Desenvolver soluções com fluxos de dados
Os fluxos de dados do Power BI são uma solução de preparação de dados voltada para empresas que permite o uso de um ecossistema de dados pronto para consumo, reutilização e integração. Este artigo apresenta alguns cenários comuns, links para artigos e outras informações para ajudá-lo a entender e aproveitar ao máximo os fluxos de dados.
Obter acesso aos recursos Premium de fluxos de dados
Os fluxos de dados do Power BI com capacidades Premium fornecem muitos recursos importantes que ajudam a obter escala e desempenho maiores para seus fluxos de dados, como:
- Computação avançada, que acelera o desempenho do ETL e fornece funcionalidades do DirectQuery.
- Atualização incremental, que permite carregar dados que foram alterados de uma fonte.
- Entidades vinculadas, que você pode usar para fazer referência a outros fluxos dados.
- Entidades computadas, que você pode usar para criar blocos de construção combináveis de fluxos de dados que contêm mais lógica de negócios.
Por esses motivos, recomendamos que você use fluxos de dados em uma capacidade Premium sempre que possível. Os fluxos de dados usados em uma licença do Power BI Pro podem ser usados para casos de uso simples e de pequena escala.
Solução
Há duas maneiras de se obter acesso a esses recursos Premium de fluxo de dados:
- Designar uma capacidade Premium a um determinado workspace e usar sua própria licença Pro para criar fluxos de dados aqui.
- Usar sua própria licença PPU (Premium por usuário) , que exige que outros membros do workspace também tenham uma licença PPU.
Não é possível consumir fluxos de dados do PPU (ou qualquer outro conteúdo) fora do ambiente PPU (como no Premium ou outros SKUs ou licenças).
Para capacidades Premium, seus consumidores de fluxos de dados no Power BI Desktop não precisam de licenças explícitas para consumir e publicar no Power BI. Mas para publicar em um workspace ou compartilhar um modelo semântico resultante, você precisa de pelo menos uma licença Pro.
Para PPU, todos que criam ou consomem conteúdo PPU devem ter uma licença PPU. Esse requisito varia de acordo com o restante do Power BI, em que você precisa licenciar explicitamente todos com PPU. Não é possível combinar funcionalidades Gratuitas, Pro ou até mesmo Premium com o conteúdo de PPU, a menos que migre o workspace para uma capacidade Premium.
A escolha de um modelo geralmente depende do tamanho e das metas da sua organização, mas se aplicam as diretrizes a seguir.
| Tipo de equipe | Premium por capacidade | Premium por usuário |
|---|---|---|
| >5.000 usuários | ✔ | |
| <5.000 usuários | ✔ |
Para equipes pequenas, o PPU pode preencher a lacuna entre as licenças Gratuita, Pro e Premium por capacidade. Se você tiver necessidades maiores, usar uma capacidade Premium com usuários que têm licenças Pro será a melhor abordagem.
Criar fluxos de dados de usuário com segurança aplicada
Imagine que você precisa criar fluxos de dados para consumo, mas tem requisitos de segurança:
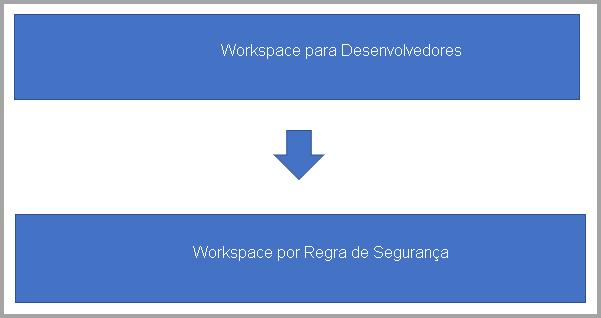
Nesse cenário, você provavelmente tem dois tipos de workspaces:
Workspaces de back-end em que você desenvolve fluxos de dados e cria a lógica de negócios.
Workspaces do usuário nos quais você deseja expor alguns fluxos de dados ou tabelas de um determinado grupo de usuários para consumo:
- O workspace do usuário contém tabelas vinculadas que apontam para os fluxos de dados no workspace de back-end.
- Os usuários têm acesso de espectador ao workspace do consumidor e não têm acesso ao workspace de back-end.
- Quando um usuário usa o Power BI Desktop para acessar um fluxo de dados no workspace do usuário, ele pode ver o fluxo de dados. Mas como o fluxo de dados aparece vazio no navegador, as tabelas vinculadas não são exibidas.
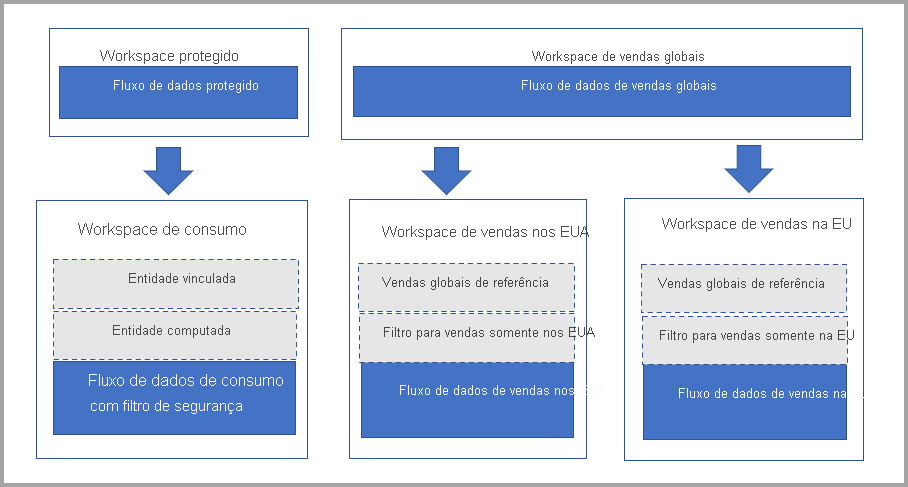
Entender as tabelas vinculadas
As tabelas vinculadas são simplesmente um ponteiro para as tabelas de fluxo de dados originais e elas herdam a permissão da origem. Se o Power BI permitisse que a tabela vinculada usasse a permissão de destino, qualquer usuário poderia burlar a permissão de origem criando uma tabela vinculada no destino que aponta para a origem.
Solução: usar tabelas computadas
Se você tiver acesso ao Power BI Premium, poderá criar uma tabela computada no destino que se refere à tabela vinculada, que possui uma cópia dos dados da tabela vinculada. Você pode remover as colunas por meio de projeções e remover as linhas por meio de filtros. O usuário com permissão no workspace de destino pode acessar dados por meio dessa tabela.
A linhagem para indivíduos privilegiados também mostra o workspace referenciado e permite que os usuários façam a vinculação de volta para entender totalmente o fluxo de dados pai. Para os usuários que não são privilegiados, a privacidade ainda é respeitada. Somente o nome do workspace é mostrado.
O diagrama a seguir ilustra essa instalação. À esquerda está o padrão de arquitetura. À direita está um exemplo que mostra os dados de vendas divididos e protegidos por região.
Reduzir os tempos de atualização para fluxos de dados
Imagine que você tem um grande fluxo de dados, mas deseja criar modelos semânticos a partir dele e diminuir o tempo necessário para atualizá-los. Normalmente, as atualizações demoram muito para serem concluídas a partir da fonte de dados até o fluxo de dados para o modelo semântico. As atualizações demoradas são difíceis de gerenciar ou manter.
Solução: usar tabelas com Habilitar Carga explicitamente configurada para tabelas referenciadas e não desabilitar carga
O Power BI oferece suporte à orquestração simples para fluxos de dados, conforme definido em noções básicas e otimização da atualização de fluxos de dados. Para tirar proveito da orquestração, é preciso explicitamente ter todos os fluxos de dados downstream configurados para Habilitar Carga.
Geralmente, a desabilitação da carga só é apropriada quando a sobrecarga do carregamento de mais consultas cancela o benefício da entidade com a qual você está desenvolvendo.
Embora a desabilitação da carga indique que o Power BI não avalia essa consulta, quando usada como ingredientes, ou seja, referenciada em outros fluxos de dados, isso também significa que Power BI não a trata como uma tabela existente, na qual podemos fornecer um ponteiro e executar otimizações de dobramento e consulta. Nesse sentido, a execução de transformações, como uma junção ou uma mesclagem, é meramente uma junção ou mesclagem de duas consultas de fonte de dados. Essas operações podem ter um efeito negativo no desempenho, porque o Power BI deve recarregar totalmente a lógica já calculada novamente e, em seguida, aplicar mais lógica.
Para simplificar o processamento de consultas de seu fluxo de dados e garantir que quaisquer otimizações do mecanismo estejam em vigor, habilite a carga e verifique se o mecanismo de computação em fluxo de dados do Power BI Premium está definido na configuração padrão, que é Otimizada.
Habilitar a carga também permite que você mantenha a visão completa da linhagem, porque o Power BI considera um fluxo de dados de carga não habilitado como um novo item. Se a linhagem for importante para você, não desabilite a carga para entidades ou fluxos de dados conectados a outros fluxos de dados.
Reduzir os tempos de atualização para modelos semânticos
Imagine que você tem um fluxo de dados grande, mas deseja criar modelos semânticos a partir dele e diminuir a orquestração. As atualizações demoram muito para serem concluídas, desde a fonte de dados até os fluxos de dados e até os modelos semânticos, o que aumenta a latência.
Solução: usar fluxos de dados do DirectQuery
O DirectQuery pode ser usado sempre que a configuração de ECE (mecanismo de computação avançado) de um workspace estiver configurada explicitamente como Ativado. Essa configuração é útil quando você tem dados que não precisam ser carregados diretamente em um modelo do Power BI. Se você estiver configurando o ECE para ser Ativado pela primeira vez, as alterações que permitem o DirectQuery ocorrerão durante a próxima atualização. Você precisa atualizá-lo ao habilitá-lo para que as alterações ocorram imediatamente. As atualizações na carga de fluxo de dados inicial podem ser mais lentas, porque o Power BI grava dados no armazenamento e em um mecanismo de SQL gerenciado.
Para resumir, o uso do DirectQuery com fluxos de dados permite os seguintes aprimoramentos aos seus processos de Power BI e de fluxo de dados:
- Evitar agendas de atualização separadas: o DirectQuery se conecta diretamente a um fluxo de dados, que elimina a necessidade de criar um modelo semântico importado. Dessa forma, o uso do DirectQuery com seus fluxos de dados significa que não há mais necessidade de agendar atualizações separadamente para o fluxo de dados e o modelo semântico a fim de garantir que os dados fiquem sincronizados.
- Filtragem de dados: o DirectQuery é útil para trabalhar em uma exibição filtrada de dados dentro de um fluxo de dados. Se você quiser filtrar os dados e, dessa forma, trabalhar com um subconjunto menor dos dados em seu fluxo de dados, poderá usar o DirectQuery (e o ECE) para filtrar os dados do fluxo de dados e trabalhar com o subconjunto filtrado de que precisar.
Em geral, o uso do DirectQuery obterá dados atualizados em seu modelo semântico, mas terá um desempenho de relatório mais lento em comparação com o modo de importação. Considere essa abordagem somente quando:
- Seu caso de uso necessitar de dados de baixa latência provenientes do seu fluxo de dados.
- Os dados do fluxo de dados forem grandes.
- Uma importação seria muito demorada.
- Você está disposto a trocar o desempenho em cache por dados atualizados.
Solução: use o conector do fluxos de dados para habilitar a dobragem de consulta e a atualização incremental para importação
O conector de fluxo de dados unificados pode reduzir significativamente o tempo de avaliação das etapas executadas em relação a entidades computadas, como a execução de junções, distinções, filtros e operações de agrupamento. Há dois benefícios específicos:
- Os usuários downstream que se conectarem ao conector de fluxos de dados no Power BI Desktop podem obter um desempenho melhor em cenários de criação, porque o novo conector dá suporte à dobragem de consulta.
- As operações de atualização de modelo semântico também podem ser dobradas para o mecanismo de computação aprimorado, o que significa que até mesmo a atualização incremental de um modelo semântico pode ser dobrada para um fluxo de dados. Essa funcionalidade melhora o desempenho da atualização e reduz potencialmente a latência entre os ciclos de atualização.
Para habilitar esse recurso para qualquer fluxo de dados Premium, verifique se o mecanismo de computação está definido explicitamente como Ativado. Depois, use o conector de fluxos de dados no Power BI Desktop. Para poder utilizar esse recurso, use a versão de agosto de 2021 ou posterior do Power BI Desktop.
Para utilizar esse recurso para as soluções existentes, você deve ter uma assinatura Premium ou PPU. Talvez você também precise fazer algumas alterações em seu fluxo de dados, conforme descrito em Usar o mecanismo de computação aprimorado. Você deve atualizar todas as consultas existentes do Power Query para usar o novo conector, substituindo PowerBI.Dataflows na seção de Origem por PowerPlatform.Dataflows.
Criação de fluxo de dados complexa no Power Query
Imagine que você tem um fluxo de dados com milhões de linhas, mas deseja usá-lo para criar uma lógica de negócios complexa e transformações. Você deseja seguir as melhores práticas para trabalhar com grandes fluxos de trabalho. Você também precisa que as visualizações de fluxo de dados sejam executadas rapidamente. Mas você tem dezenas de colunas e milhões de linhas de dados.
Solução: usar a Exibição de esquema
Você pode usar a Exibição de esquema, que é projetada para otimizar seu fluxo ao trabalhar em operações de nível de esquema, colocando as informações de coluna da consulta na frente e no centro. A exibição de esquema fornece interações contextuais para formatar sua estrutura de dados. A exibição de esquema também fornece operações de latência mais baixa, porque requer apenas que os metadados de coluna sejam computados e não os resultados de dados completos.
Trabalhar com fontes de dados maiores
Imagine que você executará uma consulta no sistema de origem, mas não deseja fornecer acesso direto ao sistema nem democratizar o acesso. Você planeja colocá-lo em um fluxo de dados.
Solução 1: usar uma exibição para a consulta ou otimizar a consulta
A melhor opção é usar uma fonte de dados otimizada e uma consulta. Frequentemente a fonte de dados opera melhor com as consultas destinadas a ela. O Power Query avança os recursos de dobramento de consulta para delegar essas cargas de trabalho. O Power BI também fornece indicadores de dobragem de etapas no Power Query Online. Leia mais sobre os tipos de indicadores na documentação de indicadores de dobragem de etapa.
Solução 2: usar uma consulta nativa
Você também pode usar a função M Value.NativeQuery(). Você define EnableFolding=true no terceiro parâmetro. A Consulta Nativa está documentada neste site para o conector do Postgres. Ele também funciona para o conector do SQL Server.
Solução 3: quebre o fluxo de dados em fluxos de dados de ingestão e consumo para aproveitar o ECE e as Entidades Vinculadas
Ao quebrar um fluxo de dados em fluxos de dados separados de ingestão e consumo, você pode aproveitar o ECE e as Entidades Vinculadas. Você pode saber mais sobre esse e outros padrões na documentação de melhores práticas.
Garantir que os clientes usem fluxos de dados sempre que possível
Imagine que você tem muitos fluxos de dados que atendem a finalidades comuns, por exemplo, dimensões conformadas, como clientes, tabelas de dados, produtos e geografias. Os fluxos de dados já estão disponíveis na faixa de opções do Power BI. Idealmente, você deseja que os clientes usem principalmente os fluxos de dados que você criou.
Solução: usar endossos para certificar e promover fluxos de dados
Para saber mais sobre como o endosso funciona, confira Endosso: promoção e certificação do conteúdo do Power BI.
Programação e automação em fluxos de dados do Power BI
Imagine que você tem requisitos de negócios para automatizar importações, exportações ou atualizações, além de mair orquestrações e ações fora do Power BI. Algumas opções para habilitar essa ação estão descritas na tabela a seguir.
| Tipo | Mecanismo |
|---|---|
| Usar os modelos do PowerAutomate. | Sem código |
| Usar scripts de automação no PowerShell. | Scripts de automação |
| Criar sua própria lógica de negócios usando as APIs. | API Rest |
Para obter mais informações sobre a atualização, confira Reconhecimento e otimização da atualização de fluxos de dados.
Garantir a proteção do downstream dos ativos de dados
Você pode usar rótulos de confidencialidade para aplicar uma classificação de dados e quaisquer regras configuradas em itens downstream que se conectam aos seus fluxos de dados. Para saber mais sobre os rótulos de confidencialidade, confira Rótulos de confidencialidade no Power BI. Para analisar a herança, veja Herança de downstream do rótulo de confidencialidade no Power BI.
Suporte multigeográfico
Atualmente, há muitos clientes que precisam atender aos requisitos de soberania e residência de dados. Você pode concluir uma configuração manual do seu workspace de fluxos de dados para ter múltiplas áreas geográficas.
Os fluxos de armazenamento têm suporte multigeográfico quando usam o recurso traga sua conta de armazenamento. Esse recurso está descrito em Como configurar o armazenamento de fluxos de dados para usar o Azure Data Lake Gen 2. O workspace deve estar vazio antes de anexar essa funcionalidade. Com essa configuração específica, você pode armazenar dados de fluxo de dados em regiões geográficas da sua escolha.
Garantir que você proteja os ativos de dados por trás de uma rede virtual
Atualmente, há muitos clientes que precisam proteger seus ativos de dados por trás de um ponto de extremidade privado. Para isso, use redes virtuais e um gateway para permanecer em conformidade. A tabela a seguir descreve o atual suporte à rede virtual e explica como usar fluxos de dados para permanecer em conformidade e proteger seus ativos de dados.
| Cenário | Status |
|---|---|
| Ler fontes de dados de rede virtual por meio de um gateway local. | Com suporte por meio de um gateway local |
| Grave dados em uma conta de rótulo de sensibilidade por trás de uma rede virtual usando um gateway local. | Ainda não compatível |
Conteúdo relacionado
Os seguintes artigos fornecem mais informações sobre os fluxos de dados e o Power BI: