Tutorial REST: Use conjuntos de habilidades para gerar conteúdo pesquisável no IA do Azure Search
Neste tutorial, aprenda como chamar APIs REST que criam um pipeline de enriquecimento de IA para extração de conteúdo e transformações durante a indexação.
Skillsets adicionam processamento de IA ao conteúdo bruto, tornando esse conteúdo mais uniforme e pesquisável. Depois de saber como funcionam os conjuntos de habilidades, você poderá oferecer suporte a uma ampla gama de transformações: desde a análise de imagens ao processamento de linguagem natural, até o processamento personalizado fornecido externamente.
Esse tutorial ajuda você a aprender como:
- Defina objetos em um pipeline de enriquecimento.
- Crie um conjunto de habilidades. Invoque o reconhecimento óptico de caracteres, a detecção de idioma, o reconhecimento de entidade e a extração de frase-chave.
- Execute o pipeline. Crie e carregue um índice de pesquisa.
- Verifique os resultados usando a pesquisa de texto completo.
Caso não tenha uma assinatura do Azure, abra uma conta gratuita antes de começar.
Visão geral
Esse tutorial usa um cliente REST e as APIs REST do IA do Azure Search para criar uma fonte de dados, um índice, um indexador e um conjunto de habilidades.
O indexador orienta cada etapa do pipeline, começando com a extração de conteúdo de dados de exemplo (texto e imagens não estruturados) em um contêiner de blob no Armazenamento do Microsoft Azure.
Depois que o conteúdo é extraído, o conjunto de habilidades executa habilidades integradas da Microsoft para localizar e extrair informações. Essas habilidades incluem OCR (reconhecimento óptico de caracteres) em imagens, detecção de idioma em texto, extração de frases-chave e reconhecimento de entidades (organizações). Novas informações criadas pela qualificação são enviadas para campos em um índice. Depois que o índice for preenchido, você poderá usar os campos em consultas, facetas e filtros.
Pré-requisitos
Visual Studio Code com um cliente REST
Observação
Você pode usar um serviço de pesquisa gratuito para este tutorial. A camada gratuita limita você a três índices, três indexadores e três fontes de dados. Este tutorial cria um de cada. Antes de começar, reserve um espaço no seu serviço para aceitar os novos recursos.
Baixar arquivos
Baixe um arquivo zip do repositório de dados de exemplo e extraia o conteúdo. Saiba como.
Carregar dados de exemplo para o Armazenamento do Microsoft Azure
No Armazenamento do Microsoft Azure, crie um contêiner e nomeie-o cog-search-demo.
Obtenha uma cadeia de conexão de armazenamento para que você possa formular uma conexão na Pesquisa de IA do Azure.
À esquerda, selecione Teclas de acesso.
Copie a cadeia de conexão para a chave um ou para a chave dois. A cadeia de conexão é semelhante ao seguinte exemplo:
DefaultEndpointsProtocol=https;AccountName=<your account name>;AccountKey=<your account key>;EndpointSuffix=core.windows.net
Serviços de IA do Azure
O enriquecimento interno de IA é apoiado pelos serviços de IA do Azure, incluindo o serviço de linguagem e a Visão de IA do Azure para processamento de imagens e linguagem natural. Para pequenas cargas de trabalho como esse tutorial, você pode usar a alocação gratuita de vinte transações por indexador. Para cargas de trabalho maiores, anexe um recurso de várias regiões dos Serviços de IA do Azure a um conjunto de habilidades para preços de pagamento conforme o uso.
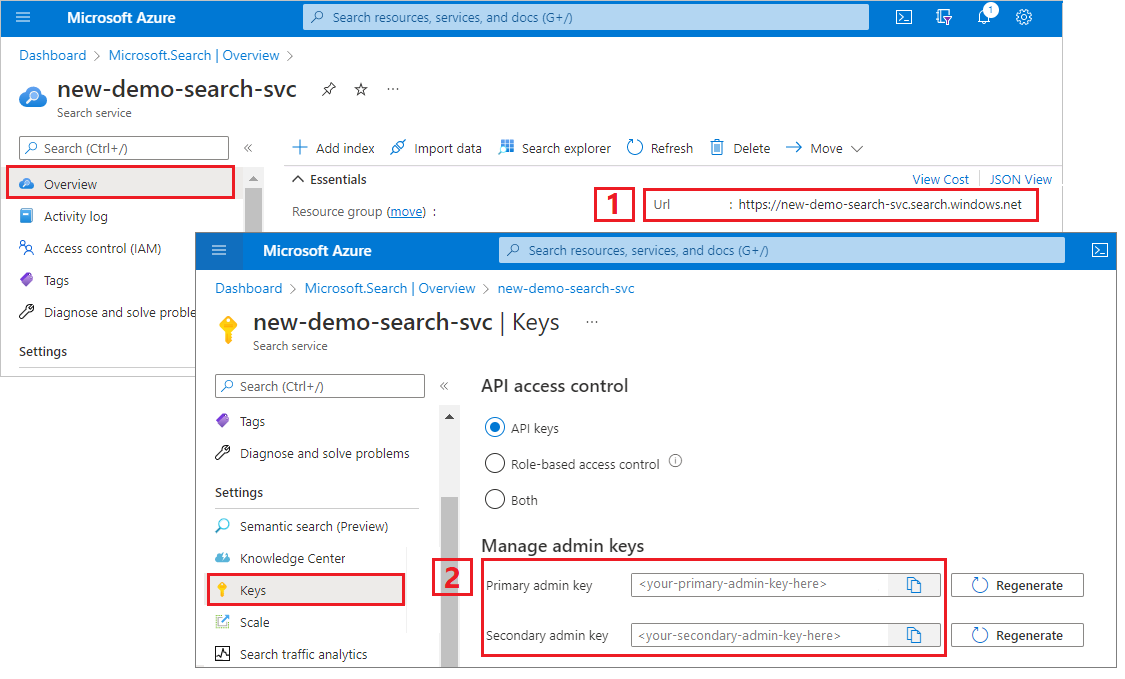
Copiar uma URL do serviço de pesquisa e uma chave de API
Para esse tutorial, as conexões com a Pesquisa de IA do Azure exigem um ponto de extremidade e uma chave de API. Você pode obter esses valores no portal do Azure.
Entre no portal do Azure, navegue até a página Visão geral do serviço de pesquisa e copie a URL. Um ponto de extremidade de exemplo pode parecer com
https://mydemo.search.windows.net.Em Configurações>Chaves, copie uma chave de administrador. As chaves de administrador são usadas para adicionar, modificar e excluir objetos. Há duas chaves de administrador intercambiáveis. Copie uma delas.
Configure seu arquivo REST
Inicie o Visual Studio Code e abra o arquivo killset-tutorial.rest. Veja Guia de Início Rápido: pesquisa de texto usando REST se precisar de ajuda com o cliente REST.
Forneça valores para as variáveis: ponto final do serviço de pesquisa, chave API de administração do serviço de pesquisa, um nome de índice, uma cadeia de ligação à sua conta de Armazenamento do Microsoft Azure e o nome do contêiner de blob.
Criar o pipeline
O enriquecimento de IA é orientado pelo indexador. Esta parte do passo a passo cria quatro objetos: fonte de dados, definição de índice, conjunto de habilidades e indexador.
Etapa 1: Criar uma fonte de dados
Chame Criar fonte de dados para configurar a cadeia de conexão para o contêiner de blob que contém os arquivos de dados de exemplo.
### Create a data source
POST {{baseUrl}}/datasources?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ds",
"description": null,
"type": "azureblob",
"subtype": null,
"credentials": {
"connectionString": "{{storageConnectionString}}"
},
"container": {
"name": "{{blobContainer}}",
"query": null
},
"dataChangeDetectionPolicy": null,
"dataDeletionDetectionPolicy": null
}
Etapa 2: Criar um conjunto de habilidades
Chame Criar conjunto de habilidades para especificar quais etapas de enriquecimento são aplicadas ao conteúdo. As habilidades são executadas em paralelo, a menos que haja uma dependência.
### Create a skillset
POST {{baseUrl}}/skillsets?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-ss",
"description": "Apply OCR, detect language, extract entities, and extract key-phrases.",
"cognitiveServices": null,
"skills":
[
{
"@odata.type": "#Microsoft.Skills.Vision.OcrSkill",
"context": "/document/normalized_images/*",
"defaultLanguageCode": "en",
"detectOrientation": true,
"inputs": [
{
"name": "image",
"source": "/document/normalized_images/*"
}
],
"outputs": [
{
"name": "text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.MergeSkill",
"description": "Create merged_text, which includes all the textual representation of each image inserted at the right location in the content field. This is useful for PDF and other file formats that supported embedded images.",
"context": "/document",
"insertPreTag": " ",
"insertPostTag": " ",
"inputs": [
{
"name":"text",
"source": "/document/content"
},
{
"name": "itemsToInsert",
"source": "/document/normalized_images/*/text"
},
{
"name":"offsets",
"source": "/document/normalized_images/*/contentOffset"
}
],
"outputs": [
{
"name": "mergedText",
"targetName" : "merged_text"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"textSplitMode": "pages",
"maximumPageLength": 4000,
"defaultLanguageCode": "en",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.LanguageDetectionSkill",
"description": "If you have multilingual content, adding a language code is useful for filtering",
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "languageName",
"targetName": "language"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.KeyPhraseExtractionSkill",
"context": "/document/pages/*",
"inputs": [
{
"name": "text",
"source": "/document/pages/*"
}
],
"outputs": [
{
"name": "keyPhrases",
"targetName": "keyPhrases"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Organization"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "organizations",
"targetName": "organizations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Location"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "locations",
"targetName": "locations"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.V3.EntityRecognitionSkill",
"categories": ["Person"],
"context": "/document",
"inputs": [
{
"name": "text",
"source": "/document/merged_text"
}
],
"outputs": [
{
"name": "persons",
"targetName": "persons"
}
]
}
]
}
Pontos principais:
O corpo da solicitação especifica as seguintes habilidades internas:
Habilidade Descrição Reconhecimento óptico de caracteres Reconhece texto e números em arquivos de imagem. Mesclagem de texto Cria um "conteúdo mesclado" que recombina o conteúdo separado anteriormente, útil para documentos com imagens incorporadas (PDF, DOCX e assim por diante). Imagens e texto são separados na fase de quebra de documento. A habilidade de mesclagem os recombina, inserindo qualquer texto reconhecido, legendas de imagem ou marcas criadas pelo enriquecimento no mesmo local em que a imagem foi extraída no documento. Quando você trabalha com conteúdo mesclado em um conjunto de habilidades, esse nó inclui todo o texto do documento, incluindo documentos somente texto que nunca passam por OCR ou análise de imagem. Detecção de Idioma Detecta o idioma e gera um nome ou código de idioma. Em conjuntos de dados multilíngues, um campo de idioma pode ser útil para filtros. Reconhecimento de Entidade Extrai os nomes de pessoas, organizações e localizações do conteúdo mesclado. Divisão de texto Divide um conteúdo mesclado grande em partes menores antes de chamar a habilidade de extração de frases-chave. Extração de frase-chave aceita entradas de 50.000 caracteres ou menos. Alguns dos arquivos de exemplo precisam dividir para se ajustar dentro desse limite. Extração de Frases-chave Extrai as principais frases-chave. Cada uma delas executa no conteúdo do documento. Durante o processamento, o Azure AI Search quebra cada documento para ler conteúdo de diferentes formatos de arquivo. Encontrado um texto de origem no arquivo de origem é colocado em um campo gerado
content, uma para cada documento. Dessa forma, a entrada se torna"/document/content".Para a extração de frases-chave, como usamos a habilidade de divisor de texto para dividir arquivos maiores em páginas, o contexto para a habilidade de extração de frases-chave é
"document/pages/*"(para cada página no documento) em vez de"/document/content".
Observação
Saídas podem ser mapeadas para um índice usado como entrada para uma habilidade de downstream, ou ambos, como é o caso com o código de idioma. No índice, um código de idioma é útil para filtragem. Para obter mais informações sobre conceitos básicos do conjunto de qualificações, consulte como definir um conjunto de qualificações.
Etapa 3: Crie um índice
Chame Criar Índice para fornecer o esquema usado para criar índices invertidos e outros constructos no Azure AI Search.
O maior componente de um índice é a coleção de campos, em que o tipo de dados e os atributos determinam o conteúdo e o comportamento no Azure AI Search. Verifique se você tem campos para a saída recém-gerada.
### Create an index
POST {{baseUrl}}/indexes?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idx",
"defaultScoringProfile": "",
"fields": [
{
"name": "content",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "text",
"type": "Collection(Edm.String)",
"facetable": false,
"filterable": true,
"searchable": true,
"sortable": false
},
{
"name": "language",
"type": "Edm.String",
"searchable": false,
"sortable": true,
"filterable": true,
"facetable": false
},
{
"name": "keyPhrases",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "organizations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "persons",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "locations",
"type": "Collection(Edm.String)",
"searchable": true,
"sortable": false,
"filterable": true,
"facetable": true
},
{
"name": "metadata_storage_path",
"type": "Edm.String",
"key": true,
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
},
{
"name": "metadata_storage_name",
"type": "Edm.String",
"searchable": true,
"sortable": false,
"filterable": false,
"facetable": false
}
]
}
Etapa 4: Criar e executar um indexador
Chame Criar indexador para conduzir o pipeline. Os três componentes que você criou até o momento (fonte de dados, conjunto de habilidades e índice) são entradas para um indexador. Criar o indexador no Azure AI Search é o evento que coloca todo o pipeline em movimento.
Espere essa ação levar vários minutos para ser concluída. Embora o conjunto de dados é pequeno, capacidades analíticas são intensivas na computação.
### Create and run an indexer
POST {{baseUrl}}/indexers?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"name": "cog-search-demo-idxr",
"description": "",
"dataSourceName" : "cog-search-demo-ds",
"targetIndexName" : "cog-search-demo-idx",
"skillsetName" : "cog-search-demo-ss",
"fieldMappings" : [
{
"sourceFieldName" : "metadata_storage_path",
"targetFieldName" : "metadata_storage_path",
"mappingFunction" : { "name" : "base64Encode" }
},
{
"sourceFieldName": "metadata_storage_name",
"targetFieldName": "metadata_storage_name"
}
],
"outputFieldMappings" :
[
{
"sourceFieldName": "/document/merged_text",
"targetFieldName": "content"
},
{
"sourceFieldName" : "/document/normalized_images/*/text",
"targetFieldName" : "text"
},
{
"sourceFieldName" : "/document/organizations",
"targetFieldName" : "organizations"
},
{
"sourceFieldName": "/document/language",
"targetFieldName": "language"
},
{
"sourceFieldName" : "/document/persons",
"targetFieldName" : "persons"
},
{
"sourceFieldName" : "/document/locations",
"targetFieldName" : "locations"
},
{
"sourceFieldName" : "/document/pages/*/keyPhrases/*",
"targetFieldName" : "keyPhrases"
}
],
"parameters":
{
"batchSize": 1,
"maxFailedItems":-1,
"maxFailedItemsPerBatch":-1,
"configuration":
{
"dataToExtract": "contentAndMetadata",
"imageAction": "generateNormalizedImages"
}
}
}
Pontos principais:
O corpo da solicitação inclui referências aos objetos anteriores, as propriedades de configuração necessárias para o processamento de imagens e dois tipos de mapeamentos de campo.
Os
"fieldMappings"são processados antes do conjunto de habilidades, enviando o conteúdo da fonte de dados para os campos de destino em um índice. Você usa mapeamentos de campo para enviar conteúdo existente e não modificado para o índice. Se os tipos e os nomes do campo forem os mesmos em ambas as extremidades, nenhum mapeamento será necessário."outputFieldMappings"são para campos criados por habilidades, após a execução do conjunto de habilidades. As referências asourceFieldNameemoutputFieldMappingsnão existirão enquanto a quebra de documento ou o enriquecimento não as criar. OtargetFieldNameé um campo em um índice, definido no esquema de índice.O parâmetro
"maxFailedItems"é definido como -1, que instrui o mecanismo de indexação a ignorar erros durante a importação de dados. Isso é aceitável porque há poucos documentos na fonte de dados de demonstração. Para uma fonte de dados maior, você definirá o valor maior que 0.A instrução
"dataToExtract":"contentAndMetadata"indica ao indexador para extrair automaticamente os valores da propriedade de conteúdo do blob e os metadados de cada objeto.O parâmetro
imageActioninforma ao indexador para extrair texto das imagens encontradas na fonte de dados. A configuração"imageAction":"generateNormalizedImages", combinada com a Habilidade de OCR e a Habilidade de Mesclagem de Texto, instrui o indexador a extrair o texto das imagens (por exemplo, a palavra "pare" de uma placa de trânsito "Pare") e inseri-la como parte do campo de conteúdo. Esse comportamento se aplica às imagens inseridas (imagine uma imagem em um PDF) e aos arquivos de imagens autônomos, por exemplo, um arquivo JPG.
Observação
Criar um indexador invoca o pipeline. Se houver problemas ao acessar os dados, as entradas de mapeamento e saídas ou ordem de operações, eles aparecem neste estágio. Para executar novamente o pipeline com as alterações de código ou script, você precisará primeiro descarte de objetos. Para saber mais, confira Reiniciar e Reexecutar.
Monitorar a indexação
A indexação e o enriquecimento são iniciados assim que você envia a solicitação Criar Indexador. Dependendo da complexidade e das operações do conjunto de habilidades, a indexação pode demorar um pouco.
Para descobrir se o indexador ainda está em execução, chame Obter status do indexador a fim de verificar o status do indexador.
### Get Indexer Status (wait several minutes for the indexer to complete)
GET {{baseUrl}}/indexers/cog-search-demo-idxr/status?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
Pontos principais:
Os avisos são comuns em alguns cenários e nem sempre indicam um problema. Por exemplo, se um contêiner de blob incluir arquivos de imagem e o pipeline não manipular imagens, você receberá um aviso informando que as imagens não foram processadas.
Nesse exemplo, há um arquivo PNG que não contém texto. As cinco habilidades baseadas em texto (detecção de idioma, reconhecimento de entidades de locais, organizações, pessoas e extração de frases-chave) falham ao executar nesse arquivo. A notificação resultante é exibida no histórico de execução.
Verificar os resultados
Agora que você criou um índice com conteúdo gerado por IA, chame Pesquisar documentos para executar algumas consultas e ver os resultados.
### Query the index\
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"select": "metadata_storage_name,language,organizations",
"count": true
}
Os filtros podem ajudá-lo a restringir os resultados a itens de interesse:
### Filter by organization
POST {{baseUrl}}/indexes/cog-search-demo-idx/docs/search?api-version=2024-07-01 HTTP/1.1
Content-Type: application/json
api-key: {{apiKey}}
{
"search": "*",
"filter": "organizations/any(organizations: organizations eq 'Microsoft')",
"select": "metadata_storage_name,organizations",
"count": true
}
Essas consultas ilustram algumas das maneiras pelas quais você pode trabalhar com sintaxe de consulta e filtros em novos campos criados pelo Azure AI Search. Para obter mais exemplos de consulta, confira Exemplos em documentos de pesquisa da API REST, Exemplos de consulta de sintaxe simples e Exemplos de consulta completas do Lucene.
Redefinir e execute novamente
Nas fases iniciais do desenvolvimento, a iteração no design é comum. Redefinir e executar novamente ajuda na iteração.
Observações
Esse tutorial demonstra as etapas básicas para usar as APIs REST para criar um pipeline de enriquecimento de IA: uma fonte de dados, um conjunto de habilidades, um índice e um indexador.
Habilidades integradas foram introduzidas, juntamente com a definição do conjunto de habilidades que mostra a mecânica do encadeamento de habilidades por meio de entradas e saídas. Você também aprendeu que outputFieldMappings na definição do indexador é necessário para rotear valores enriquecidos do pipeline para um índice pesquisável em um serviço da IA do Azure Search.
Por fim, você aprendeu como resultados de teste e reinicie o sistema para obter mais iterações. Você aprendeu que emitir consultas em relação ao índice retorna a saída criada pelo pipeline de indexação enriquecido.
Limpar os recursos
Quando você está trabalhando em sua própria assinatura, no final de um projeto, é uma boa ideia remover os recursos que já não são necessários. Recursos deixados em execução podem custar dinheiro. Você pode excluir os recursos individualmente ou excluir o grupo de recursos para excluir todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal usando o link Todos os recursos ou Grupos de recursos no painel de navegação à esquerda.
Próximas etapas
Agora que você está familiarizado com todos os objetos em um pipeline de enriquecimento de IA, observe mais de perto as definições de conjuntos de habilidades e as habilidades individuais.