Permita que uma aplicação processe falhas transitórias quando tentar ligar a um recurso ou serviço de rede, ao repetir de forma transparente uma operação que falhou. Este procedimento pode melhorar a estabilidade da aplicação.
Contexto e problema
Uma aplicação que comunica com elementos em execução na cloud tem de ser sensível às falhas transitórias que podem ocorrer neste ambiente. As falhas incluem a perda momentânea de conectividade de rede para componentes e serviços, a indisponibilidade temporária de um serviço ou os tempos limite que ocorrem quando um serviço está ocupado.
Por norma, estas falhas corrigem-se automaticamente e, se a ação que acionou uma falha se repetir após um atraso adequado, é provável que seja concluída com sucesso. Por exemplo, um serviço de banco de dados que está processando um grande número de solicitações simultâneas pode implementar uma estratégia de limitação que rejeita temporariamente quaisquer outras solicitações até que sua carga de trabalho seja reduzida. Uma aplicação a tentar aceder à base de dados pode não conseguir estabelecer ligação, mas se tentar novamente, depois de um atraso, pode ser bem-sucedida.
Solução
Na nuvem, falhas transitórias devem ser esperadas e um aplicativo deve ser projetado para lidar com elas de forma elegante e transparente. Isso minimiza os efeitos que as falhas podem ter nas tarefas de negócios que o aplicativo está executando. O padrão de design mais comum a ser abordado é a introdução de um mecanismo de repetição.
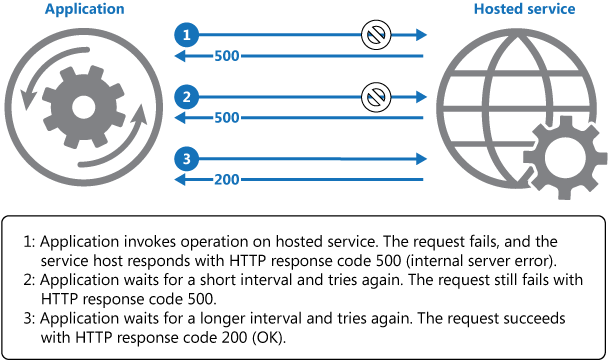
O diagrama acima ilustra a invocação de uma operação em um serviço hospedado usando um mecanismo de repetição. Se o pedido não for bem-sucedido após um número predefinido de tentativas, a aplicação deverá tratar a falha como uma exceção e processá-la em conformidade.
Nota
Devido à natureza comum de falhas transitórias, mecanismos de repetição integrados estão agora disponíveis em muitas bibliotecas de clientes e serviços de nuvem, com algum grau de configurabilidade para o número de tentativas máximas, o atraso entre as tentativas e outros parâmetros. O suporte interno de repetição para muitos serviços do Azure pode ser encontrado aqui e o Microsof Entity Framework fornece recursos para repetir operações de banco de dados com falha.
Estratégias de repetição
Se uma aplicação detetar uma falha ao tentar enviar um pedido para um serviço remoto, esta poderá lidar com a falha com recurso às seguintes estratégias:
Cancelar. Se a falha indicar que não é transitória ou que é pouco provável que seja bem-sucedida se repetida, a aplicação deverá cancelar a operação e comunicar uma exceção.
Tente novamente imediatamente. Se a falha específica relatada for incomum ou rara, como um pacote de rede corrompido enquanto estava sendo transmitido, o melhor curso de ação pode ser repetir imediatamente a solicitação.
Repetir após atraso. Se a falha for causada por uma das falhas de conectividade mais comuns ou ocupadas, a rede ou serviço pode precisar de um curto período enquanto os problemas de conectividade são corrigidos ou a lista de pendências de trabalho é limpa, portanto, atrasar programaticamente a repetição é uma boa estratégia. Em muitos casos, o período entre novas tentativas deve ser escolhido para distribuir as solicitações de várias instâncias do aplicativo da forma mais uniforme possível para reduzir a chance de um serviço ocupado continuar sobrecarregado.
Se o pedido continuar a falhar, a aplicação poderá aguardar e efetuar outra tentativa. Se necessário, este processo pode ser repetido com cada vez mais atrasos entre as tentativas de repetição, até que o número máximo de pedidos seja atingido. O atraso pode ser aumentado incrementalmente ou exponencialmente, dependendo do tipo de falha e a probabilidade de este ser corrigido durante este período.
A aplicação deve moldar todas as tentativas de acesso a um serviço remoto no código que implementa uma política de repetição correspondente a uma das estratégias listadas acima. Os pedidos enviados para diferentes serviços podem estar sujeitos a políticas diferentes.
Uma aplicação deve registar os detalhes das falhas e as operações com falhas. Estas informações são úteis para os operadores. Dito isto, a fim de evitar inundar os operadores com alertas sobre operações em que as tentativas subsequentes foram bem-sucedidas, é melhor registrar as falhas iniciais como entradas informativas e apenas a falha da última das tentativas de repetição como um erro real. Aqui está um exemplo de como esse modelo de log seria.
Se um serviço estiver frequentemente indisponível ou ocupado, isso poderá muitas vezes significar que o serviço esgotou os recursos. Pode reduzir a frequência destas falhas ao aumentar horizontalmente o serviço. Por exemplo, se um serviço de base de dados estiver continuamente sobrecarregado, poderá ser vantajoso dividir a base de dados em partições e distribuir a carga por vários servidores.
Problemas e considerações
Deve considerar os seguintes pontos ao decidir como implementar este padrão.
Impacto no desempenho
A política de repetição deve ser ajustada para corresponder aos requisitos comerciais da aplicação e à natureza da falha. Para algumas operações não críticas, é melhor falhar e adaptar-se depressa ao invés de repetir várias vezes e afetar o débito da aplicação. Por exemplo, em um aplicativo Web interativo que acessa um serviço remoto, é melhor falhar após um número menor de novas tentativas com apenas um pequeno atraso entre as tentativas e exibir uma mensagem adequada para o usuário (por exemplo, "tente novamente mais tarde"). Para uma aplicação de lote, pode ser mais adequado aumentar o número de tentativas de repetição com um atraso a aumentar exponencialmente entre tentativas.
Uma política de repetição agressiva com um atraso mínimo entre tentativas e um grande número de tentativas pode degradar ainda mais um serviço ocupado em execução perto ou no limite da capacidade. Esta política de repetição também poderá afetar a capacidade de resposta da aplicação se continuar a tentar realizar uma operação com falha.
Se um pedido continuar a falhar após um número significativo de tentativas, será melhor para a aplicação impedir futuros pedidos de acesso ao mesmo recurso e simplesmente comunicar uma falha. Quando o período expira, a aplicação pode permitir provisoriamente o envio de um ou mais pedidos para ver se forem bem-sucedidos. Para obter mais detalhes sobre esta estratégia, veja o Padrão Disjuntor Automático.
Idempotência
Considere se a operação é idempotente. Se for, é inerentemente seguro repetir. Caso contrário, as repetições podem fazer com que a operação seja executada mais do que uma vez, com efeitos secundários indesejados. Por exemplo, um serviço pode receber o pedido, processar o pedido com sucesso, mas falhar o envio de uma resposta. Nessa altura, a lógica de repetição pode reenviar o pedido, partindo do princípio de que o primeiro pedido não foi recebido.
Tipo de exceção
Um pedido para um serviço pode falhar por diversos motivos desencadeados por diferentes exceções, dependendo da natureza da falha. Algumas exceções indicam uma falha que pode ser resolvida rapidamente, enquanto outras indicam que a falha vai durar mais tempo. É útil para a política de repetição ajustar o tempo entre as tentativas de repetição com base no tipo de exceção.
Consistência da transação
Considere a forma como a repetição de uma operação que faz parte de uma transação vai afetar a consistência global da transação. Ajuste a política de repetição para operações transacionais para maximizar a hipótese de sucesso e reduzir a necessidade de anular todos os passos da transação.
Documentação de orientação geral
Confirme se todo o código de repetição foi inteiramente testado face a uma variedade de condições de falha. Verifique se não afeta gravemente o desempenho ou a fiabilidade da aplicação, provoca uma carga excessiva nos serviços e recursos ou gera condições race ou estrangulamentos.
Implemente a lógica de repetição apenas quando o contexto completo de uma operação com falha for compreendido. Por exemplo, se uma tarefa que contém uma política de repetição invocar outra tarefa que também contém uma política de repetição, esta camada adicional de tentativas poderá adicionar grandes atrasos ao processamento. Pode ser melhor configurar a tarefa de nível inferior para falhar e adaptar-se depressa e comunicar o motivo da falha à tarefa que a invocou. Esta tarefa de nível mais elevado pode, em seguida, processar a falha com base na sua própria política.
Registre todas as falhas de conectividade que causam uma nova tentativa para que problemas subjacentes com o aplicativo, serviços ou recursos possam ser identificados.
Investigue as falhas com a maior probabilidade de ocorrência num serviço ou recurso para descobrir a probabilidade de serem de longa duração ou terminais. Se forem, será melhor processar a falha como uma exceção. A aplicação pode comunicar ou registar a exceção e, em seguida, tentar continuar a invocar um serviço alternativo (se disponível) ou oferecer a funcionalidade degradada. Para obter mais informações sobre como detetar e processar falhas de longa duração, veja o Padrão Disjunto Automático.
Quando utilizar este padrão
Utilize este padrão se houver a possibilidade de uma aplicação experienciar falhas transitórias à medida que interage com um serviço remoto ou acede a um recurso remoto. Espera-se que estas falhas sejam de curta duração e que a repetição de um pedido que falhou anteriormente seja concluída com sucesso numa tentativa subsequente.
Este padrão pode não ser prático:
- Quando há uma probabilidade de uma falha ser de longa duração, uma vez que tal pode afetar a capacidade de resposta de uma aplicação. A aplicação pode estar a perder tempo e recursos ao tentar repetir um pedido que muito provavelmente vai falhar.
- Para o processamento de falhas que não se devem a falhas transitórias, tal como exceções internas causadas por erros na lógica de negócio de uma aplicação.
- Como alternativa para resolver problemas de escalabilidade num sistema. Se uma aplicação experienciar repetidas falhas de indisponibilidade, isso é sinal frequente de que o serviço ou o recurso a serem acedidos deverão ser aumentados verticalmente.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Retry pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Mitigar falhas transitórias em um sistema distribuído é uma técnica central para melhorar a resiliência de uma carga de trabalho. - RE:07 Autopreservação - RE:07 Falhas transitórias |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
Consulte o guia Implementar uma política de repetição com .NET para obter um exemplo detalhado usando o SDK do Azure com suporte interno ao mecanismo de repetição.
Próximos passos
Antes de escrever a lógica de repetição personalizada, considere o uso de uma estrutura geral, como Polly para .NET ou Resilience4j para Java.
Ao processar comandos que alteram dados comerciais, esteja ciente de que novas tentativas podem resultar na execução da ação duas vezes, o que pode ser problemático se essa ação for algo como cobrar o cartão de crédito de um cliente. Usar o padrão de idempotência descrito nesta postagem do blog pode ajudar a lidar com essas situações.
Recursos relacionados
O padrão de aplicativo Web confiável mostra como aplicar o padrão de repetição a aplicativos Web convergentes na nuvem.
Para a maioria dos serviços do Azure, os SDKs de cliente incluem lógica de repetição interna. Para obter mais informações, consulte Diretrizes de repetição para serviços do Azure.
Padrão Disjuntor Automático. No caso de prever uma falha de longa duração, poderá ser mais apropriado implementar o padrão Disjuntor Automático. A combinação dos padrões Retry e Circuit Breaker fornece uma abordagem abrangente para lidar com falhas.