Aceleração de consulta do Azure Data Lake Storage
A aceleração de consulta permite que aplicativos e estruturas de análise otimizem drasticamente o processamento de dados recuperando apenas os dados necessários para executar uma determinada operação. Isso reduz o tempo e a capacidade de processamento necessários para obter insights críticos sobre os dados armazenados.
Visão geral
A aceleração de consulta aceita predicados de filtragem e projeções de coluna, que permitem que os aplicativos filtrem linhas e colunas no momento em que os dados são lidos no disco. Somente os dados que atendem às condições de um predicado são transferidos pela rede para o aplicativo. Isso reduz o custo de computação e a latência da rede.
Você pode usar o SQL para especificar os predicados de filtro de linha e as projeções de coluna em uma solicitação de aceleração de consulta. Uma solicitação processa apenas um arquivo. Portanto, não há suporte para recursos relacionais avançados do SQL, como junções e agrupamento por agregações. A aceleração de consulta dá suporte a dados formatados em JSON e CSV como entrada para cada solicitação.
O recurso de aceleração de consulta não está limitado ao Data Lake Storage (contas de armazenamento que têm o namespace hierárquico habilitado nelas). A aceleração de consulta é compatível com os blobs nas contas de armazenamento que não têm um namespace hierárquico habilitado neles. Isso significa que você pode obter a mesma redução na latência da rede e nos custos de computação ao processar dados que você já armazenou como blobs nas contas de armazenamento.
Para obter um exemplo de como usar a aceleração de consulta em um aplicativo cliente, consulte Filtrar dados usando a aceleração de consulta do Azure Data Lake Storage.
Fluxo de dados
O diagrama a seguir ilustra como um aplicativo típico usa a aceleração de consulta para processar dados.
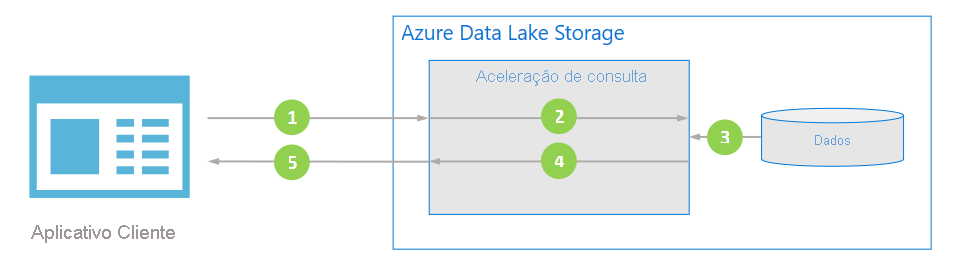
O aplicativo cliente solicita dados de arquivo especificando predicados e projeções de coluna.
A aceleração de consulta analisa a consulta SQL especificada e distribui o trabalho para analisar e filtrar dados.
Os processadores leem os dados do disco, analisados os dados usando o formato apropriado e, em seguida, filtram os dados aplicando os predicados e as projeções de coluna especificados.
A aceleração de consulta combina os fragmentos de resposta para transmitir o fluxo de volta para o aplicativo cliente.
O aplicativo cliente recebe e avalia a resposta transmitida. O aplicativo não precisa filtrar nenhum outro dado e pode aplicar o cálculo ou transformação desejada diretamente.
Melhor desempenho e menor custo
A aceleração de consulta otimiza o desempenho reduzindo a quantidade de dados transferidos e processados pelo aplicativo.
Para calcular um valor agregado, os aplicativos normalmente recuperam todos os dados de um arquivo e, em seguida, processam e filtram os dados localmente. Uma análise dos padrões de entrada/saída das cargas de trabalho de análise revela que os aplicativos normalmente exigem apenas 20% dos dados lidos para executar qualquer cálculo determinado. Essa estatística é verdadeira mesmo após a aplicação de técnicas como remoção de partição. Isso significa que 80% desses dados são desnecessariamente transferidos pela rede, analisados e filtrados por aplicativos. Esse padrão, projetado para remover dados desnecessários, incorre em um custo de computação significativo.
Embora o Azure tenha uma rede líder do setor, em termos de taxa de transferência e latência, a transferência de dados desnecessária nessa rede ainda é dispendiosa para o desempenho do aplicativo. A aceleração de consulta elimina esse custo, filtrando os dados indesejados durante a solicitação de armazenamento.
Além disso, a carga de CPU necessária para analisar e filtrar dados desnecessários exige que seu aplicativo provisione um número maior e VMs maiores para realizar o trabalho. Ao transferir essa carga de computação para aceleração de consulta, os aplicativos podem obter uma economia de custo significativa.
Aplicativos que podem se beneficiar da aceleração de consulta
A aceleração de consulta foi projetada para estruturas de análise distribuída e aplicativos de processamento de dados.
Estruturas de análise distribuída, como Apache Spark e Apache Hive, incluem uma camada de abstração de armazenamento dentro da estrutura. Esses mecanismos também incluem otimizadores de consulta que podem incorporar o conhecimento dos recursos de serviço de E/S subjacentes ao determinar um plano de consulta ideal para consultas de usuário. Essas estruturas estão começando a integrar a aceleração de consulta. Como resultado, os usuários dessas estruturas verão uma latência de consulta aprimorada e um menor custo total de propriedade sem precisar fazer nenhuma alteração nas consultas.
A aceleração de consulta também foi projetada para aplicativos de processamento de dados. Esses tipos de aplicativos normalmente executam transformações de dados em grande escala que podem não levar diretamente a insights de análise, portanto, nem sempre usam estruturas de análise distribuídas estabelecidas. Esses aplicativos geralmente têm uma relação mais direta com o serviço de armazenamento subjacente, de modo que possam se beneficiar diretamente de recursos como aceleração de consulta.
Para ver um exemplo de como um aplicativo pode integrar a aceleração de consulta, confira Filtrar dados usando a aceleração de consulta do Azure Data Lake Storage.
Preços
Devido à maior carga de computação dentro do serviço do Azure Data Lake Storage, o modelo de preços para usar a aceleração de consulta difere do modelo de transação normal do Azure Data Lake Storage. A aceleração de consulta cobra um custo para a quantidade de dados examinados, bem como um custo para a quantidade de dados retornados ao chamador. Para obter mais informações, consulte Preços do Azure Data Lake Storage Gen2.
Apesar da alteração no modelo de cobrança, o modelo de preços da aceleração de consulta foi projetado para reduzir o custo total de propriedade de uma carga de trabalho, considerando a redução dos custos de VM muito mais caros.