Processe falhas que possam demorar um período de tempo de recuperação variável ao ligar a um serviço ou recurso remoto. Isto pode melhorar a estabilidade e resiliência de uma aplicação.
Contexto e problema
Num ambiente distribuído, as chamadas para serviços e recursos remotos podem falhar devido a falhas transitórias, como ligações de rede lentas, limites de tempo ou recursos sobrecarregados ou temporariamente disponíveis. Estas falhas costumam ser corrigidas de forma autónoma após um breve período de tempo, e uma aplicação na cloud robusta deve ser preparada para processá-las através de uma estratégia como o Padrão de repetição.
No entanto, pode também haver situações em que as falhas se devem a eventos imprevistos e podem demorar muito mais tempo a corrigir. Estas falhas podem variar em termos de gravidade, de uma perda parcial de conectividade à falha total de um serviço. Nestas situações, pode ser inútil para uma aplicação repetir continuamente uma operação com baixas probabilidades de ser bem-sucedida. Em vez disso, a aplicação deverá aceitar rapidamente que a operação falhou e processar esta falha adequadamente.
Adicionalmente, se um serviço estiver muito ocupado, a falha numa parte de um sistema poderá gerar falhas em cascata. Por exemplo, uma operação que invoque um serviço poderá ser configurada para implementar um limite de tempo e responder com uma mensagem de falha se o serviço não responder dentro deste período. No entanto, esta estratégia poderá fazer com que muitos pedidos em simultâneo para a mesma operação sejam bloqueados até que o limite de tempo expire. Estes pedidos bloqueados poderão conter recursos de sistema cruciais, como memória, threads, ligações de base de dados, etc. Consequentemente, estes recursos podem ficar esgotados, originando a falha de outras partes (possivelmente separadas) do sistema que precisam de utilizar os mesmos recursos. Nestas situações, é preferível que a operação falhe imediatamente e tente apenas invocar o serviço se tiver boas probabilidades de sucesso. Note que a definir um limite de tempo mais curto poderá ajudar a resolver o problema, mas o limite de tempo não deve ser tão curto que faça com que a operação falhe na maioria das vezes, mesmo que o pedido ao serviço acabe por ser bem-sucedido.
Solução
O padrão do Disjuntor Automático, popularizado por Michael Nygard, no seu livro Release It!, pode impedir uma aplicação de tentar repetidamente executar uma operação com boas probabilidades de falhar. Permitir que esta continue sem esperar que a falha seja corrigida ou desperdiçar ciclos de CPU enquanto determina que a falha é duradoura. O padrão do Disjuntor Automático também permite que uma aplicação detete se a falha foi resolvida. Se o problema aparentar estar resolvido, a aplicação pode tentar invocar a operação.
O objetivo do padrão do Disjuntor Automático é diferente do Padrão de repetição. O Padrão de repetição permite a uma aplicação repetir uma operação com a expectativa de que esta seja bem-sucedida. O padrão do Disjuntor Automático impede que uma aplicação efetue uma operação que é provável que falhe. Uma aplicação pode combinar estes dois padrões ao utilizar o padrão de Repetição para invocar uma operação através de um disjuntor automático. No entanto, a lógica de repetição deve ser sensível a eventuais exceções devolvidas pelo disjuntor automático e abandonar tentativas de repetição se o disjuntor automático indicar que uma falha não é transitória.
Um disjuntor automático atua como proxy para operações suscetíveis de falhar. O proxy deverá monitorizar o número de falhas recentes que ocorreram e utilizar esta informação para decidir se devem permitir que a operação continue ou simplesmente devolver uma exceção imediatamente.
O proxy pode ser implementado como computador com estado, tendo os seguintes estados que emulam a funcionalidade de um disjuntor automático elétrico:
Fechado: o pedido da aplicação é encaminhado para a operação. O proxy mantém uma contagem do número de falhas recentes e, se a chamada para a operação não for bem-sucedida, o proxy aumenta esta contagem. Se o número de falhas recentes exceder um limiar especificado num determinado período de tempo, o proxy é colocado em estado Aberto. Nesta altura, o proxy inicia um temporizador de limite de tempo e, quando o mesmo terminar, o proxy é colocado em estado Meio-aberto.
O objetivo do temporizador de limite de tempo é dar ao sistema algum tempo para corrigir o problema na origem da falha antes de permitir à aplicação que tente a operação novamente.
Aberto: o pedido da aplicação falha imediatamente e uma exceção é devolvida à aplicação.
Meio-aberto: um número limitado de pedidos da aplicação pode passar e invocar a operação. Se estes pedidos forem bem-sucedidos, assume-se que a falha que estava a causar o problema foi corrigida e o disjuntor automático muda para o estado Fechado (a contagem de falhas é reposta). Se alguma solicitação falhar, o disjuntor assume que a falha ainda está presente, então ele reverte para o estado Aberto e reinicia o temporizador de tempo limite para dar ao sistema um período adicional de tempo para se recuperar da falha.
O estado Meio-Aberto é útil para impedir um serviço de recuperação de ficar repentinamente sobrecarregado com pedidos. À medida que o serviço recupera, este poderá conseguir suportar um volume limitado de pedidos até a recuperação ser concluída, mas enquanto a recuperação se encontra em curso, uma sobrecarga de trabalho pode fazer com que o serviço exceda o tempo limite ou falhe novamente.
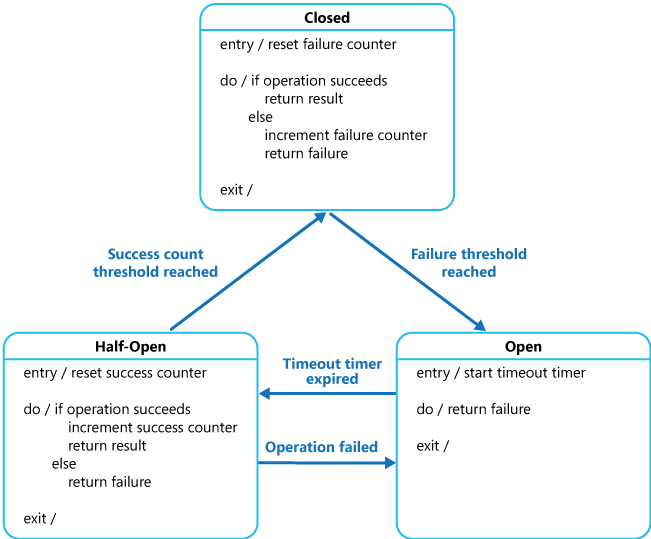
Na figura, o contador de falhas utilizado pelo estado Fechado é baseado em tempo. É automaticamente reiniciado em intervalos periódicos. Isto ajuda a impedir o disjuntor automático de entrar no estado Aberto se experienciar falhas ocasionais. O limiar de falha que coloca o disjuntor automático em estado Aberto só é alcançado após um número especificado de falhas ter ocorrido durante um intervalo especificado. O contador utilizado pelo estado Meio-Aberto regista o número de tentativas bem-sucedidas de invocar a operação. O disjuntor automático regressa ao estado Fechado após um número especificado de invocações de operação consecutivas ter sito efetuado com êxito. Se alguma invocação falhar, o disjuntor automático entra imediatamente no estado Aberto e a contagem de tentativas bem-sucedidas é reposta da próxima vez que entrar no estado Meio-Aberto.
A forma como o sistema recupera é processada de forma externa, possivelmente ao restaurar ou reiniciar um componente falhado ou ao reparar uma ligação de rede.
O padrão do Disjuntor Automático confere estabilidade enquanto o sistema recupera de uma falha e minimiza o impacto no desempenho. Pode ajudar a manter o tempo de resposta do sistema ao rejeitar rapidamente um pedido de uma operação com boas probabilidades de falhar, em vez de esperar que o limite de tempo de uma operação seja ultrapassado ou que esta nunca seja devolvida. Se o disjuntor automático gerar um evento sempre que muda de estado, esta informação pode ser utilizada para monitorizar o estado de funcionamento da parte do sistema protegida pelo disjuntor automático ou para alertar um administrador quando um disjuntor automático passar para o estado Aberto.
O padrão é personalizável e pode ser adaptado segundo o tipo da possível falha. Por exemplo, pode aplicar um temporizador de tempo limite aumentado a um disjuntor automático. Você pode colocar o disjuntor no estado Aberto por alguns segundos inicialmente e, em seguida, se a falha não tiver sido resolvida, aumentar o tempo limite para alguns minutos e assim por diante. Em alguns casos, em vez de o estado Aberto devolver uma falha e gerar uma exceção, poderá ser útil regressar a um valor predefinido que seja significativo para a aplicação.
Problemas e considerações
Deve considerar os seguintes pontos ao decidir como implementar este padrão:
Processamento de exceções. Uma aplicação a invocar uma operação através de um disjuntor automático tem de estar preparada para processar as exceções colocadas se a operação não estiver disponível. A forma como as exceções são processadas depende da aplicação. Por exemplo, uma aplicação pode degradar temporariamente o funcionamento da mesma, invocar uma operação alternativa para tentar efetuar a mesma tarefa, obter os mesmos dados ou reportar a exceção ao utilizador e pedir a este que tente novamente mais tarde.
Tipos de Exceções. Um pedido pode falhar por diversos motivos, alguns dos quais poderão indicar um tipo de falha mais grave do que os outros. Por exemplo, um pedido pode falhar porque um serviço remoto falhou e serão necessários vários minutos para recuperar, ou devido a um limite de tempo devido ao facto de o serviço estar temporariamente sobrecarregado. Um disjuntor automático poderá conseguir examinar os tipos de exceções que ocorrem e ajustar a respetiva estratégia consoante a natureza dessas exceções. Por exemplo, poderá precisar de um número maior de exceções ao limite de tempo para colocar o disjuntor automático no estado Aberto, relativamente ao número de falhas devido ao sistema se encontrar totalmente indisponível.
Registo. Um disjuntor automático deverá registar todos os pedidos falhados (e, possivelmente, pedidos bem-sucedidos) para permitir que um administrador monitorize o estado de uma operação.
Recuperabilidade. Deverá configurar o disjuntor automático de forma a corresponder ao padrão de recuperação provável da operação que está a proteger. Por exemplo, se o disjuntor automático permanecer muito tempo no estado Aberto, poderá colocar exceções, mesmo que o motivo da falha tenha sido resolvido. De forma semelhante, um disjuntor automático pode aumentar e reduzir os tempos de respostas de aplicações se mudar demasiado rapidamente do estado Aberto para o estado Meio-Aberto.
Testar Operações com Falhas. No estado Aberto, em vez de utilizar um temporizador para determinar quando mudar para o estado Meio-Aberto, um disjuntor automático pode enviar periodicamente um ping ao serviço ou recurso remoto para determinar se voltou a ficar disponível. Este ping pode assumir a forma de uma tentativa de invocar uma operação que tinha anteriormente falhado, ou poderá utilizar uma operação especial fornecida pelo serviço remoto especificamente para testar o estado de funcionamento do serviço, conforme descrito pelo Padrão de Monitorização do Estado de Pontos Finais.
Substituição Manual. Num sistema em que o tempo de recuperação para uma operação falhada é extremamente variável, é benéfico fornecer uma opção de reposição que permita a um administrador fechar um disjuntor automático (e repor a contagem de falhas). De forma semelhante, um administrador pode forçar um disjuntor automático a entrar em estado Aberto (e reiniciar o temporizador de limite de tempo) se a operação protegida pelo disjuntor automático estiver temporariamente indisponível.
Simultaneidade. O mesmo disjuntor automático poderá ser acedido por um grande número de instâncias simultâneas de uma aplicação. A implementação não deve bloquear pedidos simultâneos ou adicionar uma carga excessiva a cada chamada a uma operação.
Diferenciação de Recursos. Tenha cuidado ao utilizar um único disjuntor automático para um tipo de recurso se puder haver múltiplos fornecedores independentes subjacentes. Por exemplo, num arquivo de dados que contenha diversas partições, uma partição poderá estar totalmente acessível, ficando a outra com um problema temporário. Se as respostas de erro nesses cenários forem unidas, uma aplicação poderá tentar aceder a algumas partições mesmo quando uma falha for provável, enquanto que o acesso a outras partições poderá estar bloqueado, não obstante as boas probabilidades de sucesso.
Disjunção Automática Acelerada. Por vezes, uma resposta a uma falha pode conter informações suficientes para que o disjuntor automático seja ativado automaticamente e mantenha-se ativado durante um tempo mínimo. Por exemplo, a resposta de erro de um recurso partilhado que está sobrecarregado poderá indicar que uma nova tentativa imediata não é recomendada e que a aplicação deverá tentar novamente em poucos minutos.
Nota
Um serviço pode devolver o erro HTTP 429 (Demasiados Pedidos) se estiver a limitar o cliente ou HTTP 503 (Serviço Indisponível) se o serviço não estiver atualmente disponível. A resposta pode incluir informações adicionais, como a duração prevista do atraso.
Repetir Pedidos Falhados. No estado Aberto, em vez de simplesmente falhar com demasiada rapidez, um disjuntor automático pode também registar os detalhes de cada pedido num diário e fazer com que estes pedidos sejam repetidos quando o recurso ou serviço remoto ficar disponível.
Tempos Limite Inapropriados em Serviços Externos. Um disjuntor automático poderá não conseguir proteger totalmente as aplicações de operações que falhem em serviços externos configurados com um período de tempo limite bastante prolongado. Se o tempo limite for demasiado longo, executar um disjuntor automático poderá ser bloqueado durante um período alargado antes de o disjuntor automático indicar que a operação falhou. Durante este período, muitas outras instâncias de aplicações poderão também tentar invocar o serviço através do disjuntor automático e ligar um número significativo de threads antes de todas falharem.
Quando utilizar este padrão
Utilize este padrão:
- Para impedir uma aplicação de tentar invocar um serviço remoto ou aceder a um recurso partilhado se esta operação tiver fortes probabilidades de falhar.
Este padrão não é recomendado:
- Para gerir o acesso a recursos privados locais numa aplicação, como a estrutura de dados na memória. Neste ambiente, utilizar um disjuntor automático adicionaria uma sobrecarga ao seu sistema.
- Como substituto para processar exceções na lógica de negócio das suas aplicações.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Disjuntor pode ser usado no design de sua carga de trabalho para abordar as metas e princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Esse padrão evita sobrecarregar uma dependência com falha. Você também pode usar esse padrão para acionar a degradação normal na carga de trabalho. Os disjuntores são frequentemente acoplados à recuperação automática para fornecer autopreservação e auto-cura. - RE:03 Análise do modo de falha - RE:07 Falhas transitórias - RE:07 Autopreservação |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Esse padrão evita a abordagem de repetição em erro, que pode levar à utilização excessiva de recursos durante a recuperação de dependência e também pode sobrecarregar o desempenho em uma dependência que está tentando recuperar. - PE:07 Código e infraestrutura - PE:11 Respostas a questões em direto |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
Numa aplicação Web, várias páginas são preenchidas com dados obtidos de um serviço externo. Se o sistema implementar a cache mínima, a maioria dos resultados para estas páginas causará uma ida e volta ao serviço. As ligações da aplicação Web ao serviço poderão ser configuradas com um período de tempo limite (geralmente de 60 segundos) e, se o serviço não responder neste tempo, a lógica em cada página Web irá assumir que o serviço está indisponível e lançar uma exceção.
No entanto, se o serviço falhar e o sistema estiver muito ocupado, os utilizadores poderão ser forçados a aguardar até 60 segundos antes de uma exceção ocorrer. Eventualmente, recursos como memória, ligações e threads poderão ficar esgotados, impedindo outros utilizadores de se ligar ao sistema, mesmo que não estejam a aceder a páginas que obtenham dados do serviço.
Dimensionar o sistema ao adicionar mais servidores Web e implementar balanceamento de carga poderá atrasar a altura em que os recursos se esgotam, mas não resolverá o problema, uma vez que os pedidos de utilizadores continuarão a não ser responsivos e todos os servidores Web poderão mesmo assim ficar sem recursos.
Encapsular a lógica que liga ao serviço e obtém os dados num disjuntor automático pode ajudar a resolver o problema e processar a falha de serviço de forma mais elegante. Os pedidos de utilizadores continuarão a falhar, mas irão falhar mais rapidamente e os recursos não serão bloqueados.
A classe CircuitBreaker mantém as informações de estado relativas a um disjuntor automático num objeto que implementa a interface ICircuitBreakerStateStore mostrada no seguinte código.
interface ICircuitBreakerStateStore
{
CircuitBreakerStateEnum State { get; }
Exception LastException { get; }
DateTime LastStateChangedDateUtc { get; }
void Trip(Exception ex);
void Reset();
void HalfOpen();
bool IsClosed { get; }
}
A propriedade State indica o estado atual do disjuntor automático, que será Open, HalfOpen ou Closed, conforme definido pela enumeração CircuitBreakerStateEnum. A propriedade IsClosed deverá ser verdadeira se o disjuntor automático estiver fechado, mas falsa se estiver aberto ou meio aberto. O método Trip muda o estado do disjuntor automático para o estado aberto e regista a exceção que causou a mudança de estado, juntamente com a data e a hora em que a exceção ocorreu. As propriedades LastException e LastStateChangedDateUtc devolvem esta informação. O método Reset fecha o disjuntor automático e o método HalfOpen define o disjuntor automático como meio aberto.
A classe InMemoryCircuitBreakerStateStore no exemplo contém uma implementação da interface ICircuitBreakerStateStore. A classe CircuitBreaker cria uma instância desta classe para suspender o estado do disjuntor automático.
O método ExecuteAction na classe CircuitBreaker encapsula uma operação, especificada como um delegado Action. Se o disjuntor automático estiver fechado, ExecuteAction invoca o delegado Action. Se a operação falhar, um processador de exceção chama TrackException, que define o estado do disjuntor automático como aberto. O seguinte exemplo de código realça este fluxo.
public class CircuitBreaker
{
private readonly ICircuitBreakerStateStore stateStore =
CircuitBreakerStateStoreFactory.GetCircuitBreakerStateStore();
private readonly object halfOpenSyncObject = new object ();
...
public bool IsClosed { get { return stateStore.IsClosed; } }
public bool IsOpen { get { return !IsClosed; } }
public void ExecuteAction(Action action)
{
...
if (IsOpen)
{
// The circuit breaker is Open.
... (see code sample below for details)
}
// The circuit breaker is Closed, execute the action.
try
{
action();
}
catch (Exception ex)
{
// If an exception still occurs here, simply
// retrip the breaker immediately.
this.TrackException(ex);
// Throw the exception so that the caller can tell
// the type of exception that was thrown.
throw;
}
}
private void TrackException(Exception ex)
{
// For simplicity in this example, open the circuit breaker on the first exception.
// In reality this would be more complex. A certain type of exception, such as one
// that indicates a service is offline, might trip the circuit breaker immediately.
// Alternatively it might count exceptions locally or across multiple instances and
// use this value over time, or the exception/success ratio based on the exception
// types, to open the circuit breaker.
this.stateStore.Trip(ex);
}
}
O seguinte exemplo mostra o código (omitido do exemplo anterior) que é executado se o disjuntor automático não estiver fechado. Começa por verificar se o disjuntor automático esteve aberto durante mais tempo do que o especificado pelo campo local OpenToHalfOpenWaitTime na classe CircuitBreaker. Se for este o caso, o método ExecuteAction define o disjuntor automático como meio aberto e, em seguida, tenta efetuar a operação especificada pelo delegado Action.
Se a operação for bem-sucedida, o disjuntor automático volta ao estado fechado. Se a operação falhar, volta ao estado aberto e a hora da exceção ocorrida é atualizada, para que o disjuntor automático aguarde mais tempo antes de tentar voltar a efetuar a operação.
Se o disjuntor automático estiver aberto durante pouco tempo, menos do que o valor OpenToHalfOpenWaitTime, o método ExecuteAction lança simplesmente uma exceção CircuitBreakerOpenException e devolve o erro que fez com que o disjuntor automático mudasse para o estado aberto.
Adicionalmente, utiliza um bloqueio para impedir o disjuntor automático de tentar efetuar chamadas simultâneas à operação enquanto está meio aberto. Uma tentativa simultânea de invocar a operação será processada como se o disjuntor automático estivesse aberto e irá falhar com uma exceção, como será depois descrito.
...
if (IsOpen)
{
// The circuit breaker is Open. Check if the Open timeout has expired.
// If it has, set the state to HalfOpen. Another approach might be to
// check for the HalfOpen state that had be set by some other operation.
if (stateStore.LastStateChangedDateUtc + OpenToHalfOpenWaitTime < DateTime.UtcNow)
{
// The Open timeout has expired. Allow one operation to execute. Note that, in
// this example, the circuit breaker is set to HalfOpen after being
// in the Open state for some period of time. An alternative would be to set
// this using some other approach such as a timer, test method, manually, and
// so on, and check the state here to determine how to handle execution
// of the action.
// Limit the number of threads to be executed when the breaker is HalfOpen.
// An alternative would be to use a more complex approach to determine which
// threads or how many are allowed to execute, or to execute a simple test
// method instead.
bool lockTaken = false;
try
{
Monitor.TryEnter(halfOpenSyncObject, ref lockTaken);
if (lockTaken)
{
// Set the circuit breaker state to HalfOpen.
stateStore.HalfOpen();
// Attempt the operation.
action();
// If this action succeeds, reset the state and allow other operations.
// In reality, instead of immediately returning to the Closed state, a counter
// here would record the number of successful operations and return the
// circuit breaker to the Closed state only after a specified number succeed.
this.stateStore.Reset();
return;
}
}
catch (Exception ex)
{
// If there's still an exception, trip the breaker again immediately.
this.stateStore.Trip(ex);
// Throw the exception so that the caller knows which exception occurred.
throw;
}
finally
{
if (lockTaken)
{
Monitor.Exit(halfOpenSyncObject);
}
}
}
// The Open timeout hasn't yet expired. Throw a CircuitBreakerOpen exception to
// inform the caller that the call was not actually attempted,
// and return the most recent exception received.
throw new CircuitBreakerOpenException(stateStore.LastException);
}
...
Para utilizar um objeto CircuitBreaker para proteger uma operação, uma aplicação cria uma instância da classe CircuitBreaker e invoca o método ExecuteAction, especificando a operação de forma a ser executada como o parâmetro. A aplicação deverá ser preparada para apanhar a exceção CircuitBreakerOpenException se a operação falhar, pois o disjuntor automático está aberto. O código seguinte mostra um exemplo:
var breaker = new CircuitBreaker();
try
{
breaker.ExecuteAction(() =>
{
// Operation protected by the circuit breaker.
...
});
}
catch (CircuitBreakerOpenException ex)
{
// Perform some different action when the breaker is open.
// Last exception details are in the inner exception.
...
}
catch (Exception ex)
{
...
}
Recursos relacionados
Os padrões seguintes podem também ser úteis ao implementar este padrão:
O padrão de aplicativo Web confiável mostra como aplicar o padrão de disjuntor a aplicativos Web convergentes na nuvem.
Padrão Repetição. Descreve como uma aplicação pode processar falhas previstas e temporárias quando tentar ligar a um recurso ou serviço de rede, ao repetir de forma transparente uma operação que falhou anteriormente.
Padrão de monitoramento de ponto final de integridade. Um disjuntor automático pode conseguir testar o estado de um serviço ao enviar um pedido ao ponto final exposto pelo serviço. O serviço deve devolver informações a indicar o seu estado.