Exportar dados do Dataverse no formato Delta Lake
Use o Azure Synapse Link for Dataverse para exportar seus dados do Microsoft Dataverse para o Azure Synapse Analytics no formato Delta Lake. Em seguida, explore seus dados e acelere o tempo de obtenção de insights. Este artigo fornece as seguintes informações e mostra como executar as seguintes tarefas:
- Explica o Delta Lake e o Parquet e por que você deve exportar dados neste formato.
- Exporte seus dados do Dataverse para seu espaço de trabalho do Azure Synapse Analytics no formato Delta Lake com o Azure Synapse Link.
- Monitore seu Azure Synapse Link e a conversão de dados.
- Visualize seus dados do Azure Data Lake Storage Gen2.
- Visualize seus dados da área de trabalho do Synapse.
Importante
- Se você estiver atualizando de CSV para Delta Lake com exibições personalizadas existentes, é recomendável atualizar o script para substituir todas as tabelas particionadas para non_partitioned. Faça isso procurando instâncias de
_partitionede substitua-as por uma cadeia de caracteres vazia. - Para a configuração do Dataverse, a função somente anexar é ativada por padrão para exportar dados CSV no modo
appendonly. Porém, a tabela Delta Lake terá uma estrutura de atualização em vigor, já que a conversão do Delta Lake vem com um processo de mesclagem periódico. - Não há custos incorridos com a criação de pools do Spark. As cobranças são incorridas apenas quando um trabalho do Spark for executado no pool do Spark de destino e quando a instância do Spark forstanciada sob demanda. Esses custos estão relacionados ao uso do espaço de trabalho Spark do Azure Synapse e são cobrados mensalmente. O custo de executar computação do Spark depende principalmente do intervalo de tempo para atualização incremental e dos volumes de dados. Mais informações: Preços do Azure Synapse Analytics
- É importante levar em consideração esses custos adicionais ao decidir usar esse recurso, pois eles não são opcionais e devem ser pagos para continuar usando esse recurso.
- O fim do serviço anunciado (EOLA) do Runtime do Azure Synapse para Apache Spark 3.1 foi anunciado em 26 de janeiro de 2023. De acordo com a política do ciclo de vida de runtime do Synapse para Apache Spark, o runtime do Azure Synapse para Apache Spark 3.1 será desativado e desabilitado a partir de 26 de janeiro de 2024. Após a data de EOL, os runtimes desativados não permanecerão disponíveis para novos pools do Spark, e os fluxos de trabalho existentes não poderão ser executados. Os metadados vão permanecer temporariamente no espaço de trabalho do Synapse. Mais informações: Runtime do Azure Synapse para Apache Spark 3.1 (EOLA). Para fazer com que o Link do Synapse para Dataverse com exportação para formato Delta Lake seja atualizado para o Spark 3.3, faça uma atualização in-loco para os perfis existentes. Mais informações: IAtualização in-loco para Apache Spark 3.3 com Delta Lake 2.2
- A partir de 4 de janeiro de 2024, somente o Pool do Spark versão 3.3 será compatível durante a criação inicial do link.
Observação
O status do Azure Synapse Link no Power Apps (make.powerapps.com) reflete o estado de conversão do Delta Lake:
Countmostra o número de registros na tabela do Delta Lake.Last synchronized onDatetime representa o carimbo de data/hora da última conversão bem-sucedida.Sync statusé mostrado como ativo assim que a sincronização de dados e a conversão do Delta Lake forem concluídas, indicando que os dados estão prontos para consumo.
O que é um Delta Lake?
Delta Lake é um projeto de código aberto que permite construir uma arquitetura de lakehouse sobre Data Lakes. O Delta Lake fornece transações ACID (atomicidade, consistência, isolamento e durabilidade), manipulação de metadados escalonáveis e unificação de streaming e processamento de dados em lote sobre os Data Lakes existentes. O Azure Synapse Analytics é compatível com Linux Foundation Delta Lake. A versão atual do Delta Lake incluída no Azure Synapse tem suporte de linguagem para Scala, PySpark e .NET. Mais informações: O que é o Delta Lake? Você também pode aprender mais com o Vídeo de introdução às Delta Tables.
O Apache Parquet é o formato de linha de base para o Delta Lake, permitindo que você aproveite os esquemas eficientes de compactação e codificação nativos do formato. O formato de arquivo Parquet usa compactação em colunas. É eficiente e economiza espaço de armazenamento. As consultas que buscam valores de coluna específicos não precisam ler os dados da linha inteira, melhorando assim o desempenho. Portanto, o pool de SQL sem servidor precisa de menos tempo e menos solicitações de armazenamento para ler os dados.
Por que usar um Delta Lake?
- Escalabilidade: o Delta Lake foi desenvolvido com base na licença Apache de código aberto, projetada para atender aos padrões do setor para lidar com workloads de processamento de dados em larga escala.
- Confiabilidade: o Delta Lake fornece transações ACID, garantindo consistência e confiabilidade de dados mesmo diante de falhas ou acessos simultâneos.
- Desempenho: o Delta Lake aproveita o formato de armazenamento em colunas do Parquet, fornecendo melhores técnicas de compactação e codificação, o que pode levar a um melhor desempenho de consulta em comparação com arquivos CSV de consulta.
- Custo-beneficio: o formato de arquivo Delta Lake é uma tecnologia de armazenamento de dados altamente compactada que oferece um potencial significativo de economia de armazenamento para empresas. Esse formato foi projetado especificamente para otimizar o processamento de dados e potencialmente reduzir a quantidade total de dados processados ou o tempo de execução necessário para a computação sob demanda.
- Conformidade com a proteção de dados: o delta Lake com o Azure Synapse Link fornece ferramentas e recursos, incluindo exclusão reversível e exclusão irreversível para estar em conformidade com vários regulamentos de privacidade de dados, incluindo o Regulamento Geral sobre a Proteção de Dados (RGPD).
Como o delta lake funciona com o Azure Synapse Link for Dataverse?
Ao configurar um Azure Synapse Link for Dataverse, você pode habilitar o recurso exportação para Delta Lake recurso e conectar-se a um espaço de trabalho do Synapse e ao pool do Spark. O Azure Synapse Link exporta as tabelas do Dataverse selecionadas em formato CSV em intervalos de tempo designados, processando-as por meio de um trabalho do Spark de conversão do Delta Lake. Após a conclusão desse processo de conversão, os dados CSV ficam limpos para economia de armazenamento. Além disso, uma série de tarefas de manutenção são programadas para serem executadas diariamente, executando automaticamente processos de compactação e aspiração para mesclar e limpar arquivos de dados, otimizando ainda mais o armazenamento e melhorando o desempenho das consultas.
Pré-requisitos
- Dataverse: você deve ter o direito de acesso administrador do sistema no Dataverse. Além disso, as tabelas pelas quais você deseja exportar o Azure Synapse Link devem ter a propriedade Controlar alterações habilitada. Mais Informações: Opções avançadas
- Azure Data Lake Storage Gen2: você deve ter uma conta do Azure Data Lake Storage Gen2 e o acesso de funções Proprietário e Colaborador de Dados do Blob de Armazenamento. Sua conta de armazenamento deve habilitar o Namespace hierárquico e o acesso à rede pública para a configuração inicial e a sincronização delta. Permitir acesso à chave da conta de armazenamento é necessário apenas para a configuração inicial.
- Workspace do Synapse: você deve ter um workspace do Synapse, a função Proprietário em controle de acesso (IAM) e o acesso da função Administrador do Synapse no Synapse Studio. O workspace do Synapse deve estar na mesma região da sua conta do Azure Data Lake Storage Gen2. A conta de armazenamento deve ser adicionada como um serviço vinculado no Synapse Studio. Para criar um workspace do Synapse, vá para Criar um workspace do Synapse.
- Um Apache Spark pool no espaço de trabalho Azure Synapse conectado com a Apache Spark Versão 3.3 usando esta configuração recomendada do Spark Pool. Para obter informações sobre como criar uma solução com o Pool do Spark, acesse Criar um pool do Apache Spark.
- O requisito de versão mínima do Microsoft Dynamics 365 para usar esse recurso é 9.2.22082. Mais informações: Aceitar atualizações com acesso antecipado
Configuração de pool do Spark recomendada
Essa configuração pode ser considerada uma etapa de inicialização para casos de uso médios.
- Tamanho do nó: pequeno (4 vCores / 32 GB)
- Escala automática: habilitada
- Número de nós: 5 a 10
- Pausa automática: habilitada
- Número de minutos em tempo ocioso: 5
- Apache Spark: 3.3
- Alocar executores dinamicamente: habilitado
- Número padrão de executores: 1 a 9
Importante
Use o pool Spark exclusivamente para operação de conversação do Delta Lake com o Synapse vincular Dataverse. Para obter confiabilidade e desempenho ideais, evite executar outros trabalhos do Spark usando o mesmo pool do Spark.
Conecte o Dataverse à área de trabalho do Synapse e exporte dados em formato Delta Lake
Entre no Power Apps e selecione o ambiente desejado.
No painel de navegação à esquerda, selecione Azure Synapse Link. Se o item não estiver no painel lateral, selecione …Mais e selecione o item desejado.
Na barra de comandos, selecione + Novo link
Selecione Conectar-se ao seu espaço de trabalho do Azure Synapse Analytics e selecione Assinatura, Grupo de recursos e Nome do espaço de trabalho.
Selecione Usar Pool do Spark para o processamento e, em seguida, selecione o Pool do Spark pré-criados e a Conta de armazenamento.
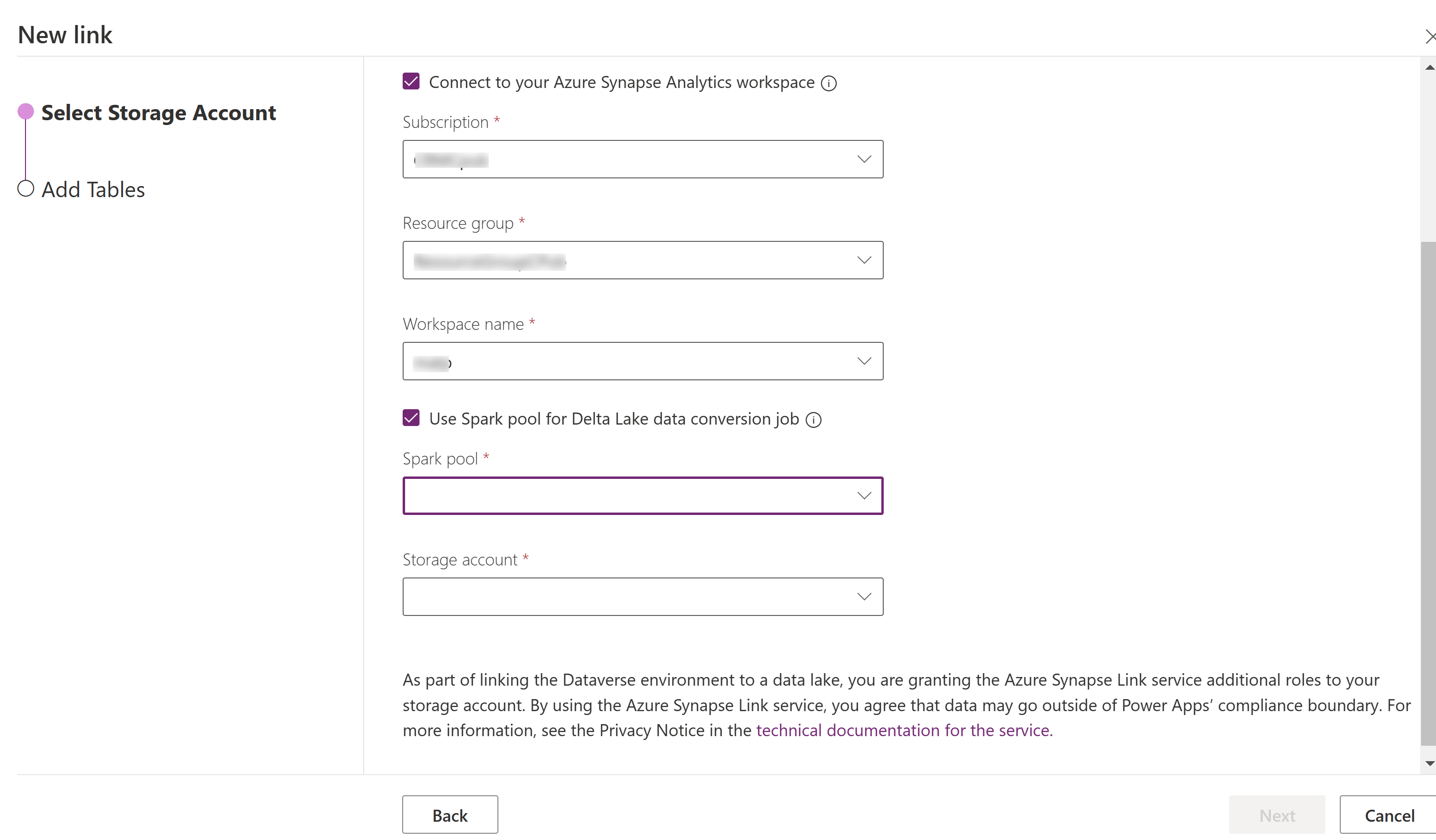
Selecione Avançar
Adicione as tabelas que deseja exportar e selecione Avançado.
De outro modo, selecione Mostrar configurações avançadas e insira o intervalo de tempo em minutos para a frequência com que as atualizações incrementais devem ser capturadas.
Selecione Salvar.
Monitore seu Azure Synapse Link e a conversão de dados
- Selecione o Azure Synapse Link desejado e, em seguida, selecione Ir para a área de trabalho do Azure Synapse Analytics na barra de comando.
- Selecione Monitorar > Aplicativos do Apache Spark. Mais informações: Usar o Synapse Studio para monitorar seus aplicativos do Apache Spark
Visualize seus dados da área de trabalho do Synapse
- Selecione o Azure Synapse Link desejado e, em seguida, selecione Ir para a área de trabalho do Azure Synapse Analytics na barra de comando.
- Expanda Bancos de dados do Lake no painel esquerdo, selecione dataverse-environmentNameorganizationUniqueName e, em seguida, expanda Tabelas. Todas as tabelas do Parquet estão listadas e disponíveis para análise com a convenção de nomenclatura DataverseTableName. (Non_partitioned Table).
Observação
Não use tabelas com a convenção e nomenclatura _partitioned. Quando você escolhe o formato Delta parquet, as tabelas com a convenção de nomenclatura _partition são usadas como tabelas de preparo e removidas depois de usadas pelo sistema.
Visualize seus dados do Azure Data Lake Storage Gen2
- Selecione o Azure Synapse Link desejado e, em seguida, selecione Acessar o Azure Data Lake na barra de comandos.
- Selecione os Contêineres em Armazenamento de Dados.
- Selecione *dataverse- *environmentName-organizationUniqueName. Todos os arquivos do Parquet são armazenados na pasta deltalake.
Atualização in-loco para Apache Spark 3.3 com Delta Lake 2.2
Pré-requisitos
- Você deve ter um perfil Delta Lake do Azure Synapse Link for Dataverse existente em execução com um Synapse Spark versão 3.1.
- Você deve criar um novo pool do Spark Synapse com o Spark versão 3.3, usando a mesma configuração de hardware dos nós ou superior dentro do mesmo espaço de trabalho do Synapse. Para obter informações sobre como criar uma solução com o Pool do Spark, acesse Criar um pool do Apache Spark. Esse pool do Spark deve ser criado independentemente do pool 3.1 atual.
Atualização in-loco para o Spark 3.3:
- Entre no Power Apps e selecione o ambiente preferido.
- No painel de navegação à esquerda, selecione Azure Synapse Link. Se o item não estiver no painel de navegação esquerdo, selecione …More e selecione o item desejado.
- Abra o perfil do Azure Synapse Link e selecione Atualizar para o Apache Spark 3.3 com o Delta Lake 2.2.
- Selecione o pool do Spark disponível na lista e Atualizar.
Observação
A atualização do pool do Spark só ocorre quando um novo trabalho do Spark de conversão do Delta Lake é disparado. Verifique se você tem pelo menos uma alteração de dados após a seleção de Atualizar.