Descompasso de esquema no fluxo de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O descompasso de esquema consiste no caso em que as suas fontes alteram frequentemente os metadados. É possível adicionar, remover ou alterar campos, colunas e tipos em tempo real. Sem o manuseio do descompasso de esquema, o fluxo de dados se torna vulnerável às alterações da fonte de dados upstream. Os padrões típicos de ETL falham quando as colunas e os campos de entrada são alterados, porque tendem a estar vinculados a esses nomes de fonte.
Para proteger contra o descompasso de esquema, é importante ter recursos em uma ferramenta de fluxo de dados para permitir que você, como Engenheiro de Dados:
- Defina fontes que tenham nomes de campos, tipos de dados, valores e tamanhos mutáveis
- Defina parâmetros de transformação que funcionam com padrões de dados ao invés de campos e valores codificados
- Defina expressões que compreendam padrões para corresponder aos campos recebidos, ao invés de usar campos nomeados
O Azure Data Factory dá suporte nativo a esquemas flexíveis que mudam de execução para execução de modo que você possa criar uma lógica de transformação de dados genérica sem a necessidade de recompilar os fluxos de dados.
Você precisa tomar uma decisão sobre a arquitetura de seu fluxo de dados para aceitar o descompasso de esquema em todo o fluxo. Ao fazer isso, você pode proteger contra alterações de esquema das fontes. No entanto, você perderá a vinculação antecipada de suas colunas e tipos em todo o fluxo de dados. O Azure Data Factory trata os fluxos de descompasso de esquema como fluxos de vinculação tardia, portanto, ao criar as transformações, os nomes das colunas descompassadas não ficam disponíveis nas visualizações de esquema durante todo o fluxo.
Este vídeo apresenta uma introdução a algumas das soluções complexas que você pode criar facilmente nos pipelines do Azure Data Factory ou do Synapse Analytics com o recurso de descompasso de esquema do fluxo de dados. Neste exemplo, criamos padrões reutilizáveis com base em esquemas de banco de dados flexíveis:
Descompasso de esquema na fonte
As colunas que entram no fluxo de dados na definição da fonte são definidas como “descompassadas” quando não estão presentes na projeção da fonte. É possível exibir a projeção da fonte na guia Projeção na transformação de fonte. Quando você seleciona um conjunto de dados para a fonte, o serviço pegará automaticamente o esquema do conjunto de dados e criará uma projeção a partir dessa mesma definição de esquema do conjunto.
Em uma transformação de fonte, o descompasso de esquema é definido como colunas de leitura que não são definidas no esquema do seu conjunto de dados. Para habilitar o descompasso de esquema, marque Permitir descompasso de esquema na transformação de fonte.
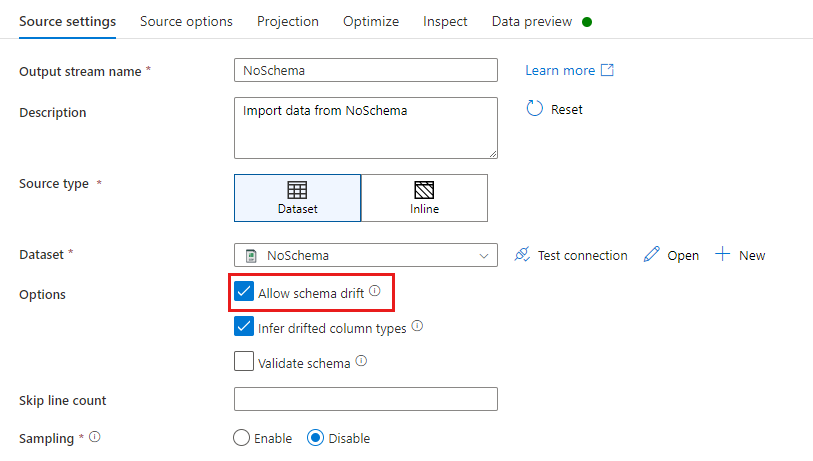
Quando o descompasso de esquema está habilitado, todos os campos de entrada são lidos a partir da fonte durante a execução e passados por todo o fluxo para o coletor. Por padrão, todas as colunas recentemente detectadas, conhecidas como colunas descompassadas, chegam como um tipo de dados da cadeia de caracteres. Se você quiser que o fluxo de dados infira automaticamente os tipos de dados de colunas descompassadas, marque Inferir tipos de colunas descompassadas nas configurações da fonte.
Descompasso de esquema no coletor
Em uma transformação de coletor, o descompasso de esquema é quando você grava colunas adicionais por cima daquilo que é definido no esquema de dados do coletor. Para habilitar o descompasso de esquema, marque Permitir descompasso de esquema na transformação de coletor.
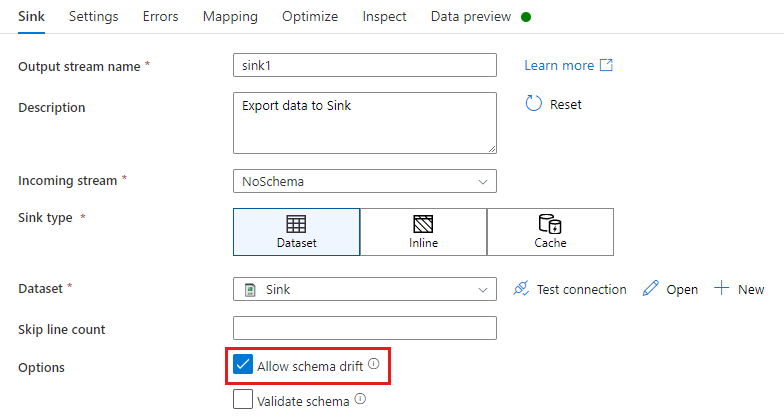
Se o descompasso de esquema estiver habilitado, verifique se o controle deslizante de Mapeamento automático na guia Mapeamento está ativado. Com esse controle deslizante ativado, todas as colunas de entrada são gravadas no destino. Caso contrário, você deve usar o mapeamento baseado em regras para gravar as colunas descompassadas.
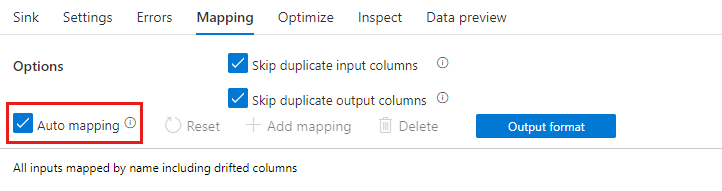
Transformar colunas descompassadas
Quando o fluxo de dados tiver colunas descompassadas, será possível acessá-las nas transformações com os seguintes métodos:
- Use as expressões
byPositionebyNamepara referenciar explicitamente uma coluna por nome ou número de posição. - Adicione um padrão de coluna em uma transformação Coluna Derivada ou Agregada para corresponder a qualquer combinação de nome, fluxo, posição, origem ou tipo
- Adicione o mapeamento baseado em regra em uma transformação Seleção ou Coletor para corresponder colunas descompassadas a aliases de colunas por meio de um padrão
Para obter mais informações sobre como implementar padrões de coluna, veja Padrões de coluna no fluxo de dados de mapeamento.
Mapear colunas descompassadas –ação rápida
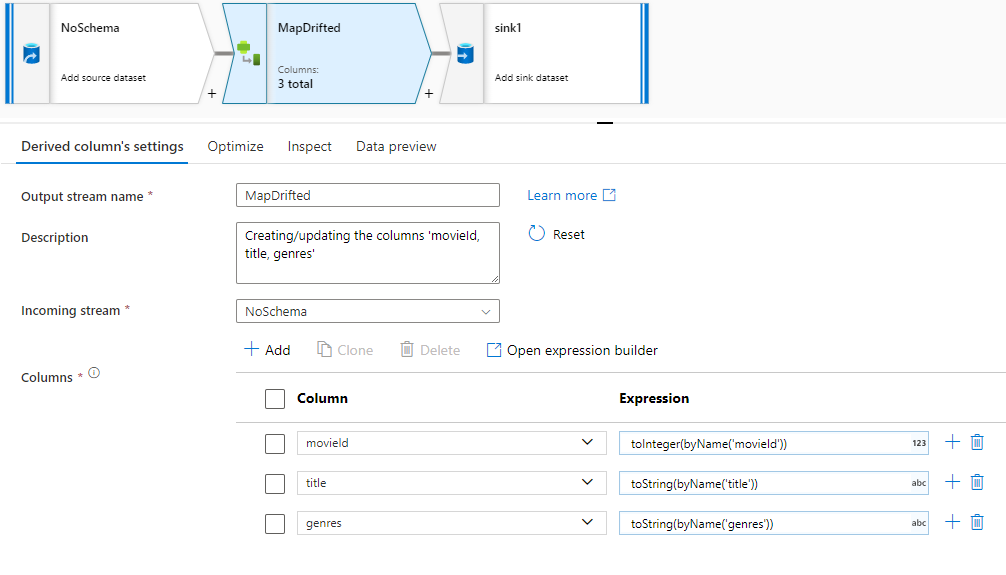
Para referenciar explicitamente colunas descompassadas, é possível gerar rapidamente mapeamentos para essas colunas por meio de uma ação rápida de visualização de dados. Depois que o modo de depuração estiver ativado, vá para a guia Visualização de dados e clique em Atualizar para buscar a visualização de dados. Se o data factory detectar que as colunas descompassadas existem, você poderá clicar em Mapear Descompassos e gerar uma coluna derivada que permitirá que você referencie todas as colunas descompassadas em exibições de esquema downstream.
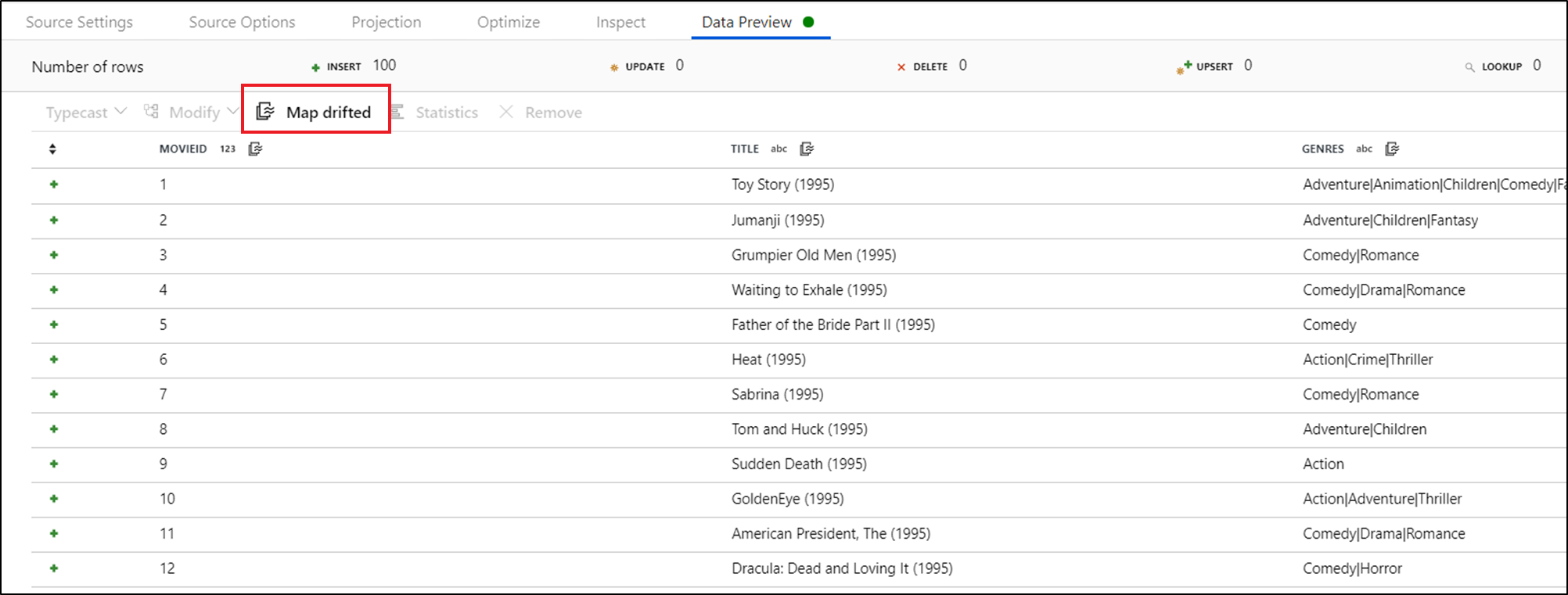
Na transformação Coluna Derivada gerada, cada coluna descompassada é mapeada por nome e tipo de dados detectados. Na visualização de dados acima, a coluna “MovieID” é detectada como um inteiro. Depois de você clicar em Mapear Descompasso, a coluna MovieID é definida na Coluna Derivada como toInteger(byName('movieId')) e incluída em exibições de esquema em transformações de downstream.
Conteúdo relacionado
Em Linguagem de Expressão de Fluxo de Dados, você encontrará recursos adicionais para padrões de coluna e descompasso de esquema, incluindo “byName” e “byPosition”.