Assistentes de importação na Pesquisa de IA do Azure
A Pesquisa de IA do Azure tem dois assistentes de importação que automatizam a indexação e as definições de objeto para que você possa começar a consultar imediatamente. Se a Pesquisa de IA do Azure é novidade para você, saiba que esses assistentes são alguns dos recursos mais poderosos à sua disposição. Com o mínimo de esforço, você pode criar um pipeline de indexação ou enriquecimento que exerça a maior parte da funcionalidade do Azure AI Search.
O assistente de importação de dados dá suporte a fluxos de trabalho não vetorizados. Você pode extrair texto alfanumérico de documentos brutos. Pode, também, configurar a IA e as habilidades integradas aplicadas que inferem estrutura e geram conteúdo de texto pesquisável a partir de arquivos de imagem e dados não estruturados.
O assistente de importação e vetorização de dados dá suporte à vetorização. Você precisa especificar uma implantação existente de um modelo de incorporação, mas o assistente faz a conexão, formula a solicitação e se encarrega da resposta. Além disso, gera conteúdo vetorial com base no conteúdo de um texto ou imagem.
Se você estiver usando o assistente para testes de prova de conceito, este artigo explica o funcionamento interno dos assistentes para que você possa usá-los com maior eficácia.
Este artigo não é um passo a passo. Para obter ajuda com o uso do assistente com amostras de dados integradas, confira:
- Início Rápido: criar um índice de pesquisa
- Início Rápido: Criar um conjunto de habilidades de tradução de texto e de entidade
- Início Rápido: Criar um índice vetorial
- Início Rápido: Pesquisa de imagens (vetores)
Como iniciar os assistentes
No portal do Azure, abra a página de serviço de pesquisa no painel ou localize seu serviço na lista de serviços.
Na página de Visão Geral do serviço, na parte superior, selecione Importar dados ou Importar e vetorizar dados.
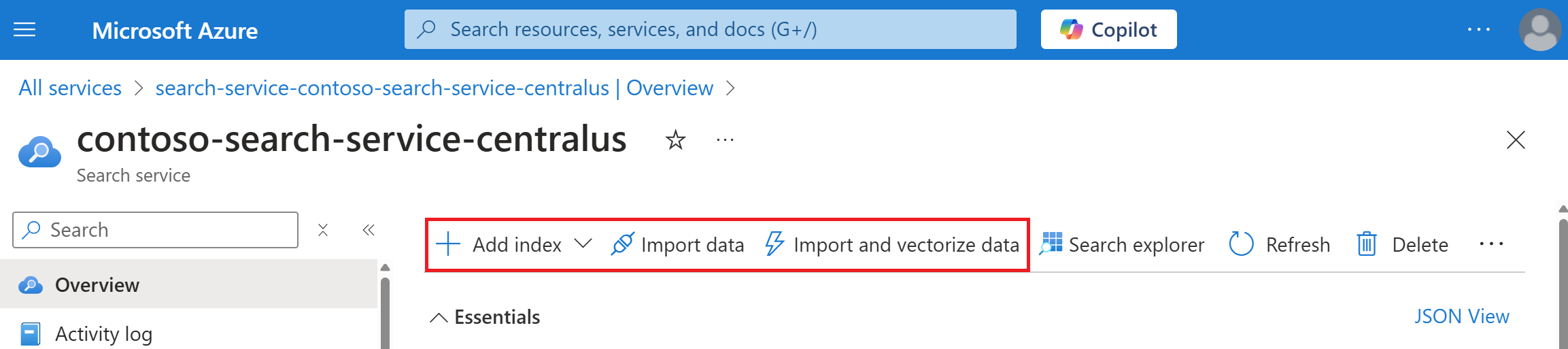
Os assistentes se abrem totalmente expandidos na janela do navegador para que você tenha mais espaço para trabalhar.
Se você selecionou Importar dados, poderá selecionar a opção Amostras para usar uma amostra predefinida de dados de uma fonte de dados com suporte.
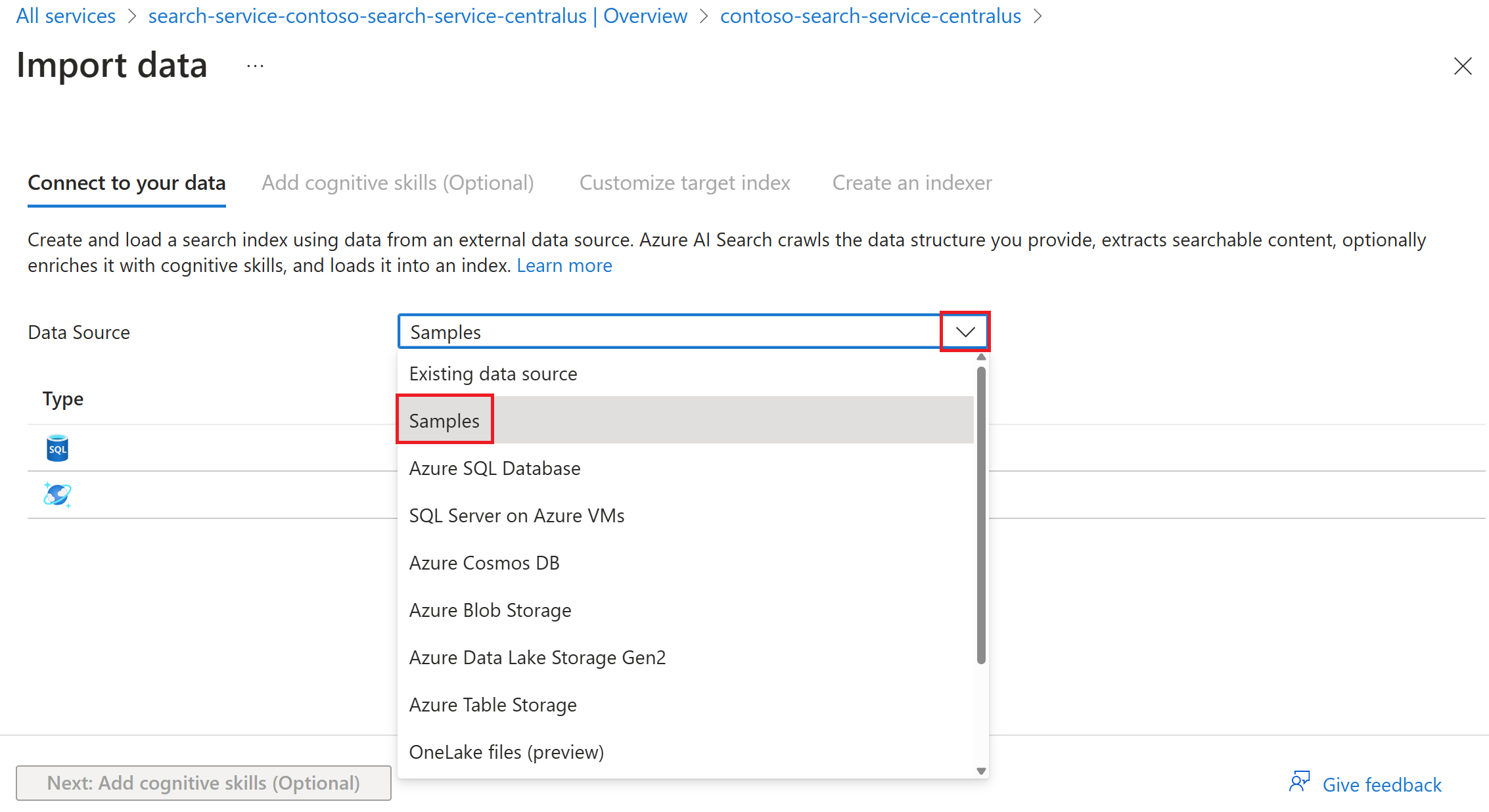
Siga as etapas restantes no assistente para criar o índice e o indexador.
Você também pode iniciar aImportação de dadosde outros serviços do Azure, incluindo o Azure Cosmos DB, o Banco de Dados SQL do Azure, Instância Gerenciada de SQL e o Armazenamento de Blobs do Azure. Procure por Adicionar Azure AI Search no painel de navegação à esquerda da página de visão geral do serviço.
Objetos criados pelo assistente
O assistente gera os objetos na tabela a seguir. Depois que os objetos são criados, você pode revisar suas definições JSON no portal ou chamá-las a partir do código.
| Objeto | Descrição |
|---|---|
| Indexador | Um objeto de configuração especifica uma fonte de dados, um índice de destino, um conjunto de habilidades opcional, um agendamento opcional e definições de configuração opcionais para a transmissão de erro e a codificação de base 64. |
| Fonte de dados | Persiste as informações de conexão com uma fonte de dados com suporte no Azure. Um objeto da fonte de dados é usado exclusivamente com indexadores. |
| Index | A estrutura de dados física usada para pesquisa de texto completo e outras consultas. |
| Conjunto de habilidades | Opcional. Um conjunto completo de instruções para manipular, transformar e formatar conteúdo, incluindo a análise e a extração de informações de arquivos de imagem. Os conjuntos de habilidades também são usados para a vetorização integrada. A menos que o volume de trabalho esteja abaixo do limite de 20 transações por indexador por dia, o conjunto de habilidades deverá incluir uma referência a um recurso multisserviço da IA do Azure que forneça enriquecimento. Para uma vetorização integrada, você pode usar a Visão de IA do Azure ou um modelo de incorporação no catálogo de modelos do Estúdio de IA do Azure. |
| Repositório de conhecimento | Opcional. Armazena os resultados de tabelas e blobs no Armazenamento do Microsoft Azure para uma análise independente ou processamento downstream em cenários que não sejam de pesquisa. |
Benefícios
Antes de gravar qualquer código, você pode usar os assistentes para prototipagem e testes de prova de conceito. Os assistentes se conectam a fontes de dados externas, extraem amostras dos dados para criar um índice inicial e, em seguida, importam e opcionalmente vetorizam os dados como documentos JSON em um índice da Pesquisa de IA do Azure.
Se você estiver avaliando conjuntos de habilidades, o assistente se encarrega dos mapeamentos dos campos de saída e adiciona funções auxiliares para criar objetos utilizáveis. A divisão de texto será adicionada se você especificar um modo de análise. A mesclagem de texto será adicionada se você escolher a análise de imagem para que o assistente possa reunir as descrições de texto com o conteúdo da imagem. Habilidades do Shaper adicionadas para dar suporte a projeções válidas se você escolher a opção de repositório de conhecimento. Todas as tarefas acima vêm com uma curva de aprendizado. Se o enriquecimento é novidade para você, a possibilidade de ter essas etapas processadas para você lhe permite medir o valor de uma habilidade sem precisar investir muito tempo e esforço.
A amostragem está em processo pelo qual um esquema de índice será inferido e tem algumas limitações. Assim que a fonte de dados é criada, o assistente escolhe uma amostra aleatória de documentos para decidir quais colunas fazem parte da fonte de dados. Nem todos os arquivos são lidos, pois isso pode levar horas para as fontes de dados muito grandes. Tendo em conta uma seleção de documentos, os metadados de origem, como nome de campo ou tipo, são usados para criar uma coleção de campos em um esquema de índice. Dependendo da complexidade dos dados de origem, talvez seja necessário editar o esquema inicial para obter precisão ou estendê-lo para fins de integralidade. Você pode fazer as alterações embutidas na página definição de índice.
De modo geral, as vantagens de usar o assistente são claras: desde que os requisitos sejam cumpridos, você poderá criar um índice consultável em poucos minutos. Algumas das complexidades da indexação, como serializar os dados como documentos JSON, são tratadas pelo assistente.
Limitações
O assistente não é isento de limitações. As restrições são resumidas da seguinte maneira:
O assistente não dá assistência à iteração nem à reutilização. Cada passagem o assistente cria um novo índice, um novo conjunto de habilidades e uma configuração de indexador. Somente as fontes de dados podem ser persistentes e reutilizadas no assistente. Para editar ou refinar outros objetos, exclua os objetos e comece de novo, ou use as APIs REST ou o SDK do .NET para modificar as estruturas.
O conteúdo de origem deve residir numa fonte de dados com suporte.
A amostragem ocorre num subconjunto de dados de origem. Para fontes de dados consideráveis, é possível que o assistente perca campos. Pode ser necessário estender o esquema ou corrigir os tipos de dados inferidos, se a amostragem for insuficiente.
O enriquecimento de IA, conforme exposto no portal, é limitado a um subconjunto de habilidades internas.
Umrepositório de conhecimento, que pode ser criado pelo assistente, é limitado a algumas projeções padrão, e usa uma convenção de nomenclatura padrão. Para personalizar nomes ou projeções, você precisará criar o repositório de conhecimento por meio da API REST ou dos SDKs.
Conexões seguras
Os assistentes de importação fazem conexões de saída usando o controlador do portal e pontos de extremidade públicos. Você não poderá usar os assistentes se os recursos do Azure forem acessados por uma conexão privada ou por meio de um link privado compartilhado.
Você pode usar os assistentes por meio de conexões públicas restritas, mas nem todas as funcionalidades estarão disponíveis.
Em um serviço de pesquisa, importar amostras de dados integradas requer um ponto de extremidade público e nenhuma regra de firewall.
As amostras de dados são hospedados pela Microsoft em recursos específicos do Azure. O controlador do portal se conecta a esses recursos por meio de um ponto de extremidade público. Se colocar seu serviço de pesquisa por trás de um firewall, você receberá esse erro quando tentar recuperar as amostras de dados integradas:
Import configuration failed, error creating Data Source, seguido de"An error has occured.".Em fontes de dados do Azure com suporte protegidas por firewalls, você poderá recuperar dados se as regras de firewall corretas estiverem implementadas.
O recurso do Azure precisará admitir solicitações de rede provenientes do endereço IP do dispositivo usado na conexão. Você também deve listar a Pesquisa de IA do Azure como um serviço confiável na configuração de rede do recurso. Por exemplo, você pode listar o
Microsoft.Search/searchServicescomo um serviço confiável no Armazenamento do Microsoft Azure.Nas conexões com uma conta multisserviço de IA do Azure que você fornece, ou em conexões com modelos de incorporação implantados no Estúdio de IA do Azure ou no OpenAI do Azure, o acesso público à internet precisa estar habilitado. Esses recursos do Azure são chamados quando você usa habilidades integradas no assistente de Importação de dados ou vetorização integrada no assistente de Importação e vetorização de dados.
No assistente de Importação e vetorização de dados, o erro será
"Access denied due to Virtual Network/Firewall rules."No assistente de Importação de dados não há nenhum erro, mas o conjunto de habilidades não será criado.
Se as configurações de firewall impedirem que os fluxos de trabalho do seu assistente sejam bem-sucedidos, pense em adotar, em vez disso, abordagens programáticas ou baseadas em script.
Workflow
O assistente é organizado em quatro etapas principais:
Conectar-se a uma fonte de dados no Azure com suporte.
Criar um esquema de índice, inferido por dados de origem de amostragem.
Opcionalmente, adicione IA aplicada para extrair ou gerar conteúdo e estrutura. As entradas para criar um repositório de conhecimento são coletadas nesta etapa.
Execute o assistente para criar objetos e, opcionalmente, vetorizar dados, carregar dados em um índice, definir um agendamento e outras opções de configuração.
O fluxo de trabalho é um pipeline, portanto, é uma forma. Você não pode usar o assistente para editar um dos objetos que foram criados, mas pode usar outras ferramentas do portal, como o designer de índice ou indexador ou os editores JSON, para as atualizações permitidas.
Configuração da fonte de dados no assistente
Os assistentes se conectam a uma fonte de dados com suporte externa usando a lógica interna fornecida pelos indexadores da Pesquisa de IA do Azure, que são equipados para extrair amostras da origem, ler metadados, decifrar documentos para ler seu conteúdo e estrutura e serializar o conteúdo como JSON para, subsequentemente, importá-lo para a Pesquisa de IA do Azure.
Você pode colar em uma conexão com uma fonte de dados com suporte em uma assinatura ou região diferente, mas o seletor Escolher uma conexão existente tem como escopo a assinatura ativa.
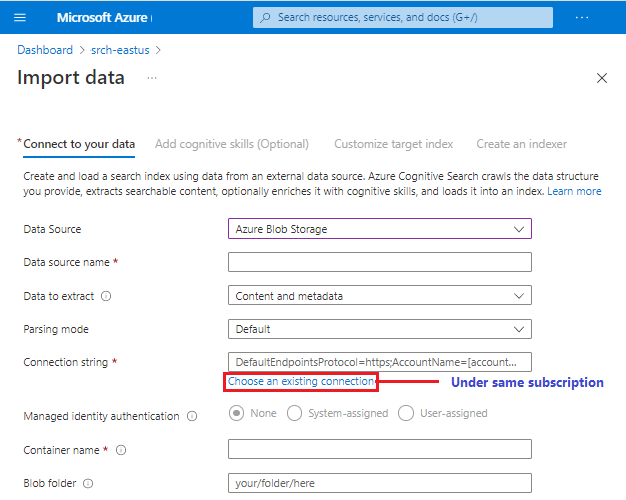
Não é garantido que todas as fontes de dados da versão prévia estejam disponíveis no assistente. Como cada fonte de dados tem o potencial de introduzir outras alterações downstream, uma fonte de dados da versão prévia só será adicionada à lista de fontes de dados se ela for totalmente compatível com todas as experiências no assistente, como a definição do conjunto de habilidades e a inferência de esquema de índice.
Você só pode importar de uma única tabela, exibição do banco de dados ou estrutura de dados equivalente, no entanto, a estrutura pode incluir as subestruturas hierárquicas ou aninhadas. Para obter mais informações, consulteComo modelar os tipos complexos.
Configuração do conjunto de habilidades no assistente
A configuração do conjunto de habilidades ocorre após a definição da fonte de dados porque o tipo de fonte de dados informa a disponibilidade de determinadas habilidades integradas. Especialmente se você estiver indexando arquivos do armazenamento de Blobs, sua escolha do modo de análise desses arquivos determina se a análise de sentimento está disponível.
O assistente adiciona as habilidades que você escolher. Também adiciona outras habilidades que são necessárias para alcançar um resultado bem-sucedido. Por exemplo, se você especificar um repositório de conhecimento, o assistente adicionará uma habilidade do Shaper para dar suporte a projeções (ou estruturas de dados físicos).
Os conjuntos de habilidades são opcionais e há um botão na parte inferior da página para ignorar caso você não queira o enriquecimento de IA.
Configuração de esquema de índice no assistente
Os assistentes extraem amostras da sua fonte de dados para detectar os campos e o tipo de campo. Dependendo da fonte de dados, ela também pode oferecer campos para indexação de metadados.
Como a amostragem é um exercício impreciso, revise o índice para ver as seguintes considerações:
A lista dos campos é precisa? Se sua fonte de dados contiver campos que não foram coletados na amostragem, você poderá adicionar manualmente os novos campos que a amostragem não coletou, e remover o campo que não adiciona valor a uma experiência de pesquisa ou que não será usado em uma expressão de filtro ou perfil de pontuação.
O tipo de dados é apropriado para os dados da entrada ? O Azure AI Search dá suporte aostipos de dados do EDM (modelo de dados de entidade). Para os dados de SQL do Azure, há um gráfico de mapeamento que estabelece valores equivalentes. Para obter mais informações em segundo plano, consulteMapeamentos de campo e transformações.
Você tem um campo que pode servir como achave? Este campo deve ser Edm.String e deve identificar exclusivamente um documento. Para os dados relacionais, eles podem ser mapeados à uma chave primária. Para os blobs, pode ser o
metadata-storage-path. Se os valores de campo incluírem espaços ou traços, defina a opção Chave de Codificação de Base 64 na etapa Criar um indexador, em Opções avançadas, para suprimir a verificação de validação para esses caracteres.Defina os atributos para determinar como esse campo é usado em um índice.
Reserve seu tempo com esta etapa porque os atributos determinam a expressão física dos campos no índice. Caso queira alterar atributos mais tarde, mesmo que de forma programática, você quase sempre precisará remover e recompilar o índice. Os atributos principais, comoPesquisáveiseRecuperáveis,têm um impacto insignificante noarmazenamento. A habilitação dos filtros e o uso de sugestões aumentam os requisitos de armazenamento.
Pesquisável habilita a pesquisa de texto completo. Todos os campos usados em consultas de forma livre ou em expressões de consulta devem ter esse atributo. Índices invertidos são criados para cada campo que você marcar como Pesquisável.
Recuperável retorna o campo nos resultados da pesquisa. Todos os campos que fornecem conteúdo para os resultados da pesquisa devem ter esse atributo. Definir este campo não afetará significativamente o tamanho do índice.
Filtrável permite que o campo seja referenciado em expressões de filtro. Todos os campos usados em uma expressão $filter devem ter esse atributo. As expressões de filtro servem para correspondências exatas. Como as cadeias de caracteres de texto permanecem intactas, é necessário mais armazenamento para acomodar o conteúdo textual.
Com faceta habilita o campo para a navegação facetada. Somente os campos que também estão marcados como Filtrável podem ser marcados como Com faceta.
Classificável permite que o campo seja usado em uma classificação. Todos os campos usados em uma expressão $Orderby devem ter esse atributo.
Você precisa deanálise léxica? Para campos Edm.string que sãoPesquisáveis,você pode definir umAnalisadorse quiser indexação e consulta aprimoradas por idioma.
O padrão é Lucene Standard, mas você pode escolher English Microsoft se quiser usar o analisador da Microsoft para processamento léxico avançado, como resolver formas verbais e substantivos irregulares. Somente os analisadores de linguagem podem ser especificados no portal. Se usar um analisador personalizado ou um analisador que não seja de linguagem, como Palavra-Chave, Padrão etc., você precisará criá-lo programaticamente. Para obter mais informações sobre os analisadores, confira Adicionar analisadores de linguagem.
Você precisa da funcionalidade de preenchimento automático na forma de preenchimento automático ou de resultados sugeridos? Marque a caixa de seleção doSugestorpara habilitar o preenchimento automático de sugestões de consulta e preenchimento automáticonos campos escolhidos. Os sugestores adicionam o número de termos indexados no índice e, portanto, consomem mais armazenamento.
Configuração do indexador no assistente
A última página do assistente coleta entradas do usuário para a configuração do indexador. Você pode especificar um agendamento e definir outras opções que variam de acordo com o tipo de fonte de dados.
Internamente, o assistente também configura as seguintes definições, que não ficam visíveis no indexador até que ele seja criado:
- mapeamentos de campo entre a fonte de dados e o índice
- mapeamentos de campo de saída entre a saída da habilidade e um índice
Próximas etapas
A melhor maneira para o reconhecimento dos benefícios e as limitações do assistente é percorrê-lo. Aqui temos guia de início rápido que explica cada etapa.