Formato Common Data Model em pipelines do Azure Data Factory e do Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
O sistema de metadados do Common Data Model (CDM) possibilita que os dados e o significado deles sejam facilmente compartilhados entre aplicativos e processos de negócios. Para saber mais, confira a visão geral do Common Data Model.
Nos pipelines do Azure Data Factory e do Synapse, os usuários podem transformar dados de entidades CDM no formulário model.json e no de manifesto armazenado em Azure data Lake Store Gen2 (ADLS Gen2) usando fluxos de dados de mapeamento. Você também pode coletar dados no formato CDM usando referências de entidade CDM que param os dados no formato CSV ou parquet em pastas particionadas.
Propriedades do fluxo de dados de mapeamento
O Common Data Model está disponível como um conjunto de dados embutido no fluxos de dados de mapeamento como uma fonte e um coletor.
Observação
Ao escrever entidades CDM, você deve ter uma definição de entidade CDM (esquema de metadados) existente já definida para usar como referência. O coletor de fluxo de dados do lê esse arquivo de entidade CDM e importa o esquema no coletor para o mapeamento de campos.
Propriedades da fonte
A tabela abaixo lista as propriedades com suporte de uma origem CDM. Você pode editar essas propriedades na guia Opções de origem.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Formatar | O formato deve ser cdm |
sim | cdm |
format |
| Formato de metadados | Onde a referência de entidade para os dados está localizada. Se estiver usando o CDM versão 1.0, escolha manifesto. Se estiver usando uma versão do CDM anterior a 1.0, escolha model.json. | Sim | 'manifest' ou 'model' |
manifestType |
| Local raiz: contêiner | Nome do contêiner da pasta CDM | sim | String | fileSystem |
| Local raiz: caminho da pasta | Local da pasta raiz da pasta CDM | sim | String | folderPath |
| Arquivo de manifesto: caminho da entidade | Caminho da pasta da entidade na pasta raiz | não | String | entityPath |
| Arquivo de manifesto: nome do manifesto | Nome do arquivo de manifesto. O valor padrão é “default”. | Não | String | manifestName |
| Filtrar pela última modificação | Escolher filtrar arquivos com base na última alteração | não | Carimbo de data/hora | modifiedAfter modifiedBefore |
| Serviço vinculado ao esquema | O serviço vinculado em que o corpus está localizado | sim, se estiver usando o manifesto | 'adlsgen2' ou 'github' |
corpusStore |
| Contêiner de referência de entidade | O corpus do contêiner está em | sim, se estiver usando manifesto e corpus ADLS Gen2 | String | adlsgen2_fileSystem |
| Repositório de referência de entidade | Nome do repositório GitHub | sim, se estiver usando manifesto e corpus no GitHub | String | github_repository |
| Ramificação de referência de entidade | Ramificação do repositório GitHub | sim, se estiver usando manifesto e corpus no GitHub | String | github_branch |
| Pasta corpus | o local raiz do corpus | sim, se estiver usando o manifesto | String | corpusPath |
| Entidade corpus | Caminho para referência de entidade | sim | String | entidade |
| Permitir nenhum arquivo encontrado | Se for true, um erro não será gerado caso nenhum arquivo seja encontrado | não | true ou false |
ignoreNoFilesFound |
Ao selecionar "referência de entidade" nas transformações de origem e de coletor, você pode selecionar dentre essas três opções para o local da referência de sua entidade:
- Local usa a entidade definida no arquivo de manifesto que já está sendo usada pelo serviço
- Personalizado pedirá que você aponte para um arquivo de manifesto de entidade diferente do arquivo de manifesto que o serviço está usando
- Padrão usará uma referência de entidade da biblioteca padrão de entidades CDM mantidas no
GitHub.
Configurações do coletor
- Aponte para o arquivo de referência de entidade CDM que contém a definição da entidade que você deseja escrever.
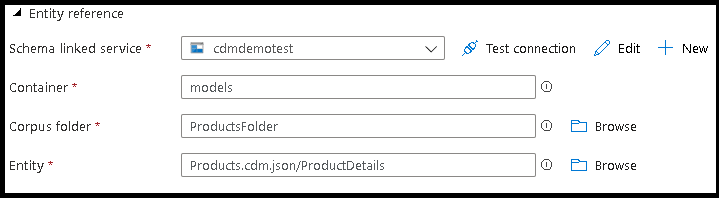
- Defina o caminho da partição e o formato dos arquivos de saída que você deseja que o serviço use para escrever as entidades.
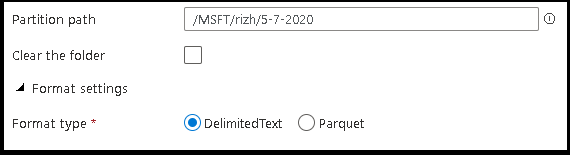
- Defina o local do arquivo de saída, assim como o local e o nome do arquivo de manifesto.

Importar esquema
O CDM só está disponível como um conjunto de dados embutido e, por padrão, não tem um esquema associado. Para obter metadados de coluna, clique no botão Importar esquema na guia Projeção. Isso permitirá que você referencie os nomes de coluna e os tipos de dados especificados pelo corpus. Para importar o esquema, uma sessão de depuração de fluxo de dados deve estar ativa e você deve ter um arquivo de definição de entidade CDM existente para o qual apontar.
Ao mapear colunas de fluxo de dados para propriedades de entidade na transformação do coletor, clique na guia "mapeamento" e selecione "importar esquema". O serviço lê a referência de entidade para a qual você apontou nas opções de coletor, permitindo que você mapeie para o esquema CDM de destino.
Observação
Ao usar o tipo de origem model.json originado de fluxos de dados Power BI ou Power Platform, você pode encontrar erros "caminho de corpus é nulo ou vazio" da transformação de origem. Isso provavelmente ocorre devido a problemas de formatação do caminho de local da partição no arquivo model.json. Para corrigir isso, siga estas etapas:
- Abra o arquivo model.json em um editor de texto
- Encontre a propriedade partitions.Location
- Altere "blob.core.windows.net" para "dfs.core.windows.net"
- Corrija qualquer codificação "%2F" na URL para "/"
- Se estiver usando fluxos de dados do ADF, os caracteres especiais no caminho do arquivo de partição deverão ser substituídos por valores alfanuméricos ou alterne para Fluxos de Dados do Azure Synapse
Exemplo de script de fluxo de dados de origem do CDM
source(output(
ProductSizeId as integer,
ProductColor as integer,
CustomerId as string,
Note as string,
LastModifiedDate as timestamp
),
allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
manifestType: 'manifest',
manifestName: 'ProductManifest',
entityPath: 'Product',
corpusPath: 'Products',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
folderPath: 'ProductData',
fileSystem: 'data') ~> CDMSource
Propriedades do coletor
A tabela abaixo lista as propriedades com suporte de um coletor do CDM. Você pode editar essas propriedades na guia Configurações.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Formatar | O formato deve ser cdm |
sim | cdm |
format |
| Local raiz: contêiner | Nome do contêiner da pasta CDM | sim | String | fileSystem |
| Local raiz: caminho da pasta | Local da pasta raiz da pasta CDM | sim | String | folderPath |
| Arquivo de manifesto: caminho da entidade | Caminho da pasta da entidade na pasta raiz | não | String | entityPath |
| Arquivo de manifesto: nome do manifesto | Nome do arquivo de manifesto. O valor padrão é “default”. | Não | String | manifestName |
| Serviço vinculado ao esquema | O serviço vinculado em que o corpus está localizado | sim | 'adlsgen2' ou 'github' |
corpusStore |
| Contêiner de referência de entidade | O corpus do contêiner está em | sim, se corpus em ADLS Gen2 | String | adlsgen2_fileSystem |
| Repositório de referência de entidade | Nome do repositório GitHub | sim, se corpus no GitHub | String | github_repository |
| Ramificação de referência de entidade | Ramificação do repositório GitHub | sim, se corpus no GitHub | String | github_branch |
| Pasta corpus | o local raiz do corpus | sim | String | corpusPath |
| Entidade corpus | Caminho para referência de entidade | sim | String | entidade |
| Caminho da partição | Local onde a partição será gravada | não | String | partitionPath |
| Limpe a pasta | Se a pasta de destino for limpa antes da gravação | não | true ou false |
truncate |
| Tipo de formato | Escolha especificar o formato parquet | não | parquet se especificado |
subformatação |
| Delimitador de coluna | Se estiver escrevendo em DelimitedText, como delimitar colunas | sim, se estiver escrevendo em DelimitedText | String | columnDelimiter |
| Primeira linha como cabeçalho | Se estiver usando DelimitedText, se os nomes das colunas serão adicionados como um cabeçalho | não | true ou false |
columnNamesAsHeader |
Exemplo de script de fluxo de dados do sink do CDM
O script de fluxo de dados associado é:
CDMSource sink(allowSchemaDrift: true,
validateSchema: false,
entity: 'Product.cdm.json/Product',
format: 'cdm',
entityPath: 'ProductSize',
manifestName: 'ProductSizeManifest',
corpusPath: 'Products',
partitionPath: 'adf',
folderPath: 'ProductSizeData',
fileSystem: 'cdm',
subformat: 'parquet',
corpusStore: 'adlsgen2',
adlsgen2_fileSystem: 'models',
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CDMSink
Conteúdo relacionado
Crie uma transformação de origem no fluxo de dados de mapeamento.