Copiar dados do MongoDB, usando o Azure Data Factory ou Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Este artigo descreve como usar a atividade de cópia nos pipelines do Azure Data Factory e do Azure Synapse Analytics para copiar dados de um banco de dados do MongoDB. Ele amplia o artigo Visão geral da atividade de cópia que apresenta uma visão geral da atividade de cópia.
Importante
O novo conector do MongoDB fornece suporte ao MongoDB nativo aprimorado. Se você estiver usando o conector MongoDB herdado em sua solução, que é tem suporte no estado em que se encontra para oferecer compatibilidade com versões anteriores, confira o artigo Conector do MongoDB (herdado).
Funcionalidades com suporte
O conector MongoDB é compatível com as seguintes funcionalidades:
| Funcionalidades com suporte | IR |
|---|---|
| Atividade de cópia (origem/coletor) | ① ② |
① Runtime de integração do Azure ② Runtime de integração auto-hospedada
Para obter uma lista de armazenamentos de dados com suporte como origens/coletores, consulte a tabela de Armazenamentos de dados com suporte.
Especificamente, este conector do MongoDB dá suporte a versões até 4.2. Se o seu trabalho exige versões mais recentes que a 4.2, considere utilizar o MongoDB Atlas com o conector do MongoDB Atlas, que oferece suporte e recursos mais completos.
Pré-requisitos
Se o armazenamento de dados estiver localizado dentro de uma rede local, em uma rede virtual do Azure ou na Amazon Virtual Private Cloud, você precisará configurar um runtime de integração auto-hospedada para se conectar a ele.
Se o armazenamento de dados for um serviço de dados de nuvem gerenciado, você poderá usar o Azure Integration Runtime. Se o acesso for restrito aos IPs que estão aprovados nas regras de firewall, você poderá adicionar IPs do Azure Integration Runtime à lista de permissões.
Você também pode usar o recurso de runtime de integração da rede virtual gerenciada no Azure Data Factory para acessar a rede local sem instalar e configurar um runtime de integração auto-hospedada.
Para obter mais informações sobre os mecanismos de segurança de rede e as opções compatíveis com o Data Factory, consulte Estratégias de acesso a dados.
Introdução
Para executar a atividade de Cópia com um pipeline, será possível usar as ferramentas ou os SDKs abaixo:
- A ferramenta Copiar Dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- PowerShell do Azure
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado ao MongoDB usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao MongoDB na interface do usuário portal do Microsoft Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou do Synapse e selecione Serviços Vinculados, em seguida, clique em Novo:
Pesquise por MongoDB e selecione o conector MongoDB.
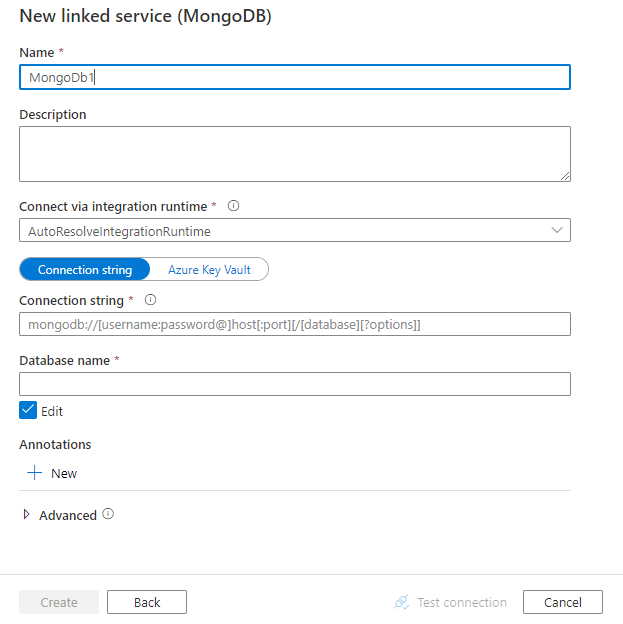
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.

Detalhes da configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas ao conector do MongoDB.
Propriedades do serviço vinculado
As propriedades a seguir têm suporte para o serviço vinculado do MongoDB:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type deve ser definida como: MongoDbV2 | Sim |
| connectionString | Especifique a cadeia de conexão MongoDB, por exemplo, mongodb://[username:password@]host[:port][/[database][?options]]. Confira o manual do MongoDB na cadeia de conexão para obter mais detalhes. Você também pode colocar uma cadeia de conexão no Azure Key Vault. Consulte o artigo Credenciais de armazenamento no Azure Key Vault para saber mais detalhes. |
Sim |
| Banco de Dados | O nome do banco de dados que você deseja criar. | Sim |
| connectVia | O Integration Runtime a ser usado para se conectar ao armazenamento de dados. Saiba mais na seção Pré-requisitos. Se não for especificado, ele usa o Integration Runtime padrão do Azure. | Não |
Exemplo:
{
"name": "MongoDBLinkedService",
"properties": {
"type": "MongoDbV2",
"typeProperties": {
"connectionString": "mongodb://[username:password@]host[:port][/[database][?options]]",
"database": "myDatabase"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definição de conjuntos de dados, consulte Conjuntos de dados e serviços vinculados. As propriedades a seguir têm suporte para o conjunto de dados do MongoDB:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como: MongoDbV2Collection | Sim |
| collectionName | Nome da coleção no banco de dados MongoDB. | Sim |
Exemplo:
{
"name": "MongoDbDataset",
"properties": {
"type": "MongoDbV2Collection",
"typeProperties": {
"collectionName": "<Collection name>"
},
"schema": [],
"linkedServiceName": {
"referenceName": "<MongoDB linked service name>",
"type": "LinkedServiceReference"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte pela fonte e pelo coletor do MongoDB.
MongoDB como fonte
As propriedades a seguir têm suporte na seção source da atividade de cópia:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type da fonte da atividade de cópia deve ser definida como: MongoDbV2Source | Sim |
| filter | Especifica o filtro de seleção usando operadores de consulta. Para retornar todos os documentos em uma coleção, omita esse parâmetro ou passe um documento vazio ({}). | Não |
| cursorMethods.project | Especifica os campos a serem retornados nos documentos para projeção. Para retornar todos os campos nos documentos correspondentes, omita este parâmetro. | Não |
| cursorMethods.sort | Especifica a ordem na qual a consulta retorna documentos correspondentes. Consulte cursor.sort(). | Não |
| cursorMethods.limit | Especifica o número máximo de documentos que o servidor retorna. Consulte cursor.limit(). | Não |
| cursorMethods.skip | Especifica o número de documentos a serem ignorados e de onde o MongoDB começa a retornar resultados. Consulte cursor.skip(). | Não |
| batchSize | Especifica o número de documentos a serem retornados em cada lote da resposta da instância do MongoDB. Na maioria dos casos, modificar o tamanho do lote não afetará o usuário ou o aplicativo. O Cosmos DB limita que cada lote não possa exceder 40 MB de tamanho, que é a soma do tamanho do batchSize dos documentos; portanto, diminua esse valor se o tamanho do documento for grande. | Não (o padrão é 100) |
Dica
Suporte do ADF consumindo o documento BSON em Modo estrito. Verifique se sua consulta de filtro está em Modo estrito em vez do modo Shell. Veja mais descrições no manual do MongoDB.
Exemplo:
"activities":[
{
"name": "CopyFromMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<MongoDB input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "MongoDbV2Source",
"filter": "{datetimeData: {$gte: ISODate(\"2018-12-11T00:00:00.000Z\"),$lt: ISODate(\"2018-12-12T00:00:00.000Z\")}, _id: ObjectId(\"5acd7c3d0000000000000000\") }",
"cursorMethods": {
"project": "{ _id : 1, name : 1, age: 1, datetimeData: 1 }",
"sort": "{ age : 1 }",
"skip": 3,
"limit": 3
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
MongoDB como coletor
As seguintes propriedades são suportadas na seção Copy Activity sink:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | O tipo de propriedade do coletor da atividade de cópia deve ser definido como MongoDbV2Sink. | Sim |
| writeBehavior | Descreve como gravar dados no MongoDB. Valores permitidos são insert e upsert. O comportamento de upsert será substituir o documento se um documento com a mesma _id já existir; caso contrário, insira o documento.Nota: o serviço gera automaticamente uma _id ID para um documento _id se não for especificada uma ID no documento original ou no mapeamento de coluna. Isso significa que, para upsert funcionar conforme esperado, o documento deve ter uma ID. |
No (o padrão é insert) |
| writeBatchSize | A propriedade writeBatchSize controla o tamanho dos documentos que escrevemos em cada lote. Você pode tentar aumentar o valor de writeBatchSize para melhorar o desempenho e diminuir o valor se o tamanho do documento for grande. | Não (o padrão é 10.000) |
| writeBatchTimeout | O tempo de espera para que a operação de inserção em lote seja concluída antes de atingir o tempo limite. O valor permitido é timespan. | Não (o padrão é 30:00:00 - 30 minutos) |
Dica
Para importar documentos JSON como eles estão, consulte a seção importar ou exportar documentos JSON; para copiar de dados em formato tabular, consulte mapeamento de esquema.
Exemplo
"activities":[
{
"name": "CopyToMongoDB",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Document DB output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "MongoDbV2Sink",
"writeBehavior": "upsert"
}
}
}
]
Importar e exportar documentos JSON
Você pode usar esse conector do MongoDB para facilmente:
- Copiar documentos entre duas coleções do MongoDB no estado em que se encontram.
- Importar documentos JSON de várias fontes para o MongoDB, incluindo o Azure Cosmos DB, o Armazenamento de blobs do Azure, o Azure Data Lake Storage e outros repositórios baseados em arquivo compatíveis.
- Exportar documentos JSON de uma coleção do MongoDB para vários repositórios baseados em arquivo.
Para efetuar essa cópia independente de esquema, ignore a seção da "estrutura" (também chamada de esquema) no conjunto de dados e mapeamento de esquema na atividade de cópia.
Mapeamento de esquema
Para copiar dados do MongoDB para o coletor de tabela ou revertido, confira o mapeamento do esquema.
Atualizar o serviço vinculado do MongoDB
Aqui estão as etapas que ajudarão você a atualizar seu serviço vinculado e as consultas relacionadas:
Crie um novo serviço vinculado ao MongoDB e configure-o consultando as Propriedades do serviço vinculado.
Se utilizar consultas no SQL em seus pipelines que se referem ao antigo serviço vinculado do MongoDB, substitua-as pelas consultas equivalentes do MongoDB. Confira na tabela a seguir os exemplos de substituição:
consulta SQL Consulta equivalente do MongoDB SELECT * FROM usersdb.users.find({})SELECT username, age FROM usersdb.users.find({}, {username: 1, age: 1})SELECT username AS User, age AS Age, statusNumber AS Status, CASE WHEN Status = 0 THEN "Pending" CASE WHEN Status = 1 THEN "Finished" ELSE "Unknown" END AS statusEnum LastUpdatedTime + interval '2' hour AS NewLastUpdatedTime FROM usersdb.users.aggregate([{ $project: { _id: 0, User: "$username", Age: "$age", Status: "$statusNumber", statusEnum: { $switch: { branches: [ { case: { $eq: ["$Status", 0] }, then: "Pending" }, { case: { $eq: ["$Status", 1] }, then: "Finished" } ], default: "Unknown" } }, NewLastUpdatedTime: { $add: ["$LastUpdatedTime", 2 * 60 * 60 * 1000] } } }])SELECT employees.name, departments.name AS department_name FROM employees LEFT JOIN departments ON employees.department_id = departments.id;db.employees.aggregate([ { $lookup: { from: "departments", localField: "department_id", foreignField: "_id", as: "department" } }, { $unwind: "$department" }, { $project: { _id: 0, name: 1, department_name: "$department.name" } } ])
Conteúdo relacionado
Para obter uma lista de armazenamentos de dados com suporte como coletores e fontes da atividade de cópia, confira os armazenamentos de dados com suporte.