Divida um arquivo de dados num conjunto de partições horizontais ou shards. Deste modo, pode melhorar a escalabilidade ao armazenar e aceder a grandes volumes de dados.
Contexto e problema
Um arquivo de dados alojado por um único servidor poderá estar sujeito às seguintes limitações:
Espaço de armazenamento. É esperado que um arquivo de dados para uma aplicação na cloud em grande escala contenha um grande volume de dados que poderá aumentar significativamente com o tempo. Um servidor normalmente proporciona apenas uma quantidade finita de armazenamento em disco, mas pode substituir discos existentes por outros maiores ou adicionar mais discos a um computador à medida que os volumes de dados aumentam. No entanto, o sistema acabará por chegar a um limite onde não poderá aumentar facilmente a capacidade de armazenamento num determinado servidor.
Recursos informáticos. Precisa de uma aplicação na cloud para suportar um grande número de utilizadores em simultâneo, sendo que cada um executa consultas que obtêm informações do arquivo de dados. Um único servidor que hospeda o armazenamento de dados pode não ser capaz de fornecer o poder de computação necessário para suportar essa carga, resultando em tempos de resposta estendidos para os usuários e falhas frequentes como aplicativos que tentam armazenar e recuperar o tempo limite de dados. Pode ser possível adicionar memória ou atualizar processadores, mas o sistema atingirá um limite quando não for possível aumentar ainda mais os recursos de computação.
Largura de banda de rede. Em última análise, o desempenho de um arquivo de dados em execução num único servidor é regido pela taxa a que o servidor consegue receber os pedidos e enviar as respostas. O volume do tráfego de rede pode exceder a capacidade da rede utilizada para ligar ao servidor, resultando em pedidos falhados.
Geografia. Poderá ser preciso armazenar dados gerados por utilizadores específicos na mesma região deles por motivos legais, de compatibilidade ou de desempenho ou para reduzir a latência do acesso aos dados. Se os utilizadores estiverem distribuídos por diferentes países ou regiões, poderá não conseguir armazenar todos os dados da aplicação num único arquivo de dados.
O dimensionamento vertical, ao adicionar mais capacidade de disco, potência de processamento, memória e ligações de rede, pode adiar os efeitos de algumas destas limitações, mas é provável que seja apenas uma solução temporária. Uma aplicação comercial na cloud capaz de suportar grandes números de utilizadores e elevados volumes de dados tem de ser capaz de dimensionar quase indefinidamente, pelo que o dimensionamento vertical não é necessariamente a melhor solução.
Solução
Divida o arquivo de dados em partições horizontais. Cada partição horizontal tem o mesmo esquema, mas mantém o seu próprio subconjunto de dados distinto. Uma partição horizontal é um arquivo de dados por direito próprio (pode conter os dados de muitas entidades de diferentes tipos), em execução num servidor a funcionar como um nó de armazenamento.
Este padrão possui as vantagens seguintes:
Pode aumentar horizontalmente o sistema ao adicionar mais partições horizontais em execução em nós de armazenamento adicionais.
Um sistema pode utilizar hardware pronto a utilizar em vez de computadores dispendiosos e especializados para cada nó de armazenamento.
Pode reduzir a disputa e melhorar o desempenho ao balancear a carga de trabalho nas partições horizontais.
Na cloud, as partições horizontais podem estar localizadas fisicamente perto dos utilizadores que irão aceder aos dados.
Ao dividir um arquivo de dados em partições horizontais, decida que dados devem ser colocados em cada partição horizontal. Normalmente, uma partição horizontal contém itens que se inserem num intervalo especificado, determinado por um ou mais atributos dos dados. Estes atributos formam a chave de partição horizontal (por vezes, denominada chave de partição). A chave de partição horizontal deve ser estática. Não deve basear-se em dados passíveis de serem alterados.
A fragmentação organiza fisicamente os dados. Quando uma aplicação armazena e obtém dados, a lógica de fragmentação direciona a aplicação para a partição horizontal adequada. Esta lógica de fragmentação poderá ser implementada como parte do código de acesso de dados na aplicação ou poderá ser implementada pelo sistema de armazenamento de dados se suportar a fragmentação de forma transparente.
Ao abstrair a localização física dos dados na lógica de fragmentação, proporciona um elevado nível de controlo sobre que partições horizontais contêm determinados dados. Também permitirá que os dados migrem entre partições horizontais sem reformular a lógica de negócio de uma aplicação se os dados nas partições horizontais tiverem de ser redistribuídos mais tarde (por exemplo, se as partições horizontais ficarem desequilibradas). O compromisso é o custo do acesso aos dados adicional necessário para determinar a localização de cada item de dados, à medida que é obtido.
Para garantir um desempenho e escalabilidade ideais, é importante dividir os dados de uma forma que seja adequada para os tipos de consultas que a aplicação executa. Em muitos casos, não é provável que o esquema de fragmentação corresponda exatamente aos requisitos de cada consulta. Por exemplo, em um sistema multilocatário, um aplicativo pode precisar recuperar dados do locatário usando a ID do locatário, mas também pode precisar pesquisar esses dados com base em algum outro atributo, como o nome ou o local do locatário. Para processar estas situações, implemente uma estratégia de fragmentação com uma chave de partição horizontal que suporte as consultas executadas com mais frequência.
Se as consultas obtiverem regularmente dados através de uma combinação de valores de atributos, será provável que possa definir uma chave de partição horizontal composta ao associar atributos. Em alternativa, utilize um padrão como Tabela de Índice para proporcionar uma pesquisa rápida de dados com base em atributos que não são abrangidos pela chave de partição horizontal.
Estratégias de fragmentação
As três estratégias são frequentemente utilizadas ao selecionar a chave de partição horizontal e ao decidir como distribuir os dados pelas partições horizontais. Observe que não precisa haver uma correspondência um-para-um entre fragmentos e os servidores que os hospedam — um único servidor pode hospedar vários fragmentos. As estratégias são:
Estratégia de Pesquisa. Nesta estratégia, a lógica de fragmentação implementa um mapa que encaminha um pedido de dados para a partição horizontal que contém os dados através da chave de partição horizontal. Em um aplicativo multilocatário, todos os dados de um locatário podem ser armazenados juntos em um fragmento usando o ID do locatário como a chave de estilhaço. Vários inquilinos podem partilhar a mesma partição horizontal, mas os dados de um único inquilino não serão distribuídos por várias partições horizontais. A figura ilustra a fragmentação dos dados de inquilino com base nos IDs de inquilino.
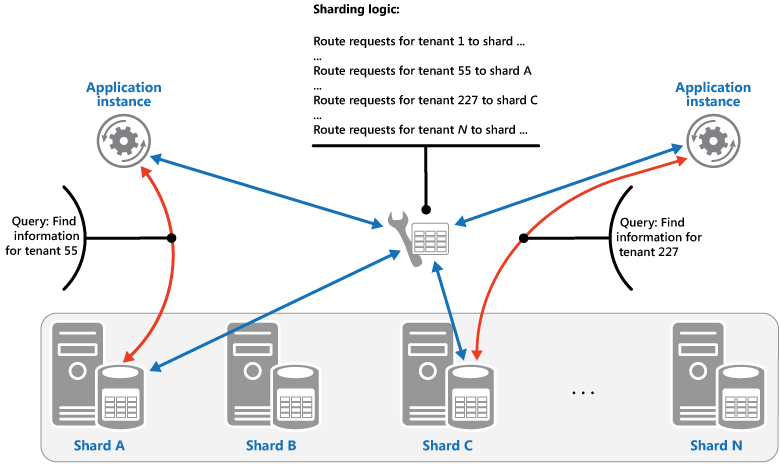
O mapeamento entre o valor da chave de estilhaço e o armazenamento físico em que os dados existem pode ser baseado em fragmentos físicos em que cada valor de chave de fragmento é mapeado para uma partição física. Como alternativa, uma técnica mais flexível para reequilibrar fragmentos é o particionamento virtual, onde os valores das chaves de estilhaços são mapeados para o mesmo número de fragmentos virtuais, que, por sua vez, são mapeados para menos partições físicas. Nessa abordagem, um aplicativo localiza dados usando um valor de chave de estilhaço que se refere a um fragmento virtual, e o sistema mapeia de forma transparente fragmentos virtuais para partições físicas. O mapeamento entre um fragmento virtual e uma partição física pode ser alterado sem exigir que o código do aplicativo seja modificado para usar um conjunto diferente de valores de chave de estilhaço.
Estratégia de intervalo. Essa estratégia agrupa itens relacionados no mesmo fragmento e os ordena por chave de estilhaço — as chaves de estilhaço são sequenciais. É útil para aplicações que, frequentemente, obtêm conjuntos de itens através de consultas de intervalo (consultas que devolvem um conjunto de itens de dados para uma chave de partição horizontal que se encontrem dentro de um determinado intervalo). Por exemplo, se uma aplicação precisar regularmente de localizar todas as encomendas realizadas num determinado mês, estes dados poderão ser obtidos mais rapidamente se todas as encomendas de um mês forem armazenadas por ordem de data e hora na mesma partição horizontal. Se cada encomenda for armazenada numa partição horizontal diferente, terá de ser obtida individualmente ao executar um grande número de consultas pontuais (consultas que devolvem um único item de dados). A figura seguinte ilustra o armazenamento de conjuntos (intervalos) de dados sequenciais na partição horizontal.
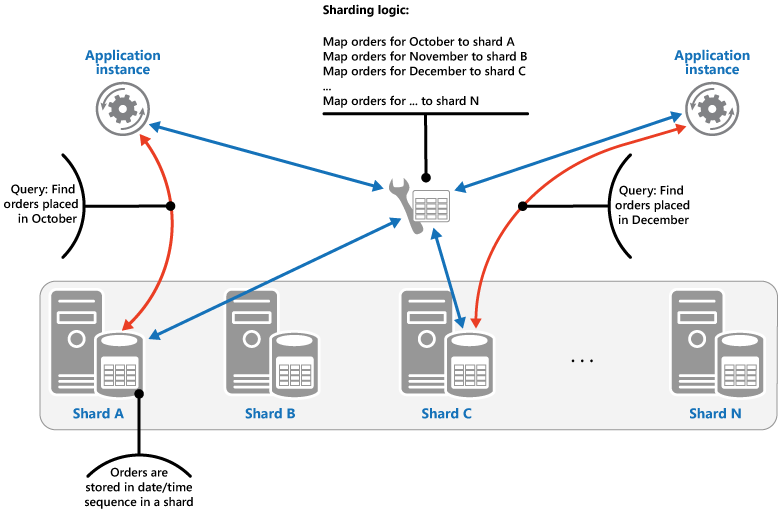
Neste exemplo, a chave de partição horizontal é uma chave composta, que contém o mês da encomenda como o elemento mais significativo, seguido do dia e hora da encomenda. Os dados das encomendas são ordenados naturalmente quando são criadas novas encomendas e adicionadas a uma partição horizontal. Alguns arquivos de dados suportam chaves de partições horizontais de duas partes que contêm um elemento de chave de partição que identifica a partição horizontal e uma chave de linha que identifica exclusivamente um item na partição horizontal. Normalmente, os dados estão contidos de acordo com a ordem de chave da linha na partição horizontal. Os itens que estão sujeitos a consultas de intervalo e que têm de ser agrupados em conjunto podem utilizar uma chave de partição horizontal que tenha o mesmo valor para a chave de partição, mas um valor exclusivo para a chave de linha.
Estratégia de hash. O objetivo desta estratégia é reduzir a possibilidade de hotspots (partições horizontais que recebem uma quantidade desproporcionada de carga). Distribui os dados pelas partições horizontais de uma forma que alcança um equilíbrio entre o tamanho de cada partição horizontal e a carga média que cada partição horizontal irá encontrar. A lógica de fragmentação calcula a partição horizontal para armazenar um item com base num hash de um ou mais atributos dos dados. A função de hash escolhida deve distribuir os dados uniformemente pelas partições horizontais, possivelmente, introduzindo alguns elementos aleatórios no cálculo. A figura seguinte ilustra a fragmentação dos dados de inquilino com base num hash dos IDs de inquilino.

Para entender a vantagem da estratégia Hash em relação a outras estratégias de fragmentação, considere como um aplicativo multilocatário que registra novos locatários sequencialmente pode atribuir os locatários a fragmentos no armazenamento de dados. Quando utilizar a Estratégia de intervalo, os dados dos inquilinos 1 a n serão armazenados na partição horizontal A, os dados dos inquilinos n + 1 a m serão armazenados na partição horizontal B e assim sucessivamente. Se os inquilinos mais recentemente registados também forem mais ativos, a maioria das atividades de dados ocorrerá num pequeno número de partições horizontais, o que poderá provocar hotspots. Em contrapartida, a Estratégia de hash atribui os inquilinos a partições horizontais com base num hash do seu ID de inquilino, o que significa que é mais provável que os inquilinos sequenciais sejam atribuídos a partições horizontais diferentes, que irão distribuir a carga entre si. A figura anterior mostra esta situação para os inquilinos 55 e 56.
As três estratégias de fragmentação têm as seguintes vantagens e considerações:
Pesquisa. Esta estratégia oferece mais controlo sobre como as partições horizontais são configuradas e utilizadas. A utilização de partições horizontais virtuais reduz o impacto ao reequilibrar os dados, porque as novas partições físicas podem ser adicionadas para repartir a carga de trabalho. O mapeamento entre uma partição horizontal virtual e as partições físicas que implementam as partições horizontais pode ser modificado sem afetar o código de aplicação que utiliza uma chave de partição horizontal para armazenar e obter dados. A procura de localizações de partições horizontais pode implicar um custo adicional.
Intervalo. Esta estratégia é fácil de implementar e funciona bem com consultas de intervalo porque, muitas vezes, podem obter vários itens de dados de uma única partição horizontal numa única operação. Esta estratégia proporciona uma gestão de dados mais fácil. Por exemplo, se os utilizadores na mesma região estiverem na mesma partição horizontal, poderão ser agendadas atualizações em cada fuso horário com base no padrão da procura e da carga local. No entanto, esta estratégia não proporciona um balanceamento ideal entre partições horizontais. Reequilibrar as partições horizontais é difícil e poderá não resolver o problema da carga desigual se a maioria das atividades for para as chaves de partições horizontais adjacentes.
Hash. Esta estratégia oferece uma melhor oportunidade para obter uma distribuição mais uniforme da carga e dos dados. O encaminhamento de pedidos pode ser conseguido diretamente através da função de hash. Não é necessário manter um mapa. Tenha em atenção que calcular o hash pode implicar um custo adicional. Além disso, reequilibrar as partições horizontais é difícil.
Os sistemas de fragmentação mais comuns implementam uma das abordagens descritas acima, mas também deve considerar os requisitos comerciais das suas aplicações e os seus padrões de utilização de dados. Por exemplo, em um aplicativo multilocatário:
Pode fragmentar os dados com base na carga de trabalho. Pode segregar os dados dos inquilinos altamente voláteis em partições horizontais separadas. Como resultado, a velocidade do acesso aos dados dos outros inquilinos pode ser melhorada.
Pode fragmentar os dados com base na localização dos inquilinos. Pode colocar os dados dos inquilinos numa região geográfica específica offline para fins de cópia de segurança e de manutenção fora das horas de ponta nessa região, enquanto os dados dos inquilinos noutras regiões permanecem online e acessíveis durante o horário comercial.
Locatários de alto valor podem receber seus próprios fragmentos privados, de alto desempenho e levemente carregados, enquanto os locatários de menor valor podem ser esperados para compartilhar fragmentos mais densamente embalados e ocupados.
Os dados para os inquilinos que precisam de um elevado grau de isolamento e de privacidade podem ser armazenados num servidor completamente separado.
Operações de movimento de dados e de dimensionamento
Cada uma das estratégias de fragmentação implica diferentes capacidades e níveis de complexidade para gerir a redução horizontal, o aumento horizontal, o movimento de dados e a manutenção do estado.
A Estratégia de pesquisa permite que as operações de movimento de dados e de dimensionamento sejam realizadas ao nível do utilizador, online ou offline. A técnica consiste em suspender algumas ou todas as atividades do utilizador (talvez fora das horas de ponta), mover os dados para a nova partição virtual ou partição horizontal física, alterar os mapeamentos, invalidar ou atualizar qualquer cache que contenha estes dados e, em seguida, permitir que a atividade do utilizador seja retomada. Muitas vezes, este tipo de operação pode ser gerido centralmente. A Estratégia de pesquisa requer um estado altamente compatível com a colocação em cache e com as réplicas.
A Estratégia de intervalo impõe algumas limitações nas operações de movimento de dados e dimensionamento, que têm, normalmente, de ser executadas quando uma parte ou todo o arquivo de dados está offline porque os dados têm de ser divididos e intercalados entre as partições horizontais. Mover os dados para reequilibrar as partições horizontais poderá não resolver o problema da carga desigual se a maioria da atividade for para as chaves de partições horizontais adjacentes ou identificadores de dados que estão dentro do mesmo intervalo. A Estratégia de intervalo pode igualmente precisar que algum estado seja mantido para mapear intervalos para as partições físicas.
A Estratégia de hash faz com que as operações de movimento de dados e dimensionamento sejam mais complexas porque as chaves de partição são hashes de chaves de partições horizontais ou identificadores de dados. A nova localização de cada partição horizontal tem de ser determinada a partir da função de hash ou da função modificada para proporcionar os mapeamentos corretos. No entanto, a Estratégia de hash não requer a manutenção do estado.
Problemas e considerações
Na altura de decidir como implementar este padrão, considere os seguintes pontos:
A fragmentação complementa outras formas de criação de partições, tais como a criação de partições verticais e a criação de partições funcionais. Por exemplo, uma única partição horizontal pode conter entidades que tenham sido particionadas verticalmente e uma partição funcional pode ser implementada como várias partições horizontais. Para obter mais informações sobre a criação de partições, veja as Orientações sobre a Criação de Partições de Dados.
Mantenha as partições horizontais equilibradas para que todas processem um volume semelhante de E/S. Como os dados são inseridos e eliminados, é preciso reequilibrar periodicamente as partições horizontais para garantir uma distribuição uniforme e para reduzir a possibilidade de hotspots. O reequilíbrio pode ser uma operação dispendiosa. Para reduzir a necessidade de reequilíbrio, planeie o crescimento ao garantir que cada partição horizontal contém espaço livre suficiente para processar o volume de alterações esperado. Também deve desenvolver estratégias e scripts que possa utilizar para reequilibrar rapidamente as partições horizontais, se for preciso.
Utilize dados estáveis para a chave de partição horizontal. Se a chave de partição horizontal for alterada, o item de dados correspondente poderá ter de ser movido entre partições horizontais, aumentando a quantidade de trabalho realizado pela operações de atualização. Por este motivo, evite basear a chave de partição horizontal em informações potencialmente voláteis. Em vez disso, procure atributos que sejam invariáveis ou que formem naturalmente uma chave.
Garanta que as chaves de partições horizontais são exclusivas. Por exemplo, evite utilizar campos que incrementam automaticamente como a chave de partição horizontal. Em alguns sistemas, os campos incrementados automaticamente não podem ser coordenados entre fragmentos, possivelmente resultando em itens em fragmentos diferentes com a mesma chave de estilhaço.
Os valores incrementados automaticamente noutros campos que não são as chaves de partições horizontais também podem causar problemas. Por exemplo, se utilizar campos incrementados automaticamente para gerar IDs exclusivos, significa que dois itens diferentes localizados em partições horizontais diferentes poderão ser atribuídos ao mesmo ID.
Pode não ser possível estruturar uma chave de partição horizontal que satisfaça os requisitos de cada consulta possível relativamente aos dados. Coloque os dados em partições horizontais para suportar as consultas mais frequentemente realizadas e, se for necessário, crie tabelas de índice secundárias para suportar consultas que obtêm dados através de critérios com base em atributos que não fazem parte da chave de partição horizontal. Para obter mais informações, veja o Padrão de Tabela de Índice.
As consultas que apenas acedem a uma partição horizontal única são mais eficientes do que as que obtêm dados de várias partições horizontais. Por isso, evite implementar um sistema de fragmentação que resulte em aplicações a executar grandes números de consultas que associem dados retidos em partições horizontais diferentes. Lembre-se de que uma partição horizontal única pode conter os dados de vários tipos de entidades. Considere desnormalizar os dados para manter entidades relacionadas que normalmente são consultadas em conjunto (por exemplo, os detalhes de clientes e as encomendas que realizaram) na mesma partição horizontal para reduzir o número de leituras separadas que uma aplicação realiza.
Se uma entidade numa partição horizontal mencionar uma entidade armazenada noutra partição horizontal, inclua a chave de partição horizontal da segunda entidade como parte do esquema da primeira entidade. Deste modo, pode ajudar a melhorar o desempenho das consultas que mencionam dados relacionados entre as partições horizontais.
Se uma aplicação tiver de executar consultas que obtêm dados de várias partições horizontais, poderá ser possível obter estes dados através da utilização de tarefas paralelas. Os exemplos incluem consultas de distribuição ramificada, onde os dados de várias partições horizontais são obtidos em paralelo e, em seguida, agregados num único resultado. No entanto, esta abordagem inevitavelmente adiciona alguma complexidade à lógica de acesso aos dados de uma solução.
Para muitas aplicações, a criação de um grande número de partições horizontais pequenas pode ser mais eficiente do que ter um pequeno número de partições horizontais grandes porque podem oferecer maiores oportunidades de balanceamento de carga. Tal também pode ser útil caso preveja a necessidade de migrar partições horizontais de uma localização física para outra. Mover uma partição horizontal pequena é mais rápido do que mover uma grande.
Garanta que os recursos disponíveis para cada nó de armazenamento de partição horizontal são suficientes para processar os requisitos de escalabilidade em termos de tamanho de dados e débito. Para obter mais informações, consulte a seção "Projetando partições para escalabilidade" nas Diretrizes de particionamento de dados.
Considere replicar os dados de referência para todas as partições horizontais. Se uma operação que obtém dados a partir de uma partição horizontal também mencionar dados estáticos ou de movimento lento como parte da mesma consulta, adicione estes dados à partição horizontal. A aplicação pode, em seguida, obter todos os dados para a consulta facilmente, sem ter de realizar um percurso de ida e volta adicional para um arquivo de dados separado.
Se os dados de referência contidos em várias partições horizontais forem alterados, o sistema terá de sincronizar estas alterações em todas as partições horizontais. O sistema pode encontrar um certo grau de inconsistência enquanto esta sincronização ocorre. Se o fizer, deve conceber as suas aplicações para que sejam capazes de a processar.
Pode ser difícil manter a integridade referencial e a consistência entre as partições horizontais, pelo que deve minimizar as operações que afetam os dados de várias partições horizontais. Se uma aplicação tiver de modificar os dados em partições horizontais, avalie se a consistência de dados completa é realmente necessária. Em vez disso, uma abordagem comum na cloud é implementar a consistência eventual. Os dados em cada partição são atualizados em separado e a lógica da aplicação tem de ser responsável por garantir que todas as atualizações são concluídas com êxito, bem como processar as inconsistências que podem surgir da consulta de dados enquanto uma operação eventualmente consistente está em execução. Para obter mais informações sobre a implementação de consistência eventual, veja o Data Consistency Primer (Manual Básico sobre a Consistência dos Dados).
A configuração e a gestão de um grande número de partições horizontais podem ser um desafio. As tarefas como a monitorização, a cópia de segurança, a verificação de consistência e o registo ou a auditoria têm de ser realizadas em várias partições horizontais e servidores, possivelmente contidas em várias localizações. É provável que estas tarefas sejam implementadas com scripts ou outras soluções de automatização, mas podem não eliminar completamente os requisitos administrativos adicionais.
As partições horizontais podem ser geolocalizadas para que os dados que contêm estejam próximos das instâncias da aplicação que a utiliza. Esta abordagem pode melhorar significativamente o desempenho, mas requer considerações adicionais para as tarefas que têm de aceder a várias partições horizontais em diferentes localizações.
Quando utilizar este padrão
Utilize este padrão quando for provável que um arquivo de dados tenha de dimensionar para além dos recursos disponíveis para um nó de armazenamento único ou para melhorar o desempenho ao reduzir a disputa num arquivo de dados.
Nota
O foco principal da fragmentação é melhorar o desempenho e a escalabilidade de um sistema, mas como um subproduto, também pode melhorar a disponibilidade, devido à forma como os dados são divididos em partições separadas. Uma falha numa partição não impede necessariamente uma aplicação de aceder aos dados contidos noutras partições e um operador pode realizar a manutenção ou a recuperação de uma ou mais partições sem tornar todos os dados de uma aplicação inacessíveis. Para obter mais informações, veja as Orientações sobre a Criação de Partições de Dados.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Sharding pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Como os dados ou o processamento são isolados no fragmento, um mau funcionamento em um fragmento permanece isolado nesse fragmento. - RE:06 Particionamento de dados - RE:07 Autopreservação |
| A Otimização de Custos está focada em sustentar e melhorar o retorno do investimento da sua carga de trabalho. | Um sistema que implementa fragmentos geralmente se beneficia do uso de várias instâncias de recursos de computação ou armazenamento mais baratos, em vez de um único recurso mais caro. Em muitos casos, esta configuração pode poupar-lhe dinheiro. - CO:07 Custos dos componentes |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Quando você usa fragmentação em sua estratégia de dimensionamento, os dados ou o processamento são isolados em um fragmento, portanto, ele compete por recursos apenas com outras solicitações direcionadas a esse fragmento. Você também pode usar a fragmentação para otimizar com base na geografia. - PE:05 Dimensionamento e particionamento - PE:08 Desempenho dos dados |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
Considere um site que apresenta uma extensa coleção de informações sobre livros publicados em todo o mundo. O número de livros possíveis catalogados nessa carga de trabalho e os padrões típicos de consulta/uso contraindicam o uso de um único banco de dados relacional para armazenar as informações do livro. O arquiteto de carga de trabalho decide fragmentar os dados em várias instâncias de banco de dados, usando o ISBN (International Standard Book Number) estático dos livros para a chave de estilhaço. Especificamente, eles usam o dígito de verificação (0 - 10) do ISBN, pois isso dá 11 fragmentos lógicos possíveis e os dados serão bastante equilibrados em cada fragmento. Para começar, eles decidem colocalizar os 11 fragmentos lógicos em três bancos de dados de fragmentos físicos. Eles usam a abordagem de fragmentação de pesquisa e armazenam as informações de mapeamento chave-para-servidor em um banco de dados de mapa de estilhaços.
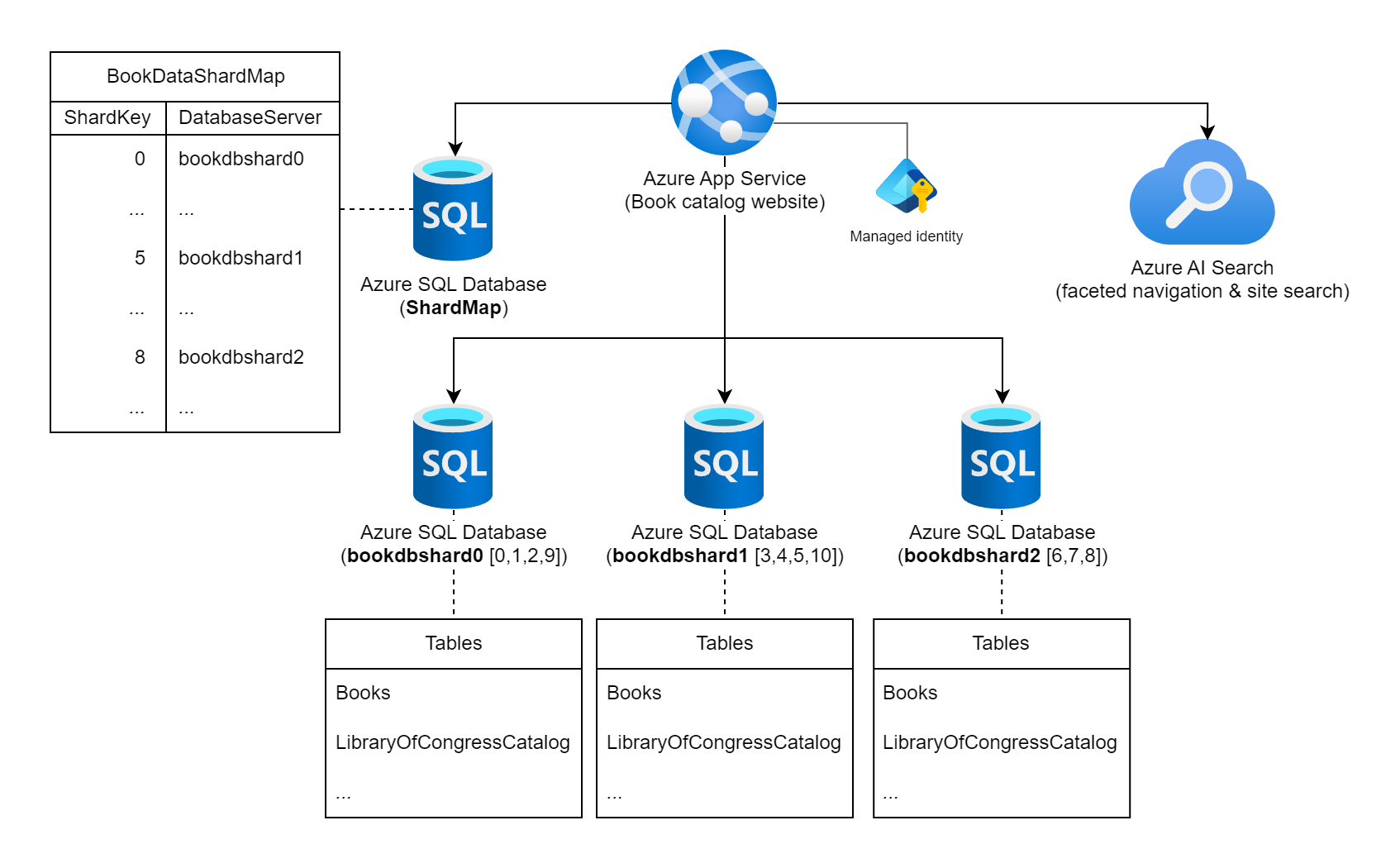
Diagrama que mostra um Serviço de Aplicativo do Azure rotulado como "Site do catálogo de livros" conectado a várias instâncias do Banco de Dados SQL do Azure e a uma instância do Azure AI Search. Um dos bancos de dados é rotulado como o banco de dados ShardMap e tem uma tabela de exemplo que espelha uma parte da tabela de mapeamento que também está listada mais adiante neste documento. Há três instâncias de bancos de dados de fragmentos listadas também: bookdbshard0, bookdbshard1 e bookdbshard2. Cada um dos bancos de dados tem um exemplo de listagem de tabelas sob eles. Todos os três exemplos são idênticos, listando as tabelas de "Livros" e "LibraryOfCongressCatalog" e um indicador de mais tabelas. O ícone Azure AI Search indica que ele é usado para navegação facetada e pesquisa de site. A identidade gerenciada é mostrada associada ao Serviço de Aplicativo do Azure.
Mapa de estilhaços de pesquisa
O banco de dados de mapa de estilhaços contém a seguinte tabela e dados de mapeamento de estilhaços.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Exemplo de código do site - acesso de estilhaço único
O site não está ciente do número de bancos de dados físicos de fragmentos (três neste caso) nem da lógica que mapeia uma chave de fragmento para uma instância de banco de dados, mas o site sabe que o dígito de verificação do ISBN de um livro deve ser considerado a chave de estilhaço. O site tem acesso somente leitura ao banco de dados de mapas de estilhaços e acesso de leitura-gravação a todos os bancos de dados de fragmentos. Neste exemplo, o site está usando a identidade gerenciada do sistema do Serviço de Aplicativo do Azure que está hospedando o site para autorização para manter segredos fora das cadeias de conexão.
O site é configurado com as seguintes cadeias de conexão, seja em um appsettings.json arquivo, como neste exemplo, ou por meio das configurações do aplicativo do Serviço de Aplicativo.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Com as informações de conexão com o banco de dados de mapa de estilhaços disponíveis, um exemplo de uma consulta de atualização executada pelo site para o pool de fragmentos do banco de dados da carga de trabalho seria semelhante ao código a seguir.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
No código de exemplo anterior, se book.Isbn era 978-8-1130-1024-6, então isbnCheckDigit deveria ser 6. A chamada para OpenShardConnectionForKeyAsync(6) normalmente seria implementada com uma abordagem de cache-side. Ele consulta o banco de dados de mapa de estilhaços identificado com a cadeia de conexão ShardMapDb se ele não tiver informações de fragmento armazenadas em cache para a chave de estilhaço 6. A partir do cache do aplicativo ou do banco de dados de estilhaços, o valor bookdbshard2 substitui na BookDbFragment cadeia de SHARD conexão. Uma conexão em pool é (re)estabelecida para bookdbshard2.database.windows.net, aberta e retornada ao código de chamada. Em seguida, o código atualiza o registro existente nessa instância de banco de dados.
Exemplo de código do site - acesso a vários estilhaços
No caso raro de uma consulta direta e cruzada ser exigida pelo site, o aplicativo executa uma consulta de distribuição paralela em todos os fragmentos.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
Como alternativa às consultas de estilhaços cruzados nessa carga de trabalho, pode ser o uso de um índice mantido externamente no Azure AI Search, como para pesquisa de site ou funcionalidade de navegação facetada.
Adicionando instâncias de estilhaços
A equipe de carga de trabalho está ciente de que, se o catálogo de dados ou seu uso simultâneo crescer significativamente, mais de três instâncias de banco de dados poderão ser necessárias. A equipe de carga de trabalho não espera adicionar dinamicamente servidores de banco de dados e suportará tempo de inatividade da carga de trabalho se um novo fragmento precisar ficar online. Colocar uma nova instância de fragmento online requer mover dados de fragmentos existentes para o novo fragmento, juntamente com uma atualização para a tabela de mapa de estilhaços. Essa abordagem bastante estática permite que a carga de trabalho armazene em cache com confiança o mapeamento do banco de dados de chaves de estilhaço no código do site.
A lógica da chave de estilhaço neste exemplo tem um limite superior rígido de 11 fragmentos físicos máximos. Se a equipe de carga de trabalho executar testes de estimativa de carga e avaliar que mais de 11 instâncias de bancos de dados serão eventualmente necessárias, uma alteração invasiva na lógica de chave de fragmento precisaria ser feita. Essa alteração envolve o planejamento cuidadoso de modificações de código e migração de dados para a nova lógica de chave.
Funcionalidade SDK
Em vez de escrever código personalizado para gerenciamento de estilhaços e roteamento de consultas para instâncias do Banco de Dados SQL do Azure, avalie a biblioteca de cliente do Banco de Dados Elástico. Esta biblioteca suporta gerenciamento de mapas de estilhaços, roteamento de consultas dependentes de dados e consultas entre estilhaços em C# e Java.
Próximos passos
As seguintes orientações também podem ser relevantes ao implementar este padrão:
- Manual Básico de Consistência de Dados. Poderá ser necessário manter a consistência dos dados distribuídos por diferentes partições horizontais. Resume os problemas referentes à conservação da consistência dos dados distribuídos e descreve os benefícios e os compromissos dos diferentes modelos de consistência.
- Orientações sobre a Criação de Partições de Dados. A fragmentação de um arquivo de dados pode acarretar uma série de outros problemas. Descreve estes problemas relativos à criação de partições dos arquivos de dados na cloud para melhorar a escalabilidade, reduzir a disputa e otimizar o desempenho.
Recursos relacionados
Os seguintes padrões também podem ser relevantes ao implementar esse padrão:
- Padrão de Tabela de Índice. Por vezes, não é possível suportar totalmente as consultas apenas através da conceção da chave de partição horizontal. Permite que uma aplicação obtenha rapidamente os dados de um arquivo de dados grande ao especificar uma chave que não seja a chave de partição horizontal.
- Padrão de Vista Materializada. Para manter o desempenho de algumas operações de consulta, é útil criar vistas materializadas que agregam e resumem os dados, especialmente se estes dados de resumos forem baseados nas informações que são distribuídas pelas partições horizontais. Descreve como gerar e preencher estas vistas.