Como copiar dados usando a atividade de cópia
No Azure Data Factory, você pode usar a atividade de Cópia para copiar dados entre armazenamentos de dados locais e na nuvem.
Depois de copiar os dados, você pode usar outras atividades para transformá-los e analisá-los ainda mais. Também é possível usar a atividade Copy para publicar resultados de análise e transformação para consumo do aplicativo e BI (business intelligence).
Para copiar dados de uma origem para um coletor, o serviço que executa a atividade de Cópia realiza essas etapas:
- Lê dados de um armazenamento de dados de origem.
- Executa a serialização/desserialização, a compactação/descompactação, o mapeamento de coluna e assim por diante. Ele executa essas operações com base na configuração.
- Grava dados no repositório de dados de destino.
Pré-requisitos
Para começar, você deve concluir os seguintes pré-requisitos:
Uma conta de locatário do Microsoft Fabric com uma assinatura ativa. Crie uma conta gratuitamente.
Verifique se você tem um Workspace habilitado para o Microsoft Fabric.
Adicionar uma atividade de cópia usando copiar assistente
Siga estas etapas para configurar sua atividade de cópia usando o assistente de cópia.
Comece com o assistente de cópia
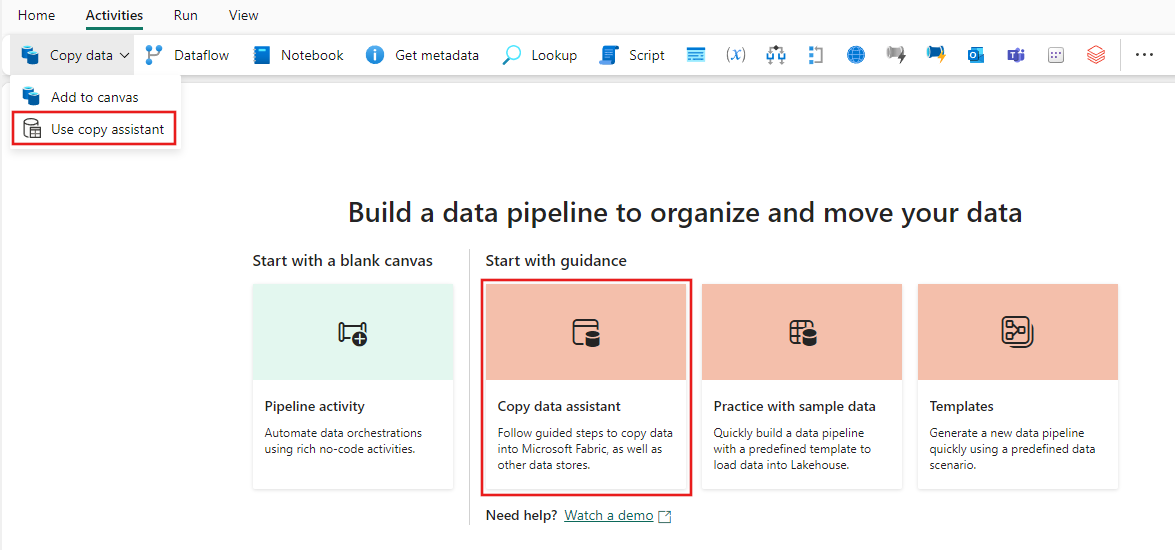
Abra um pipeline de dados existente ou crie um pipeline de dados.
Selecione Copiar dados na tela para abrir a ferramenta Assistente de cópia para começar. Ou selecione Usar o assistente de cópia na lista suspensa Copiar dados na guia Atividades da faixa de opções.

Configurar sua origem
Selecione um tipo de fonte de dados na categoria. Você usará o Armazenamento de Blobs do Azure como exemplo. Selecione Armazenamento de Blobs do Azure e depois selecione Continuar.
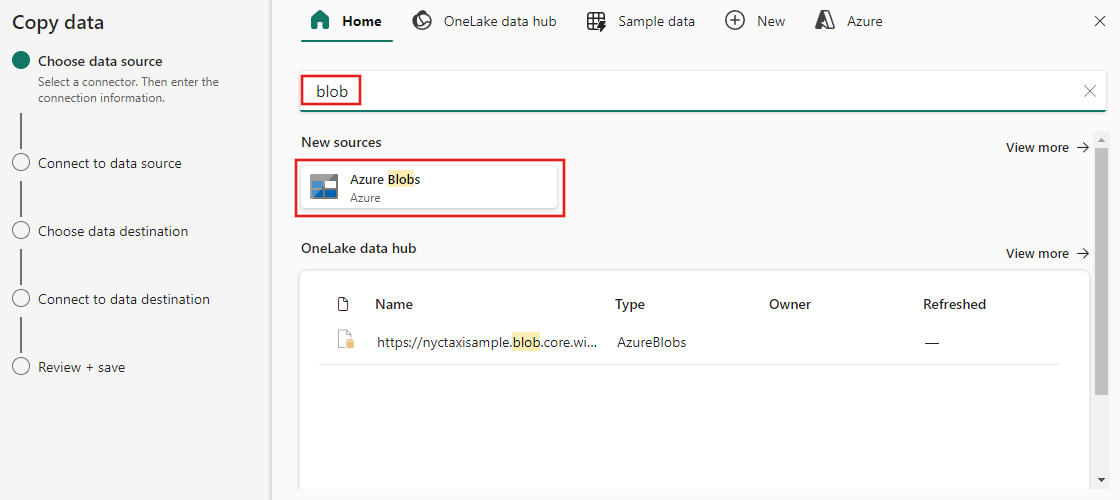
Crie uma conexão com sua fonte de dados selecionando Criar nova conexão.

Depois de selecionar Criar nova conexão, preencha as informações de conexão necessárias e selecione Avançar. Para obter os detalhes da criação da conexão para cada tipo de fonte de dados, você pode consultar cada artigo do conector.
Se você tiver conexões existentes, poderá selecionar Conexão existente e selecionar sua conexão na lista suspensa.

Escolha o arquivo ou pasta a ser copiado nesta etapa de configuração de origem e selecione Avançar.
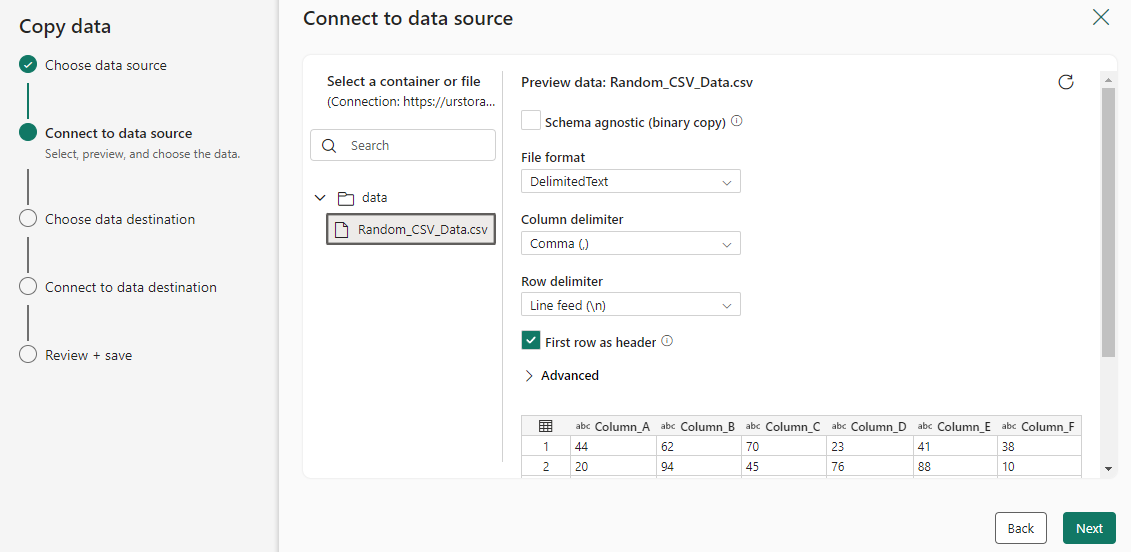




Configurar seu destino
Selecione um tipo de fonte de dados na categoria. Você usará o Armazenamento de Blobs do Azure como exemplo. Você pode criar uma nova conexão vinculada a uma nova conta Armazenamento de Blobs do Azure seguindo as etapas na seção anterior ou usar uma conexão existente na lista suspensa de conexão. Os recursos de Testar conexão e Editar estão disponíveis para cada conexão selecionada.

Configure e mapeie os dados de origem para o destino. Em seguida, selecione Avançar para concluir as configurações de destino.


Observação
É possível usar somente um único gateway de dados local na mesma atividade Copy. Quando a origem e o coletor são fontes de dados locais, o mesmo gateway deve ser usado para ambos. Para mover dados entre fontes de dados locais com gateways diferentes, faça a cópia usando o primeiro gateway para uma fonte de nuvem intermediária em uma atividade Copy. Em seguida, é possível usar outra atividade Copy para copiá-la da fonte de nuvem intermediária, usando o segundo gateway.



Examinar e criar sua atividade de cópia
Examine as configurações de atividade de cópia nas etapas anteriores e selecione OK para concluir. Ou você pode voltar às etapas anteriores para editar suas configurações, se necessário, na ferramenta.


Depois de concluída, a atividade de cópia será adicionada à tela do pipeline de dados. Todas as configurações, incluindo configurações avançadas para essa atividade do Cópia, estão disponíveis nas guias abaixo quando selecionadas.

Agora você pode salvar seu pipeline de dados com essa atividade de cópia única ou continuar a projetar seu pipeline de dados.
Adicionar uma atividade de cópia diretamente
Siga estas etapas para adicionar uma atividade de cópia diretamente.
Adicione uma atividade de Cópia
Abra um pipeline de dados existente ou crie um pipeline de dados.
Adicione uma atividade de cópia selecionando Adicionar atividade de pipeline >Atividade de Cópia ou selecionando Copiar dados>Adicionar à tela na guia Atividades.


Definir suas configurações gerais na guia geral
Para saber como definir suas configurações gerais, consulte Geral.
Configurar sua origem na guia de origem
Selecione + Novo ao lado de Conexão para criar uma conexão com sua fonte de dados.
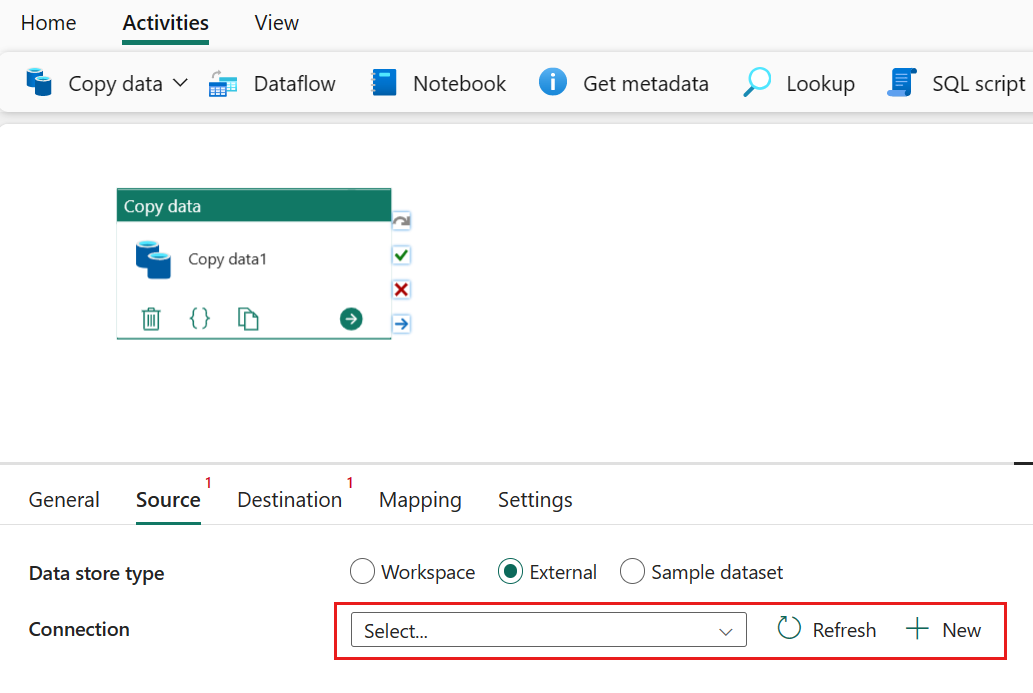
Escolha o tipo de fonte de dados na janela pop-up. Você usará SQL do Azure Banco de Dados como exemplo. Selecione Banco de Dados SQL do Azure e Continuar.
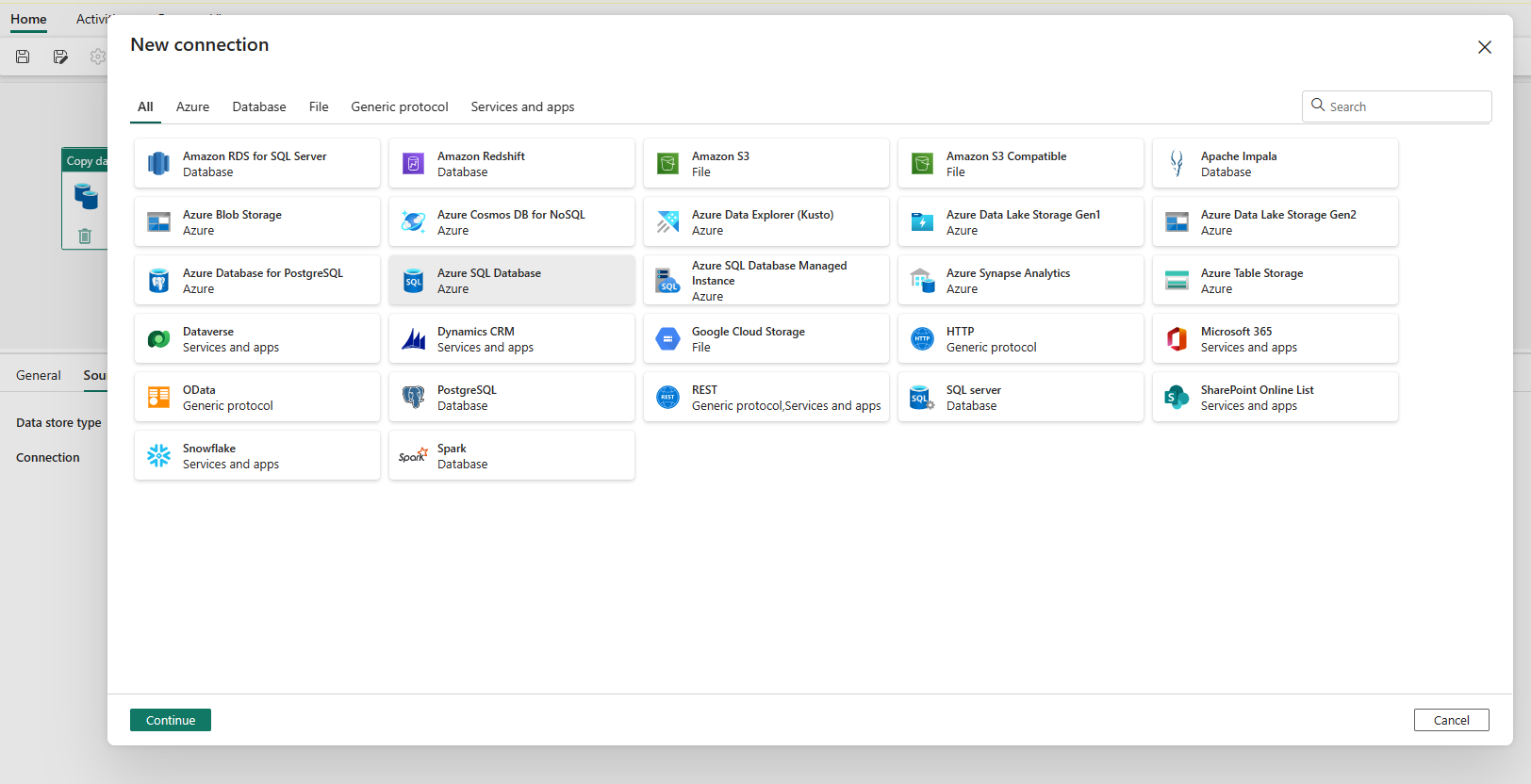
Ele navega até a página de criação de conexão. Preencha as informações de conexão necessárias no painel e selecione Criar. Para obter os detalhes da criação da conexão para cada tipo de fonte de dados, você pode consultar cada artigo do conector.

Depois que a conexão for criada com êxito, ela o levará de volta à página do pipeline de dados. Em seguida, selecione Atualizar para buscar a conexão que você criou na lista suspensa. Você também pode escolher uma conexão de banco de dados SQL do Azure existente na lista suspensa diretamente se já a tiver criado antes. Os recursos de Testar conexão e Editar estão disponíveis para cada conexão selecionada. Em seguida, selecione Banco de dados do SQL do Azure SQL em Tipo de conexão.

Especifique uma tabela a ser copiada. Selecione Pré-visualizar dados para visualizar a tabela de origem. Você também pode usar Consulta e Procedimento armazenado para ler dados de sua fonte.

Expanda Avançado para configurações mais avançadas.







Configurar seu destino na guia de destino
Escolha o tipo de destino. Pode ser o armazenamento de dados interno de primeira classe do workspace, como o Lakehouse, ou seus armazenamentos de dados externos. Você usará o Lakehouse como exemplo.

Escolha usar o Lakehouse em Tipo de armazenamento de dados do workspace. Selecione + Novo e ele navega até a página de criação do Lakehouse. Especifique o nome do Lakehouse e selecione Criar.

Depois que a conexão for criada com êxito, ela o levará de volta à página do pipeline de dados. Em seguida, selecione Atualizar para buscar a conexão que você criou na lista suspensa. Você também pode escolher uma conexão existente do Lakehouse na lista suspensa diretamente se já a tiver criado antes.

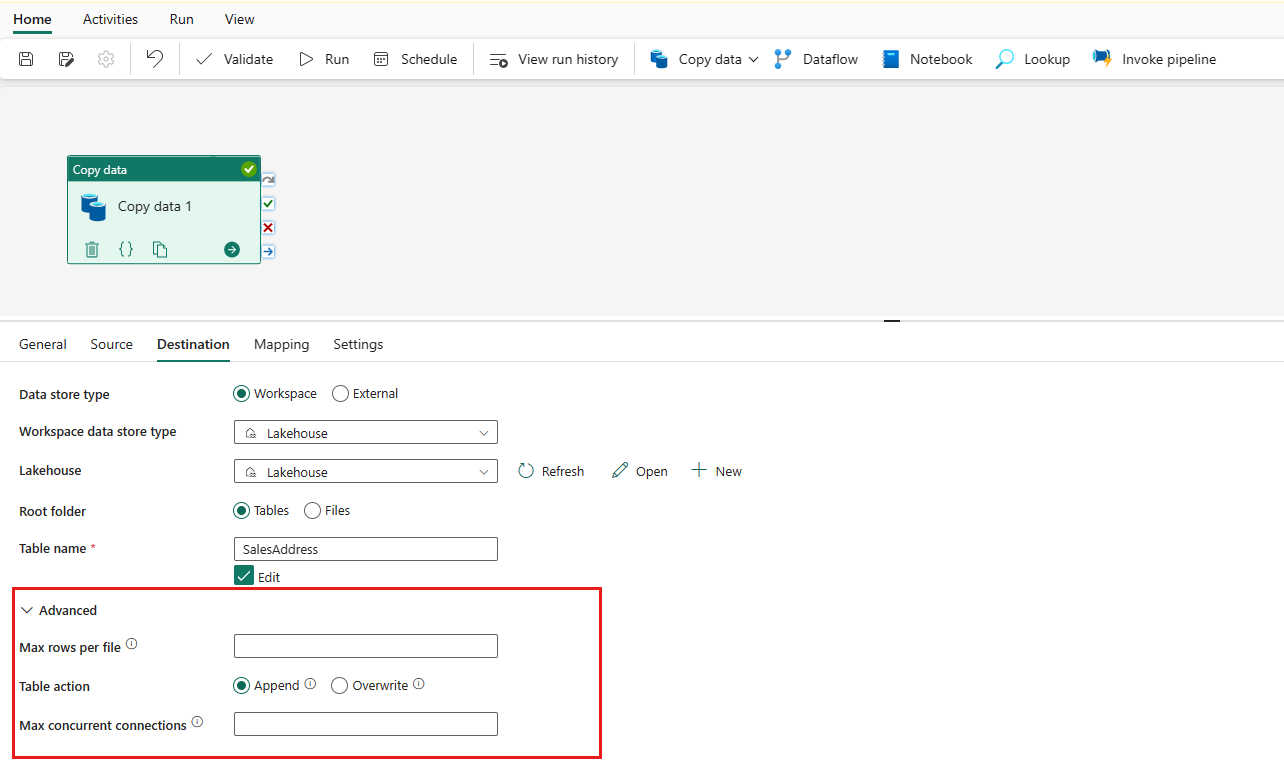
Especifique uma tabela ou configure o caminho do arquivo para definir o arquivo ou a pasta como o destino. Aqui, selecione Tabelas e especifique uma tabela para gravar dados.

Expanda Avançado para configurações mais avançadas.





Agora você pode salvar seu pipeline de dados com essa atividade de cópia única ou continuar a projetar seu pipeline de dados.
Configurar seus mapeamentos na guia mapeamento
Se o conector que você aplicar der suporte ao mapeamento, você poderá acessar a guia Mapeamento para configurar o mapeamento.
Selecione Importar esquemas para importar o esquema de dados.

Você pode ver que o mapeamento automático é mostrado. Especifique a coluna Origem e a coluna Destino. Se você criar uma nova tabela no destino, poderá personalizar o nome da coluna Destino aqui. Se você quiser gravar dados na tabela de destino existente, não poderá modificar o nome da coluna Destino existente. Você também pode exibir as colunas Tipo de origem e destino.
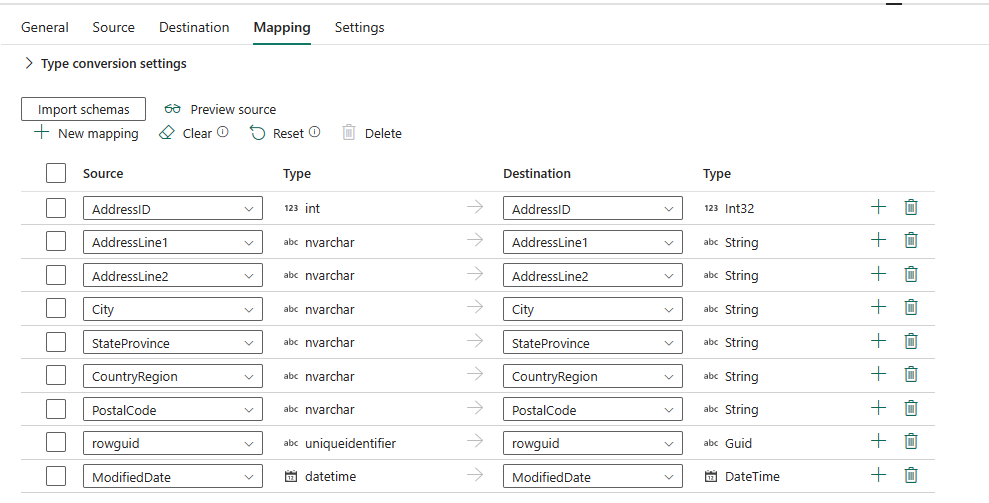


Além disso, você pode selecionar + Novo mapeamento para adicionar novo mapeamento, selecione Limpar para limpar todas as configurações de mapeamento e selecione Redefinir para redefinir todas as colunas fonte de mapeamento.
Definir suas outras configurações na guia configurações
A guia Configurações contém as configurações de desempenho, preparo e assim por diante.

Consulte a tabela a seguir para obter uma descrição de cada elemento do arquivo.
| Configuração | Descrição | Propriedade do script JSON |
|---|---|---|
| Otimização de taxa de transferência inteligente | Especifique para otimizar a taxa de transferência. Você pode escolher entre: • Automático • Padrão • Equilibrado • Máximo. Ao escolher Automático, a configuração ideal é aplicada dinamicamente com base no seu par de destino de origem e no padrão de dados. Você também pode personalizar sua taxa de transferência e o valor personalizado pode ser de 2 a 256, enquanto o valor mais alto implica mais ganhos. |
dataIntegrationUnits |
| Grau de paralelismo de cópia | Especifique o grau de paralelismo que o carregamento de dados usaria. | parallelCopies |
| Tolerância a falhas | Ao selecionar essa opção, você pode ignorar alguns erros ocorridos no meio do processo de cópia. Por exemplo, linhas incompatíveis entre o repositório de origem e de destino, o arquivo que está sendo excluído durante a movimentação de dados etc. | • enableSkipIncompatibleRow • skipErrorFile: fileMissing fileForbidden invalidFileName |
| Habilitar o registro em log | Ao selecionar essa opção, você poderá registrar arquivos copiados em log, arquivos ignorados e linhas. | / |
| Habilitar o processo de preparo | Especifique se você deseja copiar os dados por meio de um armazenamento de preparo provisório. Habilite o preparo somente para os cenários benéficos. | enableStaging |
| Tipo de armazenamento de dados | Ao habilitar o preparo, você poderá escolher o Espaço de trabalho e o Externo como o tipo de armazenamento de dados. | / |
| Para o Espaço de trabalho | ||
| Workspace | Especifique para usar o armazenamento de preparo interno. | / |
| Para o Externo | ||
| Como preparar a conexão da conta | Especifique a conexão de um Armazenamento de Blobs do Azure ou Azure Data Lake Storage Gen2, que se refere à instância do Armazenamento que você usa como um armazenamento de preparo provisório. Crie uma conexão de preparo se você não a tiver. | conexão (em externalReferences) |
| Caminho de armazenamento | Especifique o caminho que você deseja que contenha os dados preparados. Se você não fornecer um caminho, o serviço criará um contêiner para armazenar os dados temporários. Especifique um caminho somente se você usar o Armazenamento com uma assinatura de acesso compartilhado ou precisar que os dados temporários fiquem em um local específico. | caminho |
| Habilitar a compactação | Especifica se os dados devem ser compactados antes de serem copiados para o destino. Essa configuração reduz o volume de dados que são transferidos. | enableCompression |
| Preserve | Especifique se deseja preservar metadados/ACLs durante a cópia de dados. | preservar |
Observação
Caso usar a cópia preparada com a compactação ativada, a autenticação da entidade de serviço para conexão de blob de preparo não será compatível.
Configurar parâmetros em uma atividade de cópia
Os parâmetros podem ser usados para controlar o comportamento de um pipeline e suas atividades. Você pode usar Adicionar conteúdo dinâmico para especificar parâmetros para suas propriedades da atividade de cópia. Vamos tomar como exemplo a especificação do Lakehouse/Data Warehouse/Banco de Dados KQL para ver como usar o recurso.
Em sua origem ou destino, após selecionar Workspace como o tipo de armazenamento de dados e especificar o Lakehouse/Data Warehouse/Banco de Dados KQL como o tipo de armazenamento de dados do espaço de trabalho, selecione Adicionar conteúdo dinâmico na lista suspensa do Lakehouse ou Data Warehouse ou Banco de Dados KQL.
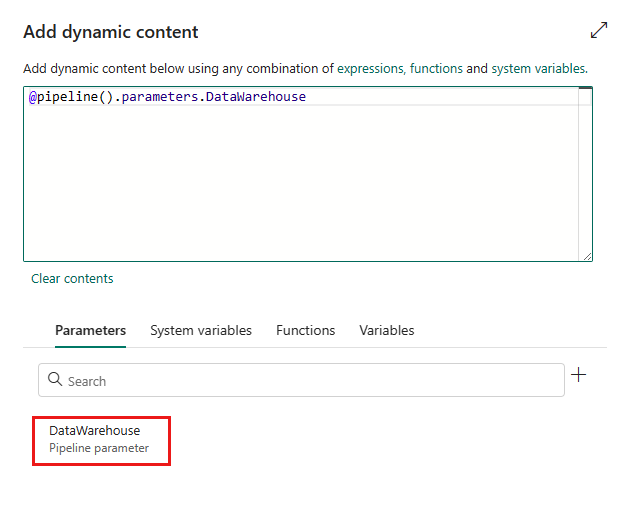
No painel pop-up Adicionar conteúdo dinâmico, na guia Parâmetros, selecione +.
Especifique o nome do seu parâmetro e dê a ele um valor padrão, se quiser, ou você pode especificar o valor para o parâmetro após selecionar Executar no pipeline.

Observe que o valor do parâmetro deve ser a ID de objeto do Lakehouse/Data Warehouse/Banco de Dados KQL. Para obter a ID do objeto Lakehouse/Data Warehouse/Banco de Dados KQL, abra o Lakehouse/Data Warehouse/Banco de Dados KQL no seu workspace e a ID estará depois de
/lakehouses/ou/datawarehouses/ou/databases/no seu URL.ID de objeto do Lakehouse:

ID de objeto do Data Warehouse:

ID do objeto do Banco de Dados KQL:

Selecione Salvar para retornar ao painel Adicionar conteúdo dinâmico. Em seguida, selecione o parâmetro para que ele apareça na caixa de expressão. Depois, selecione OK. Você voltará para a página do pipeline e poderá ver que a expressão do parâmetro está especificada após a ID do objeto do Lakehouse/ID do objeto do Data Warehouse ID/ID do objeto Banco de Dados KQL.