Atividades do cliente necessárias
Pré-incidente
Para serviços do Azure
- Esteja familiarizado com o Azure Service Health no portal do Azure. Esta página funcionará como um "balcão único" durante um incidente.
- Considere o uso de alertas de Integridade do Serviço, que podem ser configurados para produzir notificações automaticamente quando ocorrerem incidentes do Azure.
Para o Power BI
- Esteja familiarizado com o Estado de Funcionamento do Serviço no centro de administração do Microsoft 365. Esta página funcionará como um "balcão único" durante um incidente.
- Considere o uso do aplicativo móvel Microsoft 365 Admin para obter notificações automáticas de alerta de incidente de serviço.
Durante o incidente
Para serviços do Azure
- A Integridade do Serviço do Azure em seu portal de gerenciamento do Azure fornecerá as atualizações mais recentes.
- Se houver problemas para acessar a Integridade do Serviço, consulte a página Status do Azure.
- Se houver problemas para acessar a página Status, vá para @AzureSupport X (anteriormente Twitter).
- Se o impacto/problemas não corresponderem ao incidente (ou persistirem após a mitigação), entre em contato com o suporte para gerar um tíquete de suporte de serviço.
Para o Power BI
- A página Estado de Funcionamento do Serviço no centro de administração do Microsoft 365 fornecerá as atualizações mais recentes
- Se houver problemas para acessar a Integridade do Serviço, consulte a página de status do Microsoft 365
- Se o impacto/problemas não corresponderem ao incidente (ou se os problemas persistirem após a mitigação), você deverá gerar um tíquete de suporte de serviço.
Recuperação pós-Microsoft
Consulte as seções abaixo para obter esses detalhes.
Pós-incidente
Para Serviços do Azure
- A Microsoft publicará um PIR no portal do Azure - Estado de Funcionamento do Serviço para revisão.
Para o Power BI
- A Microsoft publicará um PIR no Microsoft 365 Admin - Service Health para revisão.
Aguarde o processo da Microsoft
O processo "Aguarde pela Microsoft" está simplesmente esperando que a Microsoft recupere todos os componentes e serviços na região principal afetada. Uma vez recuperada, valide a vinculação da plataforma de dados aos serviços corporativos compartilhados ou outros, a data do conjunto de dados e, em seguida, execute os processos de atualização do sistema para a data atual.
Uma vez concluído esse processo, a validação técnica e de especialistas no assunto do negócio (SME) pode ser concluída, permitindo a aprovação das partes interessadas para a recuperação do serviço.
Reimplantar em caso de desastre
Para uma estratégia de "Reimplantação em caso de desastre", o seguinte fluxo de processo de alto nível pode ser descrito.
Recupere os serviços compartilhados corporativos e os sistemas de origem da Contoso

- Esta etapa é um pré-requisito para a recuperação da plataforma de dados.
- Esta etapa seria concluída pelos vários grupos de suporte operacional da Contoso responsáveis pelos serviços compartilhados corporativos e sistemas de origem operacional.
Recuperar serviços do Azure Os Serviços do Azure referem-se aos aplicativos e serviços que fazem a oferta da Nuvem do Azure e estão disponíveis na região secundária para implantação.

Os Serviços do Azure referem-se aos aplicativos e serviços que fazem a oferta da Nuvem do Azure e estão disponíveis na região secundária para implantação.
- Esta etapa é um pré-requisito para a recuperação da plataforma de dados.
- Esta etapa seria concluída pela Microsoft e outros parceiros de plataforma como serviço (PaaS)/software como serviço (SaaS).
Recupere a base da plataforma de dados
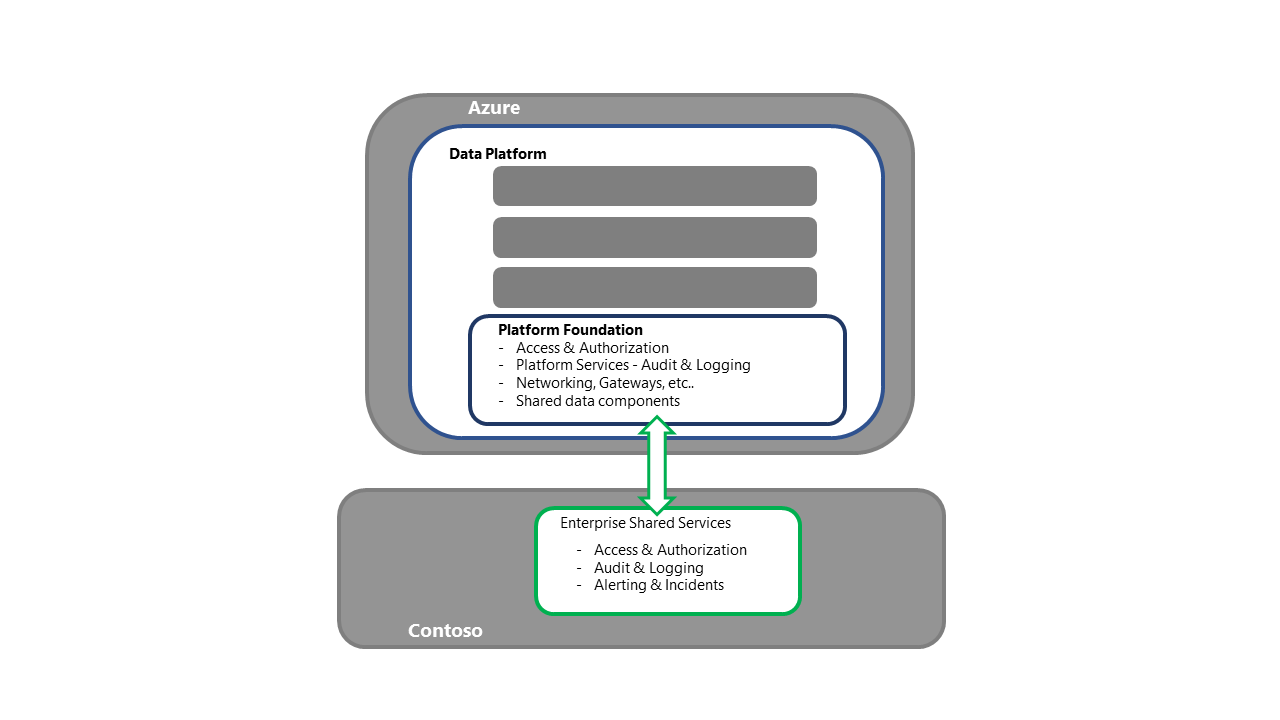
- Esta etapa é o ponto de entrada para as atividades de recuperação da plataforma.
- Para a estratégia de reimplantação, cada componente/serviço necessário seria adquirido e implantado na região secundária.
- Consulte a Seção Serviço e Componente do Azure nesta série para obter um detalhamento detalhado dos componentes e estratégias de implantação.
- Esse processo também deve incluir atividades como a vinculação aos serviços compartilhados da empresa, garantindo a conectividade para acesso/autenticação e validando se o descarregamento de log está funcionando, ao mesmo tempo em que garante a conectividade com processos upstream e downstream.
- Os dados/processamento devem ser confirmados. Por exemplo, validação do carimbo de data/hora da plataforma recuperada.
- Se houver dúvidas sobre a integridade dos dados, a decisão pode ser tomada para reverter ainda mais no tempo antes de executar o novo processamento para atualizar a plataforma.
- Ter uma ordem de prioridade para os processos (com base no impacto nos negócios) ajudará a orquestrar a recuperação.
- Esta etapa deve ser encerrada por validação técnica, a menos que os utilizadores empresariais interajam diretamente com os serviços. Se houver acesso direto, será necessária uma etapa de validação de negócios.
- Uma vez concluída a validação, uma transferência para as equipes de solução individuais para iniciar seu próprio processo de recuperação de desastres (DR) acontece.
- Esta transferência deve incluir a confirmação do carimbo de data/hora atual dos dados e processos.
- Se os principais processos de dados corporativos forem executados, as soluções individuais devem estar cientes disso - fluxos de entrada/saída, por exemplo.
Recupere as soluções individuais hospedadas pela plataforma
- Cada solução individual deve ter seu próprio runbook de DR. Os runbooks devem conter pelo menos as partes interessadas de negócios nomeadas que testarão e confirmarão que a recuperação do serviço foi concluída.
- Dependendo da contenção ou prioridade de recursos, as principais soluções/cargas de trabalho podem ser priorizadas em detrimento de outras - processos empresariais centrais em vez de laboratórios ad hoc, por exemplo.
- Uma vez concluídas as etapas de validação, uma transferência para as soluções downstream para iniciar seu processo de recuperação de DR acontece.
Transferência para sistemas dependentes a jusante
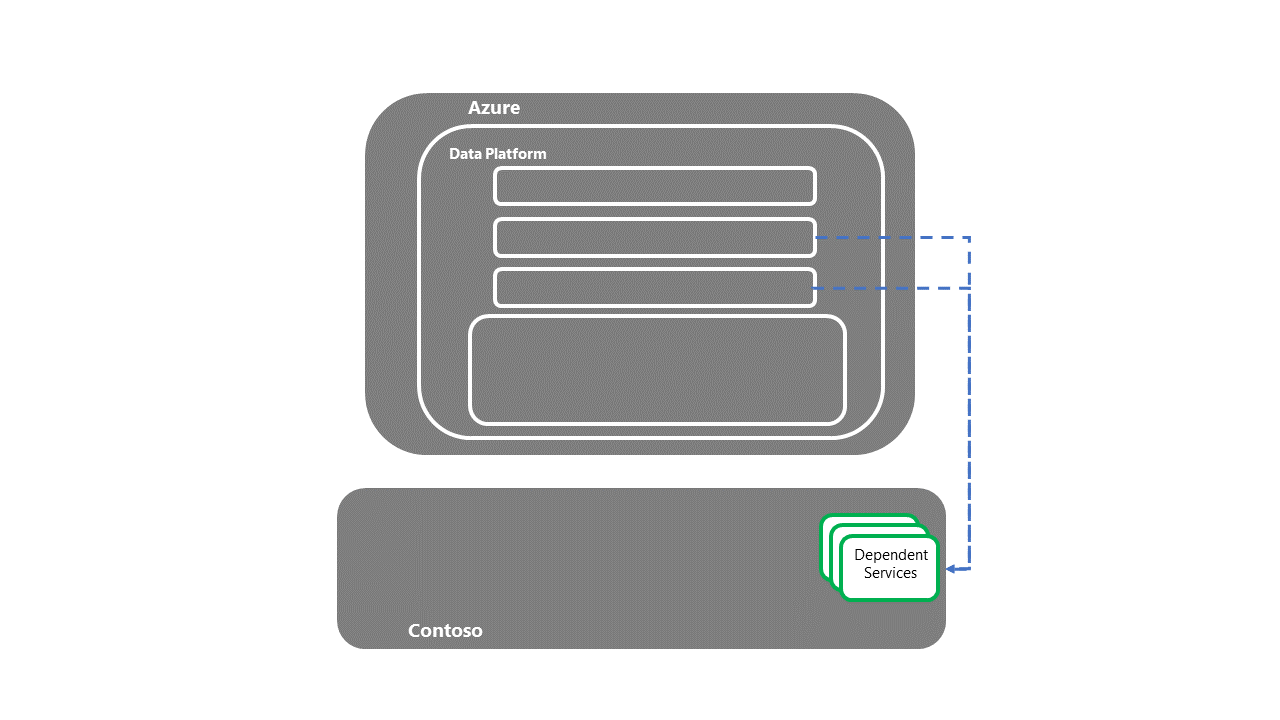
- Depois que os serviços dependentes tiverem sido recuperados, o processo de recuperação E2E DR será concluído.
Nota
Embora seja teoricamente possível automatizar completamente um processo E2E DR, é improvável dado o risco do evento versus o custo das atividades SDLC necessárias para cobrir o processo E2E.
Fallback para a região primária O fallback é o processo de mover o serviço da plataforma de dados e seus dados de volta para a região primária, assim que estiverem disponíveis para BAU.
Dependendo da natureza dos sistemas de origem e dos vários processos de dados, o fallback da plataforma de dados pode ser feito independentemente de outras partes do ecossistema de dados.
Os clientes são aconselhados a rever as dependências da sua própria plataforma de dados (tanto a montante como a jusante) para tomar a decisão adequada. A seção a seguir pressupõe uma recuperação independente da plataforma de dados.
- Depois que todos os componentes/serviços necessários estiverem disponíveis na região principal, os clientes completarão um teste de fumaça para validar a recuperação da Microsoft.
- A configuração do componente/serviço seria validada. Os deltas seriam resolvidos por meio de reimplantação a partir do controle do código-fonte.
- A data do sistema na região primária seria estabelecida entre os componentes com monitoração de estado. O delta entre a data estabelecida e o carimbo de data/hora na região secundária deve ser resolvido executando ou repetindo os processos de ingestão de dados a partir desse ponto.
- Com a aprovação das partes interessadas comerciais e técnicas, seria selecionada uma janela de recurso. Idealmente, isso deve acontecer durante uma pausa na atividade e processamento do sistema.
- Durante o fallback, a região primária seria sincronizada com a região secundária, antes que o sistema fosse trocado.
- Após um período de execução paralela, a região secundária seria retirada do ar do sistema.
- Os componentes na região secundária seriam descartados ou removidos, dependendo da estratégia de DR selecionada.
Processo de sobressalente quente
Para uma estratégia de "Warm Spare", o fluxo de processo de alto nível está estreitamente alinhado ao do "Redeploy on Disaster", a principal diferença é que os componentes já foram adquiridos na região secundária. Essa estratégia elimina o risco de contenção de recursos de outras organizações que procuram concluir sua própria DR nessa região.
Processo Hot Spare
A estratégia "Hot Spare" significa que os serviços da plataforma, incluindo PaaS e sistemas de infraestrutura como serviço (IaaS), persistirão apesar do evento de desastre, pois os sistemas secundários são executados em conjunto com os sistemas primários. Tal como acontece com a estratégia "Warm Spare", esta estratégia elimina o risco de contenção de recursos de outras organizações que procuram completar a sua própria DR naquela região.
Os clientes Hot Spare monitorariam a recuperação de componentes/serviços da Microsoft na região principal. Uma vez concluído, os clientes validariam os sistemas da região primária e completariam o fallback para a região primária. Esse processo seria semelhante ao processo de failover de DR, ou seja, verifique a base de código e os dados disponíveis, reimplantando conforme necessário.
Nota
Uma observação especial aqui deve ser feita para garantir que todos os metadados do sistema sejam consistentes entre as duas regiões.
- Depois que o Fallback para o primário for concluído, os balanceadores de carga do sistema poderão ser atualizados para trazer a região primária de volta à topologia do sistema. Se disponível, uma abordagem de liberação canária pode ser usada para alternar incrementalmente a região primária para o sistema.
Estrutura do plano de DR
Um plano de DR eficaz apresenta um guia passo a passo para recuperação de serviço que pode ser executado por um recurso técnico do Azure. Como tal, o seguinte lista uma estrutura MVP proposta para um Plano DR.
- Requisitos do processo
- Qualquer detalhe específico do processo de DR do cliente, como a autorização correta necessária para iniciar o DR e tomar decisões importantes sobre a recuperação, conforme necessário (incluindo "definição de concluído"), referência de tíquete de DR de suporte ao serviço e detalhes da sala de guerra.
- Confirmação de recursos, incluindo o backup do lead e do executor de DR. Todos os recursos devem ser documentados com contatos primários e secundários, caminhos de escalonamento e calendários de licença. Em situações críticas de DR, os sistemas de escala podem precisar ser considerados.
- Laptop, pacotes de energia ou energia de backup, conectividade de rede e detalhes do telefone celular para o executor de DR, backup de DR e quaisquer pontos de escalonamento.
- O processo a ser seguido se algum dos requisitos do processo não for atendido.
- Lista de contatos
- Liderança de DR e grupos de apoio.
- PME empresariais que completarão o ciclo de teste/revisão para a recuperação técnica.
- Proprietários de empresas afetados, incluindo os aprovadores de recuperação de serviços.
- Proprietários técnicos afetados, incluindo os aprovadores de recuperação técnica.
- Apoio às PME em todas as áreas afetadas, incluindo as principais soluções alojadas pela plataforma.
- Sistemas a jusante afetados – suporte operacional.
- Sistemas fonte upstream – suporte operacional.
- Contatos de serviços compartilhados corporativos. Por exemplo, suporte de acesso e autenticação, monitoramento de segurança e suporte de gateway
- Quaisquer fornecedores externos ou terceiros, incluindo contactos de suporte para fornecedores de serviços em nuvem.
- Projeto de arquitetura
- Descreva os detalhes do cenário final (E2E) e anexe toda a documentação de suporte associada.
- Dependências
- Liste todas as relações e dependências dos componentes.
- Pré-requisitos de DR
- Confirmação de que os sistemas fonte a montante estão disponíveis conforme necessário.
- O acesso elevado através da pilha foi concedido aos recursos do executor de DR.
- Os serviços do Azure estão disponíveis conforme necessário.
- O processo a ser seguido se algum dos pré-requisitos não tiver sido cumprido.
- Recuperação técnica - instruções passo-a-passo
- Ordem de execução.
- Descrição do passo.
- Pré-requisito da etapa.
- Etapas detalhadas do processo para cada ação discreta, incluindo URLs.
- Instruções de validação, incluindo as provas exigidas.
- Tempo esperado para concluir cada etapa, incluindo contingências.
- O processo a ser seguido se a etapa falhar.
- Os pontos de escalonamento em caso de falha ou apoio às PME.
- Recuperação técnica - pós-requisitos
- Confirme o carimbo de data/hora atual do sistema nos principais componentes.
- Confirme os URLs e IPs do sistema DR.
- Preparar-se para o processo de revisão das partes interessadas do negócio, incluindo a confirmação do acesso aos sistemas e a conclusão da validação e aprovação das PME empresariais.
- Revisão e aprovação das partes interessadas do negócio
- Detalhes de contato do recurso comercial.
- As etapas de validação de negócios de acordo com a recuperação técnica acima.
- O rastro de provas exigido do aprovador de negócios assinando a recuperação.
- Pós-requisitos de recuperação
- Entrega ao suporte operacional para execução dos processos de dados para atualização do sistema.
- Entregar os processos e soluções a jusante – confirmando a data e os detalhes de ligação do sistema DR.
- Confirme o processo de recuperação completo com o lead DR – confirmando a trilha de evidências e o runbook concluído.
- Notifique as equipes de segurança de que privilégios de acesso elevados podem ser removidos da equipe de DR.
Textos explicativos
- Recomenda-se incluir capturas de tela do sistema de cada processo de etapa. Estas capturas de ecrã ajudarão a resolver a dependência das PME do sistema para concluir as tarefas.
- Para acompanhar a rápida evolução dos serviços de nuvem, o plano de DR deve ser regularmente revisitado, testado e executado por recursos com conhecimento atual do Azure e seus serviços.
- As etapas técnicas de recuperação devem refletir a prioridade do componente e da solução para a organização. Por exemplo, os principais fluxos de dados corporativos são recuperados antes de laboratórios de análise de dados ad hoc.
- As etapas de recuperação técnica devem seguir a ordem dos fluxos de trabalho (normalmente da esquerda para a direita), uma vez que os componentes básicos ou o serviço como o Key Vault tenham sido recuperados. Essa estratégia garantirá que as dependências a montante estejam disponíveis e que os componentes possam ser testados adequadamente.
- Uma vez concluído o plano passo-a-passo, deve ser obtido um tempo total para atividades com contingência. Se este total exceder o objetivo de tempo de recuperação (RTO) acordado, existem várias opções disponíveis:
- Automatize os processos de recuperação selecionados (sempre que possível).
- Procure oportunidades para executar etapas de recuperação selecionadas em paralelo (sempre que possível). No entanto, observando que essa estratégia pode exigir recursos adicionais do executor de DR.
- Elevar os principais componentes para níveis mais altos de níveis de serviço, como PaaS, onde a Microsoft assume maior responsabilidade pelas atividades de recuperação de serviços.
- Estender o RTO com as partes interessadas.
Testes de DR
A natureza da oferta do serviço de Nuvem do Azure resulta em restrições para qualquer cenário de teste de DR. Portanto, a orientação é manter uma assinatura de DR com os componentes da plataforma de dados, pois eles estariam disponíveis na região secundária.
A partir dessa linha de base, o runbook do plano de DR pode ser executado seletivamente, prestando atenção específica aos serviços e componentes que podem ser implantados e validados. Este processo exigirá um conjunto de dados de teste selecionado, permitindo a confirmação das verificações técnicas e de validação de negócios de acordo com o plano.
Um plano de DR deve ser testado regularmente não só para garantir que está atualizado, mas também para construir "memória muscular" para as equipes que realizam atividades de failover e recuperação.
- Os backups de dados e configurações também devem ser testados regularmente para garantir que sejam "adequados à finalidade" para dar suporte a quaisquer atividades de recuperação.
A área-chave a ser focada durante um teste de DR é garantir que as etapas prescritivas ainda estejam corretas e que os tempos estimados ainda sejam relevantes.
- Se as instruções refletirem as telas do portal em vez de código – as instruções devem ser validadas pelo menos a cada 12 meses devido à cadência de mudança na nuvem.
Embora a aspiração seja ter um processo de DR totalmente automatizado, a automação total pode ser improvável devido à raridade do evento. Portanto, é recomendável estabelecer a linha de base de recuperação com a infraestrutura DSC (Configuração de Estado Desejado) como código (IaC) usado para fornecer a plataforma e, em seguida, atualizar à medida que novos projetos se baseiam na linha de base.
- Com o tempo, à medida que os componentes e serviços são estendidos, um NFR deve ser imposto, exigindo que o pipeline de implantação de produção seja refatorado para fornecer cobertura para DR.
Se os tempos do runbook excederem o RTO, há várias opções:
- Estender o RTO com as partes interessadas.
- Diminua o tempo necessário para as atividades de recuperação, por meio de automação, execução de tarefas em paralelo ou migração para níveis mais altos de servidor em nuvem.
Azure Chaos Studio
O Azure Chaos Studio é um serviço gerenciado para melhorar a resiliência injetando falhas em seus aplicativos do Azure. O Chaos Studio permite orquestrar a injeção de falhas em seus recursos do Azure de forma segura e controlada, usando experimentos. Consulte a documentação do produto para obter uma descrição dos tipos de falhas suportados atualmente.
A iteração atual do Chaos Studio abrange apenas um subconjunto de componentes e serviços do Azure. Até que mais bibliotecas de falhas sejam adicionadas, o Chaos Studio é uma abordagem recomendada para testes de resiliência isolados em vez de testes completos de DR do sistema.
Mais informações sobre o Chaos studio podem ser encontradas na documentação do Azure Chaos Studio.
Azure Site Recovery
Para componentes IaaS, o Azure Site Recovery protegerá a maioria das cargas de trabalho em execução em uma VM ou servidor físico com suporte
Existem orientações sólidas para:
- Executando um Drill de Recuperação de Desastres de VM do Azure
- Executando um failover de DR para uma região secundária
- Executando um fallback de DR para a região primária
- Habilitando a automação de um plano de DR
Recursos relacionados
- Arquitetura para resiliência e disponibilidade
- Continuidade de negócio e recuperação após desastre
- Backup e recuperação de desastres para aplicativos do Azure
- Resiliência no Azure
- Resumo dos contratos de nível de serviço (SLAs)
- Cinco práticas recomendadas para antecipar falhas
Próximos passos
Agora que você aprendeu como implantar o cenário, pode ler um resumo da série DR para plataforma de dados do Azure.