Para verificar se os aplicativos e serviços estão funcionando corretamente, você pode usar o padrão Health Endpoint Monitoring. Esse padrão especifica o uso de verificações funcionais em um aplicativo. Ferramentas externas podem acessar essas verificações em intervalos regulares por meio de pontos de extremidade expostos.
Contexto e problema
É uma boa prática monitorar aplicativos Web e serviços back-end. O monitoramento ajuda a garantir que os aplicativos e serviços estejam disponíveis e funcionando corretamente. Os requisitos de negócios geralmente incluem monitoramento.
Às vezes, é mais difícil monitorar serviços em nuvem do que serviços locais. Uma razão é que você não tem controle total do ambiente de hospedagem. Outra é que os serviços normalmente dependem de outros serviços que os fornecedores de plataforma e outros fornecem.
Muitos fatores afetam os aplicativos hospedados na nuvem. Os exemplos incluem latência de rede, o desempenho e a disponibilidade dos sistemas de computação e armazenamento subjacentes e a largura de banda de rede entre eles. Um serviço pode falhar total ou parcialmente devido a qualquer um desses fatores. Para garantir um nível necessário de disponibilidade, você deve verificar em intervalos regulares se o serviço funciona corretamente. Seu contrato de nível de serviço (SLA) pode especificar o nível que você precisa cumprir.
Solução
Implemente o monitoramento de integridade enviando solicitações para um ponto de extremidade em seu aplicativo. O pedido deve efetuar as verificações necessárias e, em seguida, devolver uma indicação do seu estado.
Normalmente, uma monitorização do estado de funcionamento combina dois fatores:
- As verificações (se houver) que o aplicativo ou serviço executa em resposta à solicitação para o ponto de extremidade de verificação de integridade
- A análise dos resultados pela ferramenta ou estrutura que executa a verificação de integridade
O código de resposta indica o estado da aplicação. Opcionalmente, o código de resposta também fornece o status dos componentes e serviços que o aplicativo usa. A ferramenta ou estrutura de monitoramento executa a verificação de latência ou tempo de resposta.
A figura a seguir fornece uma visão geral do padrão.
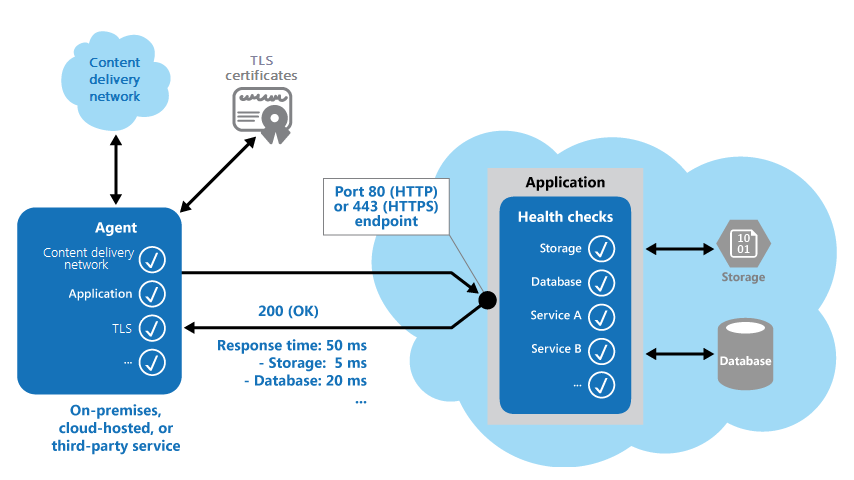
O código de monitoramento de integridade no aplicativo também pode executar outras verificações para determinar:
- A disponibilidade e o tempo de resposta do armazenamento em nuvem ou de um banco de dados.
- O status de outros recursos ou serviços que o aplicativo usa. Esses recursos e serviços podem estar no aplicativo ou fora dele.
Estão disponíveis serviços e ferramentas que monitorizam aplicações Web submetendo um pedido a um conjunto configurável de pontos de extremidade. Em seguida, esses serviços e ferramentas avaliam os resultados em relação a um conjunto de regras configuráveis. É relativamente fácil criar um ponto de extremidade de serviço com o único propósito de executar alguns testes funcionais em um sistema.
As verificações típicas que as ferramentas de monitoramento executam incluem:
- Validação do código de resposta. Por exemplo, uma resposta HTTP de 200 (OK) indica que a aplicação respondeu sem erros. O sistema de monitorização também pode procurar outros códigos de resposta para fornecer resultados mais abrangentes.
- Verificar o conteúdo da resposta para detetar erros, mesmo quando o código de status é 200 (OK). Ao verificar o conteúdo, você pode detetar erros que afetam apenas uma seção da página da Web retornada ou da resposta do serviço. Por exemplo, você pode verificar o título de uma página ou procurar uma frase específica que indique que o aplicativo retornou a página correta.
- Medição do tempo de resposta. O valor inclui a latência da rede e o tempo que o aplicativo levou para emitir a solicitação. Um valor crescente pode indicar um problema emergente na aplicação ou na rede.
- Verificar recursos ou serviços localizados fora do aplicativo. Um exemplo é uma rede de entrega de conteúdo que o aplicativo usa para fornecer conteúdo de caches globais.
- Verificação da expiração de certificados TLS.
- Medir o tempo de resposta de uma pesquisa de DNS para a URL do aplicativo. Esta verificação mede a latência do DNS e as falhas do DNS.
- Validando a URL retornada por uma pesquisa de DNS. Ao validar, você pode garantir que as entradas estejam corretas. Você também pode ajudar a evitar o redirecionamento de solicitação mal-intencionada que pode resultar após um ataque ao seu servidor DNS.
Sempre que possível, também é útil executar essas verificações a partir de diferentes locais locais ou hospedados e, em seguida, comparar os tempos de resposta. Idealmente, você deve monitorar aplicativos de locais próximos aos clientes. Em seguida, você obtém uma visão precisa do desempenho de cada local. Esta prática proporciona um mecanismo de controlo mais sólido. Os resultados também podem ajudá-lo a tomar as seguintes decisões:
- Onde implantar seu aplicativo
- Se deseja implantá-lo em mais de um datacenter
Para garantir que seu aplicativo funcione corretamente para todos os clientes, execute testes em todas as instâncias de serviço que os clientes usam. Por exemplo, se o armazenamento do cliente estiver distribuído por mais de uma conta de armazenamento, o processo de monitoramento deverá verificar cada conta.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
Pense em como validar a resposta. Por exemplo, determine se um código de status 200 (OK) é suficiente para verificar se o aplicativo está funcionando corretamente. Verificar o código de status é a implementação mínima desse padrão. Um código de status fornece uma medida básica da disponibilidade do aplicativo. Mas um código fornece poucas informações sobre as operações, tendências e possíveis problemas futuros no aplicativo.
Determine o número de pontos de extremidade a serem expostos para um aplicativo. Uma abordagem é expor pelo menos um ponto de extremidade para os serviços principais que o aplicativo usa e outro para serviços de prioridade mais baixa. Com essa abordagem, você pode atribuir diferentes níveis de importância a cada resultado de monitoramento. Considere também expor pontos de extremidade extras. Você pode expor um para cada serviço principal para aumentar a granularidade do monitoramento. Por exemplo, uma verificação de integridade pode verificar o banco de dados, o armazenamento e um serviço de geocodificação externo usado por um aplicativo. Cada um pode exigir um nível diferente de tempo de atividade e tempo de resposta. O serviço de geocodificação ou alguma outra tarefa em segundo plano pode ficar indisponível por alguns minutos. Mas o aplicativo ainda pode ser saudável.
Decida se deseja usar o mesmo ponto de extremidade para monitoramento e acesso geral. Você pode usar o mesmo ponto de extremidade para ambos, mas projetar um caminho específico para verificações de integridade. Por exemplo, você pode usar /health no ponto de extremidade de acesso geral. Com essa abordagem, as ferramentas de monitoramento podem executar alguns testes funcionais no aplicativo. Os exemplos incluem registrar um novo usuário, entrar e fazer um pedido de teste. Ao mesmo tempo, você também pode verificar se o ponto de extremidade de acesso geral está disponível.
Determine o tipo de informação a ser coletada no serviço em resposta às solicitações de monitoramento. Você também precisa determinar como retornar essas informações. A maioria das ferramentas e estruturas existentes procura apenas o código de estado HTTP que o ponto final devolve. Para regressar e validar informações adicionais, pode ter de criar um serviço ou utilitário de monitorização personalizado.
Descubra a quantidade de informações a recolher. Executar processamento excessivo durante a verificação pode sobrecarregar o aplicativo e afetar outros usuários. O tempo de processamento também pode exceder o tempo limite do sistema de monitoramento. Como resultado, o sistema pode marcar o aplicativo como indisponível. A maioria dos aplicativos inclui instrumentação, como manipuladores de erros e contadores de desempenho. Essas ferramentas podem registrar o desempenho e informações detalhadas de erro, que podem ser suficientes. Considere usar esses dados em vez de retornar informações adicionais de uma verificação de integridade.
Considere armazenar em cache o status do ponto final. Executar a verificação de integridade com frequência pode ser caro. Por exemplo, se o status de integridade for relatado por meio de um painel, você não deseja que todas as solicitações ao painel acionem uma verificação de integridade. Em vez disso, verifique periodicamente a integridade do sistema e armazene em cache o status. Expõe um ponto final que devolve o estado em cache.
Planeje como configurar a segurança para os pontos de extremidade de monitoramento. Ao configurar a segurança, você pode ajudar a proteger os pontos de extremidade do acesso público, o que pode:
- Exponha o aplicativo a ataques mal-intencionados.
- Arriscar a exposição de informações sensíveis.
- Atraia ataques de negação de serviço (DoS).
Normalmente, você configura a segurança na configuração do aplicativo. Em seguida, você pode atualizar as configurações facilmente sem reiniciar o aplicativo. Considere a utilização de uma ou mais das técnicas seguintes:
Proteja o ponto final ao solicitar autenticação. Se o serviço ou ferramenta de monitoramento oferecer suporte à autenticação, você poderá usar uma chave de segurança de autenticação no cabeçalho da solicitação. Você também pode passar credenciais com a solicitação. Ao usar a autenticação, considere como acessar seus pontos de extremidade de verificação de integridade. Como exemplo, o Serviço de Aplicativo do Azure tem uma verificação de integridade interna que se integra aos recursos de autenticação e autorização do Serviço de Aplicativo.
Utilize um ponto final obscuro ou oculto. Por exemplo, exponha o ponto de extremidade em um endereço IP diferente daquele que a URL do aplicativo padrão usa. Configure o ponto de extremidade em uma porta HTTP não padrão. Além disso, considere usar um caminho complexo para sua página de teste. Normalmente, você pode especificar endereços de ponto de extremidade e portas extras na configuração do aplicativo. Se necessário, você pode adicionar entradas para esses pontos de extremidade ao servidor DNS. Então você evita ter que especificar o endereço IP diretamente.
Exponha um método num ponto final que aceite um parâmetro tal como um valor-chave ou um valor do modo de operação. Quando uma solicitação chega, o código pode executar testes específicos que dependem do valor do parâmetro. O código pode retornar um erro 404 (Não encontrado) se não reconhecer o valor do parâmetro. Tornar possível definir valores de parâmetros na configuração do aplicativo.
Use um ponto de extremidade separado que execute testes funcionais básicos sem comprometer a operação do aplicativo. Com essa abordagem, você pode ajudar a reduzir o impacto de um ataque DoS. Idealmente, evite utilizar um teste que possa expor informações confidenciais. Às vezes, você deve retornar informações que podem ser úteis para um invasor. Nesse caso, considere como proteger o ponto de extremidade e os dados contra acesso não autorizado. Confiar na obscuridade não é suficiente. Considere também usar uma conexão HTTPS e criptografar dados confidenciais, embora essa abordagem aumente a carga no servidor.
Decida como garantir que o agente de monitoramento esteja funcionando corretamente. Uma abordagem é expor um ponto de extremidade que retorna um valor da configuração do aplicativo ou um valor aleatório que você pode usar para testar o agente. Certifique-se também de que o sistema de monitoramento realiza verificações em si mesmo. Você pode usar um autoteste ou um teste interno para evitar que o sistema de monitoramento emita resultados falsos positivos.
Quando utilizar este padrão
Este padrão é útil nas seguintes situações:
- Monitorizar sites e aplicações Web para verificar a disponibilidade.
- Monitorizar sites e aplicações Web para verificar a operação correta.
- Monitoramento de serviços compartilhados ou de camada intermediária para detetar e isolar falhas que possam interromper outros aplicativos.
- Complementar a instrumentação existente na aplicação, tal como contadores de desempenho e processadores de erros. A verificação de integridade não substitui os requisitos do aplicativo para registro em log e auditoria. A instrumentação pode fornecer informações valiosas para uma arquitetura existente que monitoriza contadores e registos de erros para detetar falhas ou outros problemas. Mas a instrumentação não pode fornecer informações se um aplicativo não estiver disponível.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Health Endpoint Monitoring pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Esses pontos de extremidade suportam os esforços de alerta e painel de confiabilidade de uma carga de trabalho. Eles também podem ser usados como um sinal para a remediação de auto-cura. - RE:07 Auto-cura e auto-preservação - RE:10 Estratégia de monitorização e alerta |
| A Excelência Operacional ajuda a fornecer qualidade de carga de trabalho por meio de processos padronizados e coesão da equipe. | Padronizar quais pontos de extremidade de integridade devem ser expostos e o nível de detalhe nos resultados em toda a sua carga de trabalho ajudará a triar problemas. - OE:07 Sistema de monitorização |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Os pontos de extremidade de integridade melhoram a lógica de balanceamento de carga roteando o tráfego apenas para nós que são verificados como íntegros. Com a configuração adicional, você também pode obter métricas sobre a capacidade disponível do nó. - PE:05 Dimensionamento e particionamento |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
Você pode usar o middleware e as bibliotecas de verificações de integridade ASP.NET para relatar a integridade dos componentes da infraestrutura do aplicativo. Esta estrutura fornece uma maneira de relatar verificações de integridade de forma consistente. Ele implementa muitas das práticas que este artigo descreve. Por exemplo, as verificações de integridade do ASP.NET incluem verificações externas, como conectividade de banco de dados, e conceitos específicos, como sondas de vivacidade e prontidão.
Vários exemplos de implementações que usam verificações de integridade ASP.NET estão disponíveis no GitHub.
Monitorar pontos de extremidade em aplicativos hospedados no Azure
As opções para monitorar pontos de extremidade em aplicativos do Azure incluem:
- Use os recursos internos de monitoramento do Azure, como o Azure Monitor.
- Use um serviço de terceiros ou uma estrutura como o Microsoft System Center Operations Manager.
- Crie um utilitário personalizado ou um serviço que seja executado em seu próprio servidor ou em um servidor hospedado.
Embora o Azure forneça opções de monitoramento abrangentes, você pode usar serviços e ferramentas adicionais para fornecer informações extras. O Application Insights, um recurso do Monitor, foi projetado para equipes de desenvolvimento. Esse recurso ajuda você a entender o desempenho do seu aplicativo e como ele é usado. O Application Insights monitora taxas de solicitação, tempos de resposta, taxas de falha e taxas de dependência. Pode ajudá-lo a determinar se os serviços externos estão a atrasá-lo.
As condições que você pode monitorar dependem do mecanismo de hospedagem que você escolher para o seu aplicativo. Todas as opções nesta seção suportam regras de alerta. Uma regra de alerta usa um ponto de extremidade da Web especificado nas configurações do seu serviço. Este ponto final deve responder de forma atempada, para que o sistema de alerta possa detetar que a aplicação está a funcionar corretamente. Para obter mais informações, consulte Criar uma nova regra de alerta.
Se houver uma grande interrupção, o tráfego do cliente deve ser roteável para uma implantação de aplicativo disponível em outras regiões ou zonas. Essa situação é um bom caso para conectividade entre locais e balanceamento de carga global. A escolha depende se o aplicativo é interno ou externo. Serviços como o Azure Front Door, o Azure Traffic Manager ou redes de entrega de conteúdo podem rotear o tráfego entre regiões com base nos dados fornecidos pelas sondas de integridade.
O Traffic Manager é um serviço de roteamento e balanceamento de carga. Ele pode usar uma variedade de regras e configurações para distribuir solicitações para instâncias específicas do seu aplicativo. Além de rotear solicitações, o Gerenciador de Tráfego pode executar regularmente ping em uma URL, porta e caminho relativo. Você especifica os destinos de ping com o objetivo de determinar quais instâncias do seu aplicativo estão ativas e respondendo a solicitações. Se o Gerenciador de Tráfego detetar um código de status de 200 (OK), ele marcará o aplicativo como disponível. Qualquer outro código de estado faz com que o Gestor de Tráfego marque a aplicação como offline. O console do Gerenciador de Tráfego exibe o status de cada aplicativo. Você pode configurar cada regra para redirecionar solicitações para outras instâncias do aplicativo que estão respondendo.
O Gestor de Tráfego aguarda um determinado período de tempo para receber uma resposta do URL de monitorização. Certifique-se de que o código de verificação de saúde é executado neste período. Permita a latência de rede para a viagem de ida e volta do Gerenciador de Tráfego para seu aplicativo e vice-versa.
Próximos passos
As orientações a seguir são úteis para implementar esse padrão:
- Diretrizes de monitoramento de integridade em aplicativos baseados em microsserviços
- Monitorando a integridade do aplicativo para confiabilidade, parte do Azure Well-Architected Framework
- Criar uma nova regra de alerta