Treine o seu modelo de voz profissional
Neste artigo, você aprenderá a treinar uma voz neural personalizada por meio do portal do Speech Studio.
Importante
Atualmente, o treinamento de voz neural personalizado está disponível apenas em algumas regiões. Depois que seu modelo de voz for treinado em uma região suportada, você poderá copiá-lo para um recurso de Fala em outra região, conforme necessário. Para obter mais informações, consulte as notas de rodapé na tabela Serviço de fala.
A duração do treinamento varia de acordo com a quantidade de dados que você usa. Leva cerca de 40 horas de computação, em média, para treinar uma voz neural personalizada. Os usuários de assinatura padrão (S0) podem treinar quatro vozes simultaneamente. Se você atingir o limite, espere até que pelo menos um de seus modelos de voz termine o treinamento e tente novamente.
Nota
Embora o número total de horas necessárias por método de formação varie, o mesmo preço unitário aplica-se a cada um deles. Para obter mais informações, consulte os detalhes de preços do treinamento neural personalizado.
Escolha um método de treino
Depois de validar seus arquivos de dados, use-os para criar seu modelo de voz neural personalizado. Ao criar uma voz neural personalizada, você pode optar por treiná-la com um dos seguintes métodos:
Neural: Crie uma voz no mesmo idioma dos seus dados de treinamento.
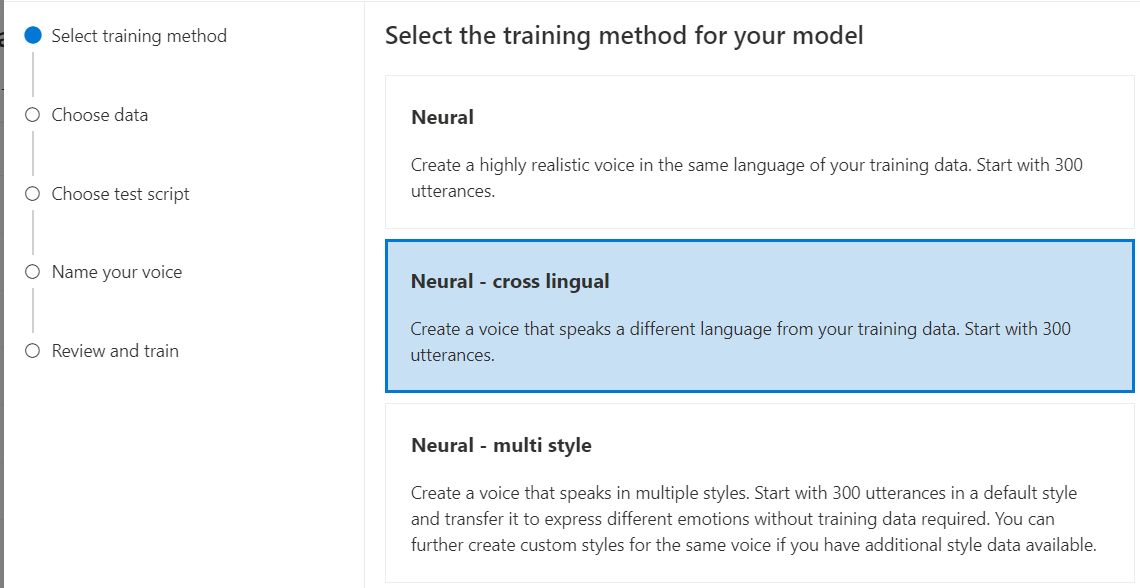
Neural - cross lingual: crie uma voz que fale um idioma diferente dos seus dados de treinamento. Por exemplo, com os dados de
zh-CNtreinamento, você pode criar uma voz que faleen-US.O idioma dos dados de treinamento e o idioma de destino devem ser um dos idiomas suportados para treinamento de voz multilíngüe. Não é necessário preparar dados de formação na língua de chegada, mas a sua folha de respostas de teste tem de estar na língua de chegada.
Neural - multi estilo: Crie uma voz neural personalizada que fale em vários estilos e emoções, sem adicionar novos dados de treinamento. Vozes de vários estilos são úteis para personagens de videogames, chatbots conversacionais, audiolivros, leitores de conteúdo e muito mais.
Para criar uma voz de vários estilos, você precisa preparar um conjunto de dados gerais de treinamento, pelo menos 300 enunciados. Selecione um ou mais dos estilos de fala de destino predefinidos. Você também pode criar vários estilos personalizados fornecendo amostras de estilo, de pelo menos 100 enunciados por estilo, como dados de treinamento extra para a mesma voz. Os estilos predefinidos suportados variam de acordo com diferentes idiomas. Veja os estilos predefinidos disponíveis em diferentes idiomas.
O idioma dos dados de treinamento deve ser um dos idiomas suportados para voz neural personalizada, treinamento multilíngüe ou de vários estilos.
Treine seu modelo de voz neural personalizado
Para criar uma voz neural personalizada no Speech Studio, siga estas etapas para um dos seguintes métodos:
Inicie sessão no Speech Studio.
Selecione Voz<>personalizada Seu nome>>de projeto Modelo de trem>Treine um novo modelo.
Selecione Neural como o método de treinamento para seu modelo e, em seguida, selecione Avançar. Para usar um método de treinamento diferente, consulte Neural - cross lingual ou Neural - multistyle.
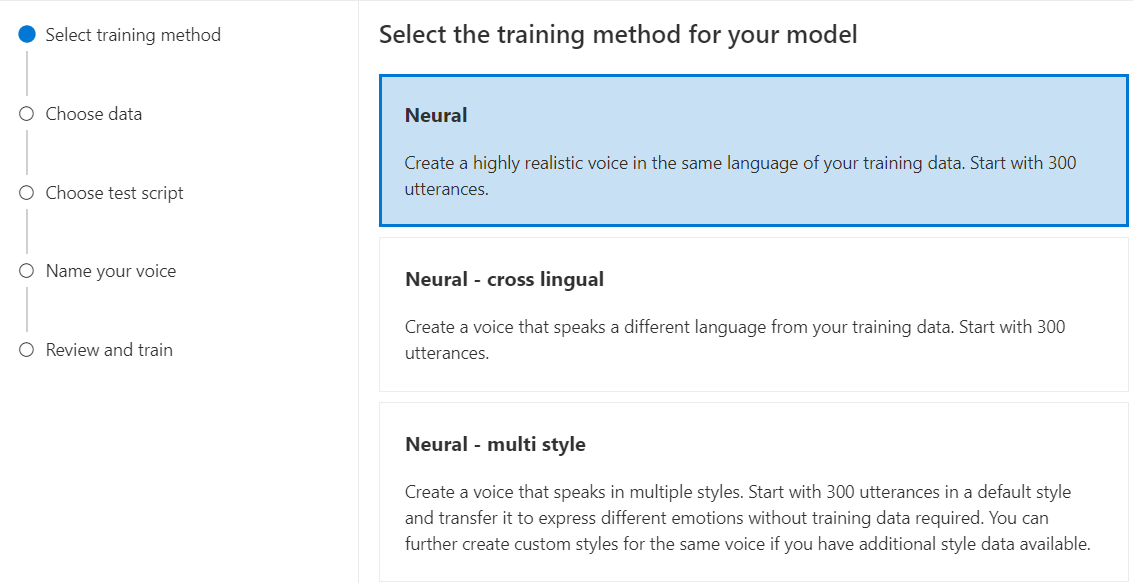
Selecione uma versão da receita de treinamento para o seu modelo. A versão mais recente é selecionada por padrão. Os recursos suportados e o tempo de treinamento podem variar de acordo com a versão. Normalmente, recomendamos a versão mais recente. Em alguns casos, você pode escolher uma versão anterior para reduzir o tempo de treinamento. Consulte Treinamento bilíngue para obter mais informações sobre treinamento bilíngue e diferenças entre localidades.
Nota
As versões
V2.2021.07do modelo , ,V4.2021.10V5.2022.05,V6.2022.11, eV9.2023.10serão desativadas até 1º de outubro de 2024. Os modelos de voz já criados nessas versões desativadas não serão afetados.Selecione os dados que você deseja usar para treinamento. Nomes de áudio duplicados são removidos do treinamento. Certifique-se de que os dados selecionados não contêm os mesmos nomes de áudio em vários arquivos .zip .
Você pode selecionar apenas conjuntos de dados processados com êxito para treinamento. Se não vir o seu conjunto de formação na lista, verifique o estado do processamento de dados.
Selecione um arquivo de alto-falante com a declaração de talento de voz que corresponde ao orador em seus dados de treinamento.
Selecione Seguinte.
Cada treinamento gera 100 arquivos de áudio de amostra automaticamente para ajudá-lo a testar o modelo com um script padrão.
Opcionalmente, você também pode selecionar Adicionar meu próprio script de teste e fornecer seu próprio script de teste com até 100 expressões para testar o modelo sem custo extra. Os arquivos de áudio gerados são uma combinação de scripts de teste automático e scripts de teste personalizados. Para obter mais informações, consulte requisitos de script de teste.
Insira um Nome para ajudá-lo a identificar o modelo. Escolha um nome cuidadosamente. O nome do modelo é usado como o nome da voz em sua solicitação de síntese de fala pela entrada SDK e SSML. Apenas letras, números e alguns caracteres de pontuação são permitidos. Use nomes diferentes para diferentes modelos de voz neural.
Opcionalmente, insira a Descrição para ajudá-lo a identificar o modelo. Um uso comum da descrição é registrar os nomes dos dados que você usou para criar o modelo.
Selecione Seguinte.
Revise as configurações e selecione a caixa para aceitar os termos de uso.
Selecione Enviar para começar a treinar o modelo.

Formação bilingue
Se você selecionar o tipo de treinamento neural , poderá treinar uma voz para falar em vários idiomas. O zh-CN, zh-HKe zh-TW localidades suportam treinamento bilíngue para que a voz fale chinês e inglês. Dependendo em parte dos seus dados de treinamento, a voz sintetizada pode falar inglês com sotaque nativo de inglês ou inglês com o mesmo sotaque dos dados de treinamento.
Nota
Para permitir que uma voz na localidade fale zh-CN inglês com o mesmo sotaque dos dados de exemplo, você deve escolher Chinese (Mandarin, Simplified), English bilingual ao criar um projeto ou especificar a zh-CN (English bilingual) localidade para os dados do conjunto de treinamento por meio da API REST.
A tabela a seguir mostra as diferenças entre as localidades:
| Localidade do Speech Studio | Localidade da API REST | Suporte bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Se os dados de amostra incluírem inglês, a voz sintetizada fala inglês com sotaque nativo de inglês, em vez do mesmo sotaque que os dados de exemplo, independentemente da quantidade de dados em inglês. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Se você quiser que a voz sintetizada fale inglês com o mesmo sotaque dos dados de amostra, recomendamos incluir mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o sotaque de língua inglesa pode não ser o ideal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Se você quiser treinar uma voz sintetizada capaz de falar inglês com o mesmo sotaque que seus dados de amostra, certifique-se de fornecer mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o padrão é um sotaque nativo do inglês. O limite de 10% é calculado com base nos dados aceites após o carregamento bem-sucedido, e não nos dados anteriores ao carregamento. Se alguns dados em inglês carregados forem rejeitados devido a defeitos e não atingirem o limite de 10%, a voz sintetizada assume como padrão um sotaque nativo do inglês. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Se você quiser treinar uma voz sintetizada capaz de falar inglês com o mesmo sotaque que seus dados de amostra, certifique-se de fornecer mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o padrão é um sotaque nativo do inglês. O limite de 10% é calculado com base nos dados aceites após o carregamento bem-sucedido, e não nos dados anteriores ao carregamento. Se alguns dados em inglês carregados forem rejeitados devido a defeitos e não atingirem o limite de 10%, a voz sintetizada assume como padrão um sotaque nativo do inglês. |
Estilos predefinidos disponíveis em diferentes idiomas
A tabela a seguir resume os diferentes estilos predefinidos de acordo com diferentes idiomas.
| Estilo de fala | Idioma (localidade) |
|---|---|
| irritado | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| calma | Chinês (mandarim, simplificado) (zh-CN) 1 |
| chat | Chinês (mandarim, simplificado) (zh-CN) 1 |
| alegre | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| descontentes | Chinês (mandarim, simplificado) (zh-CN) 1 |
| animado | Inglês (Estados Unidos) (en-US) |
| com medo | Chinês (mandarim, simplificado) (zh-CN) 1 |
| amigável | Inglês (Estados Unidos) (en-US) |
| esperançoso | Inglês (Estados Unidos) (en-US) |
| triste | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| gritando | Inglês (Estados Unidos) (en-US) |
| graves | Chinês (mandarim, simplificado) (zh-CN) 1 |
| apavorado | Inglês (Estados Unidos) (en-US) |
| hostil | Inglês (Estados Unidos) (en-US) |
| sussurrando | Inglês (Estados Unidos) (en-US) |
1 O estilo de voz neural está disponível em pré-visualização pública. Os estilos em pré-visualização pública só estão disponíveis nestas regiões de serviço: Leste dos EUA, Europa Ocidental e Sudeste Asiático.
A tabela Modelo de trem exibe uma nova entrada que corresponde a esse modelo recém-criado. O status reflete o processo de conversão de seus dados em um modelo de voz, conforme descrito nesta tabela:
| Estado | Significado |
|---|---|
| Em processamento | O seu modelo de voz está a ser criado. |
| Com êxito | Seu modelo de voz foi criado e pode ser implantado. |
| Com falhas | O seu modelo de voz falhou no treino. A causa da falha pode ser, por exemplo, problemas de dados invisíveis ou problemas de rede. |
| Cancelada | O treinamento para o seu modelo de voz foi cancelado. |
Enquanto o status do modelo for Processamento, você pode selecionar Cancelar treinamento para cancelar seu modelo de voz. Você não será cobrado por esse treinamento cancelado.

Depois de terminar o treinamento do modelo com êxito, você pode revisar os detalhes do modelo e testar seu modelo de voz.
Você pode usar a ferramenta de criação de conteúdo de áudio no Speech Studio para criar áudio e ajustar sua voz implantada. Se aplicável à sua voz, pode selecionar um dos vários estilos.
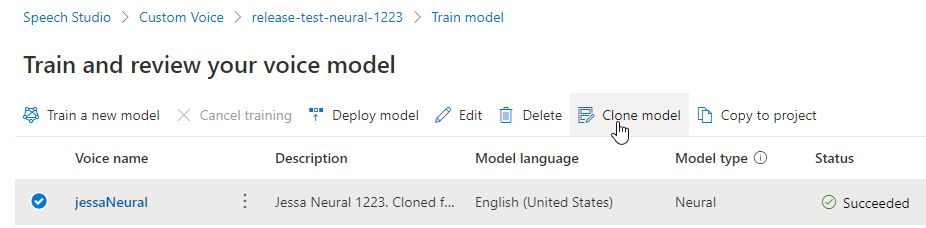
Renomeie seu modelo
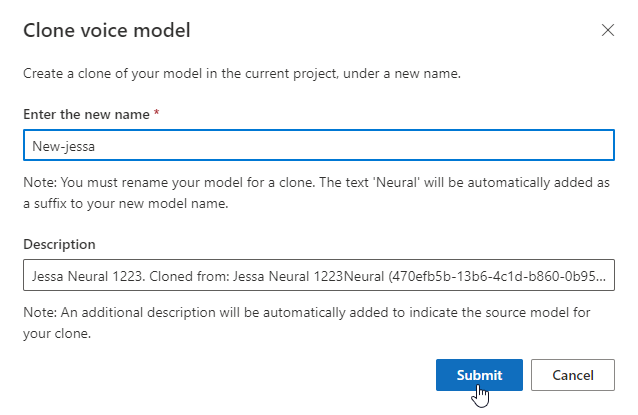
Se você quiser renomear o modelo que você criou, selecione Modelo clonado para criar um clone do modelo com um novo nome no projeto atual.
Introduza o novo nome na janela Modelo de voz de clonagem e, em seguida, selecione Submeter. O texto Neural é adicionado automaticamente como um sufixo ao nome do novo modelo.
Teste o seu modelo de voz
Depois que o modelo de voz for criado com êxito, você poderá usar os arquivos de áudio de exemplo gerados para testá-lo antes de implantá-lo.
A qualidade da voz depende de muitos fatores, tais como:
- O tamanho dos dados de treinamento.
- A qualidade da gravação.
- A precisão do arquivo de transcrição.
- Quão bem a voz gravada nos dados de treinamento corresponde à personalidade da voz projetada para o caso de uso pretendido.
Selecione DefaultTests em Testing para ouvir os arquivos de áudio de exemplo. As amostras de teste padrão incluem 100 arquivos de áudio de amostra gerados automaticamente durante o treinamento para ajudá-lo a testar o modelo. Além desses 100 arquivos de áudio fornecidos por padrão, suas próprias declarações de script de teste também são adicionadas ao conjunto DefaultTests . Esta adição é, no máximo, de 100 enunciados. Você não é cobrado pelo teste com DefaultTests.
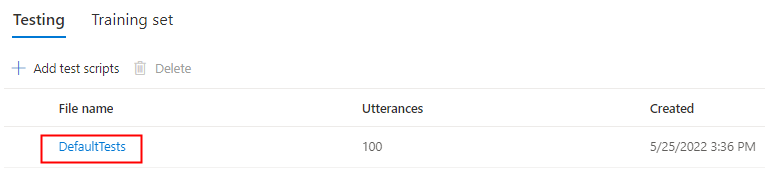
Se você quiser carregar seus próprios scripts de teste para testar ainda mais seu modelo, selecione Adicionar scripts de teste para carregar seu próprio script de teste.

Antes de carregar o script de teste, verifique os requisitos do script de teste. Você será cobrado pelo teste extra com a síntese de lote com base no número de caracteres faturáveis. Consulte Preços do Azure AI Speech.
Em Adicionar scripts de teste, selecione Procurar um arquivo para selecionar seu próprio script e, em seguida, selecione Adicionar para carregá-lo.
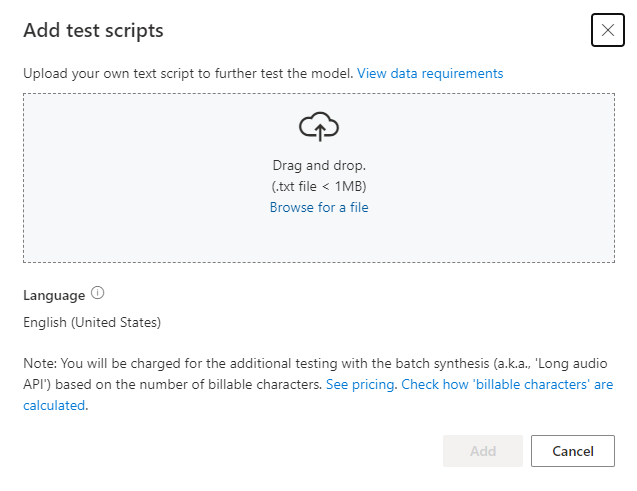
Requisitos do script de teste
O script de teste deve ser um arquivo .txt com menos de 1 MB. Os formatos de codificação suportados incluem ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE ou UTF-16-BE.
Ao contrário dos arquivos de transcrição de treinamento, o script de teste deve excluir o ID do enunciado, que é o nome do arquivo de cada enunciado. Caso contrário, esses IDs são falados.
Aqui está um conjunto de exemplos de enunciados em um arquivo .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Cada parágrafo do enunciado resulta em um áudio separado. Se você quiser combinar todas as frases em um áudio, torne-as um único parágrafo.
Nota
Os arquivos de áudio gerados são uma combinação de scripts de teste automático e scripts de teste personalizados.
Atualizar a versão do motor para o seu modelo de voz
Os mecanismos de texto para fala do Azure são atualizados periodicamente para capturar o modelo de idioma mais recente que define a pronúncia do idioma. Depois de treinar sua voz, você pode aplicá-la ao novo modelo de idioma atualizando para a versão mais recente do mecanismo.
Quando um novo mecanismo estiver disponível, você será solicitado a atualizar seu modelo de voz neural.

Vá para a página de detalhes do modelo e siga as instruções na tela para instalar o mecanismo mais recente.

Como alternativa, selecione Instalar o mecanismo mais recente mais tarde para atualizar seu modelo para a versão mais recente do mecanismo.
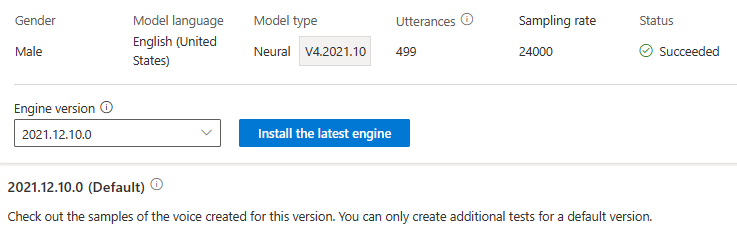
Você não é cobrado pela atualização do mecanismo. As versões anteriores ainda são mantidas.
Você pode verificar todas as versões do motor para o modelo na lista de versões do motor, ou remover um se você não precisar mais dele.
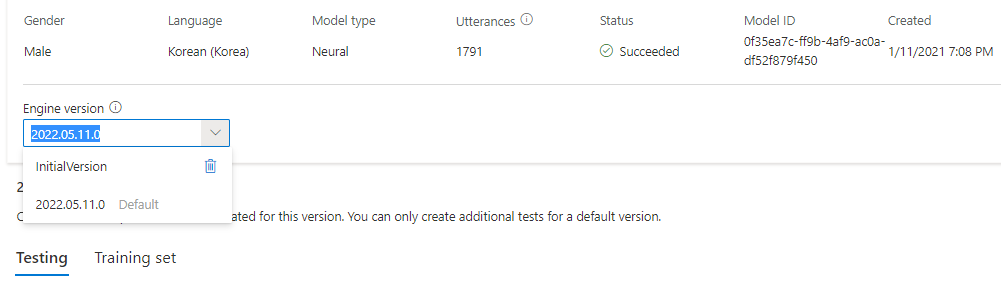
A versão atualizada é definida automaticamente como padrão. Mas você pode alterar a versão padrão selecionando uma versão na lista suspensa e selecionando Definir como padrão.
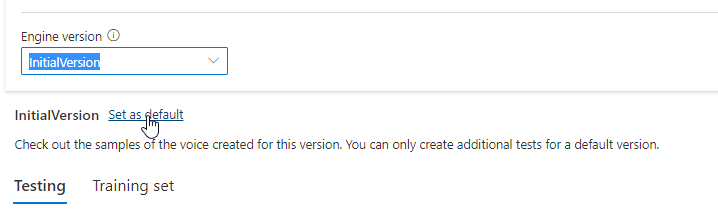

Se quiser testar cada versão do mecanismo do seu modelo de voz, você pode selecionar uma versão na lista e, em seguida, selecionar DefaultTests em Testing para ouvir os arquivos de áudio de exemplo. Se você quiser carregar seus próprios scripts de teste para testar ainda mais sua versão atual do mecanismo, primeiro verifique se a versão está definida como padrão e, em seguida, siga as etapas em Testar seu modelo de voz.
A atualização do motor cria uma nova versão do modelo sem custos adicionais. Depois de atualizar a versão do mecanismo para seu modelo de voz, você precisa implantar a nova versão para criar um novo ponto de extremidade. Você só pode implantar a versão padrão.
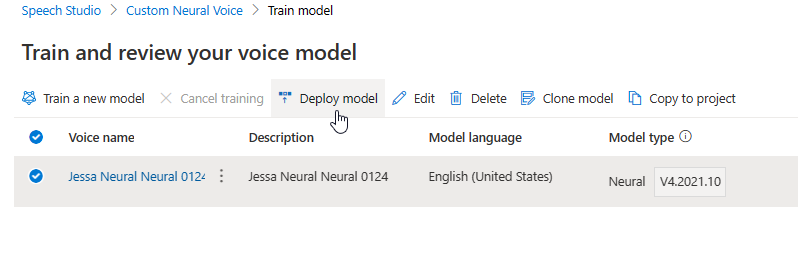
Depois de criar um novo ponto de extremidade, você precisa transferir o tráfego para o novo ponto de extremidade em seu produto.
Para saber mais sobre os recursos e limites desse recurso e as práticas recomendadas para melhorar a qualidade do modelo, consulte Características e limitações para o uso de voz neural personalizada.
Copie seu modelo de voz para outro projeto
Você pode copiar seu modelo de voz para outro projeto para a mesma região ou outra região. Por exemplo, você pode copiar um modelo de voz neural que foi treinado em uma região para um projeto para outra região.
Nota
Atualmente, o treinamento de voz neural personalizado está disponível apenas em algumas regiões. Você pode copiar um modelo de voz neural dessas regiões para outras regiões. Para obter mais informações, consulte as regiões para voz neural personalizada.
Para copiar seu modelo de voz neural personalizado para outro projeto:
No separador Modelo de comboio, selecione um modelo de voz que pretende copiar e, em seguida, selecione Copiar para projeto.
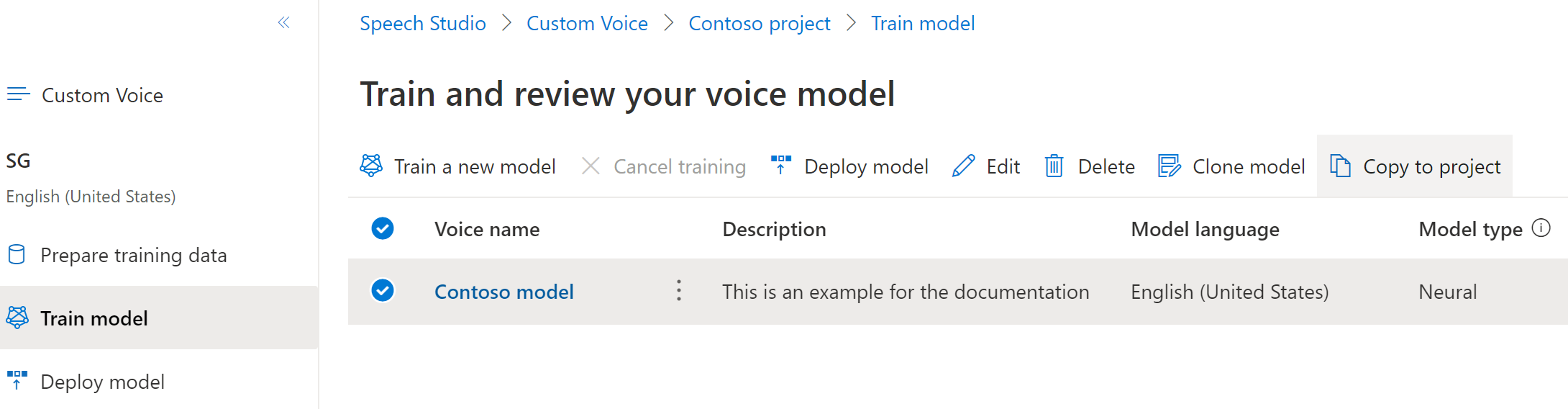
Selecione a Subscrição, Região, Recurso de Voz e Projeto onde pretende copiar o modelo. Você deve ter um recurso de fala e um projeto na região de destino, caso contrário, você precisa criá-los primeiro.
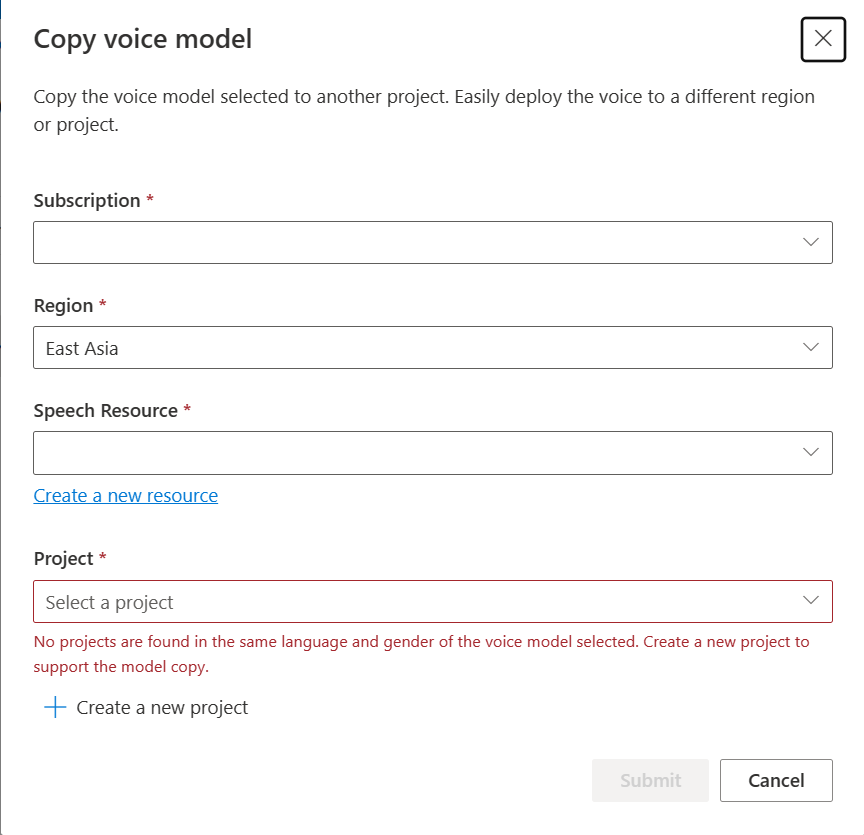
Selecione Enviar para copiar o modelo.
Selecione Exibir modelo na mensagem de notificação para a cópia bem-sucedida.
Navegue até o projeto onde você copiou o modelo para implantar a cópia do modelo.
Próximos passos
Neste artigo, você aprenderá a treinar uma voz neural personalizada por meio da API de voz personalizada.
Importante
Atualmente, o treinamento de voz neural personalizado está disponível apenas em algumas regiões. Depois que seu modelo de voz for treinado em uma região suportada, você poderá copiá-lo para um recurso de Fala em outra região, conforme necessário. Para obter mais informações, consulte as notas de rodapé na tabela Serviço de fala.
A duração do treinamento varia de acordo com a quantidade de dados que você usa. Leva cerca de 40 horas de computação, em média, para treinar uma voz neural personalizada. Os usuários de assinatura padrão (S0) podem treinar quatro vozes simultaneamente. Se você atingir o limite, espere até que pelo menos um de seus modelos de voz termine o treinamento e tente novamente.
Nota
Embora o número total de horas necessárias por método de formação varie, o mesmo preço unitário aplica-se a cada um deles. Para obter mais informações, consulte os detalhes de preços do treinamento neural personalizado.
Escolha um método de treino
Depois de validar seus arquivos de dados, use-os para criar seu modelo de voz neural personalizado. Ao criar uma voz neural personalizada, você pode optar por treiná-la com um dos seguintes métodos:
Neural: Crie uma voz no mesmo idioma dos seus dados de treinamento.
Neural - cross lingual: crie uma voz que fale um idioma diferente dos seus dados de treinamento. Por exemplo, com os dados de
fr-FRtreinamento, você pode criar uma voz que faleen-US.O idioma dos dados de treinamento e o idioma de destino devem ser um dos idiomas suportados para treinamento de voz multilíngüe. Não é necessário preparar dados de formação na língua de chegada, mas a sua folha de respostas de teste tem de estar na língua de chegada.
Neural - multi estilo: Crie uma voz neural personalizada que fale em vários estilos e emoções, sem adicionar novos dados de treinamento. Vozes de vários estilos são úteis para personagens de videogames, chatbots conversacionais, audiolivros, leitores de conteúdo e muito mais.
Para criar uma voz de vários estilos, você precisa preparar um conjunto de dados gerais de treinamento, pelo menos 300 enunciados. Selecione um ou mais dos estilos de fala de destino predefinidos. Você também pode criar vários estilos personalizados fornecendo amostras de estilo, de pelo menos 100 enunciados por estilo, como dados de treinamento extra para a mesma voz. Os estilos predefinidos suportados variam de acordo com diferentes idiomas. Veja os estilos predefinidos disponíveis em diferentes idiomas.
O idioma dos dados de treinamento deve ser um dos idiomas suportados para voz neural personalizada, cross lingual ou treinamento de vários estilos.
Criar um modelo de voz
Para criar uma voz neural, use a operação Models_Create da API de voz personalizada. Construa o corpo da solicitação de acordo com as seguintes instruções:
- Defina a propriedade necessária
projectId. Consulte Criar um projeto. - Defina a propriedade necessária
consentId. Consulte Adicionar consentimento de talento de voz. - Defina a propriedade necessária
trainingSetId. Consulte Criar um conjunto de treinamento. - Defina a propriedade de receita
kindnecessária paraDefaulttreinamento de voz neural. O tipo de receita indica o método de treino e não pode ser alterado posteriormente. Para usar um método de treinamento diferente, consulte Neural - cross lingual ou Neural - multistyle. Consulte Treinamento bilíngue para obter mais informações sobre treinamento bilíngue e diferenças entre localidades. - Defina a propriedade necessária
voiceName. O nome da voz deve terminar com "Neural" e não pode ser alterado posteriormente. Escolha um nome cuidadosamente. O nome da voz é usado em sua solicitação de síntese de fala pela entrada SDK e SSML. Apenas letras, números e alguns caracteres de pontuação são permitidos. Use nomes diferentes para diferentes modelos de voz neural. - Opcionalmente, defina a
descriptionpropriedade para a descrição de voz. A descrição da voz pode ser alterada mais tarde.
Faça uma solicitação HTTP PUT usando o URI, conforme mostrado no exemplo de Models_Create a seguir.
- Substitua
YourResourceKeypela chave de recurso de fala. - Substitua
YourResourceRegionpela região de recursos de Fala. - Substitua
JessicaModelIdpor um ID de modelo de sua escolha. O ID sensível a maiúsculas e minúsculas será usado no URI do modelo e não poderá ser alterado posteriormente.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Deverá receber um corpo de resposta no seguinte formato:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Formação bilingue
Se você selecionar o tipo de treinamento neural , poderá treinar uma voz para falar em vários idiomas. O zh-CN, zh-HKe zh-TW localidades suportam treinamento bilíngue para que a voz fale chinês e inglês. Dependendo em parte dos seus dados de treinamento, a voz sintetizada pode falar inglês com sotaque nativo de inglês ou inglês com o mesmo sotaque dos dados de treinamento.
Nota
Para permitir que uma voz na localidade fale zh-CN inglês com o mesmo sotaque dos dados de exemplo, você deve escolher Chinese (Mandarin, Simplified), English bilingual ao criar um projeto ou especificar a zh-CN (English bilingual) localidade para os dados do conjunto de treinamento por meio da API REST.
A tabela a seguir mostra as diferenças entre as localidades:
| Localidade do Speech Studio | Localidade da API REST | Suporte bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Se os dados de amostra incluírem inglês, a voz sintetizada fala inglês com sotaque nativo de inglês, em vez do mesmo sotaque que os dados de exemplo, independentemente da quantidade de dados em inglês. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Se você quiser que a voz sintetizada fale inglês com o mesmo sotaque dos dados de amostra, recomendamos incluir mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o sotaque de língua inglesa pode não ser o ideal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Se você quiser treinar uma voz sintetizada capaz de falar inglês com o mesmo sotaque que seus dados de amostra, certifique-se de fornecer mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o padrão é um sotaque nativo do inglês. O limite de 10% é calculado com base nos dados aceites após o carregamento bem-sucedido, e não nos dados anteriores ao carregamento. Se alguns dados em inglês carregados forem rejeitados devido a defeitos e não atingirem o limite de 10%, a voz sintetizada assume como padrão um sotaque nativo do inglês. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Se você quiser treinar uma voz sintetizada capaz de falar inglês com o mesmo sotaque que seus dados de amostra, certifique-se de fornecer mais de 10% de dados em inglês em seu conjunto de treinamento. Caso contrário, o padrão é um sotaque nativo do inglês. O limite de 10% é calculado com base nos dados aceites após o carregamento bem-sucedido, e não nos dados anteriores ao carregamento. Se alguns dados em inglês carregados forem rejeitados devido a defeitos e não atingirem o limite de 10%, a voz sintetizada assume como padrão um sotaque nativo do inglês. |
Estilos predefinidos disponíveis em diferentes idiomas
A tabela a seguir resume os diferentes estilos predefinidos de acordo com diferentes idiomas.
| Estilo de fala | Idioma (localidade) |
|---|---|
| irritado | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| calma | Chinês (mandarim, simplificado) (zh-CN) 1 |
| chat | Chinês (mandarim, simplificado) (zh-CN) 1 |
| alegre | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| descontentes | Chinês (mandarim, simplificado) (zh-CN) 1 |
| animado | Inglês (Estados Unidos) (en-US) |
| com medo | Chinês (mandarim, simplificado) (zh-CN) 1 |
| amigável | Inglês (Estados Unidos) (en-US) |
| esperançoso | Inglês (Estados Unidos) (en-US) |
| triste | Inglês (Estados Unidos) (en-US)Japonês (Japão) ( ja-JP) 1Chinês (mandarim, simplificado) ( zh-CN) 1 |
| gritando | Inglês (Estados Unidos) (en-US) |
| graves | Chinês (mandarim, simplificado) (zh-CN) 1 |
| apavorado | Inglês (Estados Unidos) (en-US) |
| hostil | Inglês (Estados Unidos) (en-US) |
| sussurrando | Inglês (Estados Unidos) (en-US) |
1 O estilo de voz neural está disponível em pré-visualização pública. Os estilos em pré-visualização pública só estão disponíveis nestas regiões de serviço: Leste dos EUA, Europa Ocidental e Sudeste Asiático.
Obter status de treinamento
Para obter o status de treinamento de um modelo de voz, use a operação Models_Get da API de voz personalizada. Construa o URI de solicitação de acordo com as seguintes instruções:
Faça uma solicitação HTTP GET usando o URI, conforme mostrado no exemplo de Models_Get a seguir.
- Substitua
YourResourceKeypela chave de recurso de fala. - Substitua
YourResourceRegionpela região de recursos de Fala. - Substitua
JessicaModelIdse você especificou um ID de modelo diferente na etapa anterior.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Você deve receber um corpo de resposta no seguinte formato.
Nota
A receita kind e outras propriedades dependem de como você treinou a voz. Neste exemplo, o tipo de receita é Default para treinamento de voz neural.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Pode ser necessário aguardar alguns minutos antes que o treinamento seja concluído. Eventualmente, o status mudará para um ou Succeeded Failed.