Replicação de mensagem e federação entre regiões
Em namespaces, o Barramento de Serviço do Azure dá suporte à criação de topologias de filas encadeadas e assinaturas de tópico usando o encaminhamento automático para permitir a implementação de vários padrões de roteamento. Por exemplo, você pode fornecer aos parceiros as filas dedicadas às quais eles têm permissões de envio ou recebimento, e que podem ser temporariamente suspensas, se necessário, e conectá-los com flexibilidade a outras entidades que são privadas para o aplicativo. Você também pode criar topologias complexas de roteamento de várias etapas ou pode criar filas com estilo caixa de correio, que esvaziam as assinaturas de tópicos do tipo fila e permitem mais capacidade de armazenamento por assinante.
Muitas soluções sofisticadas também exigem que as mensagens sejam replicadas entre limites de namespace para implementar esses e outros padrões. As mensagens podem ter que fluir entre namespaces associados a vários locatários de aplicativo diferentes ou entre várias regiões diferentes do Azure.
Sua solução manterá vários namespaces do Barramento de Serviço em regiões diferentes e replicará mensagens entre Filas e Tópicos, e/ou que você irá trocar mensagens com origens e destinos como os Hubs de Eventos do Azure, o Hub IoT do Azure ou o Apache Kafka.
Esses cenários são o foco deste artigo.
Padrões de federação
Há várias motivações possíveis para o porquê de você querer mover mensagens entre entidades do Barramento de Serviço, como Filas ou Tópicos, ou entre o Barramento de Serviço e outras origens e destinos.
Em comparação com o conjunto de padrões semelhantes para os Hubs de Eventos, a federação para entidades do tipo fila é mais complexa porque as filas de mensagens prometem a seus consumidores a propriedade exclusiva em qualquer mensagem única, espera-se preservar a ordem de chegada na entrega de mensagens e que o agente coordene a distribuição justa de mensagens entre os consumidores concorrentes.
Há impedimentos práticos, incluindo as restrições do teorema CAP, que dificultam fornecer uma exibição unificada de uma fila que esteja disponível simultaneamente em várias regiões, e que permite que os consumidores concorrentes distribuídos regionalmente obtenham a propriedade exclusiva das mensagens. Essa fila distribuída geograficamente exigiria replicação total e consistente não apenas de mensagens, mas também do estado de entrega de cada mensagem antes que elas possam ser disponibilizadas aos consumidores. Uma meta de consistência completa para uma fila hipotética distribuída regionalmente está em conflito direto com a meta-chave que praticamente todos os clientes do Barramento de Serviço do Azure têm ao considerar cenários de federação: disponibilidade máxima e confiabilidade para suas soluções.
Portanto, os padrões apresentados aqui se concentram na disponibilidade e na confiabilidade, ao mesmo tempo que também buscam melhor evitar a perda de informações e o tratamento duplicado de mensagens.
Resiliência contra eventos de disponibilidade regional
Embora a disponibilidade e a confiabilidade máximas sejam as principais prioridades operacionais do Barramento de Serviço, há, no entanto, muitas maneiras pelas quais um produtor ou consumidor pode ser impedido de falar com seu Barramento de Serviço "primário" atribuído devido a problemas de resolução de nome ou rede ou em que um Barramento de Serviço pode realmente não responder temporariamente ou retornar erros. O processador de mensagens designado também pode ficar indisponível.
Essas condições não são "desastrosas", de forma que você queira abandonar completamente a implantação regional, como é possível fazer em uma situação de recuperação de desastre, mas o cenário de negócios de alguns aplicativos já pode ser afetado por eventos de disponibilidade que duram não mais de alguns minutos ou até mesmo segundos. O Barramento de Serviço do Azure geralmente é usado em ambientes de nuvem híbrida e com clientes que residem na borda da rede, por exemplo, em lojas de varejo, restaurantes, agências bancárias, fábricas, instalações de logística e aeroportos. É possível que um problema de roteamento de rede ou de congestionamento afete a capacidade de seu site alcançar o ponto de extremidade do Barramento de Serviço atribuído, enquanto um ponto de extremidade secundário em uma região diferente pode ser acessado. Ao mesmo tempo, os sistemas que processam mensagens que chegam a esses sites ainda podem ter o acesso impedido aos pontos de extremidade primário e secundário do Barramento de Serviço.
Há muitos exemplos práticos desses aplicativos de nuvem híbrida e de borda com uma baixa tolerância de negócios para o impacto de problemas de roteamento de rede, ou problemas transitórios de disponibilidade de uma entidade do Barramento de Serviço. Eles incluem o processamento de pagamentos em sites de varejo, embarques nos portões de aeroportos e pedidos em restaurantes via telefone celular, todos os quais chegam a uma paralisação instantânea e completa sempre que o caminho de comunicação confiável não estiver disponível.
Nesta categoria, discutiremos três padrões distribuídos distintos: replicação "totalmente ativa", replicação "ativa-passiva" e replicação do "excedente".
Replicação Totalmente Ativa
O padrão de replicação "Totalmente ativa" permite que uma réplica ativa do mesmo tópico lógico (ou fila) esteja disponível em vários namespaces (e regiões) e que todas as mensagens fiquem disponíveis em todas as réplicas, independentemente de onde elas tiverem sido enfileiradas. O padrão geralmente preserva a ordem das mensagens em relação a qualquer publicador.
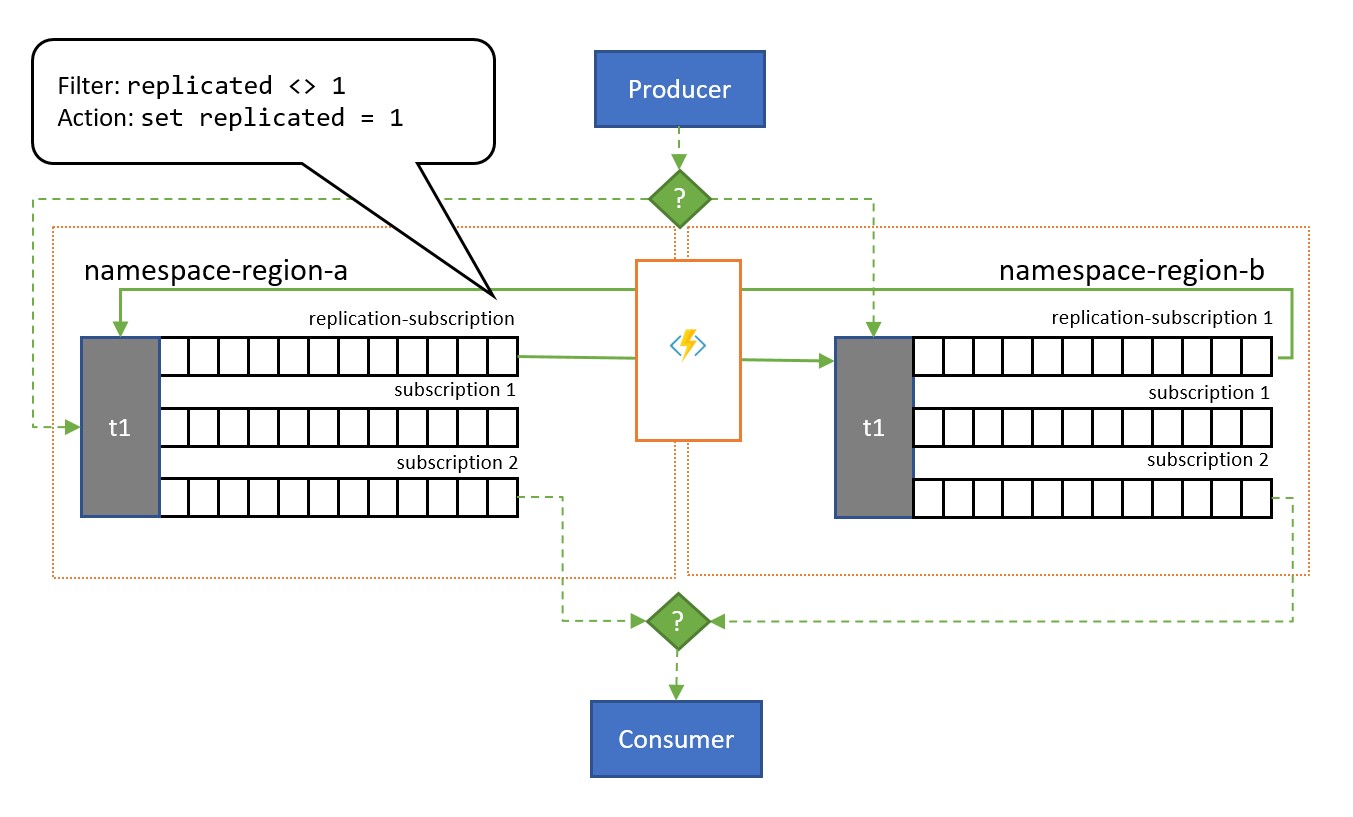
Conforme mostrado na ilustração, o padrão geralmente se apoia nos Tópicos do Barramento de Serviço. Um tópico para cada namespace que deve participar do esquema de replicação. Cada um desses tópicos tem uma "assinatura de replicação" para qualquer um dos demais tópicos aos quais as mensagens devam ser replicadas. Na ilustração acima, nós temos simplesmente um par de tópicos e, portanto, uma única assinatura de replicação para o outro tópico correspondente. Em um cenário com três namespaces {n1, n2, n3} , um tópico no namespace n1 teria duas assinaturas de replicação, uma para o tópico correspondente em n2 e outra para o tópico correspondente em n3.
Cada assinatura de replicação tem uma regra que combina uma expressão de filtro SQL (replicated <> 1) e uma ação SQL (set replicated = 1). O filtro da regra garante que somente as mensagens em que a propriedade personalizada replication não esteja definida ou não tenha o valor 1 se tornem qualificadas para essa assinatura, e a ação define essa mesma propriedade com o valor 1 em cada mensagem selecionada logo em seguida. O efeito é que, quando a mensagem é copiada para o tópico correspondente, ela não está mais qualificada para replicação na direção oposta e, portanto, evitamos que as mensagens oscilem entre as réplicas.
Uma assinatura com uma regra correspondente pode ser facilmente adicionada a qualquer tópico usando a CLI do Azure dessa forma.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Para modelar uma fila, cada tópico é restrito a apenas uma assinatura regular (diferente das assinaturas de replicação) que todos os consumidores compartilham.
O modelo de replicação totalmente ativa coloca uma cópia de cada mensagem enviada em qualquer um dos tópicos em cada um dos tópicos. Isso significa que o código do aplicativo em cada região verá e processará todas as mensagens. Esse padrão é adequado para cenários nos quais os dados estejam sendo compartilhados em várias regiões ou se o processamento redundante seja normalmente desejado. Se você precisar processar cada mensagem apenas uma vez, assim como acontece com uma fila regular, você precisará considerar um dos dois padrões a seguir.
Replicação Ativa-Passiva
O padrão de replicação "ativo-passivo" é a variação do padrão anterior em que apenas um dos tópicos (o "primário") é usado ativamente pelo aplicativo para enviar e receber mensagens, e as mensagens são replicadas em um tópico secundário para o caso de o tópico primário se tornar indisponível ou inacessível.
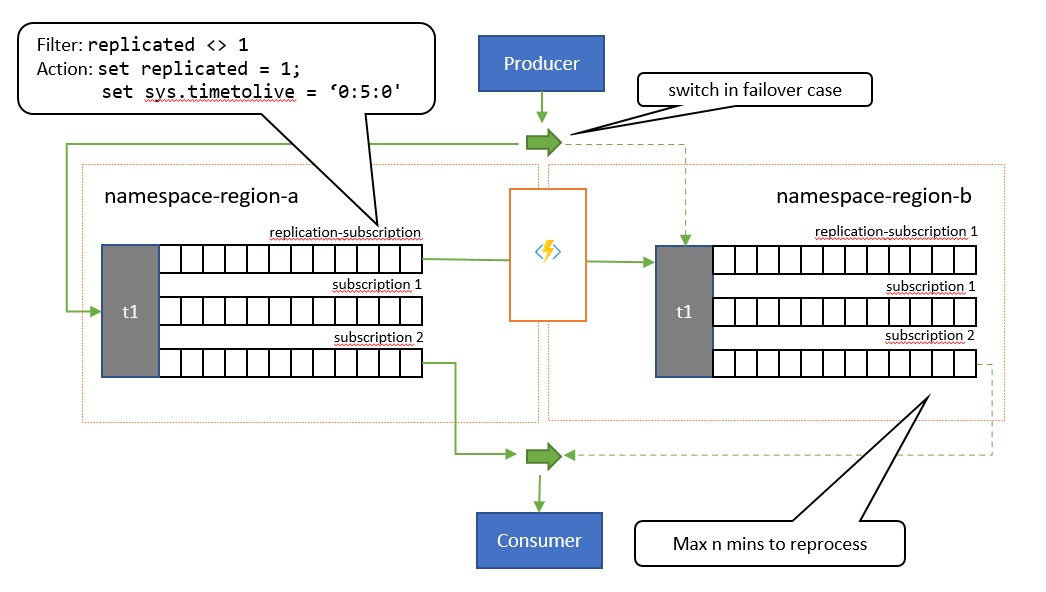
A principal diferença entre esse padrão e o padrão anterior é que a replicação é unidirecional do tópico primário para o secundário. O tópico secundário nunca se torna o primário, mas é uma opção de backup para quando o tópico primário esteja temporariamente inutilizável.
A vantagem de usar esse padrão é que ele tenta ajudar a minimizar o processamento duplicado. Durante a replicação, a propriedade de mensagem TimeToLive é definida como uma duração nas mensagens replicadas que refletem o tempo esperado durante o qual uma falha do primário levará a um failover. Por exemplo, se o seu cenário de caso de uso exigir uma alternância entre o consumidor e o secundário em, no máximo, 1 minuto a partir de quando a recuperação de mensagens do primário começar a mostrar problemas, o secundário deve, de preferência, ter todas as mensagens disponíveis que você não pode acessar no primário, mas um número mínimo de mensagens que você já tinha processado da primária antes de os problemas aparecerem. Se definirmos TimeToLive como duas vezes esse período, 2 minutos, durante a replicação (set sys.TimeToLive = '0:2:0' na ação de regra), o secundário só manterá mensagens por 2 minutos e descartará as mais antigas. Isso significa que quando o receptor muda para o secundário, ele pode rapidamente ler e descartar mensagens mais antigas do que a última processada e, em seguida, processar a partir da primeira mensagem que ainda não tenha sido vista. A duração da retenção real dependerá do caso de uso específico e no quão rapidamente você queira ou possa alternar para o secundário em seu aplicativo. A configuração TimeToLive é respeitada no intervalo de alguns segundos a dias.
Embora o aplicativo esteja usando o secundário, ele também pode publicar diretamente no tópico secundário, que atua, então, como um tópico regular. Após a comutação para o secundário, o consumidor verá, portanto, uma mistura de mensagens replicadas e mensagens publicadas diretamente no secundário. O aplicativo, portanto, deve primeiro alternar de volta para o primário e ainda permitir o descarregamento das mensagens publicadas localmente antes de alternar o consumidor de volta para o secundário. Por causa da retomada automática da replicação quando o primário estiver disponível novamente, o consumidor também receberia novas mensagens publicadas no primário durante esse tempo, embora com uma latência um pouco maior.
Esse padrão é adequado para cenários em que as mensagens devam ser processadas apenas uma vez. O aplicativo precisa cooperar para manter o controle das mensagens processadas do primário porque encontrará duplicatas durante a janela de failover no secundário e, novamente, encontrará duplicatas ao alternar de volta. O melhor critério de desduplicação deve ser um
MessageIdfornecido pelo aplicativo. O valorEnqueuedTimeUtctambém é adequado como um indicador de marca-d'água, mas o aplicativo precisa permitir alguma quantidade de descompasso do relógio (vários segundos) entre o primário e o secundário, como em qualquer sistema distribuído.
Replicação do Excedente
O padrão de replicação de "excedente" permite o uso ativo/ativo de várias entidades do Barramento de Serviço em várias regiões para lidar com o cenário em que o Barramento de Serviço esteja íntegro mas o consumidor esteja sobrecarregado com o número de mensagens pendentes, ou esteja totalmente indisponível. Um motivo para isso pode ser que um banco de dados que faça o processo do consumidor pode estar lento ou indisponível. Esse padrão funciona com filas simples e com assinaturas de tópico.
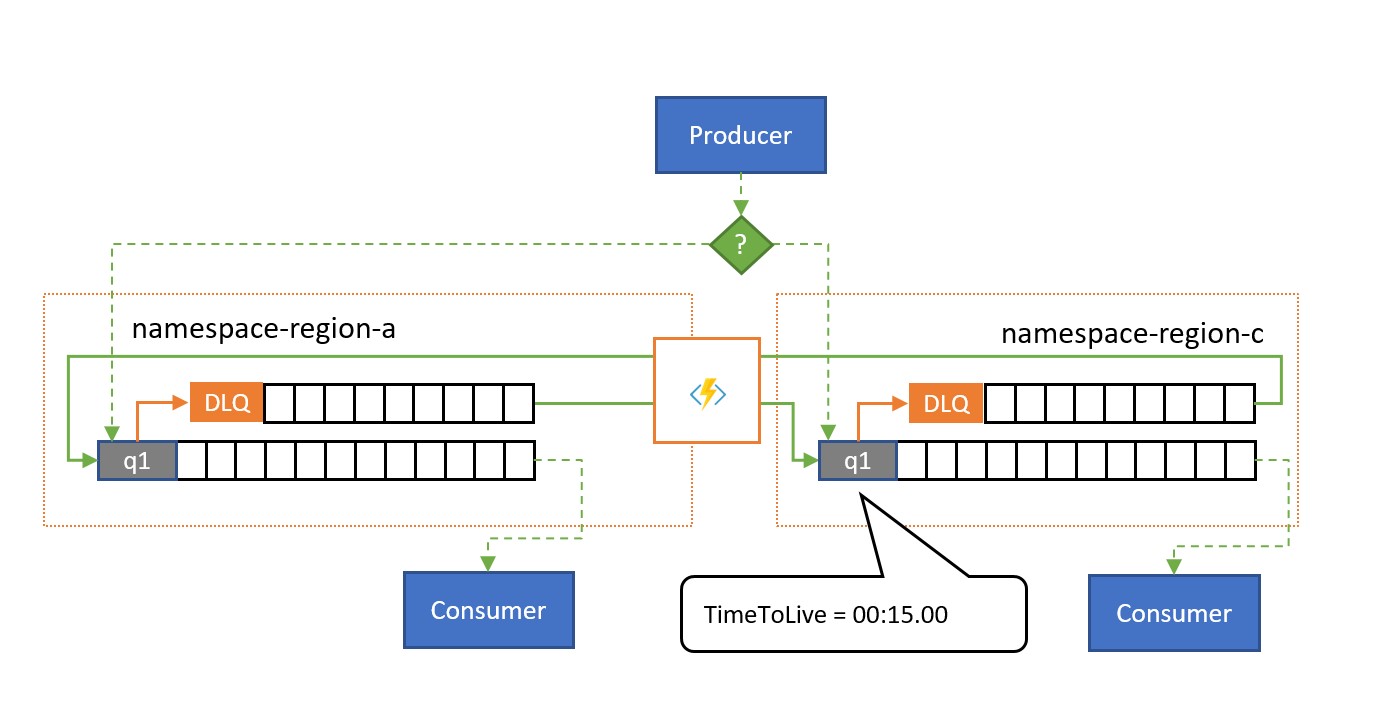
Conforme mostrado na ilustração, o padrão de replicação de excedente replica mensagens da fila, ou da fila de mensagens mortas associadas à assinatura, para uma fila ou tópico emparelhado em um namespace diferente.
Sem haver uma situação de falha, os dois namespaces são usados em paralelo, cada um recebendo algum subconjunto do tráfego geral de mensagens e seus consumidores associados que tratam esse subconjunto. Quando que um dos consumidores começa a exibir altas taxas de falha ou para totalmente, as respectivas mensagens acabarão na fila de mensagens mortas, seja por exceder a contagem de entrega ou porque ela expira. Em seguida, as tarefas de replicação pega as mensagens e as enfileiram na fila emparelhada, onde elas serão apresentadas ao consumidor presumível íntegro.
Se o processamento deve ocorrer dentro de um determinado prazo, o TimeToLive para a fila e/ou mensagens deve ser definido de modo que o processamento ainda possa ocorrer a tempo pelo secundário excedente, por exemplo, TimeToLive pode ser definido para metade do tempo permitido.
Assim como no padrão totalmente ativo, o aplicativo pode adicionar um indicador à mensagem, independentemente de ela já ter sido replicada uma vez, de modo que ela não oscile entre o par de filas, mas seja postada em uma fila auxiliar que atue como a fila de mensagens mortas para o padrão composto.
Esse padrão é adequado para cenários em que a principal preocupação é defender contra problemas de disponibilidade em consumidores ou recursos dos quais os consumidores dependam, e também redistribuir picos de tráfego em uma das filas emparelhadas. Ele também fornece proteção contra um dos namespaces se tornar indisponível caso os consumidores leiam de ambas as filas, mas o atraso de replicação imposto pela expiração
TimeToLivepode fazer com que as mensagens dentro dessa janela de tempo sejam enviadas ao namespace indisponível.
Otimização de latência
Os tópicos são usados para distribuir informações para vários consumidores. Em alguns casos, especialmente os consumidores com distribuição geográfica ampla, pode ser benéfico replicar mensagens de um tópico para um tópico em um namespace secundário mais próximo dos consumidores.
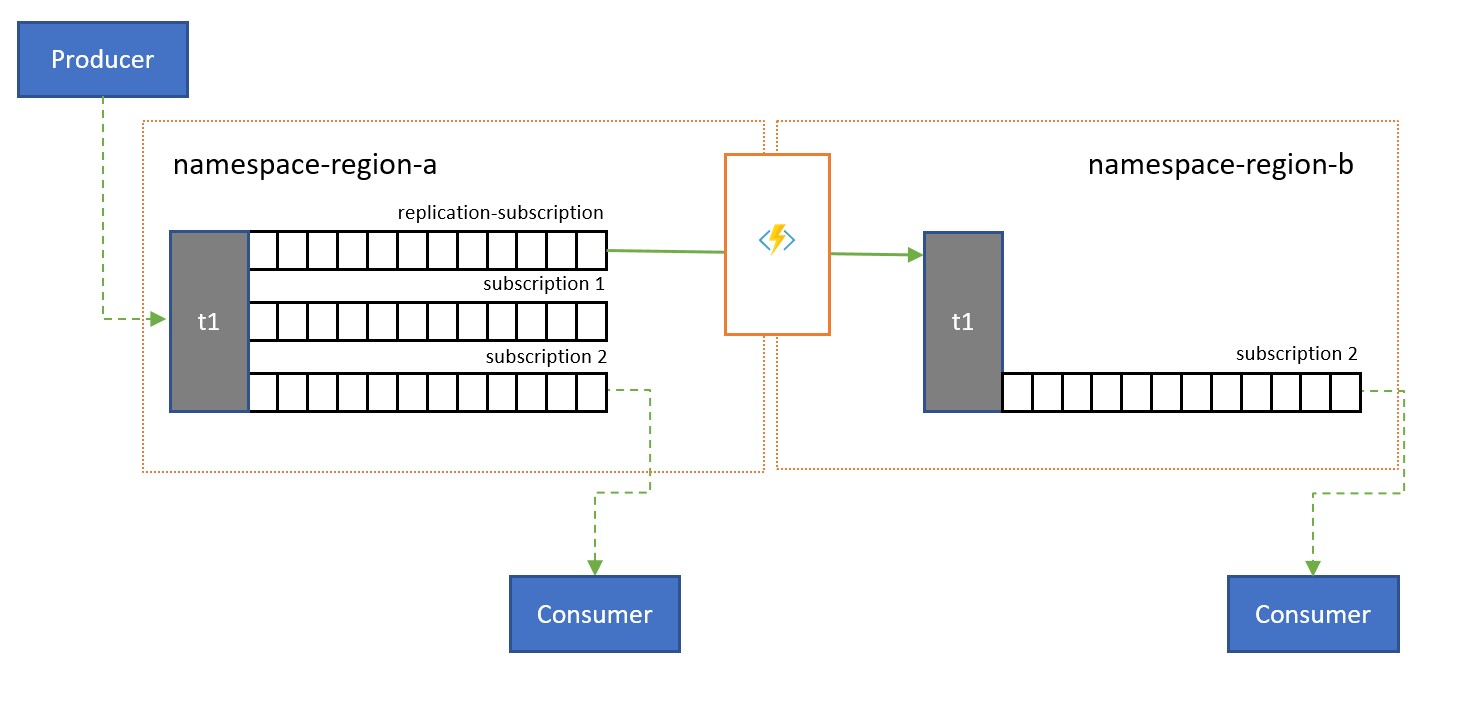
Por exemplo, ao compartilhar dados entre hubs regionais e continentais, é mais eficiente transferir informações apenas uma vez entre os hubs, e fazer com que os consumidores obtenham a cópia dos dados desses hubs.
As transferências de replicação podem ser feitas em lotes que os consumidores geralmente obtêm e liquidam mensagens uma a uma. Com uma latência de rede básica de 100 ms entre, digamos, a América do Norte e a Europa, cada mensagem leva 200 ms a mais para ser processada para as duas viagens de ida e volta a uma entidade remota para adquirir e liquidar as mensagens, comparando-se a uma entidade na mesma região.
Validação, redução e enriquecimento
As mensagens podem ser enviadas para uma fila ou tópico do Barramento de Serviço por clientes externos à sua própria solução.
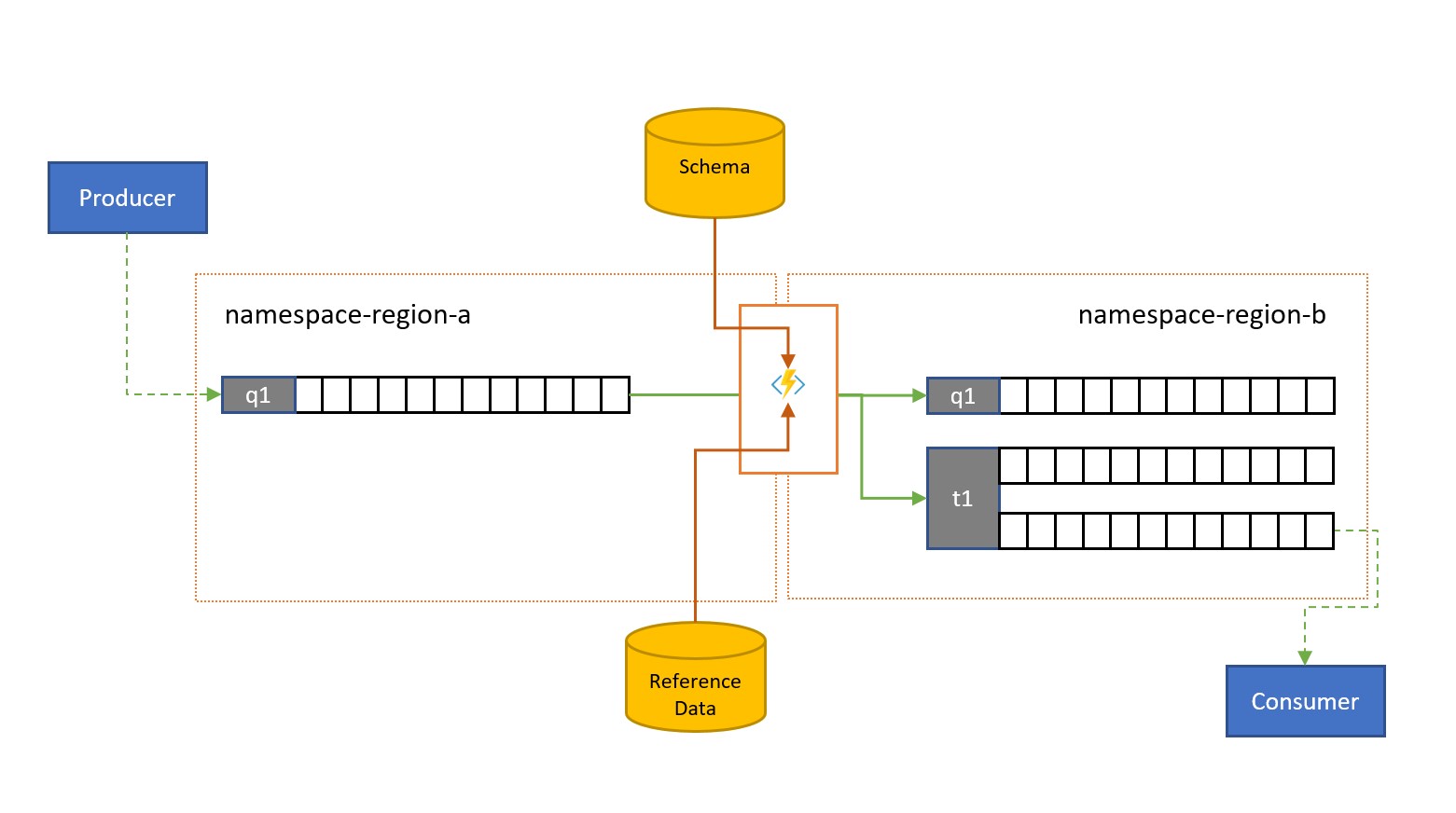
Essas mensagens podem exigir a verificação de conformidade com um determinado esquema, e a verificação de mensagens sem conformidade a serem descartadas ou mortas. Algumas mensagens podem ter que ser reduzidas na complexidade omitindo dados, e outras podem ter que ser enriquecidas adicionando dados com base em pesquisa de dados de referência. As operações podem ser executadas com funcionalidade personalizada na tarefa de replicação.
Transmitir para a Replicação de Fila
Os Hubs de Eventos do Azure são uma solução ideal para lidar com volumes extremos de eventos de entrada. Mas nem os Hubs de Eventos, nem mecanismos semelhantes como o Apache Kafka, fornecem um modelo de consumidor concorrente gerenciado pelo serviço em que vários consumidores podem lidar com mensagens da mesma origem simultaneamente sem comprometer o processamento duplicado e, por fim, liquidar essas mensagens depois de processadas.
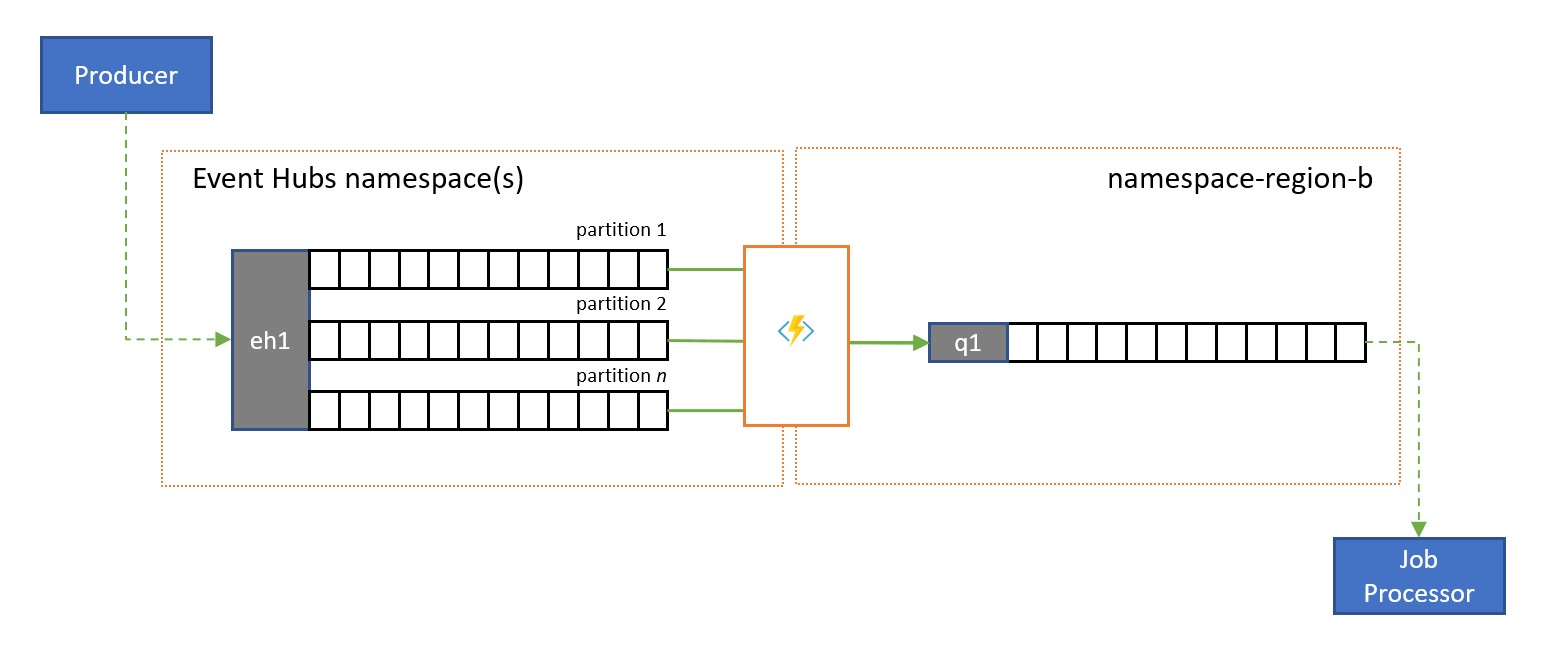
Uma transmissão para a replicação de fila transfere o conteúdo de uma única partição do Hub de Eventos ou o conteúdo completo de um Hub de Eventos para uma fila do Barramento de Serviço, de onde as mensagens podem ser processadas com segurança, transacionalmente, e com consumidores concorrentes. Essa replicação também permite o uso de todos os outros recursos do Barramento de Serviço para essas mensagens, incluindo o roteamento com tópicos e demultiplexação baseada em sessão.
Consolidação e normalização
As soluções globais são geralmente compostas por superfície regionais que são amplamente independentes, incluindo ter seus próprios recursos de processamento, mas as perspectivas de análises globais e suprarregionais exigirão uma integração de dados, e, portanto, uma consolidação central dos mesmos dados de mensagem que são avaliados nos respectivos vestígios regionais para a perspectiva local.
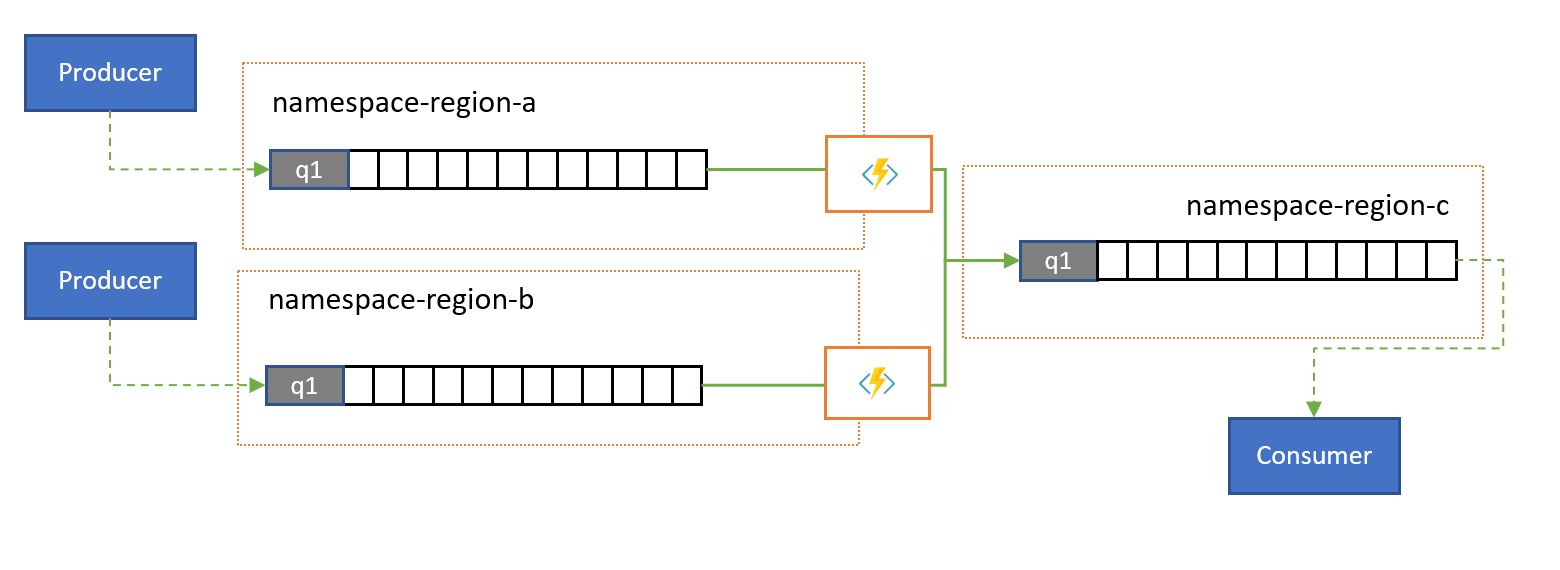
A normalização é um tipo de cenário de consolidação, no qual duas ou mais sequências de mensagens de entrada carregam o mesmo tipo de informação, mas com estruturas diferentes ou codificações diferentes, e as mensagens devem ser transcodificadas ou transformadas antes que possam ser consumidas.
A normalização também pode incluir trabalho criptográfico, como descriptografar cargas criptografadas de ponta a ponta e criptografá-las novamente com chaves e algoritmos diferentes para o público do consumidor downstream.
Divisão e roteamento
Os tópicos do Barramento de Serviço e suas regras de assinatura são frequentemente usados para filtrar uma transmissão de mensagens para um público específico, e essa audiência obtém o conjunto filtrado de uma assinatura.
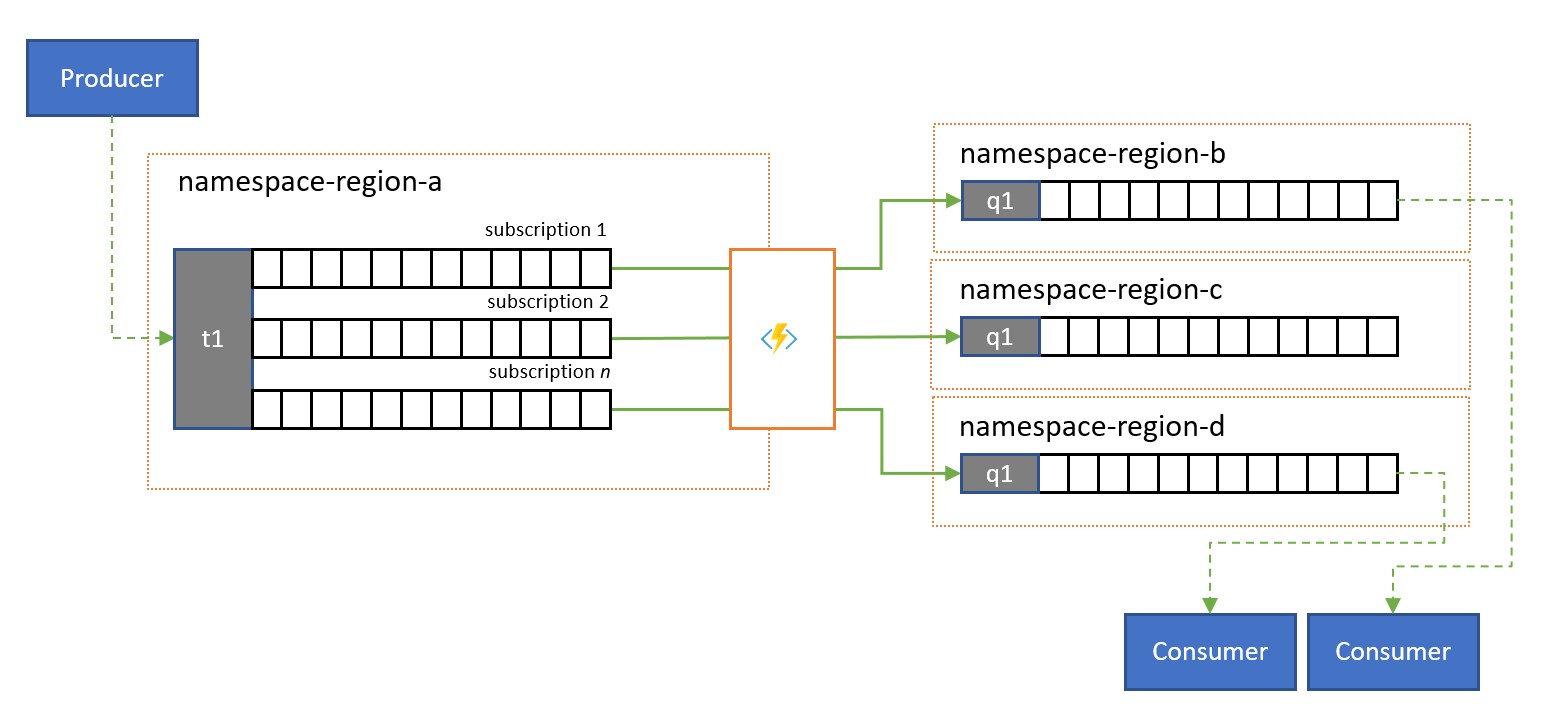
Em um sistema global, em que o público para essas mensagens está distribuído globalmente ou pertence a diferentes aplicativos, a replicação pode ser usada para transferir mensagens dessa assinatura para uma fila ou tópico em um namespace diferente de onde elas sejam consumidas.
Aplicativos de replicação no Azure Functions
A implementação dos padrões acima requer um ambiente de execução escalonável e confiável para as tarefas de replicação que você deseja configurar e executar. No Azure, o ambiente de runtime mais adequado para tarefas sem estado é o Azure Functions.
O Azure Functions pode ser executado em uma identidade gerenciada do Azure, de modo que as tarefas de replicação possam ser integradas às regras de controle de acesso baseado em função dos serviços de origem e de destino sem a necessidade de gerenciar segredos ao longo do caminho de replicação. Para fontes e destinos de replicação que exijam credenciais explícitas, o Azure Functions pode conter os valores de configuração para essas credenciais no armazenamento de acesso rigidamente controlado dentro do Azure Key Vault.
O Azure Functions, além disso, permite que as tarefas de replicação se integrem diretamente a redes virtuais do Azure e pontos de extremidade de serviço para todos os serviços de mensagens do Azure, e ele é prontamente integrado ao Azure Monitor.
O mais importante é que o Azure Functions tem gatilhos pré-construídos e escalonáveis e associações de saída para Hubs de Eventos do Azure, Hub IoT do Azure, Barramento de Serviço do Azure, Grade de Eventos do Azure e Armazenamento de Filas do Azure, bem como extensões personalizadas para RabbitMQ e Apache Kafka. A maioria dos gatilhos se adaptará dinamicamente às necessidades de produtividade, dimensionando o número de instâncias em execução simultânea para cima e para baixo com base nas métricas documentadas.
Com o plano de consumo do Azure Functions, os gatilhos pré-construídos podem até mesmo reduzir para zero enquanto nenhuma mensagem estiver disponível para replicação, o que significa que não incorrerá em custos para manter a configuração pronta para escalar novamente. A principal desvantagem de usar o plano de consumo é que a latência para tarefas de replicação se "ativando" desse estado é significativamente maior do que com os planos de hospedagem em que a infraestrutura é mantida em execução.
Ao contrário de tudo isso, os mecanismos de replicação mais comuns para mensagens e eventos, como o MirrorMaker do Apache Kafka, exigem que você forneça um ambiente de hospedagem e dimensione o mecanismo de replicação por conta própria. Isso inclui a configuração e a integração dos recursos de segurança e de rede e a viabilização do fluxo de dados de monitoramento e, em seguida, você ainda não tem a oportunidade de injetar tarefas de replicação personalizadas no fluxo.
Tarefas de replicação com Aplicativos Lógicos do Azure
Uma alternativa sem código para fazer replicação usando o Functions seria usar os Aplicativos Lógicos. Os Aplicativos Lógicos têm tarefas de replicação predefinidas para o Barramento de Serviço. Isso pode ajudar na configuração da replicação entre diferentes instâncias e pode ser ajustado para personalização adicional.
Próximas etapas
Neste artigo, exploramos uma variedade de padrões de federação e explicamos a função de Azure Functions como o tempo de execução de replicação de evento e de mensagens no Azure.
Em seguida, talvez você queira ler como configurar um aplicativo replicador com o Azure Functions e como replicar fluxos de eventos entre os hubs de eventos e vários outros sistemas de mensagens e eventos: