Transformação de Alteração de linha no fluxo de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Os fluxos de dados estão disponíveis nos pipelines do Azure Data Factory e do Azure Synapse. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for iniciante nas transformações, veja o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
Use a transformação de alteração de linha para definir políticas de inserção, exclusão, atualização e de upsert em linhas. Você pode adicionar condições de um para muitos como expressões. Essas condições devem ser especificadas em ordem de prioridade, já que cada linha é marcada com a política relativa à primeira expressão correspondente. Cada uma dessas condições pode resultar em uma ou mais linhas serem inseridas, atualizadas, excluídas ou introduzidas. Alterar Linha pode produzir as ações DDL e DML no banco de dados.
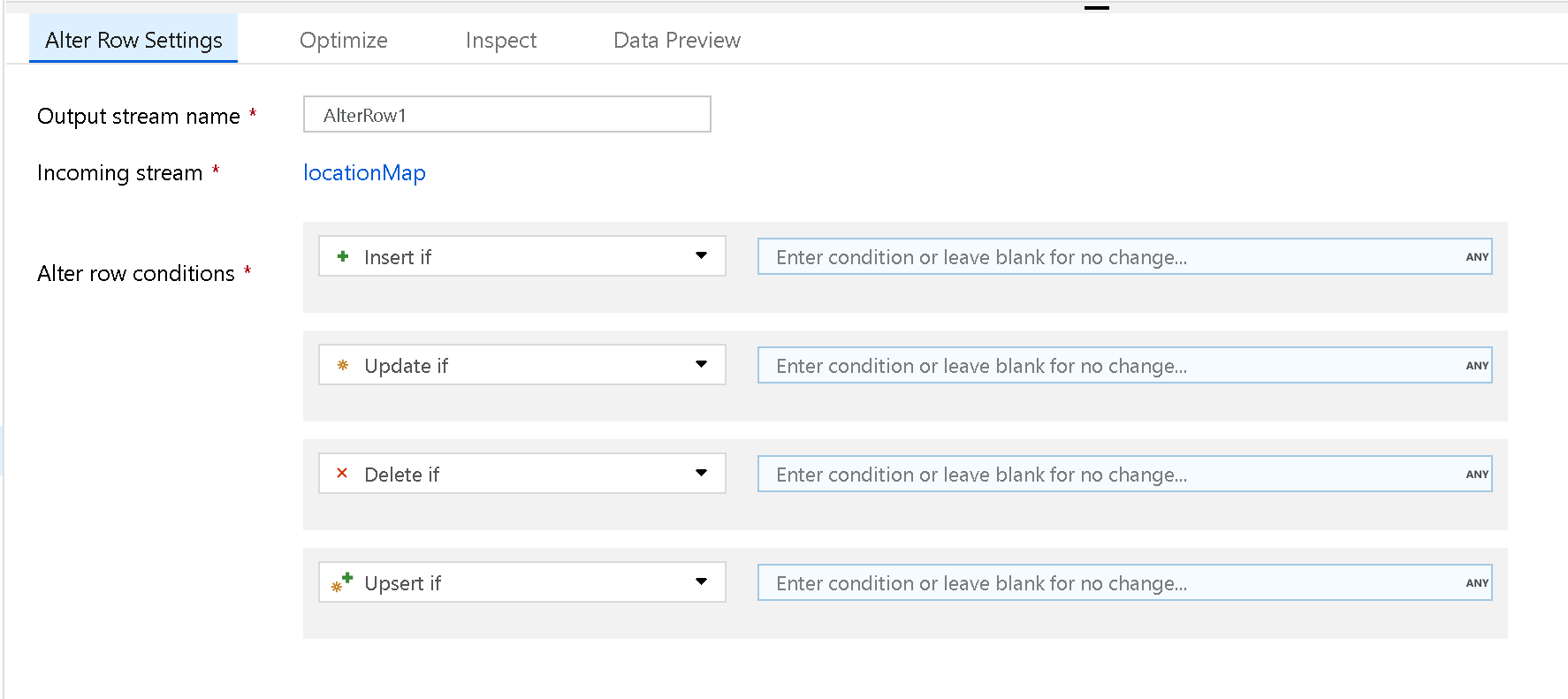
As transformações de alteração de linha funcionarão apenas em coletores de banco de dados, REST ou Azure Cosmos DB em seu fluxo de dados. As ações que você atribui às linhas (inserir, atualizar, excluir, executar upsert) não acontecem durante sessões de depuração. Para aplicar as políticas de alteração de linha nas tabelas do seu banco de dados, execute uma atividade Executar Fluxo de Dados em um pipeline.
Observação
Uma transformação Alterar Linha não é necessária para fluxos de dados da captura de dados de alterações que usam fontes CDC nativas, como SQL Server ou SAP. Nessas instâncias, o ADF detectará automaticamente o marcador de linha, de modo que as políticas Alter Row são desnecessárias.
Especificar uma política de linha padrão
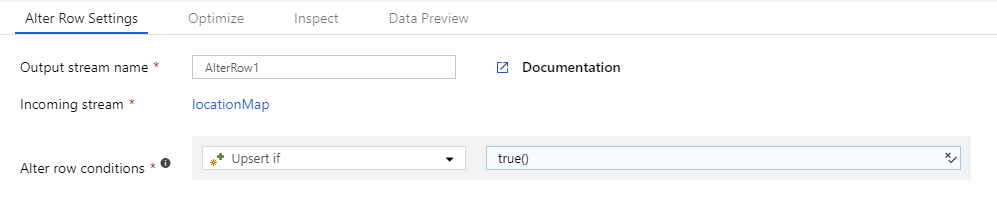
Crie uma transformação de Alteração de Linha e especifique uma política de linha com uma condição de true(). Toda linha que não corresponder a nenhuma das expressões definidas anteriormente é marcada para a política de linha especificada. Por padrão, toda linha que não corresponde a uma expressão condicional é marcada para Insert.
Observação
Para marcar todas as linhas com uma política, você pode criar uma condição para essa política e especificar a condição como true().
Exibir políticas na pré-visualização de dados
Use o modo de depuração para exibir os resultados de suas políticas de alteração de linha no painel de pré-visualização de dados. Uma pré-visualização de dados de uma transformação de alteração de linha não gera ações DDL ou DML em relação ao seu destino.
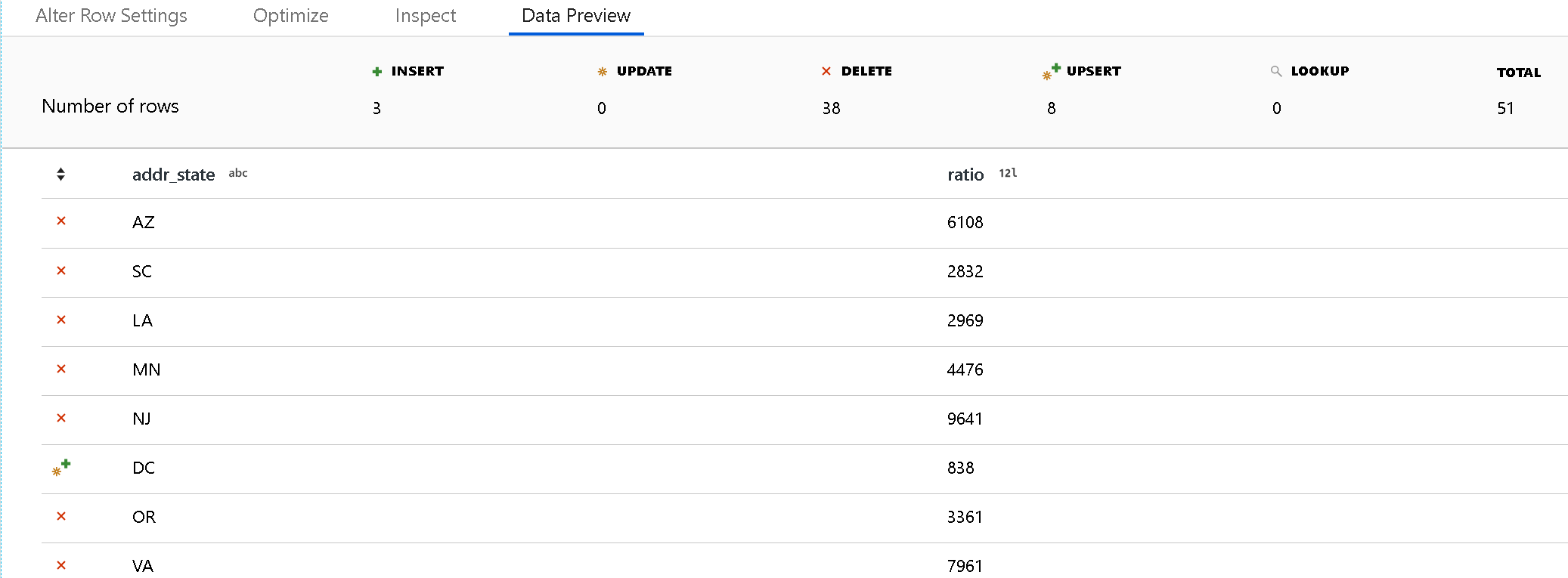
Cada política de alteração de linha tem um ícone que indica se acontecerá uma ação de inserção, atualização, upsert ou exclusão. O cabeçalho superior mostra quantas linhas cada política afeta na pré-visualização.
Permitir políticas de alteração de linha no coletor
Para que as políticas de alteração de linha funcionem, o fluxo de dados deve gravar em um coletor do banco de dados ou do Azure Cosmos DB. Na guia Configurações no coletor, habilite quais políticas de alteração de linha são permitidas para aquele coletor.
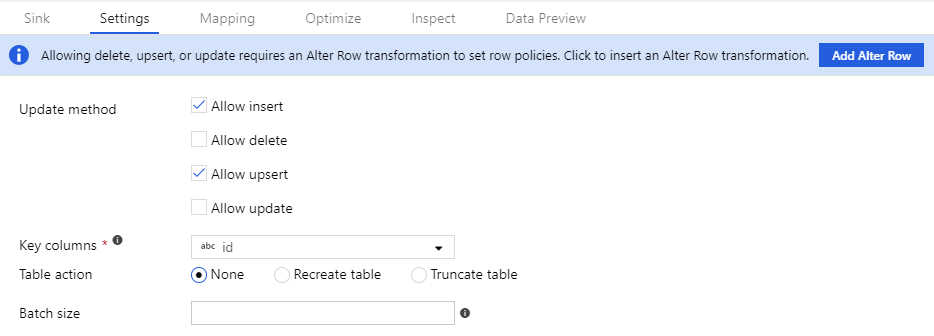
O comportamento padrão é permitir apenas inserções. Para permitir atualizações, upserts ou exclusões, marque a caixa no coletor correspondente a essa condição. Se atualizações, upserts ou exclusões estiverem habilitadas, você deverá especificar quais colunas de chave no coletor devem corresponder.
Observação
Se as inserções, atualizações ou upserts modificarem o esquema da tabela de destino no coletor, o fluxo de dados falhará. Para modificar o esquema de destino em seu banco de dados, escolha Recriar tabela como a ação da tabela. Isso removerá e recriará sua tabela com a nova definição de esquema.
A transformação do coletor requer uma chave única ou uma série de chaves para identificação de linha exclusiva no banco de dados de destino. Para coletores SQL, defina as chaves na guia de configurações do coletor. Para o Azure Cosmos DB, defina a chave de partição nas configurações e também defina o campo do sistema "ID" do Azure Cosmos DB no seu mapeamento de coletor. Para o Azure Cosmos DB, é obrigatório incluir a coluna "ID" do sistema para atualizações, upserts e exclusões.
Mescla e executa upserts com o Banco de Dados SQL do Azure e do Azure Synapse
Há suporte para mesclagens dos Fluxos de Dados entre o pool dos Bancos de Dados SQL do Azure e do banco de dados do Azure Synapse (data warehouse) com a opção upsert.
No entanto, você pode encontrar situações em que o esquema de banco de dados de destino usou a propriedade de identidade nas colunas-chave. O serviço exige que você identifique as chaves usadas para corresponder aos valores de linha para atualizações e upserts. Mas se a coluna de destino tiver a propriedade de identidade definida e você estiver usando a política de upsert, o banco de dados de destino não permitirá que você grave na coluna. Você também pode encontrar erros ao tentar executar upsert na coluna de distribuição de uma tabela distribuída.
Estas são as formas de corrigir isso:
Vá em Configurações de transformação do coletor e defina "Ignorar gravação de colunas de chave". Isso informa ao serviço para não gravar na coluna que você selecionou como o valor-chave para seu mapeamento.
Se essa coluna-chave não for a que está causando o problema para as colunas de identidade, você pode usar a opção pré-processando SQL da transformação do coletor:
SET IDENTITY_INSERT tbl_content ON. Em seguida, desative-a com a propriedade de pós-processamento SQL:SET IDENTITY_INSERT tbl_content OFF.Para o caso da identidade e o da coluna de distribuição, você pode alternar a lógica de Upsert para usar uma condição de atualização separada e uma condição de inserção separada usando uma transformação de Divisão Condicional. Dessa forma, você pode definir o mapeamento no caminho de atualização para ignorar o mapeamento da coluna de chave.
Script de fluxo de dados
Sintaxe
<incomingStream>
alterRow(
insertIf(<condition>?),
updateIf(<condition>?),
deleteIf(<condition>?),
upsertIf(<condition>?),
) ~> <alterRowTransformationName>
Exemplo
O exemplo abaixo é uma transformação de alteração de linha chamada CleanData que usa um fluxo de entrada SpecifyUpsertConditions e cria três condições de alteração de linha. Na transformação anterior, uma coluna chamada alterRowCondition é calculada que determina se uma linha é inserida, atualizada ou excluída no banco de dados. Se o valor da coluna tiver um valor de cadeia de caracteres correspondente à regra de alteração de linha, essa política será atribuída.
Na interface do usuário, essa transformação é semelhante à imagem abaixo:
O script de fluxo de dados para essa transformação está no trecho de código abaixo:
SpecifyUpsertConditions alterRow(insertIf(alterRowCondition == 'insert'),
updateIf(alterRowCondition == 'update'),
deleteIf(alterRowCondition == 'delete')) ~> AlterRow
Conteúdo relacionado
Após a transformação de alteração de linha, talvez você queira coletar seus dados em um armazenamento de dados de destino.