A arquitetura descrita neste artigo demonstra como você pode usar o Teradata VantageCloud Enterprise junto com o Azure Data Factory para desenvolver pipelines de integração de dados com uma abordagem low-code ou no-code. Ele mostra como ingerir ou extrair rapidamente dados do Vantage em uma conexão de segurança aprimorada usando o Data Factory.
Apache®, Hadoop e o logotipo flame são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. Nenhum endosso da Apache Software Foundation está implícito no uso dessas marcas.
Arquitetura
O diagrama a seguir ilustra uma versão da arquitetura que usa conectividade de emparelhamento de rede virtual. Ele usa um tempo de execução de integração (IR) auto-hospedado para se conectar ao banco de dados de análise. As VMs da Teradata são implantadas apenas com endereços IP privados.

Transfira um ficheiro do Visio desta arquitetura.
O diagrama a seguir ilustra uma versão da arquitetura que usa a conectividade do Azure Private Link.

Transfira um ficheiro do Visio desta arquitetura.
O VantageCloud Enterprise on Azure é um serviço totalmente gerenciado implantado em uma assinatura do Azure de propriedade da Teradata. Você implanta serviços de nuvem em sua própria assinatura do Azure, que é conectada à assinatura gerenciada pelo Teradata por meio de uma das opções de conectividade aprovadas. O Teradata dá suporte aos seguintes tipos de conectividade entre sua assinatura do Azure e o VantageCloud Enterprise no Azure:
- Peering de rede virtual
- Private Link
- WAN Virtual do Azure
Se você planeja usar o emparelhamento de rede virtual, trabalhe com o suporte da Teradata ou com sua equipe de conta Teradata para garantir que as configurações de grupo de segurança necessárias estejam em vigor para iniciar o tráfego do IR auto-hospedado para o banco de dados por meio do link de emparelhamento de rede virtual.
Componentes
Para implementar essa arquitetura, você precisa estar familiarizado com o Data Factory, o Armazenamento de Blobs do Azure, o Teradata VantageCloud Enterprise e o Teradata Tools and Utilities (TTU).
Esses componentes e versões são usados nos cenários de integração:
- Teradata VantageCloud Enterprise 17.20, hospedado no Azure
- Fábrica de Dados do Azure
- Armazenamento de Blobs do Azure
- TTU 17,20
- Driver ODBC Teradata 17.20.12
- Teradata Studio 17,20
Teradata Vantage
O Vantage fornece o que a Teradata chama de Pervasive Data Intelligence. Os usuários em toda a sua organização podem usá-lo para obter respostas inteligentes e em tempo real para suas perguntas. Nessa arquitetura, o Vantage no Azure é usado como origem ou destino para tarefas de integração de dados. O Vantage Native Object Storage (NOS) é usado para integrar com dados no Blob Storage.
Data Factory
O Data Factory é um serviço de extração, transformação, carregamento (ETL) na nuvem sem servidor. Você pode usá-lo para orquestrar e automatizar a movimentação e a transformação de dados. Ele fornece uma interface de usuário livre de código para ingestão de dados e criação intuitiva e monitoramento e gerenciamento de painel único.
Você pode usar o Data Factory para criar e agendar fluxos de trabalho controlados por dados (chamados pipelines) que podem ingerir dados de vários armazenamentos de dados. Você pode criar processos ETL complexos que transformam dados visualmente usando fluxos de dados executados no Spark ou serviços de computação como Azure Batch, Azure Machine Learning, Apache Spark, SQL, Azure HDInsight com Hadoop e Azure Databricks. Trabalhar com o Data Factory envolve as seguintes camadas, listadas desde o mais alto nível de abstração até o software mais próximo dos dados.
- Pipelines são interfaces gráficas que contêm atividades e caminhos de dados.
- As atividades executam operações em dados.
- Fontes e coletores são atividades que especificam de onde vêm os dados e para onde vão.
- Os conjuntos de dados são conjuntos de dados bem definidos que o Data Factory ingere, carrega e transforma.
- Os serviços vinculados permitem que o Data Factory acesse informações de conexão para fontes de dados externas específicas.
- O tempo de execução de integração (IR) fornece um gateway entre o Data Factory e dados ou recursos de computação.
Runtime de integração autoalojado
O IR auto-hospedado pode executar operações de cópia entre armazenamentos de dados em nuvem e armazenamentos de dados de rede privada. Você também pode transformar seus recursos de computação em uma rede local ou em uma rede virtual do Azure. Você precisa de um computador local ou máquina virtual em sua rede privada para instalar o IR auto-hospedado. Para obter mais informações, consulte Considerações sobre o uso de um IR auto-hospedado. Este artigo descreve como usar o IR auto-hospedado para se conectar ao VantageCloud e extrair dados para carregar no Armazenamento do Azure Data Lake.
Conector Teradata
Nessa arquitetura, o Data Factory usa o conector Teradata para se conectar ao Vantage. O conector Teradata suporta:
- Teradata versões 14.10, 15.0, 15.10, 16.0, 16.10 e 16.20.
- Copiar dados usando autenticação básica, Windows ou LDAP.
- Cópia paralela de uma fonte Teradata. Para obter mais informações, consulte Cópia paralela do Teradata.
Este artigo descreve como configurar serviços vinculados e conjuntos de dados para a atividade Copy Data do data factory, que ingere dados do Vantage e os carrega no Data Lake Storage.
Detalhes do cenário
Este artigo descreve três cenários:
- Data Factory extraindo dados do VantageCloud Enterprise e carregando-os no Blob Storage
- Data Factory carregando dados no VantageCloud Enterprise a partir do Blob Storage
- Usando a funcionalidade Vantage NOS para acessar dados transformados e carregados no Blob Storage pelo Data Factory
Cenário 1: Carregar dados no armazenamento de Blob a partir do VantageCloud
Este cenário descreve como usar o Data Factory para extrair dados do VantageCloud Enterprise, executar algumas transformações básicas e carregar os dados em um contêiner de Armazenamento de Blob.
O cenário destaca a integração nativa entre o Data Factory e o Vantage e a facilidade com que você pode criar um pipeline de ETL corporativo para integrar dados no Vantage.
Para concluir este procedimento, você precisa ter um contêiner de Armazenamento de Blob em sua assinatura, conforme mostrado nos diagramas de arquitetura.
Para criar um conector nativo para o Vantage, no seu data factory, selecione a guia Gerenciar, selecione Serviços vinculados e selecione Novo:

Procure Teradata e, em seguida, selecione o conector Teradata . Em seguida, selecione Continuar:
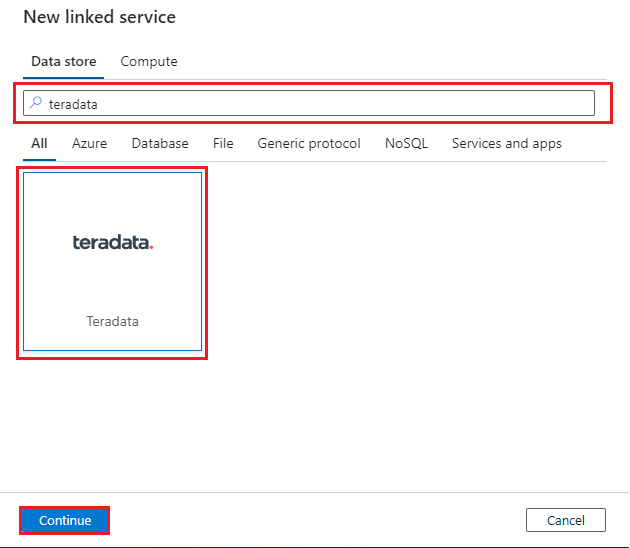
Configure o serviço vinculado para se conectar ao seu banco de dados Vantage. Use o mecanismo de autenticação mais seguro disponível e defina os parâmetros de acordo. Para obter mais informações, consulte Propriedades do serviço vinculado do conector Teradata. Use o Cofre da Chave como a fonte para quaisquer segredos de conexão. Você usará um IR auto-hospedado. Para obter mais informações, consulte estas instruções para implantar um IR auto-hospedado. Implante-o na mesma rede virtual que seu data factory.
Use os seguintes valores para configurar o serviço vinculado:
- Nome: insira um nome para sua conexão de serviço vinculado.
- Conectar via tempo de execução de integração: Selecione SelfHostedIR.
- Nome do servidor:
- Se você estiver se conectando por meio de emparelhamento de rede virtual, forneça o endereço IP de uma VM no cluster Teradata. Você pode se conectar ao endereço IP de qualquer VM no cluster.
- Se você estiver se conectando via Private Link, forneça o endereço IP do ponto de extremidade privado que você criou em sua rede virtual para se conectar ao cluster Teradata via Private Link.
- Tipo de autenticação: escolha o tipo de autenticação mais seguro, fornecendo segredos do Cofre de Chaves do Azure.
- Selecione Testar conexão e, em seguida, selecione Criar. Certifique-se de que a criação interativa esteja habilitada para seu IR para que a funcionalidade de conexão de teste funcione.
Para testes, você pode usar um banco de dados de teste no Vantage chamado
NYCTaxiADFIntegration. Este banco de dados tem uma única tabela chamadaGreen_Taxi_Trip_Data. Você pode baixar o banco de dados do NYC OpenData. A instrução CREATE TABLE a seguir pode ajudá-lo a entender o esquema da tabela.CREATE MULTISET TABLE NYCTaxiADFIntegration.Green_Taxi_Trip_Data, FALLBACK , NO BEFORE JOURNAL, NO AFTER JOURNAL, CHECKSUM = DEFAULT, DEFAULT MERGEBLOCKRATIO, MAP = TD_MAP1 ( VendorID BYTEINT, lpep_pickup_datetime DATE FORMAT ‘YY/MM/DD’, lpep_dropoff_datetime DATE FORMAT ‘YY/MM/DD’, store_and_fwd_flag VARCHAR(1) CHARACTER SET LATIN CASESPECIFIC, RatecodeID BYTEINT, PULocationID SMALLINT, DOLocationID SMALLINT, passenger_count BYTEINT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(18,16), mta_tax DECIMAL(4,2), tip_amount FLOAT, tolls_amount DECIMAL(18,16), ehail_fee BYTEINT, improvement_surcharge DECIMAL(3,1), total_amount DECIMAL(21,17), payment_type BYTEINT, trip_type BYTEINT, congestion_surcharge DECIMAL(4,2)) NO PRIMARY INDEX ;Em seguida, crie um pipeline simples para copiar os dados da tabela, execute algumas transformações básicas e, em seguida, carregue os dados em um contêiner de Armazenamento de Blob. Conforme observado no início deste procedimento, você já deve ter criado o contêiner de Armazenamento de Blob em sua assinatura. Primeiro, crie um serviço vinculado para se conectar ao contêiner, que é o coletor para o qual você copiará os dados.
Selecione o separador Gerir no seu data factory, selecione Serviços ligados e, em seguida, selecione Novo:
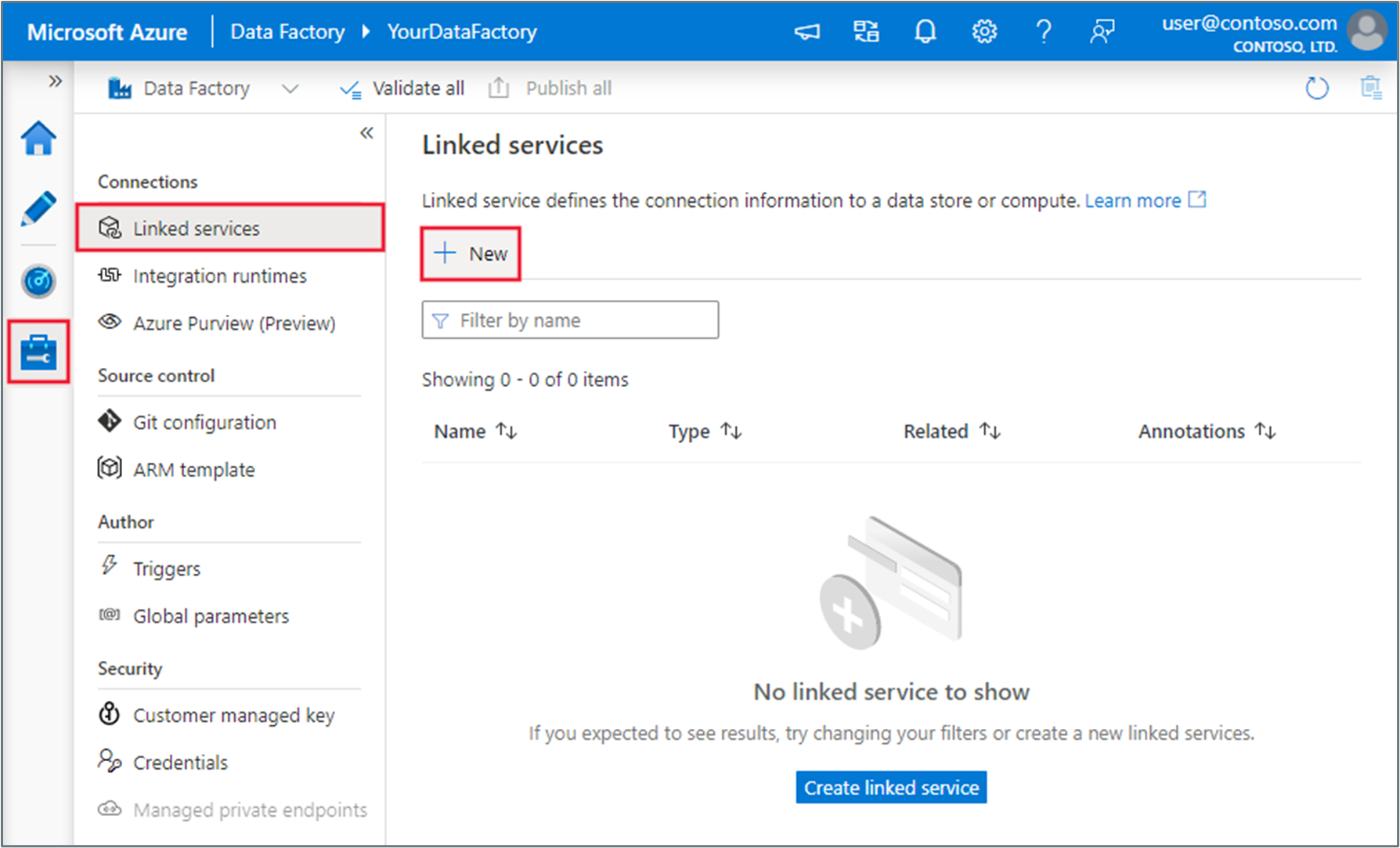
Procure o Blob do Azure, selecione o conector de Armazenamento de Blob do Azure e selecione Continuar:

Configure o serviço vinculado para se conectar à conta de Armazenamento de Blob:
- Nome: insira um nome para sua conexão de serviço vinculado.
- Conectar via tempo de execução de integração: Selecione AutoResolveIntegrationRuntime.
- Tipo de autenticação: Selecione Chave da conta.
- Subscrição do Azure: introduza o seu ID de subscrição do Azure.
- Nome da conta de armazenamento: insira o nome da sua conta de Armazenamento do Azure.
Selecione Testar conexão para verificar a conexão e, em seguida, selecione Criar.

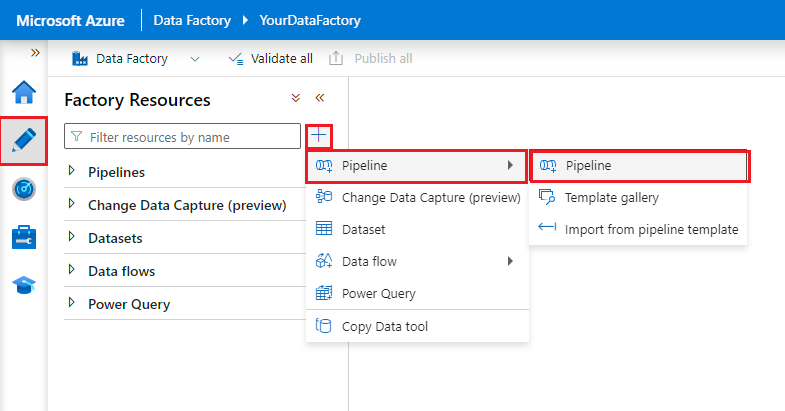
Crie um pipeline do Data Factory:
- Selecione a guia Autor .
- Selecione o botão +.
- Selecione Pipeline.
- Insira um nome para o pipeline.
Crie dois conjuntos de dados:
- Selecione a guia Autor .
- Selecione o botão +.
- Selecione Conjunto de dados.
- Crie um conjunto de dados para a
Green_Taxi_Trip_Datatabela Teradata:
- Selecione Teradata como o armazenamento de dados.
- Nome: insira um nome para o conjunto de dados.
- Serviço vinculado: selecione o serviço vinculado que você criou para Teradata nas etapas 2 e 3.
- Nome da tabela: Selecione a tabela na lista.
- Selecione OK.

- Crie um conjunto de dados de Blob do Azure:
- Selecione Blob do Azure como o Repositório de Dados.
- Selecione o formato dos seus dados. O parquet é usado nesta demonstração.
- Serviço vinculado: selecione o serviço vinculado que você criou na etapa 6.
- Caminho do arquivo: insira o caminho do arquivo de blob.
- Esquema de importação: selecione Nenhum.
- Selecione OK.

Arraste uma atividade Copiar dados para o pipeline.
Nota
Atualmente, o conector Teradata não suporta a atividade de fluxo de dados no Data Factory. Se você quiser executar a transformação nos dados, recomendamos que adicione uma atividade de Fluxo de Dados após a atividade Copiar.
Configure a atividade Copiar dados:
Na guia Origem, em Conjunto de dados de origem, selecione o conjunto de dados da tabela Teradata que você criou na etapa anterior.
Para Consulta Uso, selecione Tabela.
Use os valores padrão para as outras opções.

Na guia Coletor, em Conjunto de dados do coletor, selecione o conjunto de dados de Blob do Azure que você criou na etapa anterior.
Use os valores padrão para as outras opções.

Selecione Depurar. O pipeline copia os dados da tabela Teradata para um arquivo Parquet no Blob Storage.










Cenário 2: Carregar dados no VantageCloud a partir do armazenamento de Blob
Este cenário descreve como usar um conector ODBC para se conectar ao Vantage por meio da VM IR auto-hospedada para carregar dados. Como o IR precisa ser instalado e configurado com o driver ODBC Teradata, essa opção funciona apenas com um IR auto-hospedado do Data Factory.
Você também pode usar TTU, atividades personalizadas do Data Factory e Azure Batch para carregar dados no Vantage e transformá-los. Para obter mais informações, consulte Conectar o Teradata Vantage ao Azure Data Factory usando o recurso de atividade personalizada. Recomendamos que você avalie ambas as opções quanto a considerações de desempenho, custo e gerenciamento e escolha a opção mais adequada às suas necessidades.
Comece preparando o IR auto-hospedado que você criou no cenário anterior. Você precisa instalar o driver ODBC Teradata nele. Este cenário usa uma VM do Windows 11 para o IR auto-hospedado.
- Use RDP para se conectar à VM.
- Baixe e instale o driver ODBC Teradata.
- Se o JAVA JRE ainda não estiver na VM, baixe-o e instale-o.
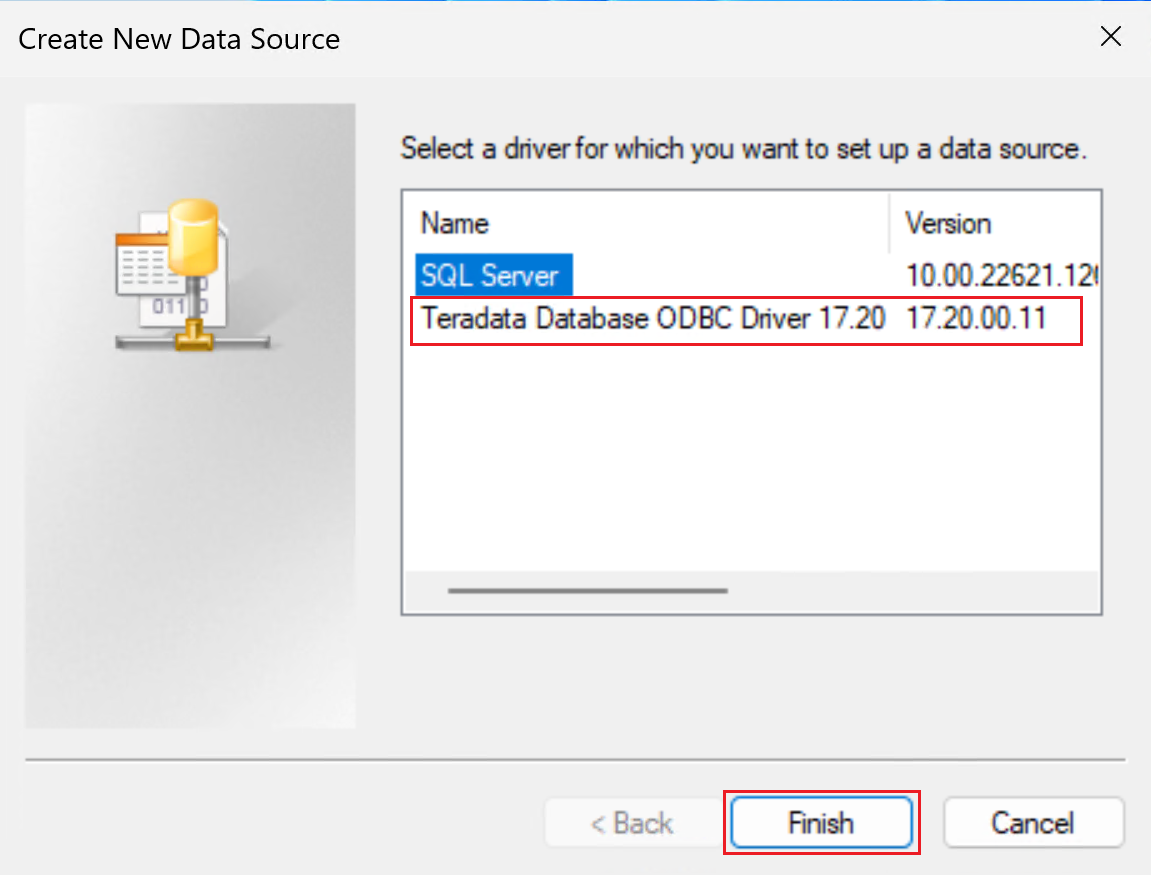
Crie um DSN de sistema de 64 bits para o banco de dados Teradata adicionando uma fonte de dados ODBC.
Certifique-se de usar a janela DSN de 64 bits.
Selecione o driver ODBC do banco de dados Teradata, conforme mostrado na captura de tela a seguir.
Selecione Concluir para abrir a janela de configuração do driver.
Configure as propriedades do DSN.
Nome: insira um nome para o DSN.
Em Informações do Teradata Server, em Nome ou Endereço IP:
- Se você estiver se conectando por meio de emparelhamento de rede virtual, forneça o endereço IP de uma VM no cluster Teradata. Você pode se conectar ao endereço IP de qualquer VM no cluster.
- Se você estiver se conectando via Private Link, forneça o endereço IP do ponto de extremidade privado que você criou em sua rede virtual para se conectar ao cluster Teradata via Private Link.
Opcionalmente, forneça o Nome de usuário e selecione Testar. Você será solicitado a inserir as credenciais. Selecione OK e verifique se a conexão foi bem-sucedida. Observe que você fornecerá o nome de usuário e a senha no Data Factory ao criar o serviço vinculado ODBC usado para se conectar ao banco de dados Teradata a partir do Data Factory.
Deixe os outros campos em branco.
Selecione OK.

A janela Administrador da Fonte de Dados ODBC será semelhante à da captura de tela a seguir. Selecione Aplicar. Agora você pode fechar a janela. Seu IR auto-hospedado agora está pronto para se conectar ao Vantage usando ODBC.

No Data Factory, crie uma conexão de serviço vinculado. Escolha ODBC como o armazenamento de dados:

Configure o serviço vinculado com o IR que você configurou nas etapas anteriores:
- Nome: forneça um nome para o serviço vinculado.
- Conectar via tempo de execução de integração: Selecione SelfhostedIR.
- Forneça credenciais com base em valores armazenados no Cofre da Chave do Azure.
- Selecione Testar conexão e, em seguida, selecione Criar.
Conclua as etapas a seguir para criar um conjunto de dados com ODBC como armazenamento de dados. Use o serviço vinculado que você criou anteriormente.
- Selecione a guia Autor .
- Selecione o botão +.
- Selecione Conjunto de dados.
- Crie um conjunto de dados para a
Green_Taxi_Trip_DataIntabela Teradata:
- Selecione ODBC como o armazenamento de dados e, em seguida, selecione Continuar.
- Nome: forneça um nome para o conjunto de dados.
- Serviço vinculado: selecione o serviço vinculado ODBC que você criou nas etapas anteriores.
- Nome da tabela: Selecione a tabela na lista.
- Selecione OK.
Gorjeta
Ao carregar os dados, use uma tabela de preparo com tipos de dados genéricos para evitar erros de incompatibilidade de tipo de dados. Por exemplo, em vez de usar o tipo de dados decimal para colunas, use Varchar. Em seguida, você pode executar transformações de tipo de dados no banco de dados Vantage.

Crie uma conexão de Blob do Azure com o arquivo de origem que você deseja carregar no Vantage seguindo as etapas 4 a 6 e a etapa 8 no primeiro cenário. Observe que você está estabelecendo essa conexão para o arquivo de origem, portanto, o caminho do arquivo será diferente.
Crie um pipeline que contenha uma atividade Copiar Dados, conforme descrito no cenário 1.
Arraste uma atividade Copiar dados para o pipeline.
Nota
Atualmente, o conector ODBC Teradata não suporta a atividade de fluxo de dados no Data Factory. Se você quiser executar a transformação nos dados, recomendamos que crie uma atividade de Fluxo de Dados antes da atividade Copiar Dados.
Configure a atividade Copiar dados:
Na guia Origem, selecione o conjunto de dados de arquivo que você deseja carregar no Teradata.
Use os valores padrão para as outras opções.

Na guia Coletor, em Conjunto de dados do coletor, selecione o conjunto de dados da tabela Teradata que você criou por meio da conexão ODBC.
Use os valores padrão para as outras opções.
Selecione Depurar. O pipeline copia os dados do arquivo Parquet para o Vantage.






Cenário 3: Acessar dados no armazenamento de Blob a partir do VantageCloud
Este cenário descreve como usar a funcionalidade Vantage Native Object Store (NOS) para acessar dados que estão no Armazenamento de Blob. O cenário anterior é ideal quando você deseja carregar dados no Vantage de forma contínua ou programada. Este cenário descreve como acessar dados de uma maneira única a partir do Armazenamento de Blobs, com ou sem carregar os dados no Vantage.
Nota
Também pode utilizar o NOS para exportar dados para o Armazenamento de Blobs.
Você pode usar a consulta a seguir para ler, a partir do Vantage, dados que foram transformados e carregados no Armazenamento de Blobs via Data Factory, sem carregar os dados no Vantage. Você pode usar o Teradata SQL Editor para executar consultas. Para acessar os dados que estão no blob, forneça o nome da conta de armazenamento e a chave de acesso nos
Access_IDcampos eAccess_Key. A consulta também retorna um campo chamadoLocationque especifica o caminho do arquivo do qual o registro foi lido.FROM ( LOCATION='/AZ/yourstorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi/' AUTHORIZATION='{"ACCESS_ID":"yourstorageaccountname","ACCESS_KEY":"yourstorageaccesskey"}' ) as GreenTaxiData;
Aqui está outro exemplo de consulta de dados no local. Ele usa o
READ_NOSoperador de tabela.
Você também pode consultar dados no local ou carregar dados em um banco de dados Vantage criando uma tabela estrangeira no repositório de objetos. Primeiro, você precisa criar um objeto de autorização que use o nome da conta de armazenamento e a chave de acesso em
USERePASSWORDcampos, respectivamente, conforme mostrado na sintaxe a seguir. Você pode usar esse objeto para criar sua tabela estrangeira para que não precise fornecer as chaves ao criar a tabela.USER 'YOUR-STORAGE-ACCOUNT-NAME' PASSWORD 'YOUR-ACCESS-KEY';Agora você pode criar a tabela estrangeira para acessar os dados. A consulta a seguir cria a tabela para os dados do Táxi Verde. Ele usa o objeto de autorização.
Nota
Ao carregar o arquivo Parquet, certifique-se de mapear os tipos de dados corretamente. Para obter ajuda com a correspondência dos tipos de dados, você pode usar o comando READ_NOS para visualizar o esquema do Parquet.
Create Foreign Table NYCTaxiADFIntegration.GreenTaxiForeignTable , External security definer trusted DefAuth3 ( VendorID INT, lpep_pickup_datetime TIMESTAMP, lpep_dropoff_datetime TIMESTAMP, store_and_fwd_flag VARCHAR(40) CHARACTER SET UNICODE CASESPECIFIC, RatecodeID INT, PULocationID INT, DOLocationID INT, passenger_count INT, trip_distance FLOAT, fare_amount FLOAT, extra DECIMAL(38,18), mta_tax DECIMAL(38,18), tip_amount FLOAT, tolls_amount DECIMAL(38,18), ehail_fee INT, improvement_surcharge DECIMAL(38,18), total_amount DECIMAL(38,18), payment_type INT, trip_type INT, congestion_surcharge DECIMAL(38,18) ) USING ( LOCATION('/AZ/adfvantagestorageaccount.blob.core.windows.net/vantageadfdatain/NYCGreenTaxi') STOREDAS ('PARQUET')) NO PRIMARY INDEX , PARTITION BY COLUMN;Agora você pode consultar os dados da tabela estrangeira da mesma forma que pode consultar qualquer outra tabela:
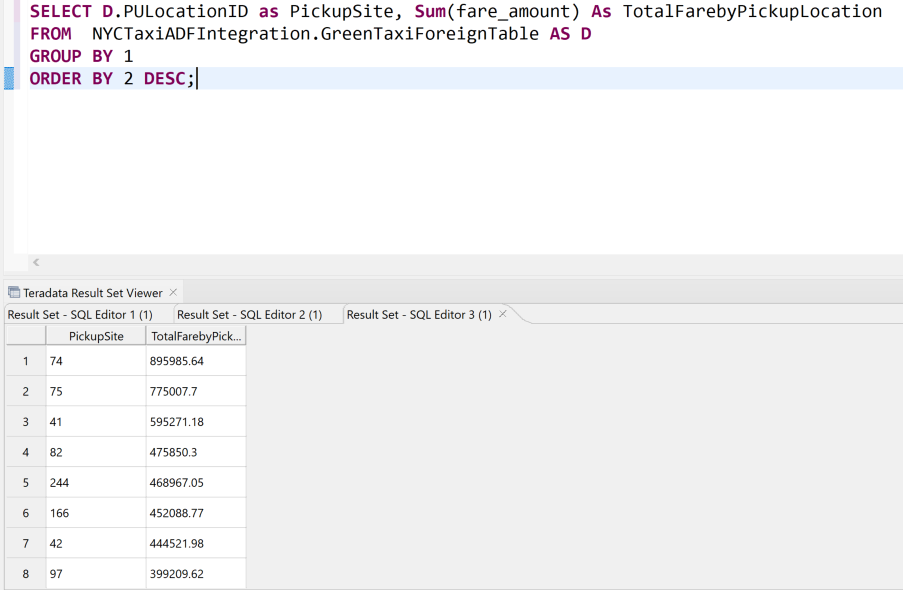
Você viu como consultar dados no armazenamento de objetos no local. No entanto, talvez você queira carregar os dados permanentemente em uma tabela no banco de dados para melhorar o desempenho da consulta. Você pode carregar dados do Armazenamento de Blob em uma tabela permanente usando as instruções a seguir. Algumas opções podem funcionar apenas para determinados formatos de arquivo de dados. Para obter detalhes, consulte a documentação do Teradata. Para obter código de exemplo, consulte Carregando dados externos em um banco de dados.
Método Description CRIAR TABELA COMO... COM DADOS Acessa definições de tabela e dados de uma tabela estrangeira existente e cria uma nova tabela permanente no banco de dados CRIAR TABELA COMO... DA READ_NOS Acessa dados diretamente do repositório de objetos e cria uma tabela permanente no banco de dados INSERIR SELECIONAR Armazena valores de dados externos em uma tabela de banco de dados persistente Os exemplos a seguir mostram como criar uma tabela permanente a partir de
GreenTaxiData:CREATE Multiset table NYCTaxiADFIntegration.GreenTaxiNosPermanent As ( SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1 ) with Data No Primary Index;INSERT INTO NYCTaxiADFIntegration.GreenTaxiNosPermanent SELECT D.PULocationID as PickupSite, Sum(fare_amount) AS TotalFarebyPickuploation FROM NYCTaxiADFIntegration.GreenTaxiForeignTable AS D GROUP BY 1;



Melhores práticas
- Siga as dicas de desempenho do conector e as práticas recomendadas descritas no Teradata como origem.
- Certifique-se de que o IR auto-hospedado está dimensionado corretamente para o seu volume de dados. Você pode querer dimensionar o RI para obter um melhor desempenho. Para obter mais informações, consulte este guia de desempenho de RI auto-hospedado.
- Use o guia Copiar desempenho e escalabilidade da atividade para ajustar os pipelines do Data Factory para desempenho.
- Use a ferramenta Data Factory Copy Data para configurar rapidamente um pipeline e executá-lo de acordo com uma programação.
- Considere usar uma VM do Azure com um IR auto-hospedado para gerenciar o custo de execução de pipelines. Se quiser executar pipelines duas vezes por dia, inicie a VM duas vezes e, em seguida, desligue-a.
- Considere o uso de CI/CD no Data Factory para implementar práticas de integração e desenvolvimento contínuos habilitados para Git.
- Otimize a contagem de atividades do seu pipeline. Atividades desnecessárias aumentam os custos e tornam os oleodutos complexos.
- Considere o uso de fluxos de dados de mapeamento para transformar dados do Armazenamento de Blob visualmente com processos no-code e low-code para preparar dados Vantage para usos como relatórios do Power BI.
- Além de usar gatilhos de agenda, considere usar uma combinação de janela de tombamento e gatilhos de evento para carregar dados do Vantage nos locais de destino. Reduza gatilhos desnecessários para reduzir custos.
- Use o Vantage NOS para consultas ad hoc para fornecer facilmente dados para aplicativos upstream.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Sunil Sabat - Brasil | Gerente de Programa Principal
- Divyesh Sah - Brasil | Diretor WW Cloud Architecture
- Jianlei Shen - Brasil | Gerente de Programa Sênior
Outros contribuidores:
- Mick Alberts - Brasil | Redator Técnico
- Emily Chen - Brasil | Gestor Principal PM
- Wee Hyong Tok - Brasil | Diretor Sócio PM
- Bunty Ranu - Brasil | Diretor Sênior, Worldwide Cloud Architecture
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- Teradata Vantage no Azure
- Ferramentas e utilitários Teradata 17.20
- Data Factory
- Emparelhamento de rede virtual do Azure
- Serviço de Link Privado
- Conector Teradata Data Factory
- IR auto-hospedado
- Documentação do Blob Storage