Formato de texto delimitado no Azure Data Factory e no Azure Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Siga este artigo quando quiser analisar os arquivos de texto delimitados ou gravar os dados em um formato de texto delimitado.
Há suporte para o formato de texto delimitado para os seguintes conectores:
- Amazon S3
- Armazenamento compatível com Amazon S3
- Blob do Azure
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2
- Arquivos do Azure
- Sistema de Arquivos
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle Cloud Storage
- SFTP
Propriedades do conjunto de dados
Para obter uma lista completa das seções e propriedades disponíveis para definir os conjuntos de dados, confira o artigo sobre Conjuntos de Dados. Esta seção fornece uma lista das propriedades com suporte pelo conjunto de dados de texto delimitado.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade type do conjunto de dados deve ser definida como DelimitedText. | Sim |
| local | Configurações de local dos arquivos. Cada conector baseado em arquivo tem seu próprio tipo de local e propriedades com suporte em location. |
Sim |
| columnDelimiter | O(s) caractere(s) usado(s) para separar as colunas em um arquivo. O valor padrão é vírgula ,. Quando o delimitador de coluna é definido como cadeia de caracteres vazia, o que significa que não há delimitador, a linha inteira é tomada como uma única coluna.Atualmente, o delimitador de colunas como cadeia de caracteres vazia tem suporte apenas para o fluxo de dados de mapeamento, e não para a atividade Copy. |
Não |
| rowDelimiter | Para a atividade Copy, o caractere individual ou "\r\n" usado para separar as linhas em um arquivo. O valor padrão é um dos seguintes valores na leitura: ["\r\n", "\r" e "\n"] e na gravação "\r\n". "\r\n" só tem suporte no comando de cópia. Para o Fluxo de dados de mapeamento, o único ou duplo caractere usado para separar as linhas em um arquivo. O valor padrão é um dos seguintes valores na leitura: ["\r\n", "\r" e "\n"] e na gravação "\n". Quando o delimitador de linha é definido como sem delimitador (cadeia de caracteres vazia), o delimitador de coluna também deve ser definido como sem delimitador (cadeia de caracteres vazia), o que significa tratar todo o conteúdo como um único valor. Atualmente, o delimitador de linha como cadeia de caracteres vazia tem suporte apenas para o fluxo de dados de mapeamento e não para a atividade Copy. |
Não |
| quoteChar | O caractere individual para citar valores de coluna se ele contiver delimitador de coluna. O valor padrão é aspas duplas ". Quando quoteChar é definido como cadeia de caracteres vazia, isso significa que não há nenhum caractere de aspas e o valor da coluna não está entre aspas e escapeChar é usado para o escape do delimitador de coluna e ele mesmo. |
Não |
| escapeChar | O caractere individual para o escape das aspas dentro de um valor entre aspas. O valor padrão é barra invertida \ . Quando escapeChar é definido como cadeia de caracteres vazia, o quoteChar também deve ser definido como cadeia de caracteres vazia; nesse caso, verifique se todos os valores de coluna não contêm delimitadores. |
Não |
| firstRowAsHeader | Especifica se deve tratar/transformar a primeira linha como linha de cabeçalho com nomes de colunas. Os valores permitidos são true e false (padrão). Quando a primeira linha como cabeçalho é falsa, observe que a visualização de dados da interface do usuário e a saída da atividade de pesquisa geram automaticamente nomes de coluna como Prop_{n} (a partir de 0), a atividade de cópia requer mapeamento explícito da origem para o coletor e localiza colunas por ordinal (a partir de 1) e o fluxo de dados de mapeamento lista e localiza colunas com o nome Column_{n} (a partir de 1). |
Não |
| nullValue | Especifica a representação de cadeia de caracteres do valor nulo. O valor padrão pode ser uma cadeia de caracteres vazia. |
Não |
| encodingName | O tipo de codificação usado para ler/gravar arquivos de teste. Os valores permitidos são os seguintes: "UTF-8","UTF-8 without BOM", "UTF-16", "UTF-16BE", "UTF-32", "UTF-32BE", "US-ASCII", "UTF-7", "BIG5", "EUC-JP", "EUC-KR", "GB2312", "GB18030", "JOHAB", "SHIFT-JIS", "CP875", "CP866", "IBM00858", "IBM037", "IBM273", "IBM437", "IBM500", "IBM737", "IBM775", "IBM850", "IBM852", "IBM855", "IBM857", "IBM860", "IBM861", "IBM863", "IBM864", "IBM865", "IBM869", "IBM870", "IBM01140", "IBM01141", "IBM01142", "IBM01143", "IBM01144", "IBM01145", "IBM01146", "IBM01147", "IBM01148", "IBM01149", "ISO-2022-JP", "ISO-2022-KR", "ISO-8859-1", "ISO-8859-2", "ISO-8859-3", "ISO-8859-4", "ISO-8859-5", "ISO-8859-6", "ISO-8859-7", "ISO-8859-8", "ISO-8859-9", "ISO-8859-13", "ISO-8859-15", "WINDOWS-874", "WINDOWS-1250", "WINDOWS-1251", "WINDOWS-1252", "WINDOWS-1253", "WINDOWS-1254", "WINDOWS-1255", "WINDOWS-1256", "WINDOWS-1257", "WINDOWS-1258". Observe que o fluxo de dados de mapeamento não dá suporte à codificação UTF-7. Observe que o fluxo de dados de mapeamento não dá suporte para a codificação UTF-8 com a Marca de Ordem de Byte (BOM). |
Não |
| compressionCodec | O codec de compactação usado para ler/gravar arquivos de texto. Os valores permitidos são bzip2, gzip, deflate, ZipDeflate, TarGzip, tar, snappyou lz4. O padrão é não compactado. Observação a atividade Copy atualmente não dá suporte a "snappy" e "lz4" e o fluxo de dados de mapeamento não dá suporte a "ZipDeflate", "TarGzip" e "Tar". Observação ao usar a atividade Copy para descompactar arquivos ZipDeflate/TarGzip/Tar e gravar no armazenamento de dados de coletor baseado em arquivo, por padrão os arquivos são extraídos para a pasta: <path specified in dataset>/<folder named as source compressed file>/, use preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder na origem da atividade de cópia para controlar se deseja preservar o nome dos arquivos compactados como estrutura de pastas. |
Não |
| compressionLevel | A taxa de compactação. Os valores permitidos são Ideal ou Mais rápida. - Mais rápida: a operação de compactação deve ser concluída o mais rápido possível, mesmo se o arquivo resultante não for compactado da maneira ideal. - Ideal: a operação de compactação deve ser concluída da maneira ideal, mesmo se a operação demorar mais tempo para ser concluída. Para saber mais, veja o tópico Nível de compactação . |
Não |
Veja abaixo um exemplo de conjunto de dados de texto delimitado no Armazenamento de Blobs do Azure:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriedades da atividade de cópia
Para obter uma lista completa das seções e propriedades disponíveis para definir atividades, confia o artigo Pipelines. Esta seção fornece uma lista das propriedades com suporte pela fonte e coletor de texto delimitado.
Texto delimitado como fonte
As propriedades a seguir têm suporte na seção de *origem* da atividade de cópia.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade Type da fonte da atividade de cópia deve ser definida como DelimitedTextSource. | Sim |
| formatSettings | Um grupo de propriedades. Consulte a tabela Configurações de leitura de texto delimitado abaixo. | Não |
| storeSettings | Um grupo de propriedades sobre como ler dados de um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de leitura com suporte em storeSettings. |
Não |
Configurações de leitura de texto delimitado com suporte em formatSettings:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | O tipo de formatSettings deve ser definido como DelimitedTextReadSettings. | Sim |
| skipLineCount | Indica o número de linhas não vazias a serem ignoradas ao ler dados de arquivos de entrada. Se skipLineCount e firstRowAsHeader forem especificados, primeiro as linhas serão ignoradas e, em seguida, as informações de cabeçalho serão lidas no arquivo de entrada. |
Não |
| compressionProperties | Um grupo de propriedades sobre como descompactar dados para um determinado codec de compactação. | Não |
| preserveZipFileNameAsFolder (em compressionProperties->type como ZipDeflateReadSettings) |
Aplica-se quando o conjunto de dados de entrada é configurado com compactação ZipDeflate. Indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pastas durante a cópia. • Quando definido como verdadeiro (padrão) , o serviço grava arquivos descompactados em <path specified in dataset>/<folder named as source zip file>/.• Quando definido como falso, o serviço grava arquivos descompactados diretamente em <path specified in dataset>. Verifique se não há nomes de arquivo duplicados nos arquivos zip de origem diferentes para evitar a corrida ou comportamento inesperado. |
Não |
| preserveCompressionFileNameAsFolder (em compressionProperties->type como TarGZipReadSettings ou TarReadSettings) |
Aplica-se quando o conjunto de dados de entrada é configurado com compactação TarGzip/Tar. Indica se o nome do arquivo zip de origem deve ser preservado como estrutura de pastas durante a cópia. • Quando definido como verdadeiro (padrão) , o serviço grava arquivos descompactados em <path specified in dataset>/<folder named as source compressed file>/. • Quando definido como falso, o serviço grava arquivos descompactados diretamente em <path specified in dataset>. Verifique se não há nomes de arquivo duplicados nos arquivos de origem diferentes para evitar a corrida ou comportamento inesperado. |
Não |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
Texto delimitado como coletor
As propriedades a seguir têm suporte na seção do *coletor* da atividade de cópia.
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | A propriedade Type da fonte da atividade de cópia deve ser definida como DelimitedTextSink. | Sim |
| formatSettings | Um grupo de propriedades. Consulte a tabela Configurações de gravação de texto delimitado abaixo. | Não |
| storeSettings | Um grupo de propriedades sobre como gravar dados em um armazenamento de dados. Cada conector baseado em arquivo tem suas próprias configurações de gravação com suporte em storeSettings. |
Não |
Configurações de gravação de texto delimitado com suporte em formatSettings:
| Propriedade | Descrição | Obrigatório |
|---|---|---|
| type | O tipo de formatSettings deve ser definido como DelimitedTextWriteSettings. | Sim |
| fileExtension | A extensão de arquivo usada para nomear os arquivos de saída, por exemplo, .csv, .txt. Ele deve ser especificado quando o fileName não for especificado no conjunto de dados DelimitedText de saída. Quando o nome do arquivo for configurado no conjunto de dados de saída, ele será usado como o nome do arquivo do coletor e a configuração da extensão do arquivo será ignorada. |
Sim, quando o nome do arquivo não é especificado no conjunto de resultados de saída |
| maxRowsPerFile | Ao gravar dados em uma pasta, você pode optar por gravar em vários arquivos e especificar o máximo de linhas por arquivo. | Não |
| fileNamePrefix | Aplicável quando maxRowsPerFile for configurado.Especifique o prefixo do nome do arquivo ao gravar dados em vários arquivos, resultando neste padrão: <fileNamePrefix>_00000.<fileExtension>. Se não for especificado, o prefixo de nome de arquivo será gerado automaticamente. Essa propriedade não se aplica quando a fonte é um armazenamento baseado em arquivo ou armazenamento de dados habilitado para opção de partição. |
Não |
Mapeamento de propriedades de fluxo de dados
Nos fluxos de dados de mapeamento, você pode fazer leituras e gravações em formato de texto delimitado nos seguintes armazenamentos de dados: Armazenamento de Blobs do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2 e SFTP. Além disso, você pode ler o formato de texto delimitado no Amazon S3.
Conjunto de dados embutido
Os fluxos de dados de mapeamento dão suporte a "conjuntos de dados embutidos" como uma opção para definir a origem e o coletor. Um conjunto de dados delimitado embutido é definido diretamente dentro de suas transformações de origem e coletor e não é compartilhado fora do fluxo de dados definido. Ele é útil para parametrizar as propriedades do conjunto de dados diretamente dentro do fluxo de dados e pode se beneficiar de um melhor desempenho em relação aos conjuntos de dados compartilhados do ADF.
Ao ler um grande número de pastas e arquivos de origem, você pode melhorar o desempenho da descoberta de arquivos de fluxo de dados definindo a opção "Esquema projetado pelo usuário" dentro da Projeção | Caixa de diálogo opções de esquema. Essa opção desativa a descoberta automática de esquema padrão do ADF e melhora muito o desempenho da descoberta de arquivos. Antes de definir essa opção, importe a projeção para que o ADF tenha um esquema existente para projeção. Essa opção não funciona com descompasso de esquema.
Propriedades da fonte
A tabela abaixo lista as propriedades com suporte de uma fonte de texto delimitado. Você pode editar essas propriedades na guia Opções de origem.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Caminhos curinga | Todos os arquivos correspondentes ao caminho curinga serão processados. Substitui a pasta e o caminho do arquivo definido no conjunto de dados. | não | String[] | wildcardPaths |
| Caminho raiz da partição | Para dados de arquivo particionados, é possível inserir um caminho raiz de partição para ler pastas particionadas como colunas | não | String | partitionRootPath |
| Lista de arquivos | Se sua fonte estiver apontando para um arquivo de texto que lista os arquivos a serem processados | não | true ou false |
fileList |
| Linhas multilinha | O arquivo de origem contém linhas que abrangem várias linhas. Os valores de multilinha devem estar entre aspas. | não true ou false |
multiLineRow | |
| Coluna para armazenar o nome do arquivo | Criar uma nova coluna com o nome e o caminho do arquivo de origem | não | String | rowUrlColumn |
| Após a conclusão | Exclua ou mova os arquivos após o processamento. O caminho do arquivo inicia a partir da raiz do contêiner | não | Excluir: true ou false Mover ['<from>', '<to>'] |
purgeFiles moveFiles |
| Filtrar pela última modificação | Escolher filtrar arquivos com base na última alteração | não | Carimbo de data/hora | modifiedAfter modifiedBefore |
| Permitir nenhum arquivo encontrado | Se for true, um erro não será gerado caso nenhum arquivo seja encontrado | não | true ou false |
ignoreNoFilesFound |
| Máximo de colunas | O valor padrão é 20480. Personalizar esse valor quando o número da coluna for superior a 20480 | não | Integer | maxColumns |
Observação
O suporte a fontes de fluxo de dados para a lista de arquivos é limitado a 1024 entradas no arquivo. Para incluir mais arquivos, use curingas na lista de arquivos.
Exemplo de fonte
A imagem abaixo é um exemplo de uma configuração de fonte de texto delimitado nos fluxos de dados de mapeamento.
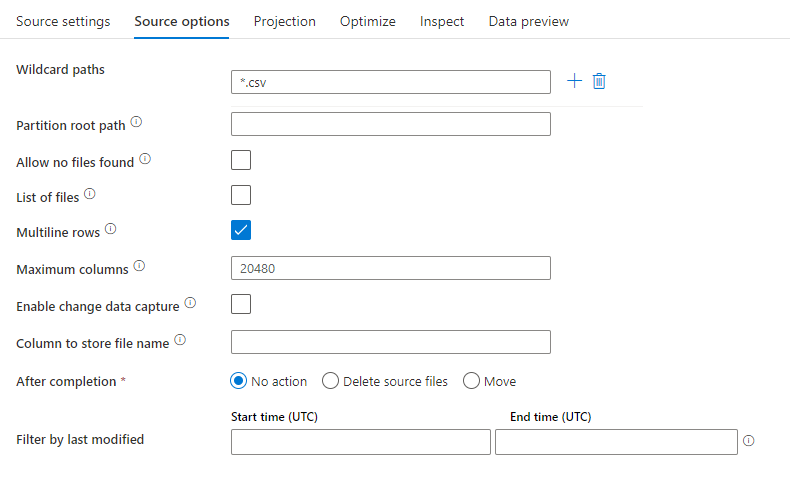
O script de fluxo de dados associado é:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
Observação
As fontes de fluxo de dados dão suporte a um conjunto limitado de recurso de curinga no Linux que é compatível com sistemas de arquivos do Hadoop
Propriedades do coletor
A tabela abaixo lista as propriedades com suporte de um coletor de texto delimitado. Você pode editar essas propriedades na guia Configurações.
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script do Fluxo de Dados |
|---|---|---|---|---|
| Limpe a pasta | Se a pasta de destino for limpa antes da gravação | não | true ou false |
truncate |
| Opção do nome do arquivo | O formato de nomenclatura dos dados gravados. Por padrão, um arquivo por partição no formato part-#####-tid-<guid> |
não | Padrão: cadeia de caracteres Por partição: cadeia de caracteres [] Nomear arquivo como dados da coluna: Cadeia de caracteres Saída para arquivo único: ['<fileName>'] Nomear pasta como dados da coluna: Cadeia de caracteres |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| Citar tudo | Colocar todos os valores entre aspas | não | true ou false |
quoteAll |
| Cabeçalho | Adicionar os cabeçalhos de cliente aos arquivos de saída | não | [<string array>] |
header |
Exemplo de coletor
A imagem abaixo é um exemplo de uma configuração de coletor de texto delimitado nos fluxos de dados de mapeamento.
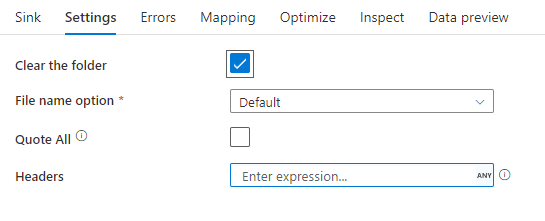
O script de fluxo de dados associado é:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
Conectores e formatos relacionados
Aqui estão alguns conectores e formatos comuns relacionados ao formato de texto delimitado:
- Armazenamento de Blobs do Azure
- Formato binário
- Dataverse
- Formato delta
- Formato do Excel
- Sistema de Arquivos
- FTP
- HTTP
- Formato JSON
- Formato Parquet