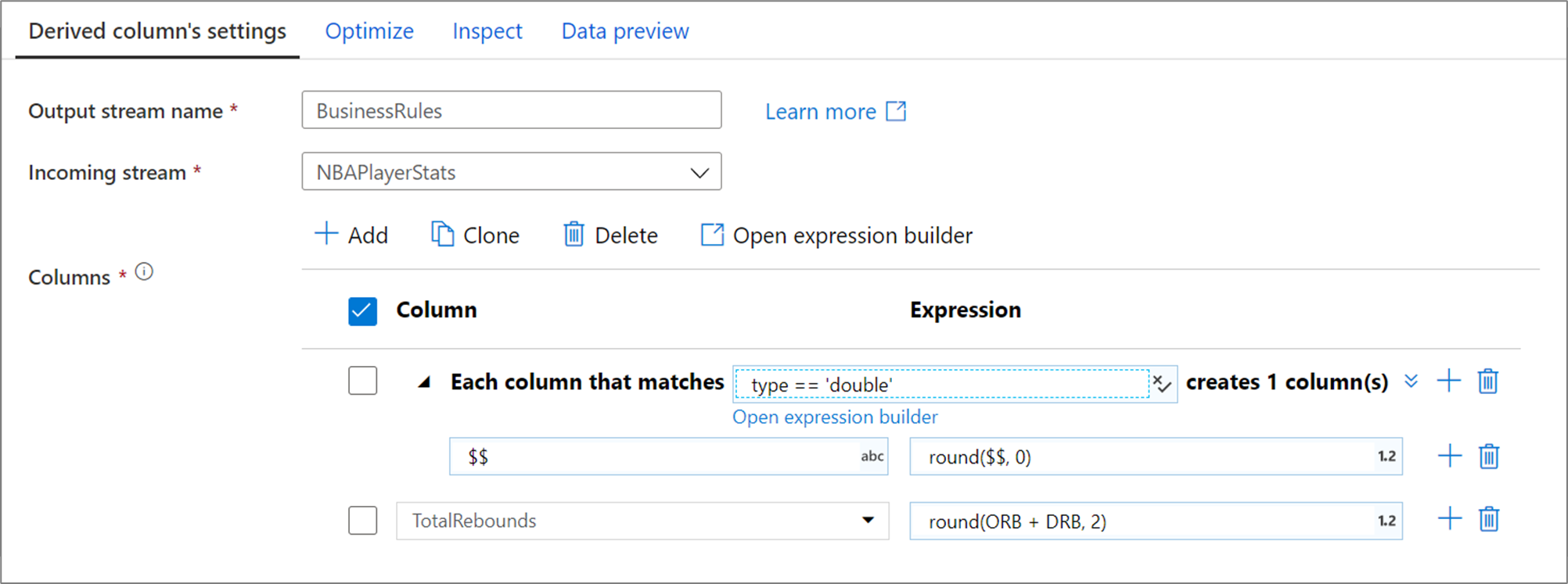
O padrão de coluna acima corresponde a cada coluna do tipo double e cria uma coluna derivada por correspondência. Ao indicar $$ como o campo nome da coluna, cada coluna correspondente é atualizada com o mesmo nome. O valor de cada coluna é o valor existente arredondado para dois pontos decimais.
Para verificar se a condição de correspondência está correta, você pode validar o esquema de saída das colunas definidas na guia Inspecionar ou obter um instantâneo dos dados na guia Visualização de dados.
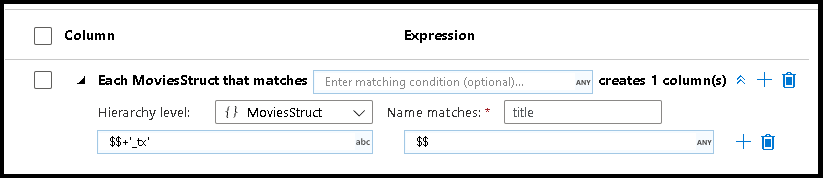
Correspondência de padrões hierárquicos
Você também pode criar a correspondência de padrões dentro de estruturas hierárquicas complexas. Expanda a seção Each MoviesStruct that matches em que você será solicitado a cada hierarquia em seu fluxo de dados. Em seguida, você pode criar padrões correspondentes para propriedades dentro dessa hierarquia escolhida.
Estruturas de nivelamento
Quando seus dados têm estruturas complexas, como matrizes, estruturas hierárquicas e mapas, você pode usar a Transformação de nivelamento para desenrolar matrizes e desnormalizar seus dados. Para estruturas e mapas, use a transformação de coluna derivada com padrões de coluna para formar sua tabela relacional nivelada com base nas hierarquias. Você pode usar os padrões de coluna que seriam parecidos com este exemplo, que nivela a hierarquia da geografia em um formato de tabela relacional:
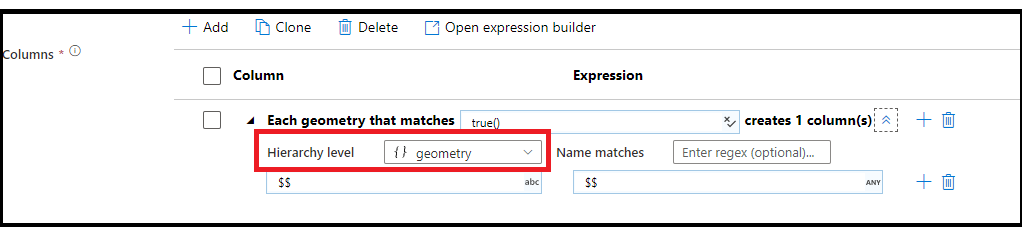
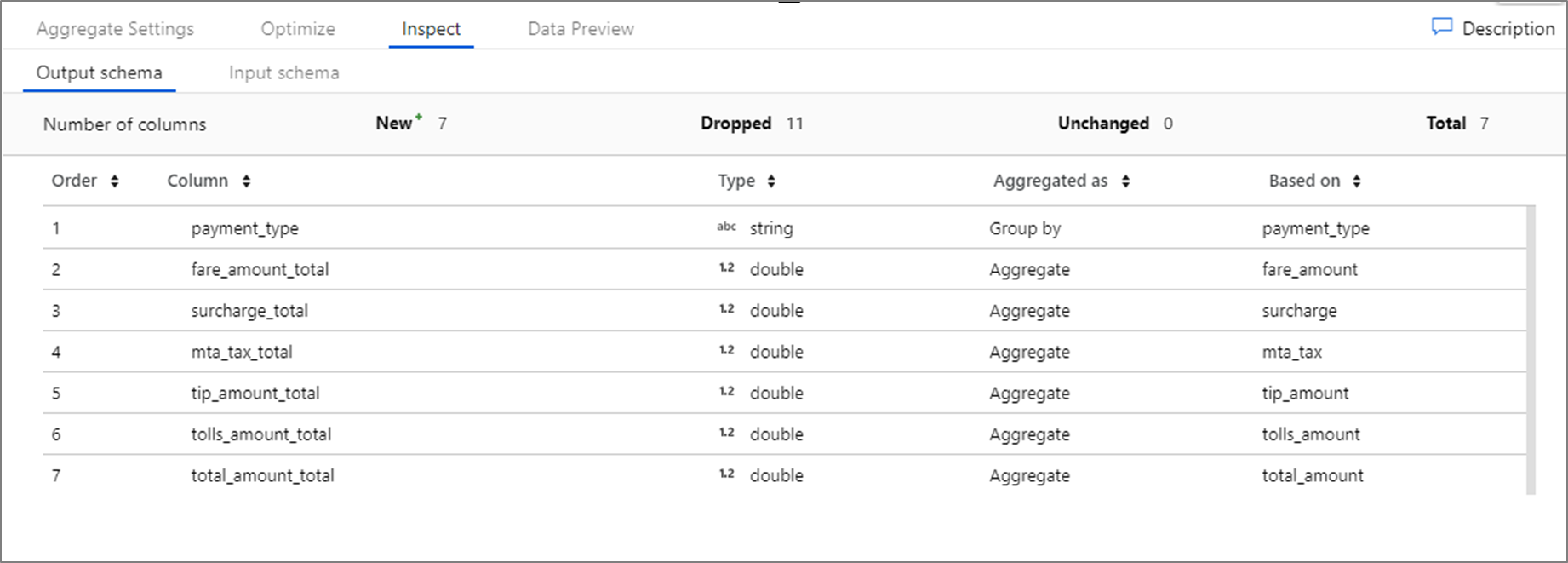
Mapeamento baseado em regras no select e sink
Ao mapear colunas na origem e selecionar transformações, você pode adicionar mapeamento fixo ou mapeamentos baseados em regras. Faça a correspondência com base nas colunas name, type, stream, origin e position. É possível fazer qualquer combinação de mapeamentos fixos e baseados em regras. Por padrão, todas as projeções com mais de 50 colunas são definidas como um mapeamento baseado em regra que corresponde a cada coluna e gera o nome inserido.
Para adicionar um mapeamento baseado em regras, clique em Adicionar mapeamento e selecione Mapeamento baseado em regras.

Cada mapeamento baseado em regras requer duas entradas: a condição que serve de base para a correspondência e o nome de cada coluna mapeada. Os dois valores são inseridos por meio do construtor de expressões. Na caixa de expressões à esquerda, insira a condição de correspondência booliana. Na caixa de expressões à direita, especifique o destino do mapeamento da coluna de correspondência.

Use a sintaxe $$ para fazer referência ao nome de entrada de uma coluna de correspondência. Adotando a imagem acima como exemplo, digamos que um usuário queira fazer a correspondência de todas as colunas de cadeia de caracteres cujos nomes tenham menos de seis caracteres. Se uma coluna de entrada tiver sido nomeada como test, a expressão $$ + '_short' renomeará a coluna para test_short. Se esse for o único mapeamento existente, todas as colunas que não atenderem à condição serão descartadas dos dados gerados.
Os padrões correspondem a colunas tanto descompassadas como definidas. Para ver quais colunas definidas são mapeadas por uma regra, clique no ícone de óculos ao lado da regra. Verifique a saída usando a visualização de dados.
Mapeamento regex
Se você clicar no ícone de divisa descendente, poderá especificar uma condição de mapeamento regex. Uma condição de mapeamento regex corresponde a todos os nomes de coluna que atendem à condição regex especificada. Isso pode ser usado em combinação com mapeamentos padrão baseados em regras.

O exemplo acima corresponde ao padrão regex (r) ou a qualquer nome de coluna que contenha uma letra r em minúscula. Assim como no mapeamento padrão baseado em regras, todas as colunas de correspondência são alteradas pela condição à direita por meio da sintaxe $$.
Hierarquias baseadas em regras
Se a projeção definida tiver uma hierarquia, use o mapeamento baseado em regras para mapear as subcolunas de hierarquias. Especifique uma condição de correspondência e a coluna complexa cujas subcolunas você deseja mapear. Todas as subcolunas de correspondência serão geradas com a regra 'Nome como' especificada à direita.
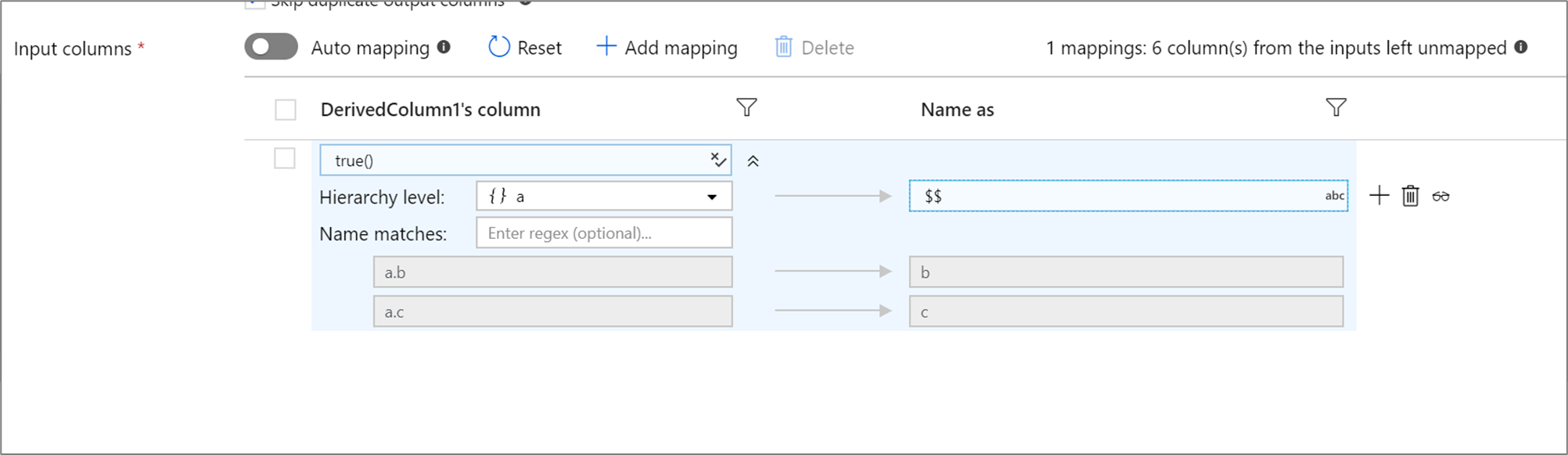
O exemplo acima corresponde a todas as subcolunas da coluna complexa a. a contém duas subcolunas b e c. O esquema de saída incluirá duas colunas b e c, já que a condição 'Nome como' é $$.
Valores de expressão de padrões correspondentes
$$converte para o nome ou o valor de cada corresponder em tempo de executar. Pense em$$como equivalente athis$0converte para a combinação de nome de coluna atual em runtime para tipos escalares. Para tipos hierárquicos, o$0representa o caminho atual da hierarquia de colunas correspondente.namerepresenta o nome de cada coluna de entradatyperepresenta o tipo de dados de cada coluna de entrada. A lista de tipos de dados no sistema de tipo de fluxos de dados pode ser encontrada aqui.streamrepresenta o nome associado a cada fluxo ou transformação em seu fluxopositioné a posição ordinal das colunas em seu fluxo de dadosoriginé a transformação em que uma coluna foi originada ou foi atualizada pela última vez
Conteúdo relacionado
- Saiba mais sobre a linguagem de expressão de fluxos de dados de mapeamento para transformações de dados
- Usar padrões de coluna na transformação do coletor e selecionar a transformação com mapeamento baseado em regras