O que é a Sincronização de Dados SQL para o Azure?
Aplica-se a:![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure
A Sincronização de Dados SQL é um serviço criado na Base de Dados SQL do Azure que lhe permite sincronizar os dados selecionados bidirecionalmente em várias bases de dados, tanto no local como na nuvem.
Importante
O Azure SQL Data Sync não oferece suporte à Instância Gerenciada SQL do Azure ou ao Azure Synapse Analytics no momento.
Descrição geral
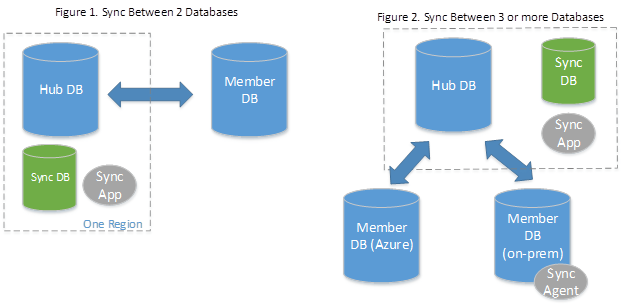
A sincronização de dados baseia-se no conceito de um grupo de sincronização. Um grupo de sincronização é um grupo de bancos de dados que você deseja sincronizar.
A Sincronização de Dados usa uma topologia de hub e spoke para sincronizar dados. Você define um dos bancos de dados no grupo de sincronização como o banco de dados do hub. O restante dos bancos de dados são bancos de dados membros. A sincronização ocorre apenas entre o hub e membros individuais.
- O Banco de Dados de Hub deve ser um Banco de Dados SQL do Azure.
- Os bancos de dados membros podem ser bancos de dados no Banco de Dados SQL do Azure ou em instâncias do SQL Server.
- O Banco de Dados de Metadados de Sincronização contém os metadados e o log para a Sincronização de Dados . O Banco de Dados de Metadados de Sincronização deve ser um Banco de Dados SQL do Azure localizado na mesma região do Banco de Dados de Hub. O banco de dados de metadados de sincronização é criado pelo cliente e de propriedade do cliente. Só pode ter uma Base de Dados de Metadados de Sincronização por região e subscrição. O Banco de Dados de Metadados de Sincronização não pode ser excluído ou renomeado enquanto existirem grupos de sincronização ou agentes de sincronização. A Microsoft recomenda a criação de um novo banco de dados vazio para uso como o Banco de Dados de Metadados de Sincronização. A Sincronização de Dados cria tabelas nesta base de dados e executa uma carga de trabalho frequente.
Nota
Se você estiver usando um banco de dados local como um banco de dados membro, será necessário instalar e configurar um agente de sincronização local.
Um grupo de sincronização tem as seguintes propriedades:
- O esquema de sincronização descreve quais dados estão sendo sincronizados.
- A direção de sincronização pode ser bidirecional ou pode fluir em apenas uma direção. Ou seja, a Direção de Sincronização pode ser Hub para Membro, ou Membro para Hub, ou ambos.
- O intervalo de sincronização descreve a frequência com que a sincronização ocorre.
- A Política de Resolução de Conflitos é uma política de nível de grupo, que pode ser Hub ganha ou Membro ganha.
Quando utilizar o
A Sincronização de Dados é útil nos casos em que os dados precisam ser mantidos atualizados em vários bancos de dados no Banco de Dados SQL do Azure ou no SQL Server. Aqui estão os principais casos de uso do Data Sync:
- Sincronização de Dados Híbrida: com a Sincronização de Dados, você pode manter os dados sincronizados entre seus bancos de dados no SQL Server e no Banco de Dados SQL do Azure para habilitar aplicativos híbridos. Esse recurso pode atrair clientes que estão pensando em migrar para a nuvem e gostariam de colocar parte de seus aplicativos no Azure.
- Aplicativos distribuídos: em muitos casos, é benéfico separar cargas de trabalho diferentes em bancos de dados diferentes. Por exemplo, se você tiver um grande banco de dados de produção, mas também precisar executar uma carga de trabalho de relatórios ou análises nesses dados, é útil ter um segundo banco de dados para essa carga de trabalho extra. Essa abordagem minimiza o impacto no desempenho da carga de trabalho de produção. Você pode usar a Sincronização de Dados para manter esses dois bancos de dados sincronizados.
- Aplicativos distribuídos globalmente: Muitas empresas abrangem várias regiões e até mesmo vários países/regiões. Para minimizar a latência da rede, é melhor ter seus dados em uma região próxima a você. Com o Data Sync, você pode facilmente manter sincronizados bancos de dados em regiões ao redor do mundo.
A Sincronização de Dados não é a solução preferida para os seguintes cenários:
| Cenário | Algumas soluções recomendadas |
|---|---|
| Recuperação após Desastre | Backups com redundância geográfica do Azure |
| Escala de leitura | Usar réplicas somente leitura para balancear a carga de trabalho de consulta somente leitura |
| ETL (OLTP para OLAP) | Azure Data Factory ou SQL Server Integration Services |
| Migração do SQL Server para o Banco de Dados SQL do Azure. No entanto, a Sincronização de Dados SQL pode ser usada após a conclusão da migração, para garantir que a origem e o destino sejam mantidos sincronizados. | Azure Database Migration Service |
Como funciona
- Controlar alterações de dados: a Sincronização de Dados controla as alterações usando gatilhos de inserção, atualização e exclusão. As alterações são registradas em uma tabela lateral no banco de dados do usuário. BULK INSERT não dispara gatilhos por padrão. Se FIRE_TRIGGERS não for especificado, nenhum gatilho de inserção será executado. Adicione a opção FIRE_TRIGGERS para que o Data Sync possa rastrear essas inserções.
- Sincronização de dados: o Data Sync foi projetado em um modelo de hub e spoke. O hub sincroniza com cada membro individualmente. As alterações do hub são baixadas para o membro e, em seguida, as alterações do membro são carregadas no hub.
- Resolução de conflitos: a Sincronização de Dados fornece duas opções para a resolução de conflitos, o Hub ganha ou o Membro ganha.
- Se você selecionar Hub vence, as alterações no hub sempre substituirão as alterações no membro.
- Se você selecionar Membro ganha, as alterações no membro substituirão as alterações no hub. Se houver mais de um membro, o valor final depende de qual membro sincroniza primeiro.
Compare com a replicação transacional
| Sincronização de Dados | Replicação Transacional | |
|---|---|---|
| Vantagens | - Suporte ativo-ativo - Bidirecional entre o local e o Banco de Dados SQL do Azure |
- Menor latência - Consistência transacional - Reutilizar topologia existente após a migração -Suporte à Instância Gerenciada SQL do Azure |
| Desvantagens | - Sem consistência transacional - Maior impacto no desempenho |
- Não é possível publicar a partir da Base de Dados SQL do Azure - Alto custo de manutenção |
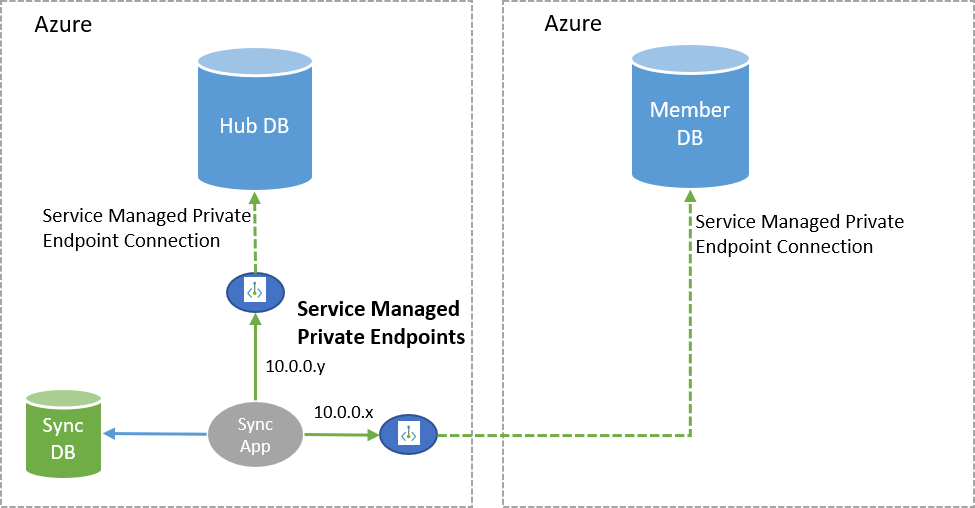
Link privado para sincronização de dados
Nota
O link privado da Sincronização de Dados SQL é diferente do Link Privado do Azure.
O novo recurso de link privado permite que você escolha um ponto de extremidade privado gerenciado pelo serviço para estabelecer uma conexão segura entre o serviço de sincronização e seus bancos de dados de membro/hub durante o processo de sincronização de dados. Um ponto final privado gerido pelo serviço é um endereço IP privado numa rede virtual e sub-rede específicas. No Data Sync, o ponto de extremidade privado gerenciado pelo serviço é criado pela Microsoft e usado exclusivamente pelo serviço Data Sync para uma determinada operação de sincronização.
Antes de configurar o link privado, leia os requisitos gerais para o recurso.
Nota
Você deve aprovar manualmente o ponto de extremidade privado gerenciado pelo serviço na página Conexões de ponto de extremidade privado do portal do Azure durante a implantação do grupo de sincronização ou usando o PowerShell.
Começar
Configurar a Sincronização de Dados no portal do Azure
- Configurar a Sincronização de Dados SQL do Azure
- Agente de Sincronização de Dados - Agente de Sincronização de Dados para Sincronização de Dados SQL do Azure
Configurar a sincronização de dados com o PowerShell
- Usar o PowerShell para sincronizar entre vários bancos de dados no Banco de Dados SQL do Azure
- Usar o PowerShell para sincronizar entre um banco de dados no Banco de Dados SQL do Azure e um banco de dados em uma instância do SQL Server
Configurar a sincronização de dados com a API REST
Analise as práticas recomendadas para a sincronização de dados
Algo correu mal
Consistência e desempenho
Consistência eventual
Como a sincronização de dados é baseada em gatilhos, a consistência transacional não é garantida. A Microsoft garante que todas as alterações são feitas eventualmente e que a Sincronização de Dados não causa perda de dados.
Impacto no desempenho
A Sincronização de Dados usa gatilhos de inserção, atualização e exclusão para controlar alterações. Ele cria tabelas laterais no banco de dados do usuário para controle de alterações. Essas atividades de controle de alterações têm impacto na carga de trabalho do banco de dados. Avalie sua camada de serviço e atualize, se necessário.
O provisionamento e o desprovisionamento durante a criação, atualização e exclusão do grupo de sincronização também podem afetar o desempenho do banco de dados.
Requisitos e limitações
Requisitos gerais
- Cada tabela deve ter uma chave primária. Não altere o valor da chave primária em nenhuma linha. Se você precisar alterar um valor de chave primária, exclua a linha e recrie-a com o novo valor de chave primária.
Importante
Alterar o valor de uma chave primária existente resultará no seguinte comportamento defeituoso:
- Os dados entre o hub e o membro podem ser perdidos mesmo que a sincronização não relate nenhum problema.
- A sincronização pode falhar porque a tabela de acompanhamento tem uma linha inexistente da origem devido à alteração da chave primária.
O isolamento de instantâneo deve ser habilitado para membros do Sync e hub. Para obter mais informações, veja Snapshot Isolation in SQL Server (Isolamento de Instantâneo no SQL Server).
Para usar o link privado do Data Sync, os bancos de dados de membro e hub devem ser hospedados no Azure (mesmas regiões ou regiões diferentes), no mesmo tipo de nuvem (por exemplo, ambos na nuvem pública ou ambos na nuvem governamental). Além disso, para usar o link privado,
Microsoft.Networkos provedores de recursos devem estar registrados para as assinaturas que hospedam o hub e os servidores membros. Por fim, você deve aprovar manualmente o link privado para a Sincronização de Dados durante a configuração de sincronização, na seção "Conexões de ponto de extremidade privadas" no portal do Azure ou por meio do PowerShell. Para obter mais informações sobre como aprovar o link privado, consulte Configurar a sincronização de dados SQL. Depois de aprovar o ponto de extremidade privado gerenciado pelo serviço, toda a comunicação entre o serviço de sincronização e os bancos de dados de membro/hub acontece pelo link privado. Os grupos de sincronização existentes podem ser atualizados para que esse recurso seja habilitado.
Limitações gerais
- Uma tabela não pode ter uma coluna de identidade que não seja a chave primária.
- Uma chave primária não pode ter os seguintes tipos de dados: sql_variant, binário, varbinário, imagem, xml.
- Tenha cuidado ao utilizar os seguintes tipos de dados como chave primária, porque a precisão suportada é apenas para a segunda: hora, datetime, datetime2, datetimeoffset.
- Os nomes de objetos (bases de dados, tabelas e colunas) não podem conter carateres imprimíveis, tal como ponto final (
.), parêntese reto esquerdo ([) ou parêntese reto direito (]). - Um nome de tabela não pode conter carateres imprimíveis:
! " # $ % ' ( ) * + -ou espaço. - A autenticação do Microsoft Entra (anteriormente Azure Ative Directory) não é suportada.
- Se existirem tabelas com o mesmo nome, mas esquema diferente (por exemplo,
dbo.customersesales.customers), apenas uma das tabelas pode ser adicionada em sincronização. - As colunas com tipos de dados definidos pelo utilizador não são suportadas.
- A movimentação de servidores entre subscrições diferentes não é suportada.
- Se duas chaves primárias forem apenas diferentes nas maiúsculas e minúscula (por exemplo,
Fooefoo), a Sincronização de Dados não suportará este cenário. - Truncar tabelas não é uma operação suportada pela Sincronização de Dados (as alterações não serão controladas).
- Não há suporte para o uso de um banco de dados SQL Hyperscale do Azure como um banco de dados de Metadados de Hub ou Sincronização. No entanto, uma base de dados Hyperscale pode ser uma base de dados membro numa topologia de Sincronização de Dados.
- Não há suporte para tabelas com otimização de memória.
- As alterações de esquema não são replicadas automaticamente. Pode criar uma solução personalizada para automatizar a replicação de alterações de esquema.
- A Sincronização de Dados suporta apenas as duas seguintes propriedades de índice: Exclusivo, Agrupado/Não Agrupado. Outras propriedades de um índice, como IGNORE_DUP_KEY ou o predicado de filtro WHERE, não são suportadas e o índice de destino é provisionado sem essas propriedades, mesmo que o índice de origem tenha essas propriedades definidas.
- Um banco de dados de trabalhos elásticos do Azure não pode ser usado como o banco de dados de metadados da Sincronização de Dados SQL e vice-versa.
- Não há suporte para a Sincronização de Dados SQL para bancos de dados contábeis.
Tipos de dados não suportados
- FileStream
- SQL/CLR UDT
- XMLSchemaCollection (XML suportado)
- Cursor, RowVersion, Timestamp, Hierarchyid
Tipos de coluna não suportados
A Sincronização de Dados não pode sincronizar colunas somente leitura ou geradas pelo sistema. Por exemplo:
- Colunas computadas.
- Colunas geradas pelo sistema para tabelas temporais.
Limitações nas dimensões do serviço e do banco de dados
| Dimensões | Limite | Solução |
|---|---|---|
| Número máximo de grupos de sincronização aos quais qualquer banco de dados pode pertencer. | 5 | |
| Número máximo de pontos de extremidade em um único grupo de sincronização | 30 | |
| Número máximo de pontos de extremidade locais em um único grupo de sincronização. | 5 | Criar vários grupos de sincronização |
| Nomes de banco de dados, tabela, esquema e coluna | 50 caracteres por nome | |
| Tabelas em um grupo de sincronização | 500 | Criar vários grupos de sincronização |
| Colunas em uma tabela em um grupo de sincronização | 1000 | |
| Tamanho da linha de dados em uma tabela | 24 Mb |
Nota
Pode haver até 30 pontos de extremidade em um único grupo de sincronização se houver apenas um grupo de sincronização. Se houver mais de um grupo de sincronização, o número total de pontos de extremidade em todos os grupos de sincronização não poderá exceder 30. Se um banco de dados pertencer a vários grupos de sincronização, ele será contado como vários pontos de extremidade, não um.
Requisitos de rede
Nota
Se você usar o link privado de sincronização, esses requisitos de rede não se aplicam.
Quando o grupo de sincronização é estabelecido, o serviço de Sincronização de Dados precisa se conectar ao banco de dados do hub. Ao estabelecer o grupo de sincronização, o servidor SQL do Azure deve ter a seguinte configuração em suas Firewalls and virtual networks configurações:
- Negar acesso à rede pública deve ser definido como Desativado.
- Permitir que os serviços e recursos do Azure acessem esse servidor deve ser definido como Sim ou você deve criar regras IP para os endereços IP usados pelo serviço de Sincronização de Dados.
Depois que o grupo de sincronização for criado e provisionado, você poderá desativar essas configurações. O agente de sincronização se conecta diretamente ao banco de dados do hub e você pode usar as regras IP do firewall do servidor ou pontos de extremidade privados para permitir que o agente acesse o servidor do hub.
Nota
Se você alterar as configurações de esquema do grupo de sincronização, precisará permitir que o serviço de Sincronização de Dados acesse o servidor novamente para que o banco de dados do hub possa ser reprovisionado.
Residência de dados da região
Se você sincronizar dados dentro da mesma região, a Sincronização de Dados SQL não armazenará/processará dados do cliente fora dessa região na qual a instância de serviço está implantada. Se você sincronizar dados entre regiões diferentes, a Sincronização de Dados SQL replicará os dados do cliente para as regiões emparelhadas.
Perguntas frequentes sobre o SQL Data Sync
Quanto custa o serviço SQL Data Sync?
Não há cobrança para o serviço SQL Data Sync em si. No entanto, você ainda coleta cobranças de transferência de dados para movimentação de dados dentro e fora de sua instância do Banco de dados SQL. Para obter mais informações, consulte Taxas de transferência de dados.
Quais regiões oferecem suporte ao Data Sync?
A Sincronização de Dados SQL está disponível em todas as regiões.
É necessária uma conta da Base de Dados SQL?
Sim. Você deve ter uma conta do Banco de dados SQL para hospedar o banco de dados do hub.
Posso usar a Sincronização de Dados para sincronizar apenas entre bancos de dados do SQL Server?
Não diretamente. No entanto, você pode sincronizar entre bancos de dados do SQL Server indiretamente, criando um banco de dados de Hub no Azure e, em seguida, adicionando os bancos de dados locais ao grupo de sincronização.
Posso configurar a Sincronização de Dados para sincronizar entre bancos de dados no Banco de Dados SQL do Azure que pertencem a assinaturas diferentes?
Sim. Você pode configurar a sincronização entre bancos de dados que pertencem a grupos de recursos pertencentes a assinaturas diferentes, mesmo que as assinaturas pertençam a locatários diferentes.
- Se as assinaturas pertencerem ao mesmo locatário e você tiver permissão para todas as assinaturas, poderá configurar o grupo de sincronização no portal do Azure.
- Caso contrário, você terá que usar o PowerShell para adicionar os membros de sincronização.
Posso configurar a Sincronização de Dados para sincronizar entre bancos de dados no Banco de Dados SQL que pertencem a nuvens diferentes (como a Nuvem Pública do Azure e o Azure operado pela 21Vianet)?
Sim. Você pode configurar a sincronização entre bancos de dados que pertencem a nuvens diferentes. Você precisa usar o PowerShell para adicionar os membros de sincronização que pertencem às diferentes assinaturas.
Posso usar a Sincronização de Dados para semear dados do meu banco de dados de produção em um banco de dados vazio e, em seguida, sincronizá-los?
Sim. Crie o esquema manualmente no novo banco de dados criando scripts a partir do original. Depois de criar o esquema, adicione as tabelas a um grupo de sincronização para copiar os dados e mantê-los sincronizados.
Devo usar a Sincronização de Dados SQL para fazer backup e restaurar meus bancos de dados?
Não é recomendável usar o SQL Data Sync para criar um backup de seus dados. Não é possível fazer backup e restaurar para um ponto específico no tempo porque as sincronizações do SQL Data Sync não são versionadas. Além disso, a Sincronização de Dados SQL não faz backup de outros objetos SQL, como procedimentos armazenados, e não faz o equivalente a uma operação de restauração rapidamente.
Para obter uma técnica de backup recomendada, consulte Copiar um banco de dados no Banco de Dados SQL do Azure.
O Data Sync pode sincronizar tabelas e colunas criptografadas?
- Se um banco de dados usar Always Encrypted, você poderá sincronizar somente as tabelas e colunas que não estão criptografadas. Não é possível sincronizar as colunas criptografadas, porque a Sincronização de Dados não pode descriptografar os dados.
- Se uma coluna usar CLE (Criptografia no Nível de Coluna), você poderá sincronizá-la, desde que o tamanho da linha seja menor que o tamanho máximo de 24 Mb. A Sincronização de Dados trata a coluna criptografada por chave (CLE) como dados binários normais. Para descriptografar os dados em outros membros da sincronização, você precisa ter o mesmo certificado.
Há suporte para agrupamento no SQL Data Sync?
Sim. A Sincronização de Dados SQL dá suporte à definição de configurações de agrupamento nos seguintes cenários:
- Se as tabelas de esquema de sincronização selecionadas ainda não estiverem em seu hub ou bancos de dados de membros, quando você implantar o grupo de sincronização, o serviço criará automaticamente as tabelas e colunas correspondentes com as configurações de agrupamento selecionadas nos bancos de dados de destino vazios.
- Se as tabelas a serem sincronizadas já existirem em seus bancos de dados de hub e membro, a Sincronização de Dados SQL exigirá que as colunas de chave primária tenham o mesmo agrupamento entre bancos de dados de hub e membro para implantar com êxito o grupo de sincronização. Não há restrições de agrupamento em colunas que não sejam as colunas de chave primária.
Há suporte para federação no SQL Data Sync?
O Banco de Dados Raiz de Federação pode ser usado no Serviço de Sincronização de Dados SQL sem qualquer limitação. Não é possível adicionar o ponto de extremidade do Banco de Dados Federado à versão atual do SQL Data Sync.
Posso usar a Sincronização de Dados para sincronizar dados exportados do Dynamics 365 usando o recurso traga seu próprio banco de dados (BYOD)?
O recurso Dynamics 365 traz seu próprio recurso de banco de dados permite que os administradores exportem entidades de dados do aplicativo para seu próprio banco de dados SQL do Microsoft Azure. A Sincronização de Dados pode ser usada para sincronizar esses dados em outros bancos de dados se os dados forem exportados usando push incremental (envio completo não é suportado) e habilitar gatilhos no banco de dados de destino estiver definido como sim.
Como faço para criar a Sincronização de Dados no grupo de Failover para dar suporte à Recuperação de Desastres?
- Para garantir que as operações de sincronização de dados na região de failover estejam no mesmo nível da região Primária, após o failover, você precisa recriar manualmente o Grupo de Sincronização na região de failover com as mesmas configurações da região primária.
Próximos passos
Atualizar o esquema de um banco de dados sincronizado
É necessário atualizar o esquema de um banco de dados em um grupo de sincronização? As alterações de esquema não são replicadas automaticamente. Para algumas soluções, consulte os seguintes artigos:
- Automatize a replicação de alterações de esquema com a Sincronização de Dados SQL no Azure
- Usar o PowerShell para atualizar o esquema de sincronização em um grupo de sincronização existente
Monitorizar e resolver problemas
O SQL Data Sync está funcionando conforme o esperado? Para monitorar a atividade e solucionar problemas, consulte os seguintes artigos:
- Monitorizar Sincronização de Dados SQL com os registos do Azure Monitor
- Resolver problemas da Sincronização de Dados SQL do Azure
Saiba mais sobre a Base de Dados SQL do Azure
Para obter mais informações sobre o Banco de Dados SQL do Azure, consulte os seguintes artigos: