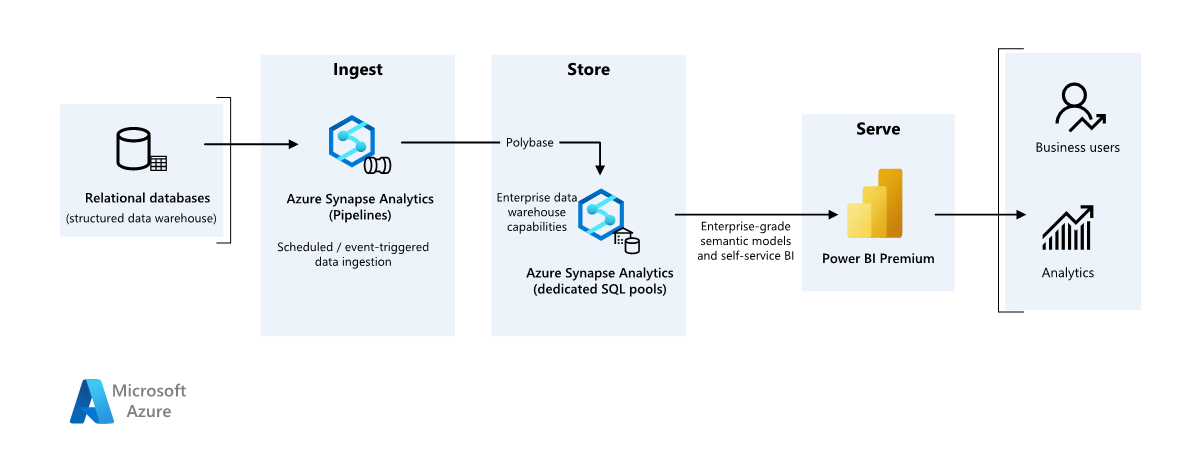
Este cenário de exemplo mostra como os dados podem ser ingeridos em um ambiente de nuvem a partir de um data warehouse local e, em seguida, servidos usando um modelo de business intelligence (BI). Essa abordagem pode ser um objetivo final ou um primeiro passo para a modernização completa com componentes baseados em nuvem.
As etapas a seguir se baseiam no cenário de ponta a ponta do Azure Synapse Analytics. Ele usa o Azure Pipelines para ingerir dados de um banco de dados SQL em pools SQL do Azure Synapse e, em seguida, transforma os dados para análise.
Arquitetura

Transfira um ficheiro do Visio desta arquitetura.
Fluxo de Trabalho
Data source
- Os dados de origem estão localizados em um banco de dados do SQL Server no Azure. Para simular o ambiente local, os scripts de implantação para este cenário provisionam um banco de dados SQL do Azure. O banco de dados de exemplo AdventureWorks é usado como o esquema de dados de origem e dados de exemplo. Para obter informações sobre como copiar dados de um banco de dados local, consulte Copiar e transformar dados de e para o SQL Server.
Ingestão e armazenamento de dados
O Azure Data Lake Gen2 é usado como uma área de preparo temporária durante a ingestão de dados. Em seguida, você pode usar o PolyBase para copiar dados em um pool SQL dedicado do Azure Synapse.
O Azure Synapse Analytics é um sistema distribuído projetado para executar análises em dados grandes. Suporta o processamento paralelo em massa (MPP), que faz com que este serviço seja adequado para executar análises de elevado desempenho. O pool SQL dedicado do Azure Synapse é um destino para ingestão contínua no local. Ele pode ser usado para processamento adicional, bem como servir os dados para o Power BI por meio do DirectQuery.
O Azure Pipelines é usado para orquestrar a ingestão e a transformação de dados em seu espaço de trabalho do Azure Synapse.
Análise e relatórios
- A abordagem de modelagem de dados neste cenário é apresentada combinando o modelo empresarial e o modelo semântico de BI. O modelo empresarial é armazenado em um pool SQL dedicado do Azure Synapse e o modelo semântico de BI é armazenado nas capacidades do Power BI Premium. O Power BI acessa os dados via DirectQuery.
Componentes
Este cenário usa os seguintes componentes:
- Base de Dados SQL do Azure
- Azure Data Lake
- Azure Synapse Analytics
- Power BI Premium
- Microsoft Entra ID
Arquitetura simplificada
Detalhes do cenário
Uma organização tem um grande data warehouse local armazenado em um banco de dados SQL. A organização deseja usar o Azure Synapse para executar análises e, em seguida, fornecer essas informações usando o Power BI.
Autenticação
O Microsoft Entra autentica usuários que se conectam a painéis e aplicativos do Power BI. O logon único é usado para se conectar à fonte de dados no pool provisionado do Azure Synapse. A autorização acontece na fonte.
Carregamento incremental
Quando você executa um processo automatizado de extração, transformação, carregamento (ETL) ou extração, carregamento, transformação (ELT), é mais eficiente carregar apenas os dados que foram alterados desde a execução anterior. É chamada de carga incremental, em oposição a uma carga completa que carrega todos os dados. Para executar uma carga incremental, você precisa de uma maneira de identificar quais dados foram alterados. A abordagem mais comum é usar um valor de marca d'água alto, que rastreia o valor mais recente de alguma coluna na tabela de origem, seja uma coluna datetime ou uma coluna inteira exclusiva.
A partir do SQL Server 2016, você pode usar tabelas temporais, que são tabelas com versão do sistema que mantêm um histórico completo de alterações de dados. O mecanismo de banco de dados registra automaticamente o histórico de cada alteração em uma tabela de histórico separada. Você pode consultar os dados históricos adicionando uma FOR SYSTEM_TIME cláusula a uma consulta. Internamente, o mecanismo de banco de dados consulta a tabela de histórico, mas é transparente para o aplicativo.
Nota
Para versões anteriores do SQL Server, você pode usar a captura de dados de alteração (CDC). Essa abordagem é menos conveniente do que as tabelas temporais, porque você precisa consultar uma tabela de alterações separada e as alterações são controladas por um número de sequência de log, em vez de um carimbo de data/hora.
As tabelas temporais são úteis para dados de dimensão, que podem mudar ao longo do tempo. As tabelas de fatos geralmente representam uma transação imutável, como uma venda, caso em que manter o histórico de versões do sistema não faz sentido. Em vez disso, as transações geralmente têm uma coluna que representa a data da transação, que pode ser usada como o valor da marca d'água. Por exemplo, no AdventureWorks Data Warehouse, as SalesLT.* tabelas têm um LastModified campo.
Aqui está o fluxo geral para o pipeline ELT:
Para cada tabela no banco de dados de origem, controle o tempo de corte quando o último trabalho ELT foi executado. Armazene essas informações no data warehouse. Na configuração inicial, todos os horários são definidos como
1-1-1900.Durante a etapa de exportação de dados, o tempo de corte é passado como um parâmetro para um conjunto de procedimentos armazenados no banco de dados de origem. Esses procedimentos armazenados consultam todos os registros que foram alterados ou criados após o tempo de corte. Para todas as tabelas no exemplo, você pode usar a
ModifiedDatecoluna.Quando a migração de dados estiver concluída, atualize a tabela que armazena os tempos de corte.
Pipeline de dados
Este cenário usa o banco de dados de exemplo AdventureWorks como uma fonte de dados. O padrão de carga de dados incremental é implementado para garantir que carregamos apenas os dados que foram modificados ou adicionados após a execução do pipeline mais recente.
Ferramenta de cópia orientada por metadados
A ferramenta de cópia controlada por metadados interna no Azure Pipelines carrega incrementalmente todas as tabelas contidas em nosso banco de dados relacional. Ao navegar pela experiência baseada em assistente, você pode conectar a ferramenta Copiar Dados ao banco de dados de origem e configurar o carregamento incremental ou completo para cada tabela. Em seguida, a ferramenta Copiar Dados cria os pipelines e scripts SQL para gerar a tabela de controle necessária para armazenar dados para o processo de carregamento incremental — por exemplo, o valor/coluna de marca d'água alto para cada tabela. Depois que esses scripts forem executados, o pipeline estará pronto para carregar todas as tabelas no data warehouse de origem no pool dedicado do Synapse.
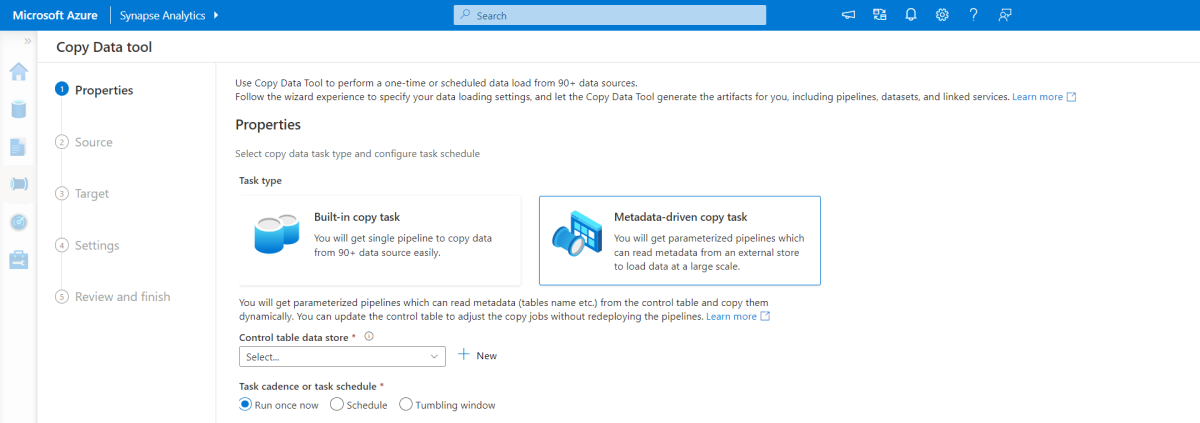
A ferramenta cria três pipelines para iterar em todas as tabelas no banco de dados, antes de carregar os dados.
Os pipelines gerados por esta ferramenta:
- Conte o número de objetos, como tabelas, a serem copiados na execução do pipeline.
- Itere sobre cada objeto a ser carregado/copiado e, em seguida:
- Verificar se é necessária uma carga delta; caso contrário, completar uma carga completa normal.
- Recupere o alto valor da marca d'água da tabela de controle.
- Copie dados das tabelas de origem para a conta de preparo no Data Lake Storage Gen2.
- Carregue dados no pool SQL dedicado por meio do método de cópia selecionado — por exemplo, PolyBase, comando Copy.
- Atualize o alto valor da marca d'água na tabela de controle.
Carregar dados no pool SQL do Azure Synapse
A atividade de cópia copia dados do banco de dados SQL para o pool SQL do Azure Synapse. Neste exemplo, como nosso banco de dados SQL está no Azure, usamos o tempo de execução de integração do Azure para ler dados do banco de dados SQL e gravar os dados no ambiente de preparo especificado.
A instrução copy é então usada para carregar dados do ambiente de preparo no pool dedicado Synapse.
Utilizar Pipelines do Azure
Os pipelines no Azure Synapse são usados para definir o conjunto ordenado de atividades para concluir o padrão de carga incremental. Os gatilhos são usados para iniciar o pipeline, que pode ser acionado manualmente ou em um horário especificado.
Transformar os dados
Como o banco de dados de exemplo em nossa arquitetura de referência não é grande, criamos tabelas replicadas sem partições. Para cargas de trabalho de produção, o uso de tabelas distribuídas provavelmente melhorará o desempenho da consulta. Para obter mais informações, consulte Orientação para projetar tabelas distribuídas no Azure Synapse. Os scripts de exemplo executam as consultas usando uma classe de recurso estático.
Em um ambiente de produção, considere a criação de tabelas de preparo com distribuição round-robin. Em seguida, transforme e mova os dados para tabelas de produção com índices columnstore clusterizados, que oferecem o melhor desempenho geral de consulta. Os índices Columnstore são otimizados para consultas que verificam muitos registros. Os índices Columnstore não funcionam tão bem para pesquisas singleton, ou seja, procurando uma única linha. Se você precisar executar pesquisas singleton frequentes, poderá adicionar um índice não clusterizado a uma tabela. As pesquisas singleton podem ser executadas muito mais rapidamente usando um índice não clusterizado. No entanto, pesquisas singleton são normalmente menos comuns em cenários de data warehouse do que cargas de trabalho OLTP. Para obter mais informações, consulte Tabelas de indexação no Azure Synapse.
Nota
As tabelas columnstore clusterizadas não suportam varchar(max), nvarchar(max)nem varbinary(max) tipos de dados. Nesse caso, considere um heap ou índice clusterizado. Você pode colocar essas colunas em uma tabela separada.
Usar o Power BI Premium para acessar, modelar e visualizar dados
O Power BI Premium dá suporte a várias opções para se conectar a fontes de dados no Azure, em particular o pool provisionado do Azure Synapse:
- Importar: os dados são importados para o modelo do Power BI.
- DirectQuery: Os dados são extraídos diretamente do armazenamento relacional.
- Modelo composto: combine Import para algumas tabelas e DirectQuery para outras.
Esse cenário é fornecido com o painel do DirectQuery porque a quantidade de dados usados e a complexidade do modelo não são altas, para que possamos oferecer uma boa experiência ao usuário. O DirectQuery delega a consulta ao poderoso mecanismo de computação abaixo e utiliza amplos recursos de segurança na origem. Além disso, o uso do DirectQuery garante que os resultados sejam sempre consistentes com os dados de origem mais recentes.
O modo de importação fornece o tempo de resposta de consulta mais rápido e deve ser considerado quando o modelo cabe inteiramente na memória do Power BI, a latência de dados entre atualizações pode ser tolerada e pode haver algumas transformações complexas entre o sistema de origem e o modelo final. Nesse caso, os usuários finais querem acesso total aos dados mais recentes sem atrasos na atualização do Power BI e a todos os dados históricos, que são maiores do que o que um conjunto de dados do Power BI pode lidar — entre 25 e 400 GB, dependendo do tamanho da capacidade. Como o modelo de dados no pool SQL dedicado já está em um esquema em estrela e não precisa de transformação, o DirectQuery é uma escolha apropriada.
O Power BI Premium Gen2 oferece a capacidade de lidar com modelos grandes, relatórios paginados, pipelines de implantação e ponto de extremidade interno do Analysis Services. Você também pode ter capacidade dedicada com proposta de valor única.
Quando o modelo de BI cresce ou a complexidade do painel aumenta, você pode alternar para modelos compostos e começar a importar partes de tabelas de pesquisa, por meio de tabelas híbridas e alguns dados pré-agregados. Habilitar o cache de consulta no Power BI para conjuntos de dados importados é uma opção, bem como utilizar tabelas duplas para a propriedade do modo de armazenamento.
Dentro do modelo composto, os conjuntos de dados atuam como uma camada de passagem virtual. Quando o usuário interage com visualizações, o Power BI gera consultas SQL para Synapse SQL pools armazenamento duplo: na memória ou consulta direta, dependendo de qual é mais eficiente. O mecanismo decide quando alternar de consulta na memória para consulta direta e envia a lógica para o pool Synapse SQL. Dependendo do contexto das tabelas de consulta, elas podem atuar como modelos compostos armazenados em cache (importados) ou não armazenados em cache. Escolha qual tabela armazenar em cache na memória, combine dados de uma ou mais fontes DirectQuery e/ou combine dados de uma combinação de fontes DirectQuery e dados importados.
Recomendações: Ao usar o DirectQuery no pool provisionado do Azure Synapse Analytics:
- Use o cache do conjunto de resultados do Azure Synapse para armazenar em cache os resultados da consulta no banco de dados do usuário para uso repetitivo, melhorar o desempenho da consulta até milissegundos e reduzir o uso de recursos de computação. As consultas que usam conjuntos de resultados armazenados em cache não usam nenhum slot de simultaneidade no Azure Synapse Analytics e, portanto, não contam para os limites de simultaneidade existentes.
- Use as exibições materializadas do Azure Synapse para pré-calcular, armazenar e manter dados como uma tabela. As consultas que usam todos ou um subconjunto dos dados em exibições materializadas podem obter um desempenho mais rápido e não precisam fazer uma referência direta à exibição materializada definida para usá-la.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Segurança
A segurança oferece garantias contra ataques deliberados e o abuso de seus valiosos dados e sistemas. Para obter mais informações, consulte Visão geral do pilar de segurança.
Violações de dados, infeções por malware e injeção de código malicioso fazem muitas vezes as manchetes e estão na extensa lista de preocupações de segurança das empresas que pretendem modernizar a cloud. Os clientes corporativos precisam de um provedor de nuvem ou solução de serviço que possa resolver suas preocupações, pois não podem se dar ao luxo de errar.
Este cenário aborda as preocupações de segurança mais exigentes usando uma combinação de controles de segurança em camadas: rede, identidade, privacidade e autorização. A maior parte dos dados é armazenada no pool provisionado do Azure Synapse, com o Power BI usando o DirectQuery por meio do logon único. Você pode usar o Microsoft Entra ID para autenticação. Há também controles de segurança abrangentes para autorização de dados de pools provisionados.
Algumas questões de segurança comuns incluem:
- Como posso controlar quem pode ver que dados?
- As organizações precisam proteger seus dados para cumprir as diretrizes federais, locais e da empresa para mitigar os riscos de violação de dados. O Azure Synapse oferece vários recursos de proteção de dados para alcançar a conformidade.
- Quais são as opções para verificar a identidade de um utilizador?
- O Azure Synapse dá suporte a uma ampla gama de recursos para controlar quem pode acessar quais dados por meio de controle de acesso e autenticação.
- Que tecnologia de segurança de rede posso utilizar para proteger a integridade, a confidencialidade e o acesso das minhas redes e dos meus dados?
- Para proteger o Azure Synapse, há uma variedade de opções de segurança de rede disponíveis para considerar.
- Quais são as ferramentas que detetam e me notificam de ameaças?
- O Azure Synapse fornece muitos recursos de deteção de ameaças, como: auditoria SQL, deteção de ameaças SQL e avaliação de vulnerabilidades para auditar, proteger e monitorar bancos de dados.
- O que posso fazer para proteger os dados na minha conta de armazenamento?
- As contas de Armazenamento do Azure são ideais para cargas de trabalho que exigem tempos de resposta rápidos e consistentes ou que têm um alto número de operações de entrada-saída (IOP) por segundo. As contas de armazenamento contêm todos os seus objetos de dados do Armazenamento do Azure e têm muitas opções para a segurança da conta de armazenamento.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Esta seção fornece informações sobre preços para diferentes serviços envolvidos nessa solução e menciona as decisões tomadas para esse cenário com um conjunto de dados de exemplo.
Azure Synapse
A arquitetura sem servidor do Azure Synapse Analytics permite dimensionar seus níveis de computação e armazenamento de forma independente. Os recursos de computação são cobrados com base no uso, e você pode dimensionar ou pausar esses recursos sob demanda. Os recursos de armazenamento são cobrados por terabyte, portanto, seus custos aumentarão à medida que você ingerir mais dados.
Azure Pipelines
Os detalhes de preços para pipelines no Azure Synapse podem ser encontrados na guia Integração de Dados na página de preços do Azure Synapse. Existem três componentes principais que influenciam o preço de um gasoduto:
- Atividades de pipeline de dados e horas de tempo de execução de integração
- Tamanho e execução do cluster de fluxos de dados
- Nos custos de operações
O preço varia dependendo dos componentes ou atividades, frequência e número de unidades de tempo de execução de integração.
Para o conjunto de dados de exemplo, o tempo de execução de integração padrão hospedado no Azure, atividade de cópia de dados para o núcleo do pipeline, é acionado em uma programação diária para todas as entidades (tabelas) no banco de dados de origem. O cenário não contém fluxos de dados. Não há custos operacionais, uma vez que há menos de 1 milhão de operações com gasodutos por mês.
Pool dedicado e armazenamento do Azure Synapse
Os detalhes de preços do pool dedicado do Azure Synapse podem ser encontrados na guia Data Warehousing na página de preços do Azure Synapse. No modelo de consumo dedicado, os clientes são cobrados por unidade de armazém de dados (DWU) unidades provisionadas, por hora de tempo de atividade. Outro fator que contribui para isso são os custos de armazenamento de dados: tamanho dos dados em repouso + snapshots + redundância geográfica, se houver.
Para o conjunto de dados de exemplo, você pode provisionar 500DWU, o que garante uma boa experiência para carga analítica. Você pode manter a computação em funcionamento durante o horário comercial de relatórios. Se levada para a produção, a capacidade reservada do data warehouse é uma opção atraente para o gerenciamento de custos. Diferentes técnicas devem ser usadas para maximizar as métricas de custo/desempenho, que são abordadas nas seções anteriores.
Armazenamento de Blobs
Considere usar o recurso de capacidade reservada do Armazenamento do Azure para reduzir os custos de armazenamento. Com este modelo, você obtém um desconto se reservar capacidade fixa de armazenamento por um ou três anos. Para obter mais informações, consulte Otimizar custos para armazenamento de Blob com capacidade reservada.
Não há armazenamento persistente nesse cenário.
Power BI Premium
Os detalhes de preços do Power BI Premium podem ser encontrados na página de preços do Power BI.
Este cenário usa espaços de trabalho do Power BI Premium com uma variedade de aprimoramentos de desempenho incorporados para acomodar necessidades analíticas exigentes .
Excelência operacional
A excelência operacional abrange os processos operacionais que implantam um aplicativo e o mantêm em execução na produção. Para obter mais informações, consulte Visão geral do pilar de excelência operacional.
Recomendações de DevOps
Crie grupos de recursos separados para ambientes de produção, desenvolvimento e teste. A utilização de grupos de recursos separados torna mais fácil gerir as implementações, eliminar as implementações de teste e atribuir direitos de acesso.
Coloque cada carga de trabalho em um modelo de implantação separado e armazene os recursos em sistemas de controle do código-fonte. Você pode implantar os modelos juntos ou individualmente como parte de um processo de integração contínua e entrega contínua (CI/CD), facilitando o processo de automação. Nessa arquitetura, há quatro cargas de trabalho principais:
- O servidor de armazém de dados e recursos relacionados
- Pipelines do Azure Synapse
- Ativos do Power BI: dashboards, aplicações, conjuntos de dados
- Um cenário simulado no local para a nuvem
Procure ter um modelo de implantação separado para cada uma das cargas de trabalho.
Considere preparar suas cargas de trabalho onde for prático. Implante em vários estágios e execute verificações de validação em cada estágio antes de passar para o próximo estágio. Dessa forma, você pode enviar atualizações para seus ambientes de produção de forma controlada e minimizar problemas de implantação imprevistos. Use estratégias de implantação azul-verde e liberação canária para atualizar ambientes de produção ao vivo.
Tenha uma boa estratégia de reversão para lidar com implantações com falha. Por exemplo, você pode reimplantar automaticamente uma implantação anterior bem-sucedida a partir do seu histórico de implantação. Consulte o
--rollback-on-errorsinalizador na CLI do Azure.O Azure Monitor é a opção recomendada para analisar o desempenho do seu armazém de dados e de toda a plataforma de análise do Azure para uma experiência de monitorização integrada. O Azure Synapse Analytics fornece uma experiência de monitoramento no portal do Azure para mostrar informações sobre sua carga de trabalho de data warehouse. O portal do Azure é a ferramenta recomendada ao monitorar seu data warehouse porque fornece períodos de retenção configuráveis, alertas, recomendações e gráficos e painéis personalizáveis para métricas e logs.
Início rápido
- Portal: Prova de conceito (POC) do Azure Synapse
- A CLI do Azure: Criar um espaço de trabalho do Azure Synapse com a CLI do Azure
- Terraform: Armazenamento de dados moderno com Terraform e Microsoft Azure
Eficiência de desempenho
Eficiência de desempenho é a capacidade da sua carga de trabalho para dimensionar para satisfazer as exigências que os utilizadores lhe colocam de forma eficiente. Para obter mais informações, consulte Visão geral do pilar de eficiência de desempenho.
Esta seção fornece detalhes sobre as decisões de dimensionamento para acomodar esse conjunto de dados.
Pool provisionado do Azure Synapse
Há uma variedade de configurações de data warehouse para escolher.
| Unidades do armazém de dados | # de nós de computação | # de distribuições por nó |
|---|---|---|
| DW100c | 1 | 60 |
-- TO -- |
||
| DW30000c | 60 | 1 |
Para ver os benefícios de desempenho da expansão, especialmente para unidades de data warehouse maiores, use pelo menos um conjunto de dados de 1 TB. Para encontrar o melhor número de unidades de data warehouse para seu pool SQL dedicado, tente dimensionar para cima e para baixo. Execute algumas consultas com números diferentes de unidades de armazém de dados depois de carregar os dados. Como o dimensionamento é rápido, você pode tentar vários níveis de desempenho em uma hora ou menos.
Encontre o melhor número de unidades de armazém de dados
Para um pool SQL dedicado em desenvolvimento, comece selecionando um número menor de unidades de data warehouse. Um bom ponto de partida é DW400c ou DW200c. Monitore o desempenho do seu aplicativo, observando o número de unidades de data warehouse selecionadas em comparação com o desempenho observado. Suponha uma escala linear e determine quanto você precisa aumentar ou diminuir as unidades de data warehouse. Continue fazendo ajustes até atingir um nível de desempenho ideal para seus requisitos de negócios.
Dimensionamento do pool SQL Synapse
- Dimensionar a computação para o pool SQL Synapse com o portal do Azure
- Dimensione a computação para pool SQL dedicado com o Azure PowerShell
- Dimensionar computação para pool SQL dedicado no Azure Synapse Analytics usando T-SQL
- Pausa, monitoramento e automação
Azure Pipelines
Para obter recursos de escalabilidade e otimização de desempenho de pipelines no Azure Synapse e a atividade de cópia usada, consulte o Guia de desempenho e escalabilidade da atividade de cópia.
Power BI Premium
Este artigo usa o Power BI Premium Gen 2 para demonstrar os recursos de BI. Os SKUs de capacidade para o Power BI Premium variam de P1 (oito v-cores) a P5 (128 v-cores) atualmente. A melhor maneira de selecionar a capacidade necessária é passar por uma avaliação de carga de capacidade, instalar o aplicativo de métricas Gen 2 para monitoramento contínuo e considerar o uso do Autoscale com o Power BI Premium.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Principais autores:
- Galina Polyakova - Brasil | Arquiteto de Soluções Cloud Sênior
- Noah Costar - Brasil | Arquiteto de Soluções Cloud
- George Stevens - Brasil | Arquiteto de Soluções Cloud
Outros contribuidores:
- Jim McLeod - Brasil | Arquiteto de Soluções Cloud
- Miguel Myers - Portugal | Gerente de Programa Sênior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- O que é o Power BI Premium?
- O que é o Microsoft Entra ID?
- Aceder ao Azure Data Lake Storage Gen2 e ao Armazenamento de Blobs com o Azure Databricks
- O que é o Azure Synapse Analytics?
- Pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics
- O que é o Azure SQL?