Crie índices sobre os campos nos arquivos de dados que são frequentemente referenciados por consultas. Este padrão pode melhorar o desempenho das consultas ao permitir às aplicações localizar mais rapidamente os dados a obter de um arquivo de dados.
Contexto e problema
Muitos arquivos de dados organizam os dados de uma coleção de entidades com a chave primária. Uma aplicação pode utilizar esta chave para localizar e obter dados. A figura mostra um exemplo de um arquivo de dados que contém informações do cliente. A chave primária é o ID de Cliente. A figura mostra as informações do cliente organizadas pela chave primária (ID de Cliente).

Apesar de a chave primária ser útil para consultas que obtêm dados com base no valor desta chave, determinada aplicação poderá não conseguir utilizar a chave primária se precisar de obter dados com base noutro campo. No exemplo de clientes, a aplicação não poderá utilizar a chave primária do ID de Cliente para obter os clientes se esta consultar os dados tendo como referência apenas o valor de outro atributo, tal como a cidade onde o cliente se encontra. Para executar uma consulta como esta, a aplicação pode ter de obter e examinar todos os registos de clientes, o que pode ser um processo lento.
Muitos sistemas de gestão de base de dados relacionais suportam índices secundários. Um índice secundário é uma estrutura de dados separada, organizada por um ou mais campos de chaves não primárias (secundárias), que indica onde estão armazenados os dados de cada valor indexado. Os itens num índice secundário são normalmente ordenados pelo valor das chaves secundárias para permitir uma pesquisa rápida dos dados. Normalmente, estes índices são mantidos automaticamente pelo sistema de gestão de bases de dados.
Pode criar todos os índices secundários que precisar para suportar as diferentes consultas realizadas pela aplicação. Por exemplo, numa tabela Clientes de uma base de dados relacional em que o ID de Cliente é a chave primária, será vantajoso adicionar um índice secundário no campo Cidade se a aplicação procurar clientes frequentemente pela cidade onde residem.
No entanto, embora os índices secundários sejam comuns em sistemas relacionais, alguns armazenamentos de dados NoSQL usados por aplicativos em nuvem não fornecem um recurso equivalente.
Solução
Se o arquivo de dados não suportar índices secundários, será possível emulá-los manualmente ao criar as suas próprias tabelas de índice. Uma tabela de índice organiza os dados por uma chave especificada. São frequentemente utilizadas três estratégias para estruturar uma tabela de índice, as quais dependem do número de índices secundários necessários e da natureza das consultas que uma aplicação executa.
A primeira estratégia consiste em duplicar os dados de cada tabela de índice, mas organizá-los por chaves diferentes (desnormalização completa). A figura seguinte mostra as tabelas de índice que organizam as mesmas informações dos clientes por Cidade e por Apelido.
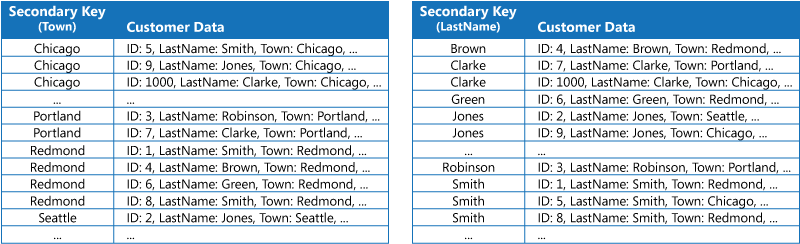
Esta estratégia será adequada se os dados forem relativamente estáticos em comparação com o número de vezes que são consultados com cada chave. Se os dados forem mais dinâmicos, os custos de processamento da manutenção de cada tabela de índice tornar-se-ão demasiado grandes para esta abordagem ser útil. Além disso, se o volume de dados for muito grande, a quantidade de espaço necessário para armazenar os dados duplicados será significativa.
A segunda estratégia consiste em criar tabelas de índice normalizadas organizadas por chaves diferentes e referenciar os dados originais com a chave primária ao invés de os duplicar, conforme mostrado na figura seguinte. Os dados originais são denominados “tabela de factos”.
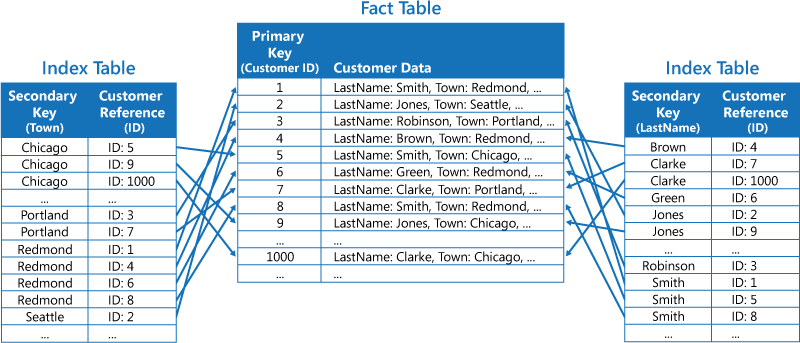
Esta técnica poupa espaço e reduz os custos da manutenção de dados duplicados. A desvantagem é que uma aplicação tem de executar duas operações de pesquisa para encontrar os dados com uma chave secundária. Tem de localizar a chave primária dos dados na tabela de índice e, em seguida, utilizar a chave primária para pesquisar os dados na tabela de factos.
A terceira estratégia consiste em criar tabelas de índice parcialmente normalizadas, organizadas por diferentes chaves que duplicam os campos frequentemente obtidos. Referencie a tabela de factos para aceder a campos menos utilizados. A figura seguinte mostra como os dados acedidos frequentemente são duplicados em cada tabela de índice.

Com esta estratégia, pode conseguir um equilíbrio entre as duas primeiras abordagens. Os dados de consultas comuns podem ser obtidos rapidamente com uma única pesquisa, embora os custos de manutenção e espaço não sejam tão significativos como a duplicação do conjunto de dados completo.
Se um aplicativo frequentemente consulta dados especificando uma combinação de valores (por exemplo, "Encontre todos os clientes que moram em Redmond e que têm um sobrenome de Smith"), você pode implementar as chaves para os itens na tabela de índice como uma concatenação do atributo Town e do atributo LastName. A figura seguinte mostra uma tabela de índice com base nas chaves compostas. As chaves são ordenadas por Cidade e, em seguida, por Apelido para os registos que têm o mesmo valor para Cidade.

As tabelas de índice podem acelerar as operações de consulta através de dados em partição horizontal e são particularmente úteis quando a chave de partição horizontal tem hash. A figura seguinte mostra um exemplo em que a chave de partição horizontal é um hash do ID de Cliente. A tabela de índice pode organizar os dados pelo valor sem hash (Cidade e Apelido) e fornecer a chave de partição horizontal com hash como os dados de pesquisa. Este procedimento evitará que a aplicação calcule repetidamente as chaves de hash (uma operação dispendiosa) se precisar de obter dados dentro de um intervalo ou se precisar de obter dados por ordem da chave sem hash. Por exemplo, uma consulta como "Localizar todos os clientes que vivem em Redmond" pode ser resolvida rapidamente localizando os itens correspondentes na tabela de índice, onde todos são armazenados em um bloco contíguo. Em seguida, siga as referências para os dados do cliente com as chaves de partição horizontal armazenadas na tabela de índice.

Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
Os custos de manutenção dos índices secundários podem ser significativos. Tem de analisar e compreender as consultas que a sua aplicação utiliza. Crie apenas tabelas de índice quando há uma grande probabilidade de serem utilizadas com regularidade. Não crie tabelas de índice especulativas para suportar consultas que uma aplicação não realiza, ou realiza apenas ocasionalmente.
A duplicação de dados de uma tabela de índice pode aumentar significativamente os custos de armazenamento e o esforço necessário para manter várias cópias dos dados.
A implementação de uma tabela de índice como uma estrutura normalizada que referencia os dados originais precisa de uma aplicação para realizar duas operações de pesquisa para localizar os dados. A primeira operação pesquisa a tabela de índice para obter a chave primária e a segunda utiliza a chave primária para obter os dados.
Se um sistema incorporar um determinado número de tabelas de índice através de conjuntos de dados muito grandes, poderá ser difícil manter a consistência entre as tabelas de índice e os dados originais. Pode ser possível criar a aplicação em torno do modelo de consistência eventual. Por exemplo, para inserir, atualizar ou eliminar dados, uma aplicação pode publicar uma mensagem numa fila e permitir que uma tarefa separada realize a operação e mantenha as tabelas de índice que referenciam estes dados de forma assíncrona. Para obter mais informações sobre a implementação de consistência eventual, veja o Data Consistency Primer (Manual Básico sobre a Consistência dos Dados).
Gorjeta
As tabelas de armazenamento do Microsoft Azure suportam atualizações transacionais para as alterações realizadas nos dados detidos na mesma partição (denominadas transações do grupo de entidades). Se puder armazenar os dados de uma tabela de factos e de uma ou mais tabelas de índices na mesma partição, poderá utilizar esta funcionalidade para ajudar a garantir a consistência.
As próprias tabelas de índice podem ser particionadas ou particionadas horizontalmente.
Quando utilizar este padrão
Utilize este padrão para melhorar o desempenho da consulta quando uma aplicação precisa de obter dados frequentemente com uma chave que não a chave primária (ou de partição horizontal).
Este padrão poderá não ser prático quando:
- Os dados são voláteis. Uma tabela de índice pode ficar desatualizada muito rapidamente, o que a torna ineficaz ou pode aumentar os custos de manutenção da tabela de índice para um valor superior às poupanças que esta cria.
- Um campo selecionado como a chave secundária para uma tabela de índice é não discriminatório e só pode ter um pequeno conjunto de valores (por exemplo, sexo).
- O equilíbrio dos valores dos dados de um campo selecionado como a chave secundária para uma tabela de índice é muito imparcial. Por exemplo, se 90% dos registos tiverem o mesmo valor num campo, a criação e a manutenção de uma tabela de índice para pesquisar dados com base neste campo poderão acarretar mais custos do que uma análise sequencial através dos dados. No entanto, se as consultas indicarem muito frequentemente valores que se situam nos restantes 10%, este índice poderá ser útil. Deve compreender as consultas que a sua aplicação realiza e a frequência com que são realizadas.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Tabela de Índice pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Como os clientes são apontados para seu fragmento, partição ou ponto de extremidade por meio de um processo de pesquisa, você pode usar esse padrão para facilitar uma abordagem de failover para acesso a dados. - RE:06 Particionamento de dados - RE:09 Recuperação de desastres |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Os clientes são direcionados para seu fragmento, partição ou ponto de extremidade, que pode habilitar o particionamento dinâmico de dados para otimização de desempenho. - PE:05 Dimensionamento e particionamento - PE:08 Desempenho dos dados |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
As tabelas de armazenamento do Azure fornecem um arquivo de dados de chave/valor altamente escalável para aplicações em execução na cloud. As aplicações armazenam e obtêm valores de dados ao especificar uma chave. Os valores de dados podem conter vários campos, mas a estrutura de um item de dados é opaca para o armazenamento de tabelas, a qual processa simplesmente um item de dados como uma matriz de bytes.
As tabelas de armazenamento do Azure suportam também a fragmentação. A chave de fragmentação inclui dois elementos, uma chave de partição e uma chave de linha. Os itens com a mesma chave de partição são armazenados na mesma partição (partição horizontal) e são armazenados por ordem da chave de linha na partição horizontal. O armazenamento da tabela é otimizado para executar consultas que obtêm dados dentro de um intervalo contíguo de valores de chave de linha dentro de uma partição. Se estiver a criar aplicações na cloud para armazenar informações nas tabelas do Azure, deve estruturar os dados com esta funcionalidade em mente.
Por exemplo, considere uma aplicação que armazena informações sobre filmes. A aplicação consulta frequentemente os filmes por género (ação, documentário, histórico, comédia, drama, entre outros). Pode criar uma tabela do Azure com partições para cada género, sendo este a chave da partição, e especificar o nome do filme como a chave de linha, conforme mostrado na figura seguinte.
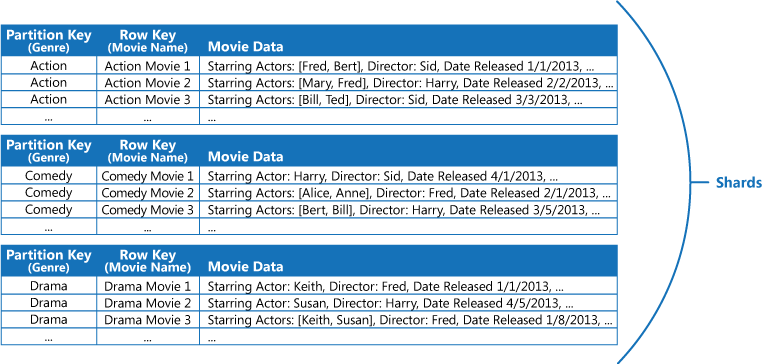
Esta abordagem será menos eficiente se a aplicação também precisar de pesquisar filmes por ator principal. Neste caso, pode criar uma tabela do Azure separada que funciona como uma tabela de índice. A chave de partição é o ator e a chave de linha é o nome do filme. Os dados para cada ator serão armazenados em partições separadas. Se um filme tiver mais do que um ator principal, o mesmo filme surgirá em várias partições.
Pode duplicar os dados do filme nos valores detidos por cada partição ao adotar a primeira abordagem descrita na secção Solução acima. No entanto, é provável que cada filmes seja replicado várias vezes (uma vez para cada ator), pelo que pode ser mais eficiente desnormalizar parcialmente os dados para suportar as consultas mais comuns (por exemplo, os nomes dos outros atores) e ativar uma aplicação para obter quaisquer detalhes restantes, ao incluir a chave de partição necessária para encontrar as informações completas nas partições de género. Esta abordagem é descrita pela terceira opção na secção Solução. A figura seguinte mostra esta abordagem.
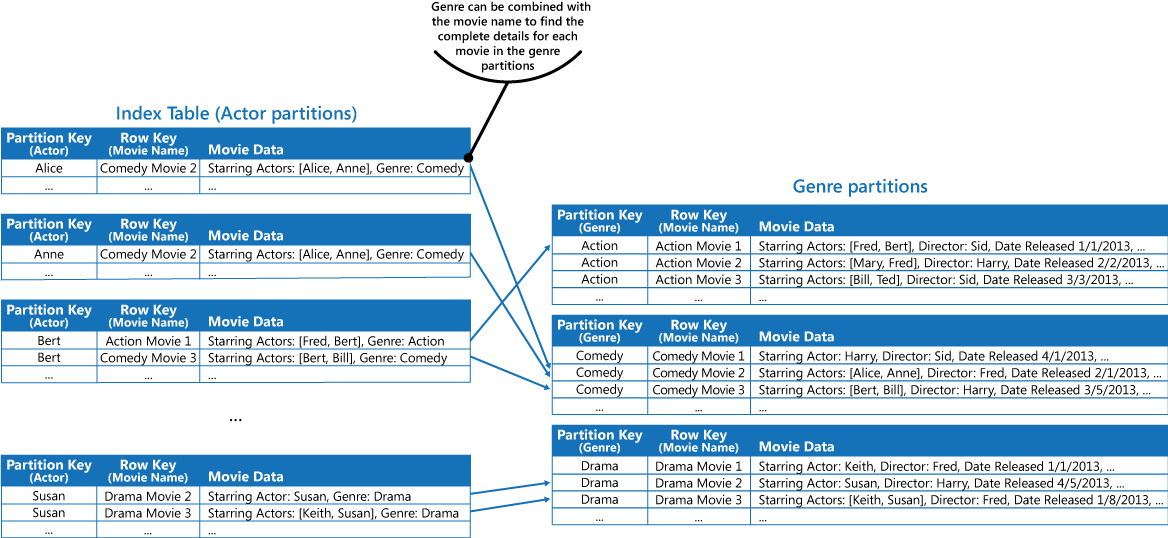
Próximos passos
- Manual Básico de Consistência de Dados. Uma tabela de índice deve ser mantida à medida que os dados que indexa são alterados. Na cloud, pode não ser possível ou adequado realizar operações que atualizam um índice como parte da mesma transação que modifica os dados. Nesse caso, uma abordagem eventualmente consistente é mais adequada. Fornece informações sobre os problemas adjacentes à consistência eventual.
Recursos relacionados
Os seguintes padrões também podem ser relevantes ao implementar esse padrão:
- Padrão de fragmentação. O padrão de Tabela de Índice é frequentemente utilizado em conjunto com os dados particionados com partições horizontais. O padrão de Fragmentação fornece mais informações sobre como dividir um arquivo de dados num conjunto de partições horizontais.
- Padrão de Vista Materializada. Em vez de indexar dados para suportar consultas que resumem os dados, pode ser mais adequado criar uma vista materializada dos dados. Descreve como pode suportar consultas de resumo eficientes ao gerar vistas pré-preenchida com dados.