Recursos e terminologia em Hubs de Eventos do Azure
Os Hubs de Evento do Azure é um serviço de processamento de evento escalonável que recebe e processa grandes volumes de eventos e dados, com baixa latência e alta confiabilidade. Para obter uma visão geral de alto nível do serviço, veja O que são Hubs de Eventos do Azure?.
Este artigo se baseia nas informações do artigo de visão geral e fornece detalhes técnicos e de implementação sobre recursos e componentes dos Hubs de Eventos.
Namespace
Um namespace dos Hubs de Eventos é um contêiner de gerenciamento para os hubs de eventos (ou tópicos, na linguagem do Kafka). Ele fornece pontos de extremidade de rede integrados ao DNS e uma variedade de recursos de controle de acesso e gerenciamento de integração de rede, como filtragem de IP, ponto de extremidade de serviço de rede virtuale Link Privado.

Partições
Os Hubs de Eventos organizam sequências de eventos enviados a um hub de eventos em uma ou mais partições. À medida que novos eventos chegam, eles são adicionados ao final dessa sequência.

Uma partição pode ser considerada como um registro de confirmação. As partições contêm dados de evento que contêm as seguintes informações:
- Corpo do evento
- Recipiente de propriedades definido pelo usuário que descreve o evento
- Metadados como o deslocamento na partição, o número na sequência de fluxo
- Carimbo de data/hora do lado do serviço no qual foi aceito

Vantagens do uso de partições
Os Hubs de Eventos são projetados para ajudar no processamento de grandes volumes de eventos, e o particionamento ajuda com isso de duas maneiras:
- Embora os Hubs de Eventos sejam um serviço de PaaS, há uma realidade física oculta. A manutenção de um log que preserva a ordem dos eventos requer que esses eventos estejam sendo mantidos juntos no armazenamento subjacente e em suas réplicas e isso resulta em um teto de taxa de transferência para esse log. O particionamento permite que vários logs paralelos sejam usados para o mesmo hub de eventos, multiplicando, portanto, a capacidade de taxa de transferência de E/S (entrada-saída) bruta disponível.
- Seus aplicativos precisam conseguir acompanhar o processamento do volume de eventos que estão sendo enviados para um hub de eventos. Ela pode ser complexa e exigir uma capacidade de processamento paralelo, substancial e de expansão. A capacidade de um só processo de lidar com os eventos é limitada. Portanto, é necessário ter vários processos. As partições são como a sua solução alimenta esses processos, garantindo, ainda, que cada evento tenha um proprietário de processamento claro.
Número of partições
O número de partições é especificado no momento da criação de um hub de eventos. Ela deve estar entre um e o número máximo de partições permitido para cada tipo de preço. Para obter o limite de contagem de partições para cada camada, confira este artigo.
Recomendamos que você escolha, pelo menos, o máximo de partições que deverão ser necessárias durante o pico de carga do seu aplicativo para esse hub de eventos específico. Quanto às camadas que não sejam as camadas premium e dedicada, não é possível alterar a contagem das partições de um hub de eventos após sua criação. Quanto a um hub de eventos em uma camada premium ou dedicada, você pode aumentar a contagem das partições após sua criação, mas não pode reduzi-las. A distribuição dos fluxos entre as partições será alterada quando isso for feito, pois o mapeamento das chaves de partição para as partições é alterado, por isso, você deve se esforçar para evitar essas alterações se a ordem relativa dos eventos for importante para o seu aplicativo.
Definir o número de partições com o valor máximo permitido é tentador, mas sempre tenha em mente que os fluxos de eventos precisam ser estruturados de um jeito que você possa tirar proveito de várias partições. Se você precisar de preservação absoluta da ordem em todos os eventos ou apenas em alguns subfluxos, talvez não consiga aproveitar muitas partições. Além disso, muitas partições tornam o lado de processamento mais complexo.
Quando se trata de preço, o número de partições existentes em um hub de eventos não é relevante. Isso depende do número de unidades de preço – TUs (unidades de produtividade) da camada standard, PUs (unidades de processamento) da camada premium e CUs (unidades de capacidade) da camada dedicada – do namespace ou do cluster dedicado. Por exemplo, um hub de eventos da camada standard com 32 partições ou com uma partição incorre exatamente no mesmo custo quando o namespace é definido para uma capacidade de TU. Além disso, é possível escalar as TUs ou as PUs no namespace ou as CUs do cluster dedicado independentemente da contagem de partições.
Como a partição é um mecanismo de organização de dados que permite publicar e consumir dados de maneira paralela. Recomendamos que você equilibre as unidades de dimensionamento (unidades de produtividade para a camada padrão, unidades de processamento para a camada Premium ou unidades de capacidade para a camada dedicada) e as partições para obter o dimensionamento ideal. Em geral, recomendamos uma taxa de transferência máxima de 1 MB/s por partição. Portanto, uma regra geral para calcular o número de partições seria dividir a taxa de transferência máxima esperada por 1 MB/s. Por exemplo, se o seu caso de uso exigir 20 MB/s, recomendamos que você escolha pelo menos 20 partições para obter a taxa de transferência ideal.
Contudo, se você tiver um modelo em que seu aplicativo tenha afinidade com uma partição específica, aumentar o número de partições não será benéfico. Para saber mais, confira disponibilidade e consistência.
Mapeamento de eventos para partições
Você pode usar uma chave de partição para mapear dados de evento de entrada em partições específicas para fins de organização de dados. A chave de partição é um valor fornecido pelo remetente passado para um hub de eventos. Ele é processado por meio de uma função de hash estático, que cria a atribuição de partição. Se você não especificar uma chave de partição ao publicar um evento, uma atribuição de round robin será usada.
O editor de eventos só está ciente da sua chave de partição, não da partição para a qual os eventos são publicados. Essa desassociação de chave e partição isenta o remetente da necessidade de saber muito sobre o processamento de downstream. Uma identidade por dispositivo ou exclusiva do usuário é uma boa chave de partição, mas outros atributos, como geografia, também podem ser usados para agrupar eventos relacionados em uma única partição.
A especificação de uma chave de partição permite manter eventos relacionados juntos na mesma partição e na ordem exata em que eles chegaram. A chave de partição é uma cadeia de caracteres derivada do contexto do aplicativo e identifica a relação entre os eventos. Uma sequência de eventos identificados por uma chave de partição é um fluxo. Uma partição é um repositório de logs multiplexado para muitos desses fluxos.
Observação
Embora você possa enviar eventos diretamente para as partições, não recomendamos isso, especialmente quando a alta disponibilidade é importante para você. Isso faz o downgrade da disponibilidade de um hub de eventos para o nível de partição. Para obter mais informações, confira Disponibilidade e consistência.
Editores de eventos
Qualquer entidade que envie dados para um Hub de Eventos é um editor de eventos (sinônimo de produtor de eventos). Os editores de eventos podem publicar eventos usando HTTPS, AMQP 1.0 ou o protocolo Kafka. Os editores de eventos usam a autorização baseada no Microsoft Entra ID com tokens JWT emitidos por OAuth2 ou um token SAS (assinatura de acesso compartilhado) específico do Hub de Eventos para obter acesso à publicação.
Você pode publicar um evento por meio do AMQP 1.0, do protocolo Kafka ou de HTTPS. Além da API REST, o serviço Hubs de Eventos fornece bibliotecas de cliente .NET, Java, Python, JavaScript e Go para publicar eventos em um hub de eventos. Para outras plataformas e runtimes, você pode usar qualquer cliente AMQP 1.0, como o Apache Qpid.
A opção de usar AMQP ou HTTPS é específica para o cenário de uso. O AMQP requer o estabelecimento de um soquete bidirecional persistente, além do TLS (segurança de nível de transporte) ou SSL/TLS. O AMQP tem custos de rede mais altos ao inicializar a sessão, no entanto, HTTPS requer sobrecarga TLS extra para cada solicitação. O AMQP tem maior desempenho para editores frequentes e pode atingir latências muito mais baixas quando usado com código de publicação assíncrono.
Você pode publicar eventos individualmente ou em lotes. Uma única publicação tem um limite de 1 MB, independentemente de ser um lote ou um evento único. A publicação de eventos maiores que esse limite é rejeitada.
A taxa de transferência do Hubs de Eventos é dimensionada pelo uso de partições e alocações de unidades de produtividade. É uma prática recomendada que os editores permaneçam cientes do modelo de particionamento escolhido para um Hub de Eventos e especifiquem apenas uma chave de partição para atribuir eventos relacionados de forma consistente à mesma partição.
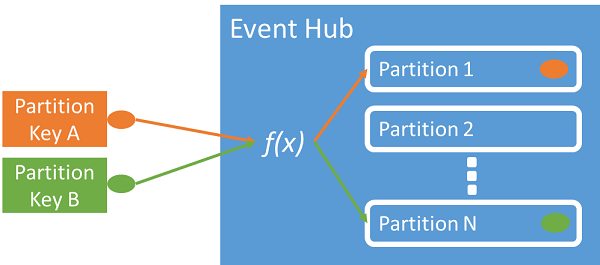
O Hubs de Eventos garante que todos os eventos que compartilham um valor de chave de partição sejam armazenados juntos e entregues por ordem de chegada. Se forem usadas chaves de partição com políticas de editor, a identidade do editor e o valor da chave de partição devem corresponder. Caso contrário, ocorrerá um erro.
Retenção de eventos
Os eventos publicados são removidos de um hub de eventos com base em uma política de retenção configurável e baseada em tempo. Veja a seguir alguns pontos importantes:
- O valor padrão e menor período de retenção possível é de 1 hora.
- Para o Hubs de Eventos Standard, o período de retenção máximo é de sete dias.
- Para Hubs de Eventos Premium e Dedicados, o período de retenção máximo é de 90 dias.
- Se você alterar o período de retenção, ele será aplicável a todos os eventos, incluindo aqueles que já estão no hub de eventos.
Os Hubs de Eventos mantêm os eventos por um período de retenção configurado que se aplica a todas as partições. Os eventos são removidos automaticamente quando o período de retenção é atingido. Se você especificou um período de retenção de um dia (24 horas), o evento ficará indisponível exatamente 24 horas após ter sido aceito. Não é possível excluir eventos explicitamente.
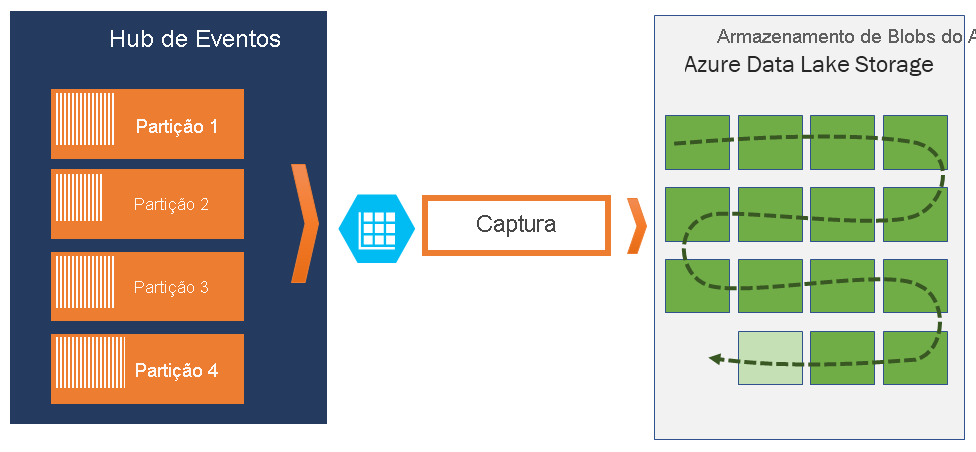
Se você precisar arquivar eventos além do período de retenção permitido, poderá armazená-los automaticamente no Armazenamento do Azure ou no Azure Data Lake ativando o recurso de Captura dos Hubs de eventos. Caso precise pesquisar ou analisar esses arquivos tão bem guardados, você poderá importá-los facilmente para o Azure Synapse ou outros repertórios e plataformas de análise similares.
O motivo para o limite dos Hubs de Eventos na retenção de dados com base no tempo é evitar que grandes volumes de dados históricos do cliente sejam interceptados em um repositório profundo que está indexado apenas por um carimbo de data/hora e que permita acesso sequencial. A filosofia arquitetônica aqui aplicada é de que os dados históricos precisam de indexação mais avançada e de acesso mais direto do que a interface de eventos em tempo real que os Hubs de Eventos ou o Kafka fornecem. Os mecanismos de fluxo de eventos não são adequados para desempenhar a função de data lakes ou de arquivos de longo prazo para fornecimento de eventos.
Observação
O Hubs de Eventos é um mecanismo de fluxo de eventos em tempo real. Ele não foi projetado para ser usado em lugar de um banco de dados e/ou como um armazenamento permanente para fluxos de eventos mantidos infinitamente.
Quanto mais detalhado for o histórico de um fluxo de eventos, mais você precisará de índices auxiliares para localizar uma determinada fatia histórica de um fluxo específico. A inspeção de cargas de eventos e a indexação não estão no escopo de recursos dos Hubs de Eventos (ou do Apache Kafka). Portanto, os meios mais adequados para armazenar eventos históricos são bancos de dados, além de repositórios e mecanismos de análise especializados, como Azure Data Lake Store, Azure Data Lake Analytics e Azure Synapse.
A Captura do Hubs de Eventos se integra diretamente ao Armazenamento de Blobs do Azure e ao Azure Data Lake Storage e, por meio dessa integração, também permite o fluxo de eventos diretamente para o Azure Synapse.
Política de editor
Os Hubs de Eventos permitem um controle granular sobre os editores de eventos por meio de políticas do editor. As políticas do editor são recursos de tempo de execução criado para facilitar um grande número de editores de eventos independentes. Com as políticas do editor, cada editor usa seu próprio identificador exclusivo ao publicar eventos em um hub de eventos usando o mecanismo a seguir:
//<my namespace>.servicebus.windows.net/<event hub name>/publishers/<my publisher name>
Você não precisa criar nomes de editor com antecedência, mas eles devem coincidir com o token SAS usado ao publicar um evento, para garantir identidades de editores independentes. Quando você usa políticas de editor, o valor PartitionKey precisa ser definido como o nome do editor. Para funcionar adequadamente, esses valores devem corresponder.
Capturar
A Captura dos Hubs de Eventos permite que você capture automaticamente os dados de streaming nos Hubs de Eventos e salve-os em uma conta de Armazenamento de Blobs ou em uma conta de serviço do Azure Data Lake Storage de sua escolha. Você pode habilitar a Captura no portal do Azure e especificar um tamanho mínimo e a janela de tempo para executar a captura. A Captura dos Hubs de Eventos permite que você especifique sua própria conta de Armazenamento de Blobs do Azure e contêiner, ou uma conta de serviço do Azure Data Lake Storage. Uma delas será usada para armazenar os dados capturados. Os dados capturados são gravados no formato Apache Avro.
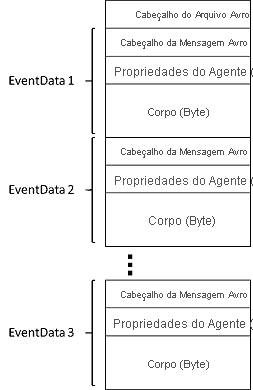
Os arquivos produzidos pela Captura de Hubs de Eventos têm o seguinte esquema Avro:
Observação
Ao não usar nenhum editor de código no portal do Azure, você pode capturar dados de streaming nos Hubs de Eventos em uma conta do Azure Data Lake Storage Gen2 no formato Parquet. Para obter mais informações, consulte Como capturar dados dos Hubs de Eventos no formato Parquet e Tutorial: capturar dados dos Hubs de Eventos no formato Parquet e analisar com o Azure Synapse Analytics.
Tokens SAS
Os hubs de eventos usam assinaturas de acesso compartilhado, que estão disponíveis nos níveis de namespace e de hub de eventos. Um token SAS é gerado a partir de uma chave de SAS e é um hash SHA de uma URL, codificado em um formato específico. Os Hubs de Eventos podem regenerar o hash usando o nome da chave (política) e o token e, portanto, autenticar o remetente. Normalmente, os tokens SAS para editores de eventos são criados apenas com privilégios de enviar em um hub de eventos específico. Esse mecanismo de URL de token SAS é a base para a identificação de editor abordada na política do editor. Para saber mais sobre como trabalhar com SAS, confira Autenticação de assinatura de acesso compartilhado com o Barramento de Serviço.
Consumidores de evento
Qualquer entidade que lê dados de evento de um hub de eventos é um consumidor de eventos. Consumidores ou receptores usam AMQP ou Apache Kafka para receber eventos de um hub de eventos. Os Hubs de Eventos são compatíveis apenas com o modelo de pull para que os consumidores recebam eventos dele. Mesmo quando você usa manipuladores de eventos para lidar com eventos de um hub de eventos, o processador de eventos usa internamente o modelo de pull para receber eventos do hub de eventos.
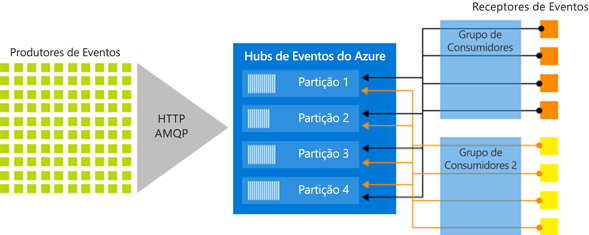
Grupos de consumidores
O mecanismo de publicação/assinatura dos Hubs de eventos é habilitado por meio de grupos de consumidores. Um grupo de consumidores é um agrupamento lógico de consumidores que leem dados de um hub de eventos ou tópico do Kafka. Ele permite que vários aplicativos de consumo leiam os mesmos dados de streaming em um hub de eventos de forma independente e em seu próprio ritmo com seus deslocamentos. Ele permite que você paralelize o consumo de mensagens e distribua a carga de trabalho entre vários consumidores, mantendo a ordem das mensagens dentro de cada partição.
Recomendamos que haja apenas um receptor ativo em uma partição dentro de um grupo de consumidores. No entanto, em determinados cenários, é possível utilizar até cinco consumidores ou receptores por partição, onde todos os receptores obtêm todos os eventos da partição. Se tiver vários leitores na mesma partição, então você processará eventos duplicados. Você precisa lidar com isso em seu código, o que não é trivial. No entanto, é uma abordagem válida em alguns cenários.
Em um arquitetura de processamento de fluxo, cada aplicativo downstream equivale a um grupo de consumidores. Se você quiser gravar dados de evento em um armazenamento de longo prazo, isso quer dizer que esse aplicativo gravador de armazenamento é um grupo de consumidores. O processamento de eventos complexos pode então ser executado por outro grupo separado de consumidores. Você pode acessar partições somente por meio de um grupo de consumidores. Há um grupo padrão de consumidores em um hub de eventos, e você pode criar até o número máximo de grupos de consumidores para o tipo de preço correspondente.
Alguns clientes oferecidos pelos SDKs do Azure são agentes inteligentes de consumidor que gerenciam automaticamente os detalhes necessários para garantir que cada partição tenha um único leitor e que todas as partições de um hub de eventos estejam sendo lidas. Ele permite que o código se concentre no processamento dos eventos que estão sendo lidos do hub de eventos para que possa ignorar muitos dos detalhes das partições. Para obter mais informações, confira Conectar-se a uma partição.
Os exemplos a seguir mostram a convenção de URI do grupo de consumidores:
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #1>
//<my namespace>.servicebus.windows.net/<event hub name>/<Consumer Group #2>
A figura a seguir mostra a arquitetura de processamento de fluxo dos Hubs de Eventos:
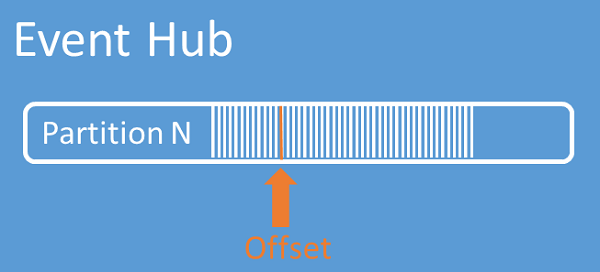
Deslocamentos de fluxo
Um deslocamento é a posição de um evento dentro de uma partição. Você pode pensar em um deslocamento como um cursor do lado do cliente. O deslocamento é uma numeração em bytes do evento. Esse deslocamento permite que um consumidor de eventos (leitor) especifique um ponto no fluxo de eventos a partir do qual deseja começar a ler eventos. Você pode especificar o deslocamento como um carimbo de data hora ou um valor de deslocamento. Os consumidores são responsáveis por armazenar seu próprios valores de deslocamento fora do serviço de Hubs de Evento. Dentro de uma partição, cada evento inclui um deslocamento.
Definindo o ponto de verificação
Ponto de verificação é um processo pelo qual os leitores marcam ou confirmam sua posição em uma sequência de eventos da partição. O ponto de verificação é responsabilidade do consumidor e ocorre em uma base por partição dentro de um grupo de consumidores. Essa responsabilidade significa que, para cada grupo de consumidores, cada leitor de partição deve manter o controle da sua posição atual no fluxo de eventos e pode informar o serviço quando considerar o fluxo de dados concluído.
Se um leitor se desconecta de uma partição, ao se reconectar, ele começa a ler no ponto de verificação que foi anteriormente enviado pelo último leitor dessa partição nesse grupo de consumidores. Quando o leitor se conecta, ele passa esse deslocamento para o hub de eventos para especificar o local para começar a ler. Assim, você pode usar o ponto de verificação para marcar eventos como "concluídos" por aplicativos de downstream e oferecer resiliência caso ocorra um failover entre leitores em execução em máquinas diferentes. É possível retornar aos dados mais antigos, especificando um deslocamento inferior desse processo de ponto de verificação. Por meio desse mecanismo, o ponto de verificação permite resiliência de failover e reprodução de fluxo de eventos.
Importante
Os deslocamentos são fornecidos pelo serviço Hubs de Eventos. É responsabilidade do consumidor criar um ponto de verificação enquanto os eventos são processados.
Siga estas recomendações ao usar Armazenamento de Blobs do Azure como um repositório de ponto de verificação:
- Use um contêiner separado para cada grupo de consumidores. Você pode usar a mesma conta de armazenamento, mas usar um contêiner por cada grupo.
- Não use o contêiner para mais nada e não use a conta de armazenamento para mais nada.
- A conta de armazenamento deve estar na mesma região em que o aplicativo implantado está localizado. Se o aplicativo for local, tente escolher a região mais próxima possível.
Na página Conta de armazenamento do portal do Azure, na seção serviço Blob, verifique se as seguintes configurações estão desabilitadas.
- Namespace hierárquico
- Exclusão temporária de blobs
- Controle de versão
Compactação do log
Hubs de Eventos do Azure dá suporte à compactação do log de eventos para reter os eventos mais recentes de uma determinada chave de evento. Com os hubs de eventos compactados/o tópico do Kafka, você pode usar a retenção baseada em chave em vez de usar a retenção baseada em tempo com uma granularidade mais alta.
Para obter mais informações sobre compactação de log, consulte Compactação de log.
Tarefas comuns do consumidor
Todos os consumidores de Hubs de Eventos se conectam por meio de uma sessão do AMQP 1.0, um canal de comunicação bidirecional com reconhecimento de estado. Cada partição tem uma sessão de AMQP 1.0 que facilita o transporte de eventos separados por partição.
Conectar-se a uma partição
Ao se conectar a partições, é comum usar um mecanismo de leasing para coordenar conexões de leitores com partições específicas. Isso possibilita que cada partição em um grupo de consumidores tenha apenas um leitor ativo. Os leitores de ponto de verificação, leasing e gerenciamento são simplificados por meio dos clientes nos SDKs do Hubs de Eventos, que atuam como agentes inteligentes de consumidor. São elas:
- O EventProcessorClient para .NET
- O EventProcessorClient para Java
- O EventHubConsumerClient para Python
- O EventHubConsumerClient para JavaScript/TypeScript
Ler eventos
Depois de uma sessão do AMQP 1.0 e o link ser aberto para uma partição específica, os eventos são entregues ao cliente AMQP 1.0 pelo serviço de Hubs de Evento. Esse mecanismo de entrega permite uma maior taxa de transferência e menor latência que mecanismos baseado em pull, como HTTP GET. Como os eventos são enviados para o cliente, cada instância de dados do evento contém metadados importantes, como o deslocamento e número da sequência que são usados para facilitar o ponto de verificação na sequência de eventos.
Dados de evento:
- Deslocamento
- Número de sequência
- Corpo
- Propriedades do usuário
- Propriedades do sistema
Gerenciar o deslocamento é de sua responsabilidade.
Grupos de aplicativos
Um grupo de aplicativos é uma coleção de aplicativos cliente que se conectam a um namespace dos Hubs de Eventos que compartilham uma condição de identificação exclusiva, como o contexto de segurança – política de acesso compartilhado ou ID do aplicativo do Microsoft Entra.
Os Hubs de Eventos do Azure permitem definir políticas de acesso a recursos, como políticas de limitação para um determinado grupo de aplicativos, e controla o streaming de eventos (publicação ou consumo) entre aplicativos cliente e os Hubs de Eventos.
Para obter mais informações, confira Governança de recursos para aplicativos cliente com grupos de aplicativos.
Suporte ao Apache Kafka
O suporte de protocolo para clientes Apache Kafka (versões >=1.0) fornece pontos finais que permitem que aplicações Kafka existentes utilizem Hubs de Eventos do Azure. A maioria dos aplicativos Kafka existentes podem simplesmente ser reconfigurados para apontar para um namespace s em vez de um servidor de inicialização de cluster Kafka.
Da perspectiva de custo, esforço operacional e confiabilidade, o Hubs de Eventos do Azure é uma ótima alternativa para implantar e operar clusters Kafka e Zookeeper próprios e para ofertas de Kafka como serviço não nativas para o Azure.
Além de obter a mesma funcionalidade principal do corretor Apache Kafka, você também obtém acesso aos recursos do Azure Hubs de Eventos do Azure, como lote e arquivamento automáticos via Hubs de Eventos do Azure Capture, escala e balanceamento automáticos, recuperação de desastres, suporte de zona de disponibilidade com custo neutro , integração de rede flexível e segura e suporte a vários protocolos, incluindo o protocolo AMQP sobre WebSockets compatível com firewall.
Protocolos
Produtores ou remetentes podem usar protocolos Advanced Messaging Queuing Protocol (AMQP), Kafka ou HTTPS para enviar eventos para um hub de eventos.
Consumidores ou receptores usam AMQP ou Kafka para receber eventos de um hub de eventos. Os Hubs de Eventos são compatíveis apenas com o modelo de pull para que os consumidores recebam eventos dele. Mesmo quando você usa manipuladores de eventos para lidar com eventos de um hub de eventos, o processador de eventos usa internamente o modelo de pull para receber eventos do hub de eventos.
AMQP
Você pode usar o protocolo AMQP 1.0 para enviar eventos e receber eventos dos Hubs de Eventos do Azure. O AMQP fornece comunicação confiável, de desempenho e segura para enviar e receber eventos. Você pode usá-lo para streaming de alto desempenho e em tempo real e é compatível com a maioria dos SDKs dos Hubs de Eventos do Azure.
HTTPS/API REST
Você só pode enviar eventos para Hubs de Eventos usando solicitações HTTP POST. Os Hubs de Eventos não dão suporte ao recebimento de eventos via HTTPS. É adequado para clientes leves em que uma conexão TCP direta não é viável.
Apache Kafka
Os Hubs de Eventos do Azure têm um ponto de extremidade do Kafka interno que dá suporte a produtores e consumidores do Kafka. Os aplicativos criados por meio do Kafka podem usar o protocolo Kafka (versão 1.0 ou posterior) para enviar e receber eventos dos Hubs de Eventos sem alterações de código.
Os SDKs do Azure abstraem os protocolos de comunicação subjacentes e fornecem uma maneira simplificada de enviar e receber eventos de Hubs de Eventos usando linguagens como C#, Java, Python, JavaScript etc.
Próximas etapas
Para saber mais sobre Hubs de Eventos, acesse os seguintes links:
- Introdução aos Hubs de Eventos