O que é um grupo de disponibilidade Always On?
Aplica-se a: ![]() SQL Server
SQL Server
Este artigo apresenta os conceitos fundamentais do Grupos de disponibilidade AlwaysOn para configurar e gerenciar um ou mais grupos de disponibilidade na edição Enterprise do SQL Server. Para a edição Standard, examine Grupos de disponibilidade Always On básicos para um banco de dados individual.
O recurso Grupos de disponibilidade AlwaysOn é uma solução de alta disponibilidade e de recuperação de desastres que fornece uma alternativa em nível corporativo para espelhamento de banco de dados. Grupos de disponibilidade AlwaysOn maximizam a disponibilidade de um conjunto de bancos de dados de usuário para uma empresa. Um grupo de disponibilidade dá suporte a um ambiente de failover para um conjunto discreto de bancos de dados de usuário, conhecidos como bancos de dados de disponibilidade, que fazem failover juntos. Um grupo de disponibilidade dá suporte a um conjunto de bancos de dados primários de leitura/gravação e a um dos oito conjuntos de bancos de dados secundários correspondentes. Opcionalmente, é possível tornar disponíveis os bancos de dados secundários para acesso somente leitura e/ou algumas operações de backup.
Com o SQL Server habilitado pelo Azure Arc, você pode exibir grupos de disponibilidade no portal do Azure.
Visão geral
Um grupo de disponibilidade dá suporte a um ambiente replicado para um conjunto discreto de bancos de dados de usuário, conhecidos como bancos de dados de disponibilidade. Crie um grupo de disponibilidade para HA (alta disponibilidade) ou escala de leitura. Um grupo de disponibilidade HA é um grupo de bancos de dados que fazem failover juntos. Um grupo de disponibilidade de escala de leitura é um grupo de bancos de dados que são copiados para outras instâncias do SQL Server para carga de trabalho somente leitura. Um grupo de disponibilidade dá suporte a um conjunto de bancos de dados primários e de um a oito conjuntos de bancos de dados secundários correspondentes. Bancos de dados secundários não são backups. Continue para fazer backup dos bancos de dados e de seus logs de transações regularmente.
Dica
Você pode criar qualquer tipo de backup de um banco de dados primário. Como alternativa, você pode criar backups de log e backups completos somente cópia dos bancos de dados secundários. Para mais informações, confira Descarregar backups com suporte em réplicas secundárias de um grupo de disponibilidade.
Cada conjunto de bancos de dados de disponibilidade é hospedado por uma réplica de disponibilidade. Existem dois tipos de réplicas de disponibilidade: uma única réplica primária, que hospeda os bancos de dados primários, e de uma a oito réplicas secundárias, cada uma hospedando um conjunto de bancos de dados secundários e atuando como destinos de failover em potencial para o grupo de disponibilidade. Um grupo de disponibilidade faz failover no nível de uma réplica de disponibilidade. Uma réplica de disponibilidade fornece redundância somente no nível do banco de dados para o conjunto de bancos de dados em um grupo de disponibilidade. Os failovers não são provocados por problemas de banco de dados, como um banco de dados que se torna suspeito devido à perda de um arquivo de dados ou à corrupção de um log de transações.
A réplica primária torna os bancos de dados primários disponíveis para conexões de leitura-gravação de clientes. A réplica primária envia registros de log de transações de cada banco de dados primário para todos os bancos de dados secundários. Esse processo – conhecido como sincronização de dados – ocorre no nível do banco de dados. Cada réplica secundária armazena em cache os registros do log de transações (intensifica o log) e os aplica a seu banco de dados secundário correspondente. A sincronização de dados ocorre entre o banco de dados primário e cada banco de dados secundário conectado, independentemente de outros bancos de dados. Assim, um banco de dados secundário pode ser suspenso ou falhar sem que isso afete outros bancos de dados secundários, e um banco de dados primário pode ser suspenso ou falhar sem que isso afete outros bancos de dados primários.
Opcionalmente, você pode configurar uma ou mais réplicas secundárias para dar suporte a acesso somente leitura a bancos de dados secundários, e pode configurar qualquer réplica secundária para permitir backups em bancos de dados secundários.
O SQL Server 2017 introduziu duas arquiteturas diferentes para grupos de disponibilidade. Os grupos de disponibilidade AlwaysOn fornecem alta disponibilidade, recuperação de desastre e balanceamento de escala de leitura. Esses grupos de disponibilidade exigem um gerenciador de cluster. No Windows, o recurso de clustering de failover fornece o gerenciador de cluster. No Linux, você pode usar o Pacemaker. A outra arquitetura é um grupo de disponibilidade de escala de leitura. Um grupo de disponibilidade de escala de leitura fornece réplicas para cargas de trabalho somente leitura, mas não para alta disponibilidade. Em um grupo de disponibilidade de escala de leitura, não há gerenciadores de cluster, pois o failover não pode ser automático.
A implantação do Grupos de disponibilidade AlwaysOn para HA no Windows exige um WSFC (Cluster de Failover do Windows Server). Cada réplica de disponibilidade de determinado grupo de disponibilidade deve residir em um nó diferente do mesmo WSFC. A única exceção é que, embora tenha sido migrado para outro cluster WSFC, um grupo de disponibilidade pode temporariamente abranger dois clusters.
Observação
Para obter informações sobre grupos de disponibilidade no Linux, confira Grupo de disponibilidade para SQL Server em Linux.
Em uma configuração de HA, uma função de cluster é criada para cada grupo de disponibilidade criado. O cluster WSFC monitora essa função para avaliar a integridade da réplica primária. O quorum para o Grupos de disponibilidade AlwaysOn é baseado em todos os nós no cluster WSFC independentemente de se um determinado nó de cluster hospeda qualquer réplica de disponibilidade. Ao contrário do espelhamento de banco de dados, não há uma função de testemunha no Grupos de disponibilidade AlwaysOn.
Observação
Para obter informações sobre a relação dos componentes do Always On do SQL Server com o cluster WSFC, confira Clustering de Failover do Windows Server com SQL Server.
A ilustração a seguir mostra um grupo de disponibilidade que contém uma réplica primária e quatro réplicas secundárias. Até oito réplicas secundárias têm suporte, incluindo uma réplica primária e quatro réplicas secundárias de confirmação síncrona.
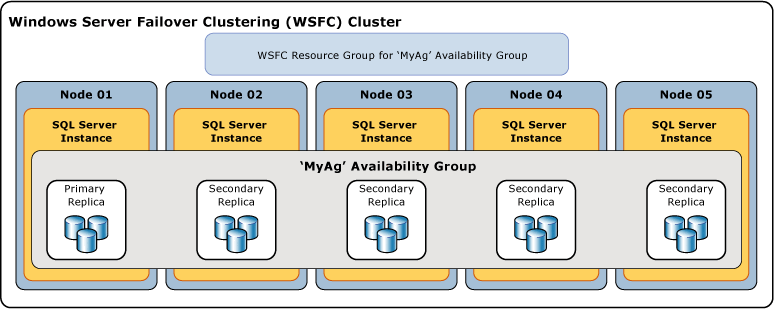
Termos e definições
| Termo | Descrição |
|---|---|
| grupo de disponibilidade | Um contêiner para um conjunto de bancos de dados, bancos de dados de disponibilidade, que executam failover juntos. |
| banco de dados de disponibilidade | Um banco de dados que pertence a um grupo de disponibilidade. Para cada banco de dados de disponibilidade, o grupo de disponibilidade mantém uma única cópia de leitura/gravação (o banco de dados primário) e de uma a oito cópias somente leitura (bancos de dados secundários). |
| banco de dados primário | A cópia de leitura-gravação de um banco de dados de disponibilidade. |
| banco de dados secundário | Uma cópia somente leitura de um banco de dados de disponibilidade. |
| réplica de disponibilidade | Uma instanciação de um grupo de disponibilidade que é hospedado por uma instância específica do SQL Server e que mantém uma cópia local de cada banco de dados de disponibilidade pertencente ao grupo de disponibilidade. Existem dois tipos de réplica de disponibilidade: uma única réplica primária e uma a oito réplicas secundárias. |
| réplica primária | A réplica de disponibilidade que torna disponíveis os bancos de dados primários para conexões de leitura/gravação de clientes e, também, envia registros do log de transações para cada banco de dados primário a toda réplica secundária. |
| réplica secundária | Uma réplica de disponibilidade que mantém uma cópia secundária de cada banco de dados de disponibilidade e serve como destinos potenciais de failover para o grupo de disponibilidade. Opcionalmente, uma réplica secundária pode incluir o suporte ao acesso somente leitura para que bancos de dados secundários possam oferecer suporte à criação de backups em bancos de dados secundários. |
| ouvinte do grupo de disponibilidade | Um nome do servidor ao qual os clientes podem se conectar para acessar um banco de dados em uma réplica primária ou secundária de um grupo de disponibilidade. Os ouvintes de grupo de disponibilidade direcionam conexões de entrada para a réplica primária ou para uma réplica secundária somente leitura. |
Bancos de dados de disponibilidade
Para adicionar um banco de dados a um grupo de disponibilidade, o banco de dados deve estar online, banco de dados de leitura/gravação que existe na instância do servidor que hospeda a réplica primária. Quando você adiciona um banco de dados, ele se une ao grupo de disponibilidade como um banco de dados primário, permanecendo disponível a clientes. Não existe nenhum banco de dados secundário correspondente até que os backups do novo banco de dados primário sejam restaurados na instância do servidor que hospeda a réplica secundária (usando RESTORE WITH NORECOVERY). O novo banco de dados secundário estará no estado RESTORING até que seja unido ao grupo de disponibilidade. Para obter mais informações, confira Iniciar movimentação de dados em um banco de dados secundário Always On (SQL Server).
A junção coloca o banco de dados secundário no estado ONLINE e inicia sincronização de dados com o banco de dados primário correspondente. Sincronização de dados é o processo pelo qual as alterações em um banco de dados primário são reproduzidas em um banco de dados secundário. A sincronização de dados envolve o envio pelo banco de dados primário dos registros do log de transações ao banco de dados secundário.
Importante
Um banco de dados de disponibilidade muitas vezes é chamado de réplica de banco de dados no Transact-SQL, no PowerShell e em nomes do SMO (SQL Server Management Objects). Por exemplo, o termo "réplica de banco de dados" é usado nos nomes das exibições de gerenciamento dinâmico AlwaysOn que retornam informações sobre bancos de dados de disponibilidade: sys.dm_hadr_database_replica_states e sys.dm_hadr_database_replica_cluster_states. Porém, nos Manuais Online do SQL Server, o termo "réplica" normalmente refere-se a réplicas de disponibilidade. Por exemplo, "réplica primária" e "réplica secundária" sempre referem-se a réplicas de disponibilidade.
Réplicas de disponibilidade
Cada grupo de disponibilidade define um conjunto de dois ou mais parceiros de failover conhecidos como réplicas de disponibilidade. Asréplicas de disponibilidade são componentes do grupo de disponibilidade. Cada réplica de disponibilidade hospeda uma cópia dos bancos de dados de disponibilidade no grupo de disponibilidade. Para um determinado grupo de disponibilidade, as réplicas de disponibilidade devem ser hospedadas por instâncias separadas do SQL Server que residem em nós diferentes de um cluster WSFC. Cada uma dessas instâncias de servidor deve estar habilitada para AlwaysOn.
SQL Server 2019 (15.x) aumenta o número máximo de réplicas síncronas para 5, um aumento com relação às 3 no SQL Server 2017 (14.x). Você pode configurar esse grupo de cinco réplicas para ter failover automático dentro do grupo. Há uma réplica primária, além de quatro réplicas secundárias síncronas.
Uma determinada instância pode hospedar apenas uma réplica de disponibilidade por grupo de disponibilidade. No entanto, cada instância pode ser usada para muitos grupos de disponibilidade. Uma determinada instância pode ser uma instância autônoma ou uma FCI (instância de cluster de failover) do SQL Server . Se você precisar de redundância em nível de servidor, use instâncias de cluster de failover.
Cada réplica de disponibilidade recebe uma função inicial, a função primária ou a função secundária, que é herdada pelos bancos de dados de disponibilidade daquela réplica. A função de uma determinada réplica determina se ela hospeda bancos de dados de leitura/gravação ou bancos de dados somente leitura. Uma réplica, conhecida como a réplica primária, recebe a função primária e hospeda bancos de dados de leitura/gravação, que são conhecidos como bancos de dados primários. Pelo menos uma outra réplica, conhecida como uma réplica secundária, recebe a função secundária. Uma réplica secundária hospeda bancos de dados somente leitura, conhecidos como bancos de dados secundários.
Observação
Quando a função de uma réplica de disponibilidade está indeterminada, como durante um failover, seus bancos de dados estão temporariamente em um estado NOT SYNCHRONIZING. A função dos bancos de dados é definida como RESOLVING até que a função da réplica de disponibilidade tenha sido resolvida. Se uma réplica de disponibilidade for resolvida para a função primária, seus bancos de dados se tornarão os bancos de dados primários. Se uma réplica de disponibilidade for resolvida para a função secundária, seus bancos de dados se tornarão os bancos de dados secundários.
Modos de disponibilidade
O modo de disponibilidade é uma propriedade de cada réplica de disponibilidade. O modo de disponibilidade determina se a réplica primária espera para confirmar transações em um banco de dados até que uma determinada réplica secundária tenha gravado os registros do log de transações em disco (protegido o log). O Grupos de disponibilidade AlwaysOn permite dois modos de disponibilidade: o modo de confirmação assíncrona e o modo de confirmação síncrona.
Asynchronous-commit mode
Uma réplica de disponibilidade que usa esse modo de disponibilidade é conhecida como réplica da confirmação assíncrona. No modo de confirmação assíncrona, a réplica primária confirma as transações sem esperar a confirmação de que as réplicas secundárias de confirmação assíncrona protegeram o log de transações. O modo de confirmação assíncrona minimiza a latência de transações nos bancos de dados secundários, mas permite que elas atrasem os bancos de dados primários, possibilitando a perda de dados.
Synchronous-commit mode
Uma réplica de disponibilidade que usa esse modo de disponibilidade é conhecida como uma réplica de confirmação síncrona. No modo de confirmação síncrona, antes de confirmar transações, uma réplica primária de confirmação síncrona espera que uma réplica secundária de confirmação síncrona confirme que concluiu a proteção do log. O modo de confirmação síncrona garante que, quando um determinado banco de dados secundário é sincronizado com o banco de dados primário, as transações confirmadas sejam totalmente protegidas. Essa proteção ocorre às custas de latência de transação aumentada. O SQL Server 2017 introduziu a opção de um recurso de secundários sincronizados necessários para aumentar ainda mais a segurança mediante o aumento da latência. O recurso REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT pode ser habilitado para exigir que um determinado número de réplicas síncronas confirmem uma transação antes que uma réplica primária tenha permissão para confirmar.
Para obter mais informações, consulte Diferenças entre os modos de disponibilidade de um Grupo de Disponibilidade AlwaysOn.
Tipos de failover
Dentro do contexto de uma sessão entre a réplica primária e uma réplica secundária, as funções primárias e secundárias são potencialmente permutáveis em um processo conhecido como failover. Durante um failover, a réplica secundária de destino faz a transição para a função primária, tornando-se a nova réplica primária. A nova réplica primária coloca seus bancos de dados online como os bancos de dados primários, e os aplicativos cliente podem conectar-se a eles. Quando a réplica primária antiga está disponível, ela faz a transição para a função secundária, tornando-se uma réplica secundária. Os bancos de dados primários anteriores se tornam bancos de dados secundários e a sincronização de dados é retomada.
Um grupo de disponibilidade faz failover no nível de uma réplica de disponibilidade. Os failovers não são provocados por problemas de banco de dados, como um banco de dados que se torna suspeito devido à perda de um arquivo de dados, à exclusão de um banco de dados ou à corrupção de um log de transações.
Existem três formulários de failover: automático, manual e forçado (com possível perda de dados). O formulário ou formulários de failover com suporte de uma determinada réplica secundária dependem de seu modo de disponibilidade, e, para o modo de confirmação síncrona, no modo de failover na réplica primária e na réplica secundária de destino, da seguinte forma.
Se a réplica secundária de destino estiver sincronizada com a réplica primária, o modo de confirmação síncrona será compatível com duas formas de failover: o failover manual planejado e o failover automático. O suporte para esses formulários de failover depende da configuração da propriedade de modo de failover nos parceiros de failover. Se o modo de failover for definido como "manual" na réplica primária ou secundária, apenas o failover manual terá suporte para aquela réplica secundária. Se o modo de failover for definido como "automático" nas réplicas primária e secundária, failover automático e manual terão suporte naquela réplica secundária.
Failover manual planejado (sem perda de dados)
Um failover manual ocorre depois que um administrador de banco de dados emite um comando de failover e faz com que uma réplica secundária sincronizada faça a transição para a função primária (com proteção de dados garantida) e a réplica primária faça a transição para a função secundária. Um failover manual exige que a réplica primária e a réplica secundária de destino estejam executando sob o modo de confirmação síncrona, e a réplica secundária já deve estar sincronizada.
Failover automático (sem perda de dados)
Um failover automático ocorre em resposta a uma falha que faz com que uma réplica secundária sincronizada faça a transição para a função primária (com proteção de dados garantida). Quando a réplica primária antiga se torna disponível, ela faz a transição para a função secundária. O failover automático exige que a réplica primária e a réplica secundária de destino estejam executando sob o modo de confirmação síncrona com o modo de failover definido como Automático. Além disso, a réplica secundária já deve estar sincronizada, ter quorum de WSFC e atender às condições especificadas pela política de failover flexível do grupo de disponibilidade.
No modo de confirmação assíncrona, a única forma de failover é o failover manual forçado (com possível perda de dados), geralmente conhecido como failover forçado. O failover forçado é considerado uma forma de failover manual porque ele só pode ser iniciado manualmente. O failover forçado é uma opção de recuperação de desastres. Trata-se da única forma de failover possível quando a réplica secundária de destino não está sincronizada com a réplica primária.
Para obter mais informações, confira Failover e modos de failover (grupos de disponibilidade Always On).
Importante
- As FCIs (Instâncias de cluster de failover) do SQL Server não dão suporte ao failover automático por grupos de disponibilidade, de modo que qualquer réplica de disponibilidade que esteja hospedado por um FCI só pode ser configurada para failover manual.
- Se você emitir um comando de failover forçado em uma réplica secundária sincronizada, a réplica secundária se comportará da mesma maneira que um failover manual planejado.
Benefícios
Grupos de disponibilidade AlwaysOn fornecem um conjunto diversificado de opções que melhoram a disponibilidade do banco de dados e o uso de recursos. Os principais componentes são os seguintes:
Permite até nove réplicas de disponibilidade. Uma réplica de disponibilidade é uma instanciação de um grupo de disponibilidade que é hospedado por uma instância específica do SQL Server e que mantém uma cópia local de cada banco de dados de disponibilidade pertencente ao grupo de disponibilidade. Cada grupo de disponibilidade suporta uma réplica primária e até oito réplicas secundárias. Para obter mais informações, confira o artigo O que é um grupo de disponibilidade Always On?
Importante
Cada réplica de disponibilidade deve residir em um nó diferente de um único cluster do WSFC (Windows Server Failover Clustering). Para obter mais informações sobre pré-requisitos, restrições e recomendações para grupos de disponibilidade, confira Pré-requisitos, restrições e recomendações para grupos de disponibilidade Always On.
Dá suporte para modos de disponibilidade alternativos, como:
Modo de confirmação assíncrona. Este modo de disponibilidade é uma solução de recuperação de desastre que funciona bem quando as réplicas de disponibilidade estão distribuídas em distâncias consideráveis.
Modo de confirmação síncrona. Este modo de disponibilidade enfatiza a alta disponibilidade e a proteção dos dados sobre o desempenho, às custas do aumento da latência de transação. Um determinado grupo de disponibilidade pode dar suporte a até cinco réplicas de disponibilidade de confirmação síncrona, incluindo a réplica primária atual.
Para obter mais informações, consulte Diferenças entre os modos de disponibilidade de um Grupo de Disponibilidade AlwaysOn.
Dá suporte a várias formas de failover de disponibilidade-grupo: failover automático, failover manual planejado (geralmente referenciado como um "failover manual" simples) e failover manual forçado (geralmente referenciado como "failover forçado" simples). Para obter mais informações, confira Failover e modos de failover (Grupos de Disponibilidade Always On).
Permite a você configurar uma determinada réplica de disponibilidade para dar suporte a um ou ambos os seguintes recursos ativos-secundários:
Acesso de conexão somente leitura, que permite que conexões somente leitura com a réplica acessem e leiam seus bancos de dados quando estiver em execução como uma réplica secundária. Para obter mais informações, confira Descarregar a carga de trabalho somente leitura na réplica secundária de um grupo de disponibilidade Always On.
Execução de operações de backup em seus bancos de dados quando estiver em execução como uma réplica secundária. Para mais informações, confira Descarregar backups com suporte em réplicas secundárias de um grupo de disponibilidade.
O uso de recursos secundários ativos melhora a eficiência de TI e reduz o custo devido à melhor utilização de recurso de hardware secundário. Além disso, descarregar aplicativos de intenção de leitura e trabalhos de backup para réplicas secundárias ajuda a melhorar o desempenho na réplica primária.
Dá suporte a um ouvinte de grupo de disponibilidade para cada grupo de disponibilidade. Um ouvinte do grupo de disponibilidade é um nome do servidor ao qual os clientes podem se conectar para acessar um banco de dados em uma réplica primária ou secundária de um grupo de disponibilidade AlwaysOn. Os ouvintes de grupo de disponibilidade direcionam conexões de entrada para a réplica primária ou para uma réplica secundária somente leitura. O ouvinte fornece o failover rápido de aplicativo depois de um failover de grupo de disponibilidade. Para obter mais informações, confira Conectar-se a um ouvinte do grupo de disponibilidade Always On.
Dá suporte a uma política de failover flexível para proporcionar maior controle sobre o failover de disponibilidade-grupo. Para obter mais informações, confira Failover e modos de failover (Grupos de Disponibilidade Always On).
Dá suporte ao conserto de página automático para proteção contra dano de página. Para obter mais informações, confira Reparo automático de página (Grupos de disponibilidade: espelhamento de banco de dados).
Dá suporte à criptografia e compactação, que fornecem um transporte seguro de alto desempenho.
Fornece um conjunto integrado de ferramentas para simplificar a implantação e o gerenciamento de grupos de disponibilidade, incluindo:
Instruções DDL Transact-SQL para criar e gerenciar grupos de disponibilidade. Para obter mais informações, confira Instruções do Transact-SQL para grupos de disponibilidade Always On.
SQL Server Management Studio , como a seguir:
O Assistente de grupo de nova disponibilidade cria e configura um grupo de disponibilidade. Em alguns ambientes, este assistente também pode preparar automaticamente os bancos de dados secundários e iniciar a sincronização de dados para cada um deles. Para obter mais informações, confira Usar a caixa de diálogo Novo Grupo de Disponibilidade (SQL Server Management Studio).
O Adicionar banco de dados ao Assistente de Grupo de Disponibilidade adiciona um ou mais bancos de dados primários a um grupo de disponibilidade existente. Em alguns ambientes, este assistente também pode preparar automaticamente os bancos de dados secundários e iniciar a sincronização de dados para cada um deles. Para obter mais informações, consulte Adicionar um banco de dados a um grupo de disponibilidade Always On com o “Assistente de grupo de disponibilidade”.
O Adicionar réplica ao Assistente de Grupo de Disponibilidade adiciona uma ou mais réplicas secundárias a um grupo de disponibilidade existente. Em alguns ambientes, este assistente também pode preparar automaticamente os bancos de dados secundários e iniciar a sincronização de dados para cada um deles. Para obter mais informações, consulte Adicionar uma réplica ao grupo de disponibilidade Always On usando o Assistente de Grupo de Disponibilidade no SQL Server Management.
O Assistente de grupo de disponibilidade de failover inicia um failover manual em um grupo de disponibilidade. Dependendo da configuração e do estado da réplica secundária que você especificar como o destino de failover, o assistente pode executar um failover planejado ou manual forçado. Para obter mais informações, confira Usar o Assistente para Executar Failover de Grupo de Disponibilidade (SQL Server Management Studio).
O Painel AlwaysOn monitora grupos de disponibilidade AlwaysOn, réplicas de disponibilidade e bancos de dados de disponibilidade e avalia os resultados para políticas AlwaysOn. Para obter mais informações, confira Usar o painel do grupo de disponibilidade Always On (SQL Server Management Studio).
O painel Detalhes do Pesquisador de Objetos exibe informações básicas sobre grupos de disponibilidade existentes. Para obter mais informações, confira Usar os detalhes do Pesquisador de Objetos para monitorar grupos de disponibilidade.
Cmdlets do PowerShell. Para obter mais informações, confira Visão geral de cmdlets do PowerShell para grupos de disponibilidade Always On.
Conexões de cliente
Você pode fornecer conectividade de cliente à réplica primária de um determinado grupo de disponibilidade criando um ouvinte de grupo de disponibilidade. Um ouvinte de grupo de disponibilidade fornece um conjunto de recursos que é conectado a um determinado grupo de disponibilidade para direcionar conexões de cliente à réplica de disponibilidade apropriada.
Um ouvinte de grupo de disponibilidade é associado a um nome DNS exclusivo, que serve como um VNN (nome de rede virtual), um ou mais VIPs (endereços IP virtuais) e um número de porta TCP. Para obter mais informações, confira Conectar-se a um ouvinte do grupo de disponibilidade Always On.
Dica
Se um grupo de disponibilidade possuir apenas duas réplicas de disponibilidade e não estiver configurado para permitir acesso de leitura à réplica secundária, os clientes poderão se conectar à réplica usando uma cadeia de conexão do espelhamento do banco de dados. Essa abordagem pode ser temporariamente útil depois que você migrar um banco de dados do espelhamento de banco de dados para o Grupos de disponibilidade AlwaysOn. Antes de adicionar mais réplicas secundárias, você precisará criar um ouvinte de grupo de disponibilidade para o grupo de disponibilidade e atualizar seus aplicativos para usarem o nome da rede do ouvinte.
Réplicas secundárias ativas
Grupos de disponibilidade AlwaysOn oferece suporte a réplicas secundárias ativas. Os recursos secundários ativos incluem suporte para:
Executando operações de backup em réplicas secundárias
As réplicas secundárias dão suporte à execução de backups de log e somente cópia de um banco de dados completo, arquivo ou grupo de arquivos. Você pode configurar o grupo de disponibilidade para especificar a preferência de onde os backups devem ser executados. É importante compreender que a preferência não é imposta pelo SQL Server e, portanto, não tem nenhum efeito em backups ad hoc. A interpretação dessa preferência depende da lógica, se houver, que você usa para o script de seus trabalhos de backup para cada um dos bancos de dados em um determinado grupo de disponibilidade. Para uma réplica de disponibilidade individual, você pode especificar suas prioridades para executar backups nesta réplica em relação às outras réplicas no mesmo grupo de disponibilidade. Para mais informações, confira Descarregar backups com suporte em réplicas secundárias de um grupo de disponibilidade.
O acesso somente leitura a uma ou mais réplicas secundárias (réplicas secundárias legíveis)
Todas as réplicas de disponibilidade secundárias podem ser configuradas para permitir apenas acesso somente leitura a seus bancos de dados locais, embora algumas operações não tenham suporte completo. Isso evitará tentativas de conexão de leitura/gravação na réplica secundária. Também é possível evitar cargas de trabalho somente leitura na réplica primária permitindo acesso de leitura/gravação. Isso impede que conexões somente leitura sejam feitas na réplica primária. Para obter mais informações, confira Descarregar a carga de trabalho somente leitura na réplica secundária de um grupo de disponibilidade Always On.
Se um grupo de disponibilidade tiver um ouvinte de grupo de disponibilidade e uma ou mais réplicas secundárias legíveis no momento, o SQL Server poderá rotear solicitações de conexão da intenção de leitura para um deles (roteamento somente leitura). Para obter mais informações, confira Conectar-se a um ouvinte do grupo de disponibilidade Always On.
Período de tempo limite da sessão
O período de tempo limite da sessão é uma propriedade de réplica de disponibilidade que determina por quanto tempo a conexão com outra réplica de disponibilidade poderá permanecer inativa antes do fechamento da conexão. As réplicas primárias e secundárias executam ping uma da outra para sinalizar que ainda estão ativas. A recepção de um ping de outra réplica durante o período de tempo limite indica que a conexão ainda está aberta e que as instâncias do servidor estão se comunicando. Durante o recebimento de um ping, uma réplica de disponibilidade redefine seu contador de tempo limite de sessão nessa conexão.
O período de tempo limite da sessão impede qualquer réplica de esperar indefinidamente para receber um ping de outra réplica. Se nenhum ping for recebido da outra réplica dentro do período de tempo limite da sessão, ocorrerá o tempo limite da réplica. Sua conexão é fechada e a réplica de tempo limite entra no estado DISCONNECTED. Mesmo que uma réplica desconectada esteja configurada para o modo de confirmação síncrona, as transações não esperarão que ela se reconecte e seja ressincronizada.
O período de tempo limite da sessão padrão para cada réplica de disponibilidade é 10 segundos. Esse valor pode ser configurado pelo usuário com um mínimo de 5 segundos. Em geral, recomendamos que você mantenha o tempo limite em 10 segundos ou mais. Definir o valor como menos de 10 segundos cria a possibilidade de um sistema extremamente carregado declarando uma falsa falha.
Observação
Na resolução da função, o período de tempo limite da sessão não se aplica, pois o ping não ocorre.
Reparo automático de página
Cada réplica de disponibilidade tenta recuperar-se automaticamente de páginas corrompidas em um banco de dados local resolvendo determinados tipos de erros que impedem a leitura de uma página de dados. Se uma réplica secundária não puder ler uma página, a réplica solicitará uma cópia atualizada da página da réplica primária. Se a réplica primária não puder ler uma página, a réplica transmitirá uma solicitação de uma cópia atualizada para todas as réplicas secundárias e obterá a página da primeira a responder. Se essa solicitação tiver êxito, a página ilegível será substituída pela cópia. Isso normalmente resolve o erro.
Para obter mais informações, confira Reparo automático de página (Grupos de disponibilidade: espelhamento de banco de dados).
Interoperabilidade e coexistência com outros recursos de mecanismo de banco de dados
Grupos de disponibilidade AlwaysOn podem ser usados com os seguintes recursos ou componentes do SQL Server:
- O que é a CDA (captura de dados de alterações)?
- Sobre o controle de alterações (SQL Server)
- Bancos de dados independentes
- Transparent data encryption (TDE)
- Instantâneos do banco de dados com grupos de disponibilidade AlwaysOn (SQL Server)
- FILESTREAM (SQL Server)
- FileTables (SQL Server)
- Sobre o envio de logs (SQL Server)
- RBS (Armazenamento de Blob Remoto) [SQL Server]
- Replicação do SQL Server
- Service Broker
- SQL Server Agent
- Reporting Services com grupos de disponibilidade AlwaysOn (SQL Server)
Tarefas relacionadas
- Pré-requisitos, restrições e recomendações para grupos de disponibilidade Always On
- Referência para a criação e a configuração de grupos de disponibilidade Always On
- Administração de grupo de disponibilidade
- Ferramentas para monitorar Grupos de Disponibilidade AlwaysOn
- Descarregue a carga de trabalho somente leitura para a réplica secundária de um grupo de disponibilidade Always On
- Descarregar backups com suporte nas réplicas secundárias de um grupo de disponibilidade
- Conectar-se a um ouvinte do grupo de disponibilidade Always On
- Instruções Transact-SQL para Grupos de disponibilidade Always On
- Visão geral de cmdlets do PowerShell para grupos de disponibilidade AlwaysOn
- Blog de suporte do SQL Server – Alta disponibilidade
- Blog do SQL Server – Always On do SQL Server
- Arquivos: blogs da equipe do Always On do SQL Server: o blog oficial da equipe do Always On do SQL Server
- Arquivos: blogs dos engenheiros do SQL Server para CSS
- Guia de soluções AlwaysOn do Microsoft SQL Server para alta disponibilidade e recuperação de desastre