Analisar dados do Microsoft Graph no armazenamento de dados
Este artigo descreve um padrão de integração comum do Microsoft Graph para um cenário empresarial que requer uma análise complexa dos dados de colaboração empresarial para melhorar os processos de negócio e a produtividade.
Este cenário baseia-se numa grande quantidade de dados extraídos do Microsoft 365 e tem os seguintes requisitos:
- Um tipo de integração de dados.
- Um fluxo de dados de saída dos limites do Microsoft 365 para a aplicação.
- Um elevado volume de dados que abrange vários meses.
- Uma latência de dados relativamente elevada; a extração de dados inicial pode incluir mensagens com até um ano de idade.
A melhor opção para este cenário é utilizar o Microsoft Graph Data Connect. O cliente tem de configurar o armazenamento de dados de alta capacidade, como o Azure Data Lake ou o Azure Synapse, ativar uma subscrição do Azure e configurar um pipeline de Azure Data Factory ou Azure Synapse.
O diagrama seguinte mostra a arquitetura desta solução.
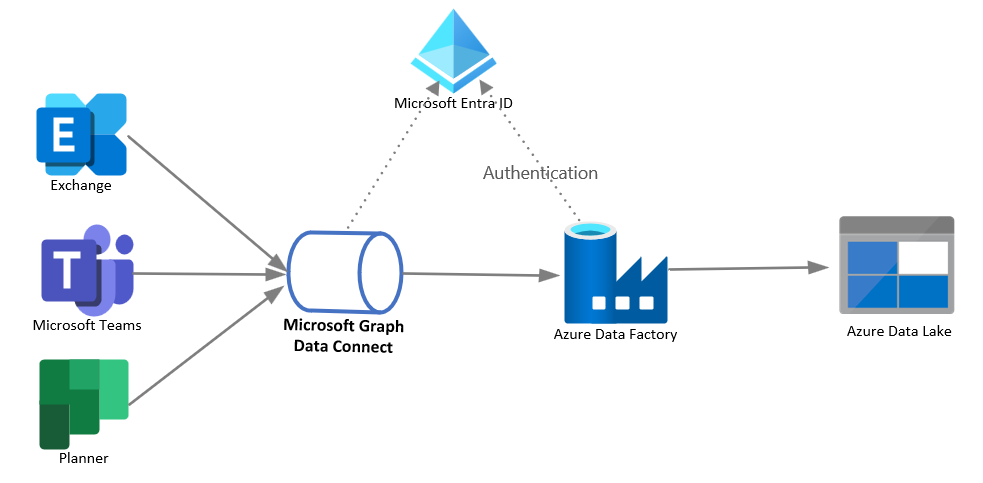
Componentes da solução
A arquitetura da solução inclui os seguintes componentes:
- O Microsoft Graph Data Connect, que permite a extração de dados do Microsoft 365 em escala com consentimento de dados granular e suporta todas as capacidades de serviço nativas do Azure, como encriptação, barreira geográfica, auditoria e imposição de políticas.
- Azure Data Factory (ADF), que permite uma construção fácil de ETL (extração, transformação e carga) e ELT (extração, carregamento e transformação) processa sem código num ambiente intuitivo ou escrevendo o seu código.
- O Azure Data Lake, que lhe permite manter grandes quantidades de dados estruturados e não estruturados em diferentes formatos.
- Microsoft Entra ID, que é necessário para gerir a autenticação para as APIs do Microsoft Graph e suporta permissões delegadas e de aplicação para ativar o fluxo OAuth.
Considerações
As seguintes considerações suportam a utilização deste padrão de integração:
Disponibilidade: o ADF do cliente pode extrair dados em massa na sua agenda ou numa base ad hoc.
Latência: a latência de dados neste cenário pode variar consoante a extração de dados históricos ou a entrega de dados mais recentes no armazenamento do Microsoft Graph Data Connect por processos assíncronos executados como tarefas agendadas. O desempenho do extrato de dados grandes do ADF é mais rápido do que as APIs HTTP granulares porque o ADF utiliza a criação de batches e a transferência de ficheiros.
Escalabilidade: esta arquitetura permite-lhe desenvolver pipelines que maximizam o débito de movimento de dados para o seu ambiente. Estes pipelines podem utilizar totalmente os seguintes recursos:
- Largura de banda de rede entre os arquivos de dados de origem e de destino.
- As operações de entrada/saída de dados de origem ou de destino por segundo (IOPS) e largura de banda.
Complexidade da solução: esta solução de saída de dados é de baixa complexidade do ponto de vista da integração porque não requer código personalizado, tem poucos componentes e é tolerante à latência de dados.