Transformar dados executando um notebook do Synapse
A atividade Notebook no pipeline permite que você execute o Notebook criado no Microsoft Fabric. Você pode criar uma atividade do Notebook diretamente por meio da interface do usuário do Fabric. Este artigo fornece um passo a passo que descreve como criar uma atividade de Notebook usando a interface do usuário do Data Factory.
Adicionar uma atividade de Notebook a um pipeline
Essa seção descreve como usar uma atividade do Notebook em um pipeline.
Pré-requisitos
Para começar, você deve concluir os seguintes pré-requisitos:
- Uma conta de locatário com uma assinatura ativa. Crie uma conta gratuitamente.
- Um workspace é criado.
- Um notebook é criado em seu workspace. Para criar um notebook, consulte Como criar notebooks do Microsoft Fabric.
Criando a atividade
Crie um pipeline no seu workspace.
Procure por Notebook no painel Atividades do pipeline e arraste uma atividade de Pesquisa para a tela do pipeline.

Selecione a nova atividade Notebook na tela se ela ainda não estiver selecionada.
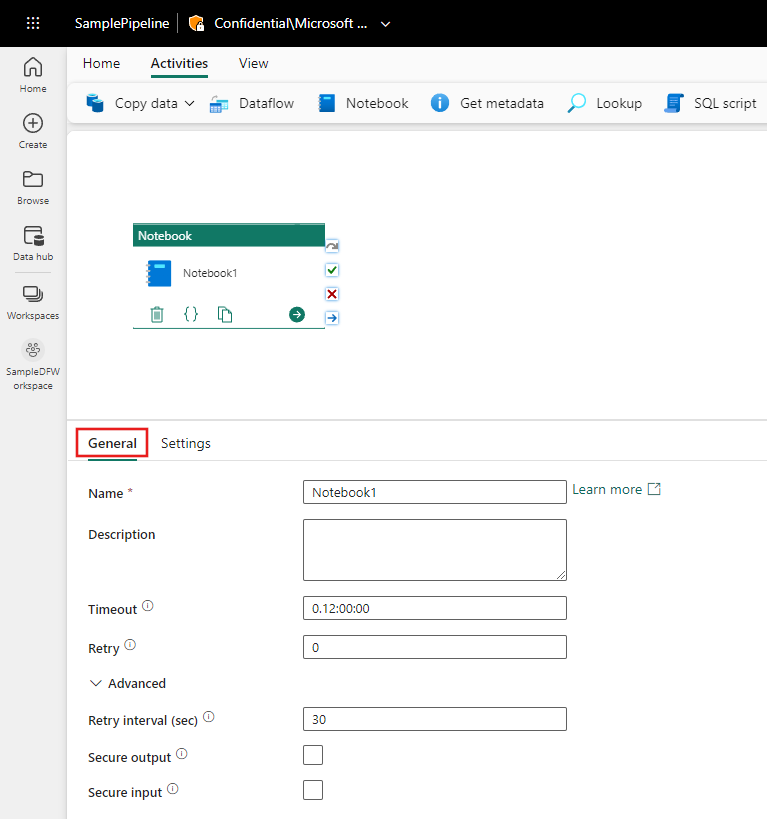
Consulte as diretrizes de Configurações Geraispara definir a guia Configurações Gerais.
Configurações do notebook
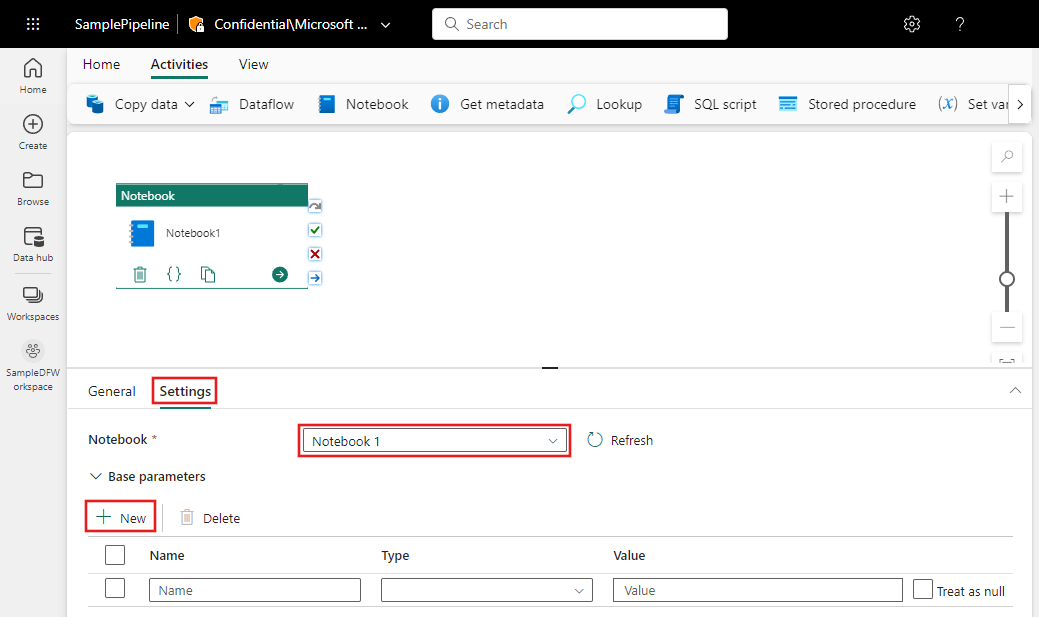
Selecione a guia Configurações , selecione um notebook existente na lista suspensa Notebook e, opcionalmente, especifique todos os parâmetros a serem passados para o notebook.
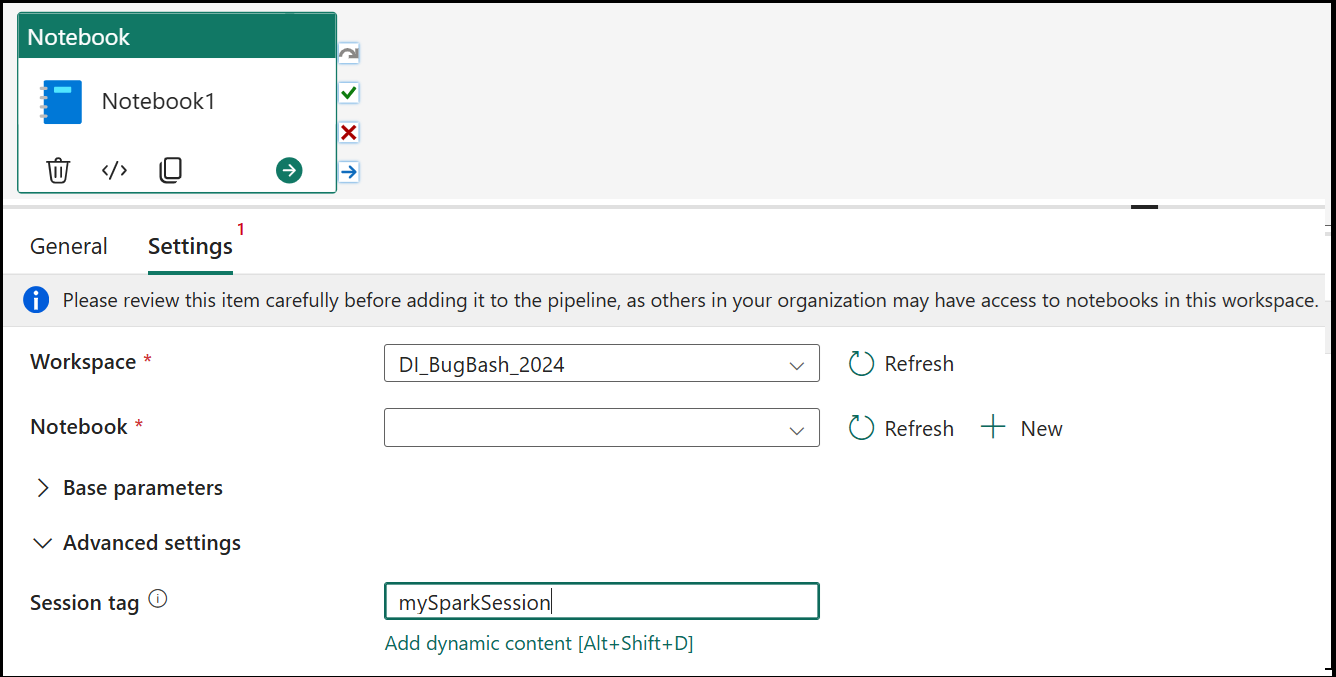
Tag de sessão
Para minimizar o tempo necessário para executar o trabalho do notebook, você pode, opcionalmente, definir uma tag de sessão. Definir a tag de sessão instruirá o Spark a reutilizar qualquer sessão existente do Spark, minimizando assim o tempo de inicialização. Qualquer valor de string arbitrário pode ser usado para a tag de sessão. Se não houver sessão, uma nova será criada usando o valor da tag.
Observação
Para poder usar a tag de sessão, a opção Modo de alta simultaneidade para pipeline que executa vários notebooks deve estar ativada. Essa opção pode ser encontrada no modo de alta simultaneidade para configurações do Spark nas configurações do Workspace

Salvar e executar ou agendar o pipeline
Alterne para a guia Página Inicial na parte superior do editor de pipeline e selecione o botão Salvar para salvar o pipeline. Selecione Executar para executá-lo diretamente ou Agendar para agendá-lo. Você também pode exibir o histórico de execuções aqui ou definir outras configurações.
