Copiar e transformar dados no Armazenamento de Blobs do Azure usando o Azure Data Factory ou o Azure Synapse Analytics
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a atividade Copiar no Azure Data Factory e nos pipelines do Azure Synapse para copiar dados de e para o Armazenamento de Blobs do Azure. Ele também descreve como usar a atividade de Fluxo de Dados para transformar dados no Armazenamento de Blobs do Azure. Para saber mais, leia os artigos de introdução do Azure Data Factory e do Azure Synapse Analytics .
Gorjeta
Para saber mais sobre um cenário de migração para um data lake ou um data warehouse, consulte o artigo Migrar dados do seu data lake ou data warehouse para o Azure.
Capacidades suportadas
Este conector de Armazenamento de Blob do Azure tem suporte para os seguintes recursos:
| Capacidades suportadas | IR | Ponto final privado gerido |
|---|---|---|
| Atividade de cópia (origem/coletor) | (1) (2) | ✓ Excluir conta de armazenamento V1 |
| Mapeando o fluxo de dados (origem/coletor) | (1) | ✓ Excluir conta de armazenamento V1 |
| Atividade de Pesquisa | (1) (2) | ✓ Excluir conta de armazenamento V1 |
| Atividade GetMetadata | (1) (2) | ✓ Excluir conta de armazenamento V1 |
| Excluir atividade | (1) (2) | ✓ Excluir conta de armazenamento V1 |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para a atividade Copiar, este conector de armazenamento de Blob suporta:
- Copiar blobs de e para contas de armazenamento do Azure de uso geral e armazenamento de blob quente/legal.
- Copiar blobs usando uma chave de conta, uma assinatura de acesso compartilhado (SAS) de serviço, uma entidade de serviço ou identidades gerenciadas para autenticações de recursos do Azure.
- Copiar blobs de bloco, acrescentar ou blobs de página e copiar dados para apenas blobs de bloco.
- Copiar blobs como estão, ou analisar ou gerar blobs com formatos de arquivo suportados e codecs de compressão.
- Preservando metadados de arquivo durante a cópia.
Começar agora
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
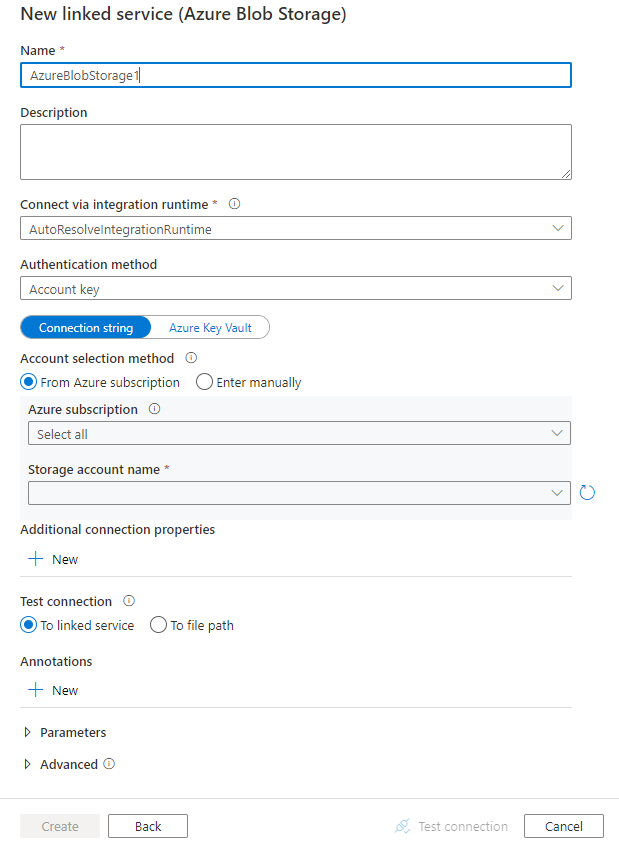
Criar um serviço vinculado do Armazenamento de Blobs do Azure usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado de Armazenamento de Blob do Azure na interface do usuário do portal do Azure.
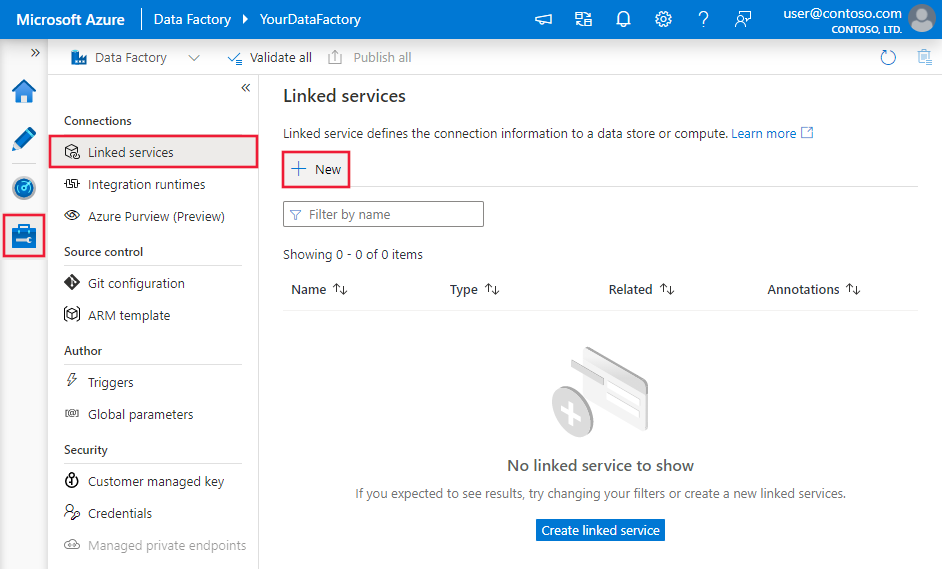
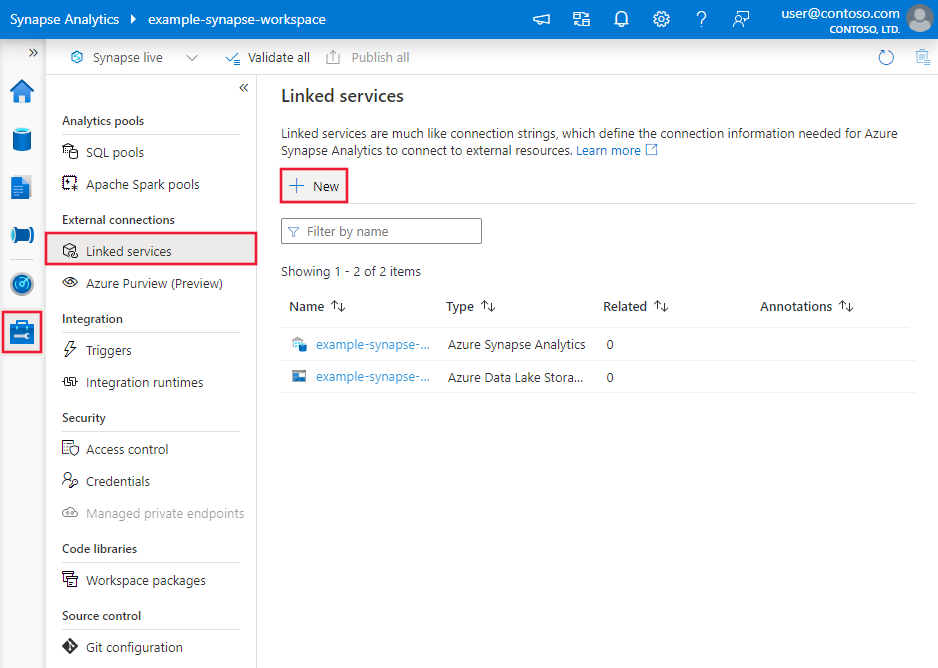
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e, em seguida, selecione Novo:
Procure blob e selecione o conector de Armazenamento de Blob do Azure.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades de pipeline do Data Factory e do Synapse específicas para o armazenamento de Blob.
Propriedades do serviço vinculado
Este conector de armazenamento de Blob suporta os seguintes tipos de autenticação. Consulte as seções correspondentes para obter detalhes.
- Autenticação anónima
- Autenticação da chave de conta
- Autenticação de assinatura de acesso compartilhado
- Autenticação do principal de serviço
- Autenticação de identidade gerenciada atribuída pelo sistema
- Autenticação de identidade gerenciada atribuída pelo usuário
Nota
- Se quiser usar o tempo de execução de integração público do Azure para se conectar ao seu armazenamento de Blob aproveitando a opção Permitir que serviços confiáveis da Microsoft acessem essa conta de armazenamento habilitada no firewall do Armazenamento do Azure, você deverá usar a autenticação de identidade gerenciada. Para obter mais informações sobre as configurações de firewalls do Armazenamento do Azure, consulte Configurar firewalls do Armazenamento do Azure e redes virtuais.
- Quando você usa a instrução PolyBase ou COPY para carregar dados no Azure Synapse Analytics, se o armazenamento de Blob de origem ou de preparo estiver configurado com um ponto de extremidade da Rede Virtual do Azure, você deverá usar a autenticação de identidade gerenciada conforme exigido pelo Azure Synapse. Consulte a seção Autenticação de identidade gerenciada para obter mais pré-requisitos de configuração.
Nota
O Azure HDInsight e as atividades do Azure Machine Learning dão suporte apenas à autenticação que usa chaves de conta do Armazenamento de Blob do Azure.
Autenticação anónima
As seguintes propriedades são suportadas para autenticação de chave de conta de armazenamento no Azure Data Factory ou pipelines Synapse:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade deve ser definida como AzureBlobStorage (sugerida) ou AzureStorage (veja as notas a seguir). |
Sim |
| containerUri | Especifique o URI do contêiner de Blob do Azure que habilitou o acesso de leitura anônimo usando esse formato https://<AccountName>.blob.core.windows.net/<ContainerName> e Configurar o acesso de leitura público anônimo para contêineres e blobs |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureBlobStorageAnonymous",
"properties": {
"annotations": [],
"type": "AzureBlobStorage",
"typeProperties": {
"containerUri": "https:// <accountname>.blob.core.windows.net/ <containername>",
"authenticationType": "Anonymous"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
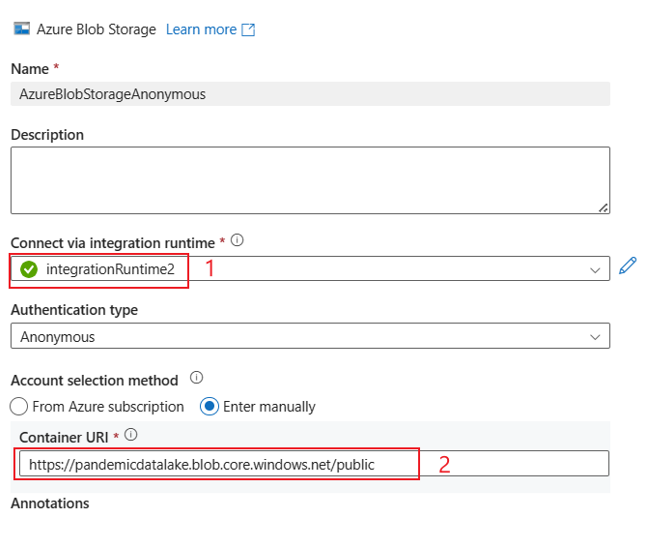
Exemplos de UI:
A experiência da interface do usuário é a descrita na imagem a seguir. Este exemplo usa o conjunto de dados aberto do Azure como a origem. Se você quiser obter o conjunto de dados aberto bing_covid-19_data.csv, basta escolher Tipo de autenticação como Anônimo e preencher o URI do contêiner com https://pandemicdatalake.blob.core.windows.net/public.
Autenticação da chave de conta
As seguintes propriedades são suportadas para autenticação de chave de conta de armazenamento no Azure Data Factory ou pipelines Synapse:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade deve ser definida como AzureBlobStorage (sugerida) ou AzureStorage (veja as notas a seguir). |
Sim |
| connectionString | Especifique as informações necessárias para se conectar ao Armazenamento para a connectionString propriedade. Você também pode colocar a chave da conta no Cofre da Chave do Azure e extrair a accountKey configuração da cadeia de conexão. Para obter mais informações, consulte os exemplos a seguir e o artigo Armazenar credenciais no Cofre de Chaves do Azure. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Nota
Um ponto de extremidade de serviço Blob secundário não é suportado quando você está usando a autenticação de chave de conta. Você pode usar outros tipos de autenticação.
Nota
Se você estiver usando o AzureStorage tipo de serviço vinculado, ele ainda é suportado como está. Mas sugerimos que você use o novo AzureBlobStorage tipo de serviço vinculado no futuro.
Exemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;AccountKey=<accountkey>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar a chave da conta no Cofre da Chave do Azure
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=<accountname>;",
"accountKey": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de assinatura de acesso compartilhado
Uma assinatura de acesso compartilhado fornece acesso delegado aos recursos em sua conta de armazenamento. Você pode usar uma assinatura de acesso compartilhado para conceder a um cliente permissões limitadas para objetos em sua conta de armazenamento por um tempo especificado.
Não tem de partilhar as chaves de acesso da sua conta. A assinatura de acesso compartilhado é um URI que engloba em seus parâmetros de consulta todas as informações necessárias para o acesso autenticado a um recurso de armazenamento. Para acessar recursos de armazenamento com a assinatura de acesso compartilhado, o cliente só precisa passar a assinatura de acesso compartilhado para o construtor ou método apropriado.
Para obter mais informações sobre assinaturas de acesso compartilhado, consulte Assinaturas de acesso compartilhado: entenda o modelo de assinatura de acesso compartilhado.
Nota
- O serviço agora suporta assinaturas de acesso compartilhado de serviço e assinaturas de acesso compartilhado de conta. Para obter mais informações sobre assinaturas de acesso compartilhado, consulte Conceder acesso limitado aos recursos do Armazenamento do Azure usando assinaturas de acesso compartilhado.
- Em configurações posteriores de conjunto de dados, o caminho da pasta é o caminho absoluto a partir do nível do contêiner. Você precisa configurar um alinhado com o caminho em seu URI SAS.
As seguintes propriedades são suportadas para usar a autenticação de assinatura de acesso compartilhado:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade deve ser definida como AzureBlobStorage (sugerida) ou AzureStorage (veja a nota a seguir). |
Sim |
| sasUri | Especifique o URI da assinatura de acesso compartilhado para os recursos de armazenamento, como blob ou contêiner. Marque este campo como SecureString para armazená-lo com segurança. Você também pode colocar o token SAS no Cofre da Chave do Azure para usar a rotação automática e remover a parte do token. Para obter mais informações, consulte os seguintes exemplos e Armazenar credenciais no Azure Key Vault. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Nota
Se você estiver usando o AzureStorage tipo de serviço vinculado, ele ainda é suportado como está. Mas sugerimos que você use o novo AzureBlobStorage tipo de serviço vinculado no futuro.
Exemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource e.g. https://<accountname>.blob.core.windows.net/?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar a chave da conta no Cofre da Chave do Azure
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"sasUri": {
"type": "SecureString",
"value": "<SAS URI of the Azure Storage resource without token e.g. https://<accountname>.blob.core.windows.net/>"
},
"sasToken": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName with value of SAS token e.g. ?sv=<storage version>&st=<start time>&se=<expire time>&sr=<resource>&sp=<permissions>&sip=<ip range>&spr=<protocol>&sig=<signature>>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Ao criar um URI de assinatura de acesso compartilhado, considere os seguintes pontos:
- Defina permissões de leitura/gravação apropriadas em objetos com base em como o serviço vinculado (leitura, gravação, leitura/gravação) é usado.
- Defina o tempo de expiração adequadamente. Certifique-se de que o acesso aos objetos de armazenamento não expire dentro do período ativo do pipeline.
- O URI deve ser criado no contêiner ou blob certo com base na necessidade. Um URI de assinatura de acesso compartilhado a um blob permite que o data factory ou o pipeline Synapse acesse esse blob específico. Um URI de assinatura de acesso compartilhado a um contêiner de armazenamento de Blob permite que o data factory ou o pipeline Synapse itere através de blobs nesse contêiner. Para fornecer acesso a mais ou menos objetos posteriormente, ou para atualizar o URI da assinatura de acesso compartilhado, lembre-se de atualizar o serviço vinculado com o novo URI.
Autenticação do principal de serviço
Para obter informações gerais sobre a autenticação principal do serviço de Armazenamento do Azure, consulte Autenticar o acesso ao Armazenamento do Azure usando a ID do Microsoft Entra.
Para usar a autenticação da entidade de serviço, siga estas etapas:
Registre um aplicativo com a plataforma de identidade da Microsoft. Para saber como, consulte Guia de início rápido: registrar um aplicativo com a plataforma de identidade da Microsoft. Anote estes valores, que você usa para definir o serviço vinculado:
- ID da aplicação
- Chave de aplicação
- ID de Inquilino do
Conceda à entidade de serviço a permissão adequada no Armazenamento de Blobs do Azure. Para obter mais informações sobre as funções, consulte Usar o portal do Azure para atribuir uma função do Azure para acesso a dados de blob e fila.
- Como origem, no Controle de acesso (IAM), conceda pelo menos a função de Leitor de Dados de Blob de Armazenamento .
- Como coletor, no Controle de acesso (IAM), conceda pelo menos a função de Colaborador de Dados de Blob de Armazenamento .
Estas propriedades têm suporte para um serviço vinculado do Armazenamento de Blobs do Azure:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureBlobStorage. | Sim |
| serviceEndpoint | Especifique o ponto de extremidade do serviço de Armazenamento de Blobs do Azure com o padrão .https://<accountName>.blob.core.windows.net/ |
Sim |
| accountKind | Especifique o tipo de sua conta de armazenamento. Os valores permitidos são: Storage (general purpose v1), StorageV2 (general purpose v2), BlobStorage ou BlockBlobStorage. Ao usar o serviço vinculado de Blob do Azure no fluxo de dados, a identidade gerenciada ou a autenticação da entidade de serviço não é suportada quando o tipo de conta está vazio ou "Armazenamento". Especifique o tipo de conta adequado, escolha uma autenticação diferente ou atualize sua conta de armazenamento para fins gerais v2. |
Não |
| servicePrincipalId | Especifique o ID do cliente do aplicativo. | Sim |
| servicePrincipalCredentialType | O tipo de credencial a ser usado para autenticação da entidade de serviço. Os valores permitidos são ServicePrincipalKey e ServicePrincipalCert. | Sim |
| servicePrincipalCredential | A credencial da entidade de serviço. Ao usar ServicePrincipalKey como o tipo de credencial, especifique a chave do aplicativo. Marque este campo como SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. Ao usar ServicePrincipalCert como credencial, faça referência a um certificado no Cofre da Chave do Azure e verifique se o tipo de conteúdo do certificado é PKCS #12. |
Sim |
| inquilino | Especifique as informações do locatário (nome de domínio ou ID do locatário) sob as quais seu aplicativo reside. Recupere-o passando o mouse sobre o canto superior direito do portal do Azure. | Sim |
| azureCloudType | Para autenticação da entidade de serviço, especifique o tipo de ambiente de nuvem do Azure, no qual seu aplicativo Microsoft Entra está registrado. Os valores permitidos são AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Por padrão, a fábrica de dados ou o ambiente de nuvem do pipeline Synapse é usado. |
Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Nota
- Se sua conta de blob habilitar a exclusão suave, a autenticação da entidade de serviço não será suportada no Fluxo de Dados.
- Se você acessar o armazenamento de blob por meio de ponto de extremidade privado usando o Fluxo de Dados, observe quando a autenticação da entidade de serviço é usada, o Fluxo de Dados se conecta ao ponto de extremidade ADLS Gen2 em vez do ponto de extremidade Blob. Certifique-se de criar o ponto de extremidade privado correspondente em seu data factory ou espaço de trabalho Synapse para habilitar o acesso.
Nota
A autenticação da entidade de serviço é suportada apenas pelo serviço vinculado do tipo "AzureBlobStorage", não pelo serviço vinculado do tipo "AzureStorage" anterior.
Exemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"type": "SecureString",
"value": "<service principal key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo sistema
Uma fábrica de dados ou pipeline Synapse pode ser associado a uma identidade gerenciada atribuída pelo sistema para recursos do Azure, que representa esse recurso para autenticação em outros serviços do Azure. Você pode usar diretamente essa identidade gerenciada atribuída ao sistema para autenticação de armazenamento de Blob, que é semelhante ao uso de sua própria entidade de serviço. Ele permite que esse recurso designado acesse e copie dados de ou para o armazenamento de Blob. Para saber mais sobre identidades gerenciadas para recursos do Azure, consulte Identidades gerenciadas para recursos do Azure
Para obter informações gerais sobre a autenticação do Armazenamento do Azure, consulte Autenticar o acesso ao Armazenamento do Azure usando a ID do Microsoft Entra. Para usar identidades gerenciadas para autenticação de recursos do Azure, siga estas etapas:
Recupere informações de identidade gerenciada atribuídas pelo sistema copiando o valor do ID do objeto de identidade gerenciado atribuído pelo sistema gerado junto com sua fábrica ou espaço de trabalho Sinapse.
Conceda a permissão de identidade gerenciada no Armazenamento de Blobs do Azure. Para obter mais informações sobre as funções, consulte Usar o portal do Azure para atribuir uma função do Azure para acesso a dados de blob e fila.
- Como origem, no Controle de acesso (IAM), conceda pelo menos a função de Leitor de Dados de Blob de Armazenamento .
- Como coletor, no Controle de acesso (IAM), conceda pelo menos a função de Colaborador de Dados de Blob de Armazenamento .
Estas propriedades têm suporte para um serviço vinculado do Armazenamento de Blobs do Azure:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureBlobStorage. | Sim |
| serviceEndpoint | Especifique o ponto de extremidade do serviço de Armazenamento de Blobs do Azure com o padrão .https://<accountName>.blob.core.windows.net/ |
Sim |
| accountKind | Especifique o tipo de sua conta de armazenamento. Os valores permitidos são: Storage (general purpose v1), StorageV2 (general purpose v2), BlobStorage ou BlockBlobStorage. Ao usar o serviço vinculado de Blob do Azure no fluxo de dados, a identidade gerenciada ou a autenticação da entidade de serviço não é suportada quando o tipo de conta está vazio ou "Armazenamento". Especifique o tipo de conta adequado, escolha uma autenticação diferente ou atualize sua conta de armazenamento para fins gerais v2. |
Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo usuário
Uma fábrica de dados pode ser atribuída com uma ou várias identidades gerenciadas atribuídas pelo usuário. Você pode usar essa identidade gerenciada atribuída pelo usuário para autenticação de armazenamento de Blob, que permite acessar e copiar dados de ou para o armazenamento de Blob. Para saber mais sobre identidades gerenciadas para recursos do Azure, consulte Identidades gerenciadas para recursos do Azure
Para obter informações gerais sobre a autenticação de armazenamento do Azure, consulte Autenticar o acesso ao Armazenamento do Azure usando a ID do Microsoft Entra. Para usar a autenticação de identidade gerenciada atribuída pelo usuário, siga estas etapas:
Crie uma ou várias identidades gerenciadas atribuídas pelo usuário e conceda permissão no Armazenamento de Blobs do Azure. Para obter mais informações sobre as funções, consulte Usar o portal do Azure para atribuir uma função do Azure para acesso a dados de blob e fila.
- Como origem, no Controle de acesso (IAM), conceda pelo menos a função de Leitor de Dados de Blob de Armazenamento .
- Como coletor, no Controle de acesso (IAM), conceda pelo menos a função de Colaborador de Dados de Blob de Armazenamento .
Atribua uma ou várias identidades gerenciadas atribuídas pelo usuário ao seu data factory e crie credenciais para cada identidade gerenciada atribuída pelo usuário.
Estas propriedades têm suporte para um serviço vinculado do Armazenamento de Blobs do Azure:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureBlobStorage. | Sim |
| serviceEndpoint | Especifique o ponto de extremidade do serviço de Armazenamento de Blobs do Azure com o padrão .https://<accountName>.blob.core.windows.net/ |
Sim |
| accountKind | Especifique o tipo de sua conta de armazenamento. Os valores permitidos são: Storage (general purpose v1), StorageV2 (general purpose v2), BlobStorage ou BlockBlobStorage. Ao usar o serviço vinculado de Blob do Azure no fluxo de dados, a identidade gerenciada ou a autenticação da entidade de serviço não é suportada quando o tipo de conta está vazio ou "Armazenamento". Especifique o tipo de conta adequado, escolha uma autenticação diferente ou atualize sua conta de armazenamento para fins gerais v2. |
Não |
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto de credencial. | Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o tempo de execução de integração do Azure ou o tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver em uma rede privada). Se essa propriedade não for especificada, o serviço usará o tempo de execução de integração padrão do Azure. | Não |
Exemplo:
{
"name": "AzureBlobStorageLinkedService",
"properties": {
"type": "AzureBlobStorage",
"typeProperties": {
"serviceEndpoint": "https://<accountName>.blob.core.windows.net/",
"accountKind": "StorageV2",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Importante
Se você usar a instrução PolyBase ou COPY para carregar dados do armazenamento de Blob (como uma origem ou como preparação) no Azure Synapse Analytics, ao usar a autenticação de identidade gerenciada para armazenamento de Blob, siga também as etapas 1 a 3 nesta orientação. Essas etapas registrarão seu servidor com a ID do Microsoft Entra e atribuirão a função de Colaborador de Dados de Blob de Armazenamento ao seu servidor. O Data Factory trata do resto. Se você configurar o armazenamento de Blob com um ponto de extremidade da Rede Virtual do Azure, também precisará ter a opção Permitir que serviços confiáveis da Microsoft acessem essa conta de armazenamento ativada no menu Configurações de firewalls e redes virtuais da conta de armazenamento do Azure, conforme exigido pelo Azure Synapse.
Nota
- Se sua conta de blob permitir a exclusão suave, a autenticação de identidade gerenciada atribuída pelo sistema/atribuída pelo usuário não será suportada no Fluxo de Dados.
- Se você acessar o armazenamento de blob por meio de ponto de extremidade privado usando o Fluxo de Dados, observe quando a autenticação de identidade gerenciada atribuída pelo sistema/atribuída pelo usuário for usada, o Fluxo de Dados se conectará ao ponto de extremidade ADLS Gen2 em vez do ponto de extremidade Blob. Certifique-se de criar o ponto de extremidade privado correspondente no ADF para habilitar o acesso.
Nota
A autenticação de identidade gerenciada atribuída pelo sistema/atribuída pelo usuário é suportada apenas pelo serviço vinculado do tipo "AzureBlobStorage", não pelo serviço vinculado do tipo "AzureStorage" anterior.
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo Conjuntos de dados.
O Azure Data Factory suporta os seguintes formatos de ficheiro. Consulte cada artigo para obter as configurações baseadas em formato.
- Formato Avro
- Formato binário
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
As seguintes propriedades têm suporte para o Armazenamento de Blobs do Azure em location configurações em um conjunto de dados baseado em formato:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do local no conjunto de dados deve ser definida como AzureBlobStorageLocation. | Sim |
| contentor | O contêiner de blob. | Sim |
| folderPath | O caminho para a pasta sob o contêiner fornecido. Se você quiser usar um curinga para filtrar a pasta, ignore essa configuração e especifique isso nas configurações da fonte de atividade. | Não |
| fileName | O nome do arquivo sob o caminho do contêiner e da pasta fornecidos. Se você quiser usar curinga para filtrar arquivos, ignore essa configuração e especifique isso nas configurações da fonte de atividade. | Não |
Exemplo:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder"
},
"columnDelimiter": ",",
"quoteChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades que a fonte de armazenamento de Blob e o coletor suportam.
Armazenamento de Blob como um tipo de origem
O Azure Data Factory suporta os seguintes formatos de ficheiro. Consulte cada artigo para obter as configurações baseadas em formato.
- Formato Avro
- Formato binário
- Formato de texto delimitado
- Formato Excel
- Formato JSON
- Formato ORC
- Formato Parquet
- Formato XML
As seguintes propriedades têm suporte para o Armazenamento de Blobs do Azure em storeSettings configurações em uma fonte de cópia baseada em formato:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type under storeSettings deve ser definida como AzureBlobStorageReadSettings. |
Sim |
| Localize os ficheiros a copiar: | ||
| OPÇÃO 1: caminho estático |
Copie do contêiner fornecido ou caminho de pasta/arquivo especificado no conjunto de dados. Se você quiser copiar todos os blobs de um contêiner ou pasta, especifique wildcardFileName adicionalmente como *. |
|
| OPÇÃO 2: prefixo blob - prefixo |
Prefixo para o nome do blob sob o contêiner fornecido configurado em um conjunto de dados para filtrar blobs de origem. Os blobs cujos nomes começam com container_in_dataset/this_prefix são selecionados. Ele utiliza o filtro do lado do serviço para armazenamento de Blob, que oferece melhor desempenho do que um filtro curinga.Quando você usa prefixo e opta por copiar para coletor baseado em arquivo com hierarquia de preservação, observe o subcaminho depois que o último "/" no prefixo é preservado. Por exemplo, você tem origem container/folder/subfolder/file.txte configura o prefixo como folder/sub, então o caminho do arquivo preservado é subfolder/file.txt. |
Não |
| OPÇÃO 3: curinga - wildcardFolderPath |
O caminho da pasta com caracteres curinga sob o contêiner fornecido configurado em um conjunto de dados para filtrar pastas de origem. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único). Use ^ para escapar se o nome da pasta tiver curinga ou esse caractere de escape dentro. Veja mais exemplos em Exemplos de filtros de pastas e ficheiros. |
Não |
| OPÇÃO 3: curinga - wildcardFileName |
O nome do arquivo com caracteres curinga sob o contêiner e o caminho da pasta fornecidos (ou caminho da pasta curinga) para filtrar os arquivos de origem. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único). Use ^ para escapar se o nome do arquivo tiver um curinga ou esse caractere de escape dentro. Veja mais exemplos em Exemplos de filtros de pastas e ficheiros. |
Sim |
| OPÇÃO 4: uma lista de ficheiros - fileListPath |
Indica para copiar um determinado conjunto de arquivos. Aponte para um arquivo de texto que inclua uma lista de arquivos que você deseja copiar, um arquivo por linha, que é o caminho relativo para o caminho configurado no conjunto de dados. Quando estiver usando essa opção, não especifique um nome de arquivo no conjunto de dados. Veja mais exemplos em Exemplos de lista de arquivos. |
Não |
| Configurações adicionais: | ||
| recursiva | Indica se os dados são lidos recursivamente das subpastas ou somente da pasta especificada. Observe que quando recursivo é definido como true e o coletor é um armazenamento baseado em arquivo, uma pasta ou subpasta vazia não é copiada ou criada no coletor. Os valores permitidos são true (padrão) e false. Esta propriedade não se aplica quando você configura fileListPatho . |
Não |
| deleteFilesAfterCompletion | Indica se os arquivos binários serão excluídos do armazenamento de origem depois de serem movidos com êxito para o repositório de destino. A exclusão do arquivo é por arquivo. Portanto, quando a atividade de cópia falhar, você verá que alguns arquivos já foram copiados para o destino e excluídos da origem, enquanto outros ainda permanecem no armazenamento de origem. Esta propriedade só é válida no cenário de cópia de arquivos binários. O valor padrão: false. |
Não |
| modifiedDatetimeStart | Os arquivos são filtrados com base no atributo: última modificação. Os arquivos serão selecionados se o tempo da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada a um fuso horário UTC no formato "2018-12-01T05:00:00Z". As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo será aplicado ao conjunto de dados. Quando modifiedDatetimeStart tiver um valor datetime, mas modifiedDatetimeEnd for NULL, os arquivos cujo último atributo modificado for maior ou igual ao valor datetime serão selecionados. Quando modifiedDatetimeEnd tiver um valor datetime, mas modifiedDatetimeStart for NULL, os arquivos cujo atributo da última modificação for menor que o valor datetime serão selecionados.Esta propriedade não se aplica quando você configura fileListPatho . |
Não |
| modifiedDatetimeEnd | O mesmo que a propriedade anterior. | Não |
| enablePartitionDiscovery | Para arquivos particionados, especifique se deseja analisar as partições do caminho do arquivo e adicioná-las como colunas de origem extras. Os valores permitidos são false (padrão) e true. |
Não |
| partitionRootPath | Quando a descoberta de partições estiver habilitada, especifique o caminho raiz absoluto para ler pastas particionadas como colunas de dados. Se não for especificado, por padrão, - Quando você usa o caminho do arquivo no conjunto de dados ou na lista de arquivos na origem, o caminho da raiz da partição é o caminho configurado no conjunto de dados. - Quando você usa o filtro de pasta curinga, o caminho da raiz da partição é o subcaminho antes do primeiro curinga. - Quando você usa prefixo, o caminho raiz da partição é sub-caminho antes do último "/". Por exemplo, supondo que você configure o caminho no conjunto de dados como "root/folder/year=2020/month=08/day=27": - Se você especificar o caminho da raiz da partição como "root/folder/year=2020", a atividade de cópia gerará mais duas colunas month e day com o valor "08" e "27", respectivamente, além das colunas dentro dos arquivos.- Se o caminho raiz da partição não for especificado, nenhuma coluna extra será gerada. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | Não |
Nota
Para o formato de texto Parquet/delimitado, o tipo BlobSource para a fonte de atividade Copy mencionado na próxima seção ainda é suportado, assim como para compatibilidade com versões anteriores. Sugerimos que você use o novo modelo até que a interface do usuário de criação tenha mudado para gerar esses novos tipos.
Exemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"formatSettings":{
"type": "DelimitedTextReadSettings",
"skipLineCount": 10
},
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true,
"wildcardFolderPath": "myfolder*A",
"wildcardFileName": "*.csv"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Nota
O $logs contêiner, que é criado automaticamente quando o Storage Analytics está habilitado para uma conta de armazenamento, não é mostrado quando uma operação de listagem de contêineres é executada por meio da interface do usuário. O caminho do arquivo deve ser fornecido diretamente para que seu data factory ou pipeline Synapse consuma arquivos do $logs contêiner.
Armazenamento de blobs como um tipo de coletor
O Azure Data Factory suporta os seguintes formatos de ficheiro. Consulte cada artigo para obter as configurações baseadas em formato.
As seguintes propriedades têm suporte para o Armazenamento de Blobs do Azure em storeSettings configurações em um coletor de cópia baseado em formato:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade sob storeSettings deve ser definida como AzureBlobStorageWriteSettings. |
Sim |
| copyBehavior | Define o comportamento de cópia quando a origem são arquivos de um armazenamento de dados baseado em arquivo. Os valores permitidos são: - PreserveHierarchy (padrão): Preserva a hierarquia de arquivos na pasta de destino. O caminho relativo do arquivo de origem para a pasta de origem é idêntico ao caminho relativo do arquivo de destino para a pasta de destino. - FlattenHierarchy: Todos os arquivos da pasta de origem estão no primeiro nível da pasta de destino. Os arquivos de destino têm nomes gerados automaticamente. - MergeFiles: Mescla todos os arquivos da pasta de origem para um arquivo. Se o nome do arquivo ou blob for especificado, o nome do arquivo mesclado será o nome especificado. Caso contrário, é um nome de arquivo gerado automaticamente. |
Não |
| blockSizeInMB | Especifique o tamanho do bloco, em megabytes, usado para gravar dados para bloquear blobs. Saiba mais sobre Blobs de bloco. O valor permitido está entre 4 MB e 100 MB. Por padrão, o serviço determina automaticamente o tamanho do bloco com base no tipo de armazenamento de origem e nos dados. Para cópia não binária no armazenamento de Blob, o tamanho de bloco padrão é de 100 MB para que possa caber (no máximo) 4,95 TB de dados. Pode não ser ideal quando seus dados não são grandes, especialmente quando você usa o tempo de execução de integração auto-hospedado com conexões de rede ruins que resultam em tempo limite de operação ou problemas de desempenho. Você pode especificar explicitamente um tamanho de bloco, garantindo que blockSizeInMB*50000 seja grande o suficiente para armazenar os dados. Caso contrário, a execução da atividade Copiar falhará. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | Não |
| do IdP | Defina metadados personalizados quando copiar para coletor. Cada objeto sob a metadata matriz representa uma coluna extra. O name define o nome da chave de metadados e indica o value valor de dados dessa chave. Se o recurso preservar atributos for usado, os metadados especificados serão unidos/substituídos pelos metadados do arquivo de origem.Os valores de dados permitidos são: - $$LASTMODIFIED: uma variável reservada indica para armazenar a hora da última modificação dos arquivos de origem. Aplique apenas à fonte baseada em arquivo com formato binário.- Expressão - Valor estático |
Não |
Exemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings":{
"type": "AzureBlobStorageWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
},
{
"name": "lastModifiedKey",
"value": "$$LASTMODIFIED"
}
]
}
}
}
}
]
Exemplos de filtros de pastas e ficheiros
Esta seção descreve o comportamento resultante do caminho da pasta e do nome do arquivo com filtros curinga.
| folderPath | fileName | recursiva | Estrutura da pasta de origem e resultado do filtro (arquivos em negrito são recuperados) |
|---|---|---|---|
container/Folder* |
(vazio, use padrão) | false | contentor PastaA File1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB File6.csv |
container/Folder* |
(vazio, use padrão) | verdadeiro | contentor PastaA File1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB File6.csv |
container/Folder* |
*.csv |
false | contentor PastaA File1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB File6.csv |
container/Folder* |
*.csv |
verdadeiro | contentor PastaA File1.csv File2.json Subpasta1 File3.csv File4.json File5.csv OutraPastaB File6.csv |
Exemplos de lista de ficheiros
Esta seção descreve o comportamento resultante do uso de um caminho de lista de arquivos na fonte de atividade Copiar.
Suponha que você tenha a seguinte estrutura de pasta de origem e deseja copiar os arquivos em negrito:
| Estrutura de origem da amostra | Conteúdo em FileListToCopy.txt | Configuração |
|---|---|---|
| contentor PastaA File1.csv File2.json Subpasta1 File3.csv File4.json File5.csv Metadados FileListToCopy.txt |
File1.csv Subpasta1/File3.csv Subpasta1/File5.csv |
No conjunto de dados: - Contentor: container- Caminho da pasta: FolderAEm Copiar fonte da atividade: - Caminho da lista de arquivos: container/Metadata/FileListToCopy.txt O caminho da lista de arquivos aponta para um arquivo de texto no mesmo armazenamento de dados que inclui uma lista de arquivos que você deseja copiar. Ele inclui um arquivo por linha, com o caminho relativo para o caminho configurado no conjunto de dados. |
Alguns exemplos recursivos e copyBehavior
Esta seção descreve o comportamento resultante da operação Copy para diferentes combinações de valores recursivo e copyBehavior .
| recursiva | copyBehavior | Estrutura da pasta de origem | Alvo resultante |
|---|---|---|---|
| verdadeiro | preserveHierarchy | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a mesma estrutura da origem: Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
| verdadeiro | achatarHierarquia | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a seguinte estrutura: Pasta1 nome gerado automaticamente para File1 nome gerado automaticamente para File2 nome gerado automaticamente para File3 nome gerado automaticamente para File4 nome gerado automaticamente para File5 |
| verdadeiro | mesclarArquivos | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a seguinte estrutura: Pasta1 File1 + File2 + File3 + File4 + File5 conteúdo são mesclados em um arquivo com um nome de arquivo gerado automaticamente. |
| false | preserveHierarchy | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a seguinte estrutura: Pasta1 Ficheiro1 Ficheiro2 Subfolder1 com File3, File4 e File5 não é coletada. |
| false | achatarHierarquia | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a seguinte estrutura: Pasta1 nome gerado automaticamente para File1 nome gerado automaticamente para File2 Subfolder1 com File3, File4 e File5 não é coletada. |
| false | mesclarArquivos | Pasta1 Ficheiro1 Ficheiro2 Subpasta1 Ficheiro3 Ficheiro4 Ficheiro5 |
A pasta de destino, Folder1, é criada com a seguinte estrutura: Pasta1 O conteúdo de File1 + File2 é mesclado em um arquivo com um nome de arquivo gerado automaticamente. nome gerado automaticamente para File1 Subfolder1 com File3, File4 e File5 não é coletada. |
Preservando metadados durante a cópia
Ao copiar arquivos do Amazon S3, do Armazenamento de Blobs do Azure ou do Azure Data Lake Storage Gen2 para o Azure Data Lake Storage Gen2 ou o Armazenamento de Blobs do Azure, você pode optar por preservar os metadados do arquivo junto com os dados. Saiba mais em Preservar metadados.
Mapeando propriedades de fluxo de dados
Ao transformar dados em fluxos de dados de mapeamento, você pode ler e gravar arquivos do Armazenamento de Blobs do Azure nos seguintes formatos:
As configurações específicas do formato estão localizadas na documentação desse formato. Para obter mais informações, consulte Transformação de origem no mapeamento de fluxo de dados e Transformação de coletor no mapeamento de fluxo de dados.
Transformação da fonte
Na transformação de origem, você pode ler a partir de um contêiner, pasta ou arquivo individual no Armazenamento de Blobs do Azure. Use a guia Opções de origem para gerenciar como os arquivos são lidos.
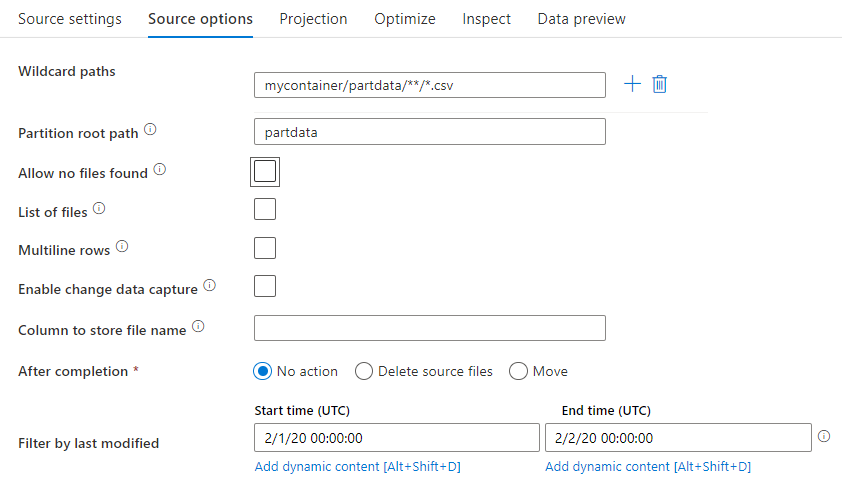
Caminhos curinga: o uso de um padrão curinga instruirá o serviço a percorrer cada pasta e arquivo correspondentes em uma única transformação de origem. Esta é uma maneira eficaz de processar vários arquivos dentro de um único fluxo. Adicione vários padrões de correspondência de curinga com o sinal de adição que aparece quando você passa o mouse sobre o padrão curinga existente.
No contêiner de origem, escolha uma série de arquivos que correspondam a um padrão. Somente um contêiner pode ser especificado no conjunto de dados. Portanto, o caminho curinga também deve incluir o caminho da pasta raiz.
Exemplos de curingas:
*Representa qualquer conjunto de caracteres.**Representa o aninhamento recursivo de diretórios.?Substitui um caractere.[]Corresponde a um ou mais caracteres entre parênteses./data/sales/**/*.csvObtém todos os arquivos .csv em /data/sales./data/sales/20??/**/Obtém todos os arquivos no século 20./data/sales/*/*/*.csvObtém arquivos .csv dois níveis em /data/sales./data/sales/2004/*/12/[XY]1?.csvObtém todos os arquivos .csv em dezembro de 2004, começando com X ou Y prefixados por um número de dois dígitos.
Caminho da raiz da partição: Se você tiver pastas particionadas na fonte do arquivo com um key=value formato (por exemplo, year=2019), poderá atribuir o nível superior dessa árvore de pastas de partição a um nome de coluna no fluxo de dados do fluxo de dados.
Primeiro, defina um curinga para incluir todos os caminhos que são as pastas particionadas mais os arquivos folha que você deseja ler.
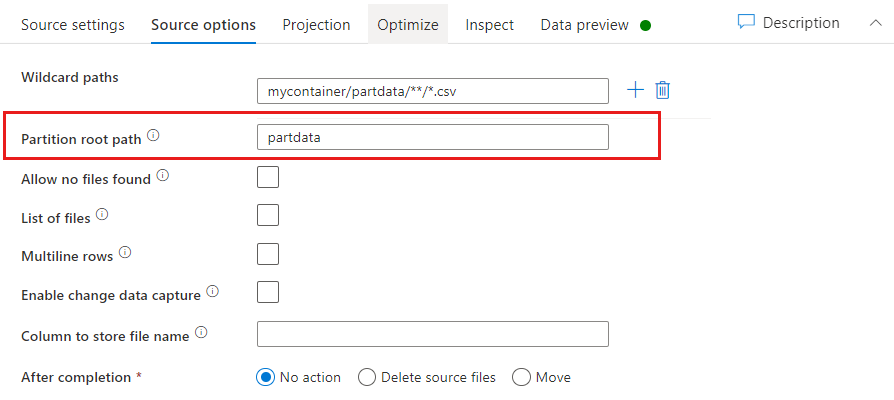
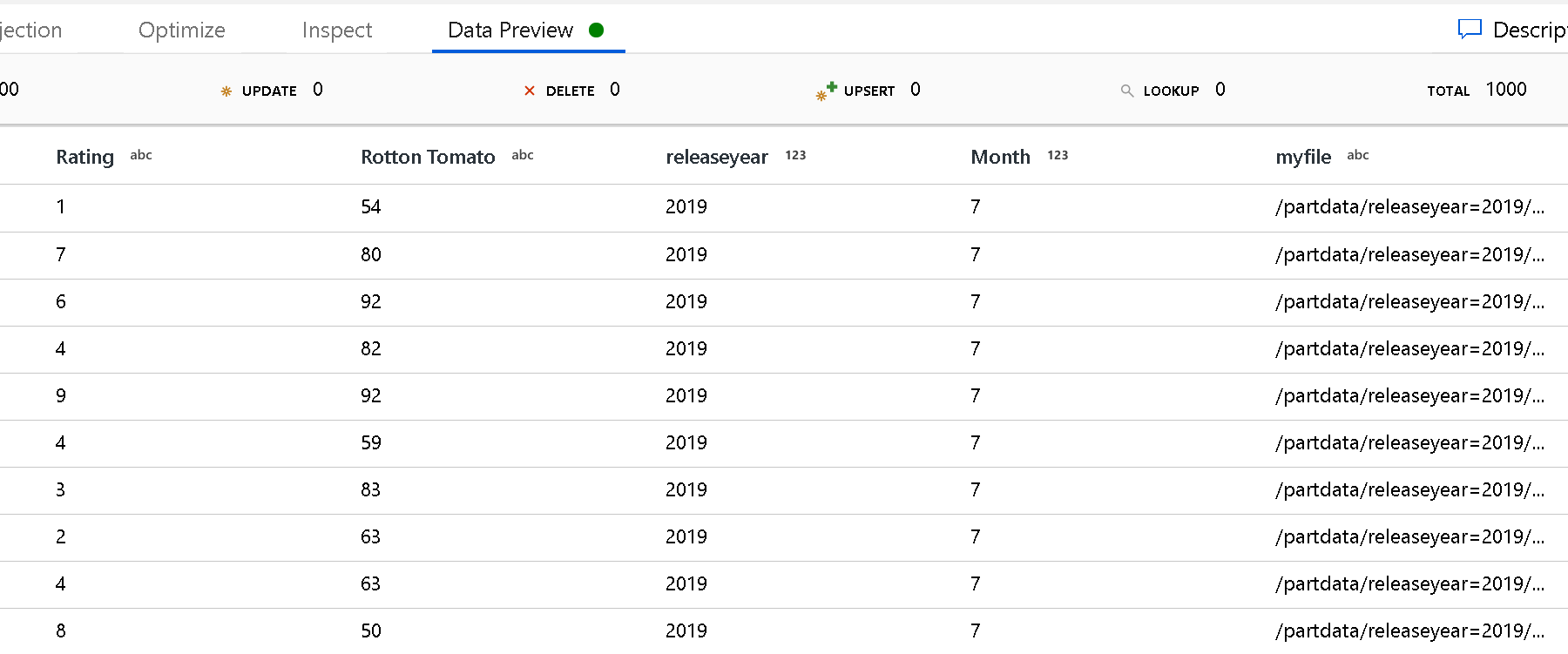
Use a configuração Caminho raiz da partição para definir qual é o nível superior da estrutura de pastas. Quando visualiza o conteúdo dos seus dados através de uma pré-visualização de dados, verá que o serviço adiciona as partições resolvidas encontradas em cada um dos seus níveis de pasta.
Lista de ficheiros: Este é um conjunto de ficheiros. Crie um arquivo de texto que inclua uma lista de arquivos de caminho relativos a serem processados. Aponte para este ficheiro de texto.
Coluna para armazenar o nome do arquivo: armazene o nome do arquivo de origem em uma coluna em seus dados. Insira um novo nome de coluna aqui para armazenar a cadeia de caracteres de nome de arquivo.
Após a conclusão: escolha não fazer nada com o arquivo de origem depois que o fluxo de dados for executado, exclua o arquivo de origem ou mova o arquivo de origem. Os caminhos para a mudança são relativos.
Para mover os arquivos de origem para outro local pós-processamento, primeiro selecione "Mover" para a operação do arquivo. Em seguida, defina o diretório "from". Se você não estiver usando nenhum curinga para seu caminho, a configuração "de" será a mesma pasta que sua pasta de origem.
Se você tiver um caminho de origem com curinga, sua sintaxe será a seguinte:
/data/sales/20??/**/*.csv
Você pode especificar "de" como:
/data/sales
E você pode especificar "para" como:
/backup/priorSales
Nesse caso, todos os arquivos que foram originados em /data/sales são movidos para /backup/priorSales.
Nota
As operações de arquivo são executadas somente quando você inicia o fluxo de dados de uma execução de pipeline (uma depuração de pipeline ou execução de execução) que usa a atividade Executar fluxo de dados em um pipeline. As operações de arquivo não são executadas no modo de depuração de fluxo de dados.
Filtrar pela última modificação: Você pode filtrar os arquivos a serem processados especificando um intervalo de datas de quando eles foram modificados pela última vez. Todas as datas/hora estão em UTC.
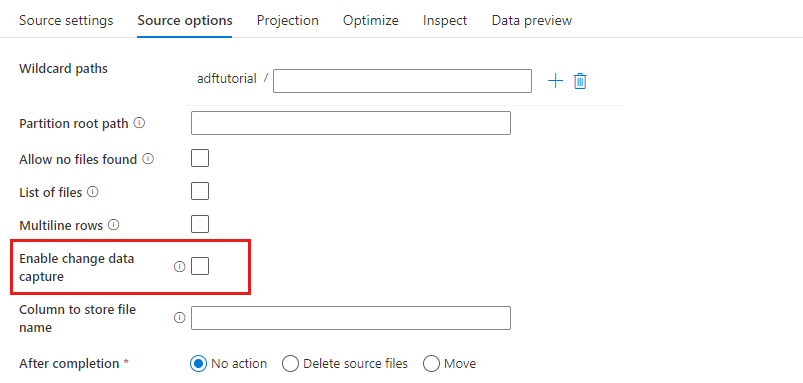
Ativar captura de dados de alteração: se verdadeiro, você obterá arquivos novos ou alterados somente a partir da última execução. A carga inicial de dados completos de snapshot sempre será obtida na primeira execução, seguida pela captura de arquivos novos ou alterados somente nas próximas execuções.
Propriedades do lavatório
Na transformação do coletor, você pode gravar em um contêiner ou em uma pasta no Armazenamento de Blobs do Azure. Use a guia Configurações para gerenciar como os arquivos são gravados.
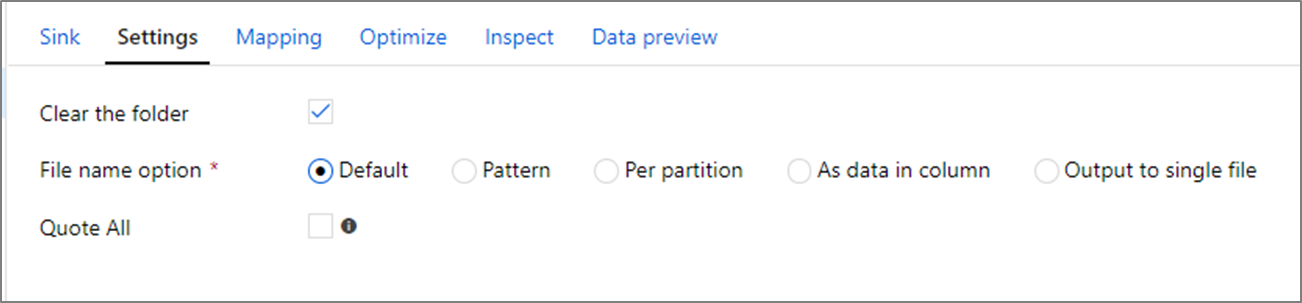
Limpar a pasta: determina se a pasta de destino é ou não limpa antes que os dados sejam gravados.
Opção Nome do arquivo: Determina como os arquivos de destino são nomeados na pasta de destino. As opções de nome de arquivo são:
- Padrão: permite que o Spark nomeie arquivos com base nos padrões PART.
- Padrão: insira um padrão que enumere seus arquivos de saída por partição. Por exemplo,
loans[n].csvcrialoans1.csv,loans2.csv, e assim por diante. - Por partição: insira um nome de arquivo por partição.
- Como dados na coluna: defina o arquivo de saída com o valor de uma coluna. O caminho é relativo ao contêiner do conjunto de dados, não à pasta de destino. Se você tiver um caminho de pasta em seu conjunto de dados, ele será substituído.
- Saída para um único arquivo: combine os arquivos de saída particionados em um único arquivo nomeado. O caminho é relativo à pasta do conjunto de dados. Lembre-se de que a operação de mesclagem pode falhar com base no tamanho do nó. Não recomendamos essa opção para grandes conjuntos de dados.
Aspar tudo: Determina se todos os valores devem ser colocados entre aspas.
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Propriedades de atividade GetMetadata
Para saber detalhes sobre as propriedades, verifique a atividade GetMetadata.
Excluir propriedades de atividade
Para saber detalhes sobre as propriedades, marque Excluir atividade.
Modelos antigos
Nota
Os seguintes modelos ainda são suportados, assim como para compatibilidade com versões anteriores. Sugerimos que utilize o novo modelo mencionado anteriormente. A interface do usuário de criação mudou para gerar o novo modelo.
Modelo de conjunto de dados herdado
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade do conjunto de dados deve ser definida como AzureBlob. |
Sim |
| folderPath | Caminho para o contêiner e a pasta no armazenamento de Blob. Um filtro curinga é suportado para o caminho, excluindo o nome do contêiner. Os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único). Use ^ para escapar se o nome da pasta tiver um curinga ou esse caractere de escape dentro. Um exemplo é: myblobcontainer/myblobfolder/. Veja mais exemplos em Exemplos de filtros de pastas e ficheiros. |
Sim para a atividade Cópia ou Pesquisa, Não para a atividade GetMetadata |
| fileName | Nome ou filtro curinga para os blobs sob o valor especificado folderPath . Se você não especificar um valor para essa propriedade, o conjunto de dados apontará para todos os blobs na pasta. Para o filtro, os curingas permitidos são: * (corresponde a zero ou mais caracteres) e ? (corresponde a zero ou caractere único).- Exemplo 1: "fileName": "*.csv"- Exemplo 2: "fileName": "???20180427.txt"Use ^ para escapar se o nome do arquivo tiver um curinga ou esse caractere de escape dentro.Quando fileName não é especificado para um conjunto de dados de saída e preserveHierarchy não é especificado no coletor de atividades, a atividade Copiar gera automaticamente o nome do blob com o seguinte padrão: "Data.[ GUID do ID de execução da atividade]. [GUID se FlattenHierarchy]. [formato, se configurado]. [compressão se configurada]". Por exemplo: "Data.0a405f8a-93ff-4c6f-b3be-f69616f1df7a.txt.gz". Se você copiar de uma fonte tabular usando um nome de tabela em vez de uma consulta, o padrão de nome será [table name].[format].[compression if configured]. Por exemplo: "MyTable.csv". |
Não |
| modifiedDatetimeStart | Os arquivos são filtrados com base no atributo: última modificação. Os arquivos serão selecionados se o tempo da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário UTC no formato "2018-12-01T05:00:00Z". Lembre-se de que habilitar essa configuração afeta o desempenho geral da movimentação de dados quando você deseja filtrar grandes quantidades de arquivos. As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo será aplicado ao conjunto de dados. Quando modifiedDatetimeStart tiver um valor datetime, mas modifiedDatetimeEnd for NULL, os arquivos cujo atributo da última modificação for maior ou igual ao valor datetime serão selecionados. Quando modifiedDatetimeEnd tiver um valor datetime, mas modifiedDatetimeStart for NULL, os arquivos cujo atributo da última modificação for menor que o valor datetime serão selecionados. |
Não |
| modifiedDatetimeEnd | Os arquivos são filtrados com base no atributo: última modificação. Os arquivos serão selecionados se o tempo da última modificação for maior ou igual a modifiedDatetimeStart e menor que modifiedDatetimeEnd. A hora é aplicada ao fuso horário UTC no formato "2018-12-01T05:00:00Z". Lembre-se de que habilitar essa configuração afeta o desempenho geral da movimentação de dados quando você deseja filtrar grandes quantidades de arquivos. As propriedades podem ser NULL, o que significa que nenhum filtro de atributo de arquivo será aplicado ao conjunto de dados. Quando modifiedDatetimeStart tiver um valor datetime, mas modifiedDatetimeEnd for NULL, os arquivos cujo atributo da última modificação for maior ou igual ao valor datetime serão selecionados. Quando modifiedDatetimeEnd tiver um valor datetime, mas modifiedDatetimeStart for NULL, os arquivos cujo atributo da última modificação for menor que o valor datetime serão selecionados. |
Não |
| format | Se você quiser copiar arquivos como está entre armazenamentos baseados em arquivo (cópia binária), ignore a seção de formato nas definições de conjunto de dados de entrada e saída. Se você quiser analisar ou gerar arquivos com um formato específico, os seguintes tipos de formato de arquivo são suportados: TextFormat, JsonFormat, AvroFormat, OrcFormat e ParquetFormat. Defina a propriedade type em format como um desses valores. Para obter mais informações, consulte as seções Formato texto, Formato JSON, Formato Avro, Formato Orc e Formato Parquet. |
Não (apenas para o cenário de cópia binária) |
| compressão | Especifique o tipo e o nível de compactação dos dados. Para obter mais informações, consulte Formatos de arquivo e codecs de compactação suportados. Os tipos suportados são GZip, Deflate, BZip2 e ZipDeflate. Os níveis suportados são Ótimos e Mais Rápidos. |
Não |
Gorjeta
Para copiar todos os blobs em uma pasta, especifique somente folderPath .
Para copiar um único blob com um determinado nome, especifique folderPath para a parte da pasta e fileName para o nome do arquivo.
Para copiar um subconjunto de blobs em uma pasta, especifique folderPath para a parte da pasta e fileName com um filtro curinga.
Exemplo:
{
"name": "AzureBlobDataset",
"properties": {
"type": "AzureBlob",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"folderPath": "mycontainer/myfolder",
"fileName": "*",
"modifiedDatetimeStart": "2018-12-01T05:00:00Z",
"modifiedDatetimeEnd": "2018-12-01T06:00:00Z",
"format": {
"type": "TextFormat",
"columnDelimiter": ",",
"rowDelimiter": "\n"
},
"compression": {
"type": "GZip",
"level": "Optimal"
}
}
}
}
Modelo de origem herdado para a atividade Copiar
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade da fonte de atividade Copy deve ser definida como BlobSource. |
Sim |
| recursiva | Indica se os dados são lidos recursivamente das subpastas ou somente da pasta especificada. Quando recursive é definido como true e o coletor é um armazenamento baseado em arquivo, uma pasta ou subpasta vazia não é copiada ou criada no coletor.Os valores permitidos são true (padrão) e false. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyFromBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Blob input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "BlobSource",
"recursive": true
},
"sink": {
"type": "<sink type>"
}
}
}
]
Modelo de coletor herdado para a atividade Copiar
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A type propriedade do coletor de atividade Copiar deve ser definida como BlobSink. |
Sim |
| copyBehavior | Define o comportamento de cópia quando a origem são arquivos de um armazenamento de dados baseado em arquivo. Os valores permitidos são: - PreserveHierarchy (padrão): Preserva a hierarquia de arquivos na pasta de destino. O caminho relativo do arquivo de origem para a pasta de origem é idêntico ao caminho relativo do arquivo de destino para a pasta de destino. - FlattenHierarchy: Todos os arquivos da pasta de origem estão no primeiro nível da pasta de destino. Os arquivos de destino têm nomes gerados automaticamente. - MergeFiles: Mescla todos os arquivos da pasta de origem para um arquivo. Se o nome do arquivo ou blob for especificado, o nome do arquivo mesclado será o nome especificado. Caso contrário, é um nome de arquivo gerado automaticamente. |
Não |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | Não |
Exemplo:
"activities":[
{
"name": "CopyToBlob",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure Blob output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "BlobSink",
"copyBehavior": "PreserveHierarchy"
}
}
}
]
Captura de dados de alteração
O Azure Data Factory pode obter arquivos novos ou alterados somente do Armazenamento de Blobs do Azure habilitando **Habilitar captura de dados de alteração** na transformação da fonte de fluxo de dados de mapeamento. Com essa opção de conector, você pode ler somente arquivos novos ou atualizados e aplicar transformações antes de carregar dados transformados em conjuntos de dados de destino de sua escolha. Consulte Alterar captura de dados para obter detalhes.
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados que a atividade Copiar suporta como fontes e coletores, consulte Armazenamentos de dados suportados.