Formato delta no Azure Data Factory
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo destaca como copiar dados de e para um lago delta armazenados no Azure Data Lake Store Gen2 ou no Armazenamento de Blobs do Azure usando o formato delta. Esse conector está disponível como um conjunto de dados embutido no mapeamento de fluxos de dados como uma fonte e um coletor.
Mapeando propriedades de fluxo de dados
Esse conector está disponível como um conjunto de dados embutido no mapeamento de fluxos de dados como uma fonte e um coletor.
Propriedades de origem
A tabela abaixo lista as propriedades suportadas por uma fonte delta. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser delta |
sim | delta |
format |
| Sistema de ficheiros | O sistema de contêiner/arquivo do lago delta | sim | String | Sistema de arquivos |
| Folder path | O diretório do lago delta | sim | String | folderPath |
| Tipo de compressão | O tipo de compressão da tabela delta | não | bzip2gzipdeflateZipDeflatesnappylz4 |
compressionType |
| Compression level | Escolha se a compactação é concluída o mais rápido possível ou se o arquivo resultante deve ser compactado de forma ideal. | obrigatório se compressedType for especificado. |
Optimal ou Fastest |
nível de compressão |
| Viagem no tempo | Escolha se deseja consultar um instantâneo mais antigo de uma tabela delta | não | Consulta por carimbo de data/hora: carimbo de data/hora Consulta por versão: Inteiro |
carimbo de data/horaAsOf versãoAsOf |
| Não permitir que nenhum arquivo seja encontrado | Se verdadeiro, um erro não é lançado se nenhum arquivo for encontrado | não | true ou false |
ignoreNoFilesFound |
Esquema de importação
Delta só está disponível como um conjunto de dados embutido e, por padrão, não tem um esquema associado. Para obter metadados de coluna, clique no botão Importar esquema na guia Projeção . Isto permite-lhe fazer referência aos nomes das colunas e aos tipos de dados especificados pelo corpus. Para importar o esquema, uma sessão de depuração de fluxo de dados deve estar ativa e você deve ter um arquivo de definição de entidade CDM existente para o qual apontar.
Exemplo de script de origem delta
source(output(movieId as integer,
title as string,
releaseDate as date,
rated as boolean,
screenedOn as timestamp,
ticketPrice as decimal(10,2)
),
store: 'local',
format: 'delta',
versionAsOf: 0,
allowSchemaDrift: false,
folderPath: $tempPath + '/delta'
) ~> movies
Propriedades do lavatório
A tabela abaixo lista as propriedades suportadas por um coletor delta. Você pode editar essas propriedades na guia Configurações .
| Nome | Descrição | Obrigatório | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Formato | O formato deve ser delta |
sim | delta |
format |
| Sistema de ficheiros | O sistema de contêiner/arquivo do lago delta | sim | String | Sistema de arquivos |
| Folder path | O diretório do lago delta | sim | String | folderPath |
| Tipo de compressão | O tipo de compressão da tabela delta | não | bzip2gzipdeflateZipDeflatesnappylz4TarGZiptar |
compressionType |
| Compression level | Escolha se a compactação é concluída o mais rápido possível ou se o arquivo resultante deve ser compactado de forma ideal. | obrigatório se compressedType for especificado. |
Optimal ou Fastest |
nível de compressão |
| Limpeza | Exclui arquivos mais antigos do que a duração especificada que não são mais relevantes para a versão atual da tabela. Quando um valor de 0 ou menos é especificado, a operação de vácuo não é executada. | sim | Número inteiro | vácuo |
| Ação da tabela | Informa ao ADF o que fazer com a tabela Delta de destino em sua pia. Você pode deixá-lo como está e acrescentar novas linhas, substituir a definição de tabela e os dados existentes por novos metadados e dados, ou manter a estrutura da tabela existente, mas primeiro truncar todas as linhas e, em seguida, inserir as novas linhas. | não | Nenhum, Truncate, Substituir | deltaTruncate, substituir |
| Método de atualização | Quando você seleciona "Permitir inserção" sozinho ou quando grava em uma nova tabela delta, o destino recebe todas as linhas de entrada, independentemente do conjunto de políticas de linha. Se seus dados contiverem linhas de outras políticas de Linha, elas precisarão ser excluídas usando uma transformação de Filtro anterior. Quando todos os métodos Update são selecionados, uma Mesclagem é executada, onde as linhas são inseridas/excluídas/atualizadas/atualizadas de acordo com as Políticas de Linha definidas usando uma transformação Alter Row anterior. |
sim | true ou false |
inserível suprimido Atualizável atualizável |
| Escrita otimizada | Obtenha uma taxa de transferência mais alta para a operação de gravação otimizando o embaralhamento interno nos executores do Spark. Como resultado, você pode notar menos partições e arquivos que são de um tamanho maior | não | true ou false |
optimizedWrite: verdadeiro |
| Auto Compacto | Após a conclusão de qualquer operação de gravação, o Spark executará automaticamente o OPTIMIZE comando para reorganizar os dados, resultando em mais partições, se necessário, para um melhor desempenho de leitura no futuro |
não | true ou false |
autoCompact: verdadeiro |
Exemplo de script de coletor delta
O script de fluxo de dados associado é:
moviesAltered sink(
input(movieId as integer,
title as string
),
mapColumn(
movieId,
title
),
insertable: true,
updateable: true,
deletable: true,
upsertable: false,
keys: ['movieId'],
store: 'local',
format: 'delta',
vacuum: 180,
folderPath: $tempPath + '/delta'
) ~> movieDB
Pia delta com poda de divisória
Com esta opção no método Update acima (ou seja, update/upsert/delete), você pode limitar o número de partições inspecionadas. Somente as partições que satisfazem essa condição são buscadas no repositório de destino. Você pode especificar um conjunto fixo de valores que uma coluna de partição pode ter.
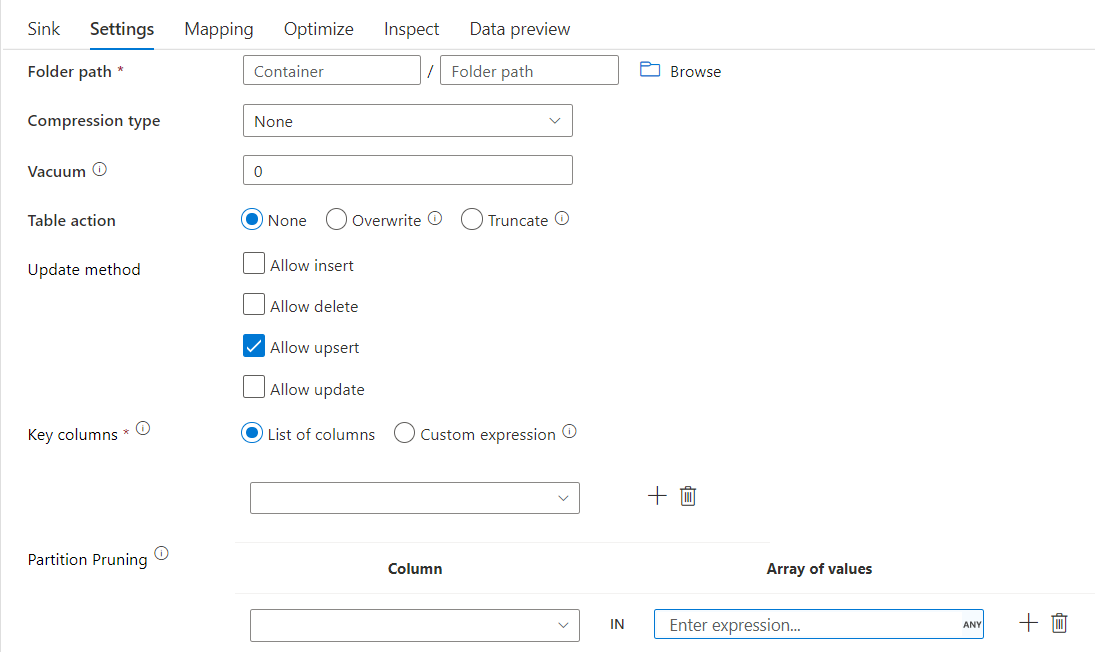
Exemplo de script de coletor delta com remoção de partição
Um script de exemplo é dado como abaixo.
DerivedColumn1 sink(
input(movieId as integer,
title as string
),
allowSchemaDrift: true,
validateSchema: false,
format: 'delta',
container: 'deltaContainer',
folderPath: 'deltaPath',
mergeSchema: false,
autoCompact: false,
optimizedWrite: false,
vacuum: 0,
deletable:false,
insertable:true,
updateable:true,
upsertable:false,
keys:['movieId'],
pruneCondition:['part_col' -> ([5, 8])],
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> sink2
Delta só lerá 2 partições onde part_col == 5 e 8 do armazenamento delta de destino em vez de todas as partições. part_col é uma coluna pela qual os dados delta de destino são particionados. Não precisa de estar presente nos dados de origem.
Opções de otimização de dissipador delta
Na guia Configurações, você encontra mais três opções para otimizar a transformação do coletor delta.
Quando a opção Mesclar esquema está habilitada, ela permite a evolução do esquema, ou seja, todas as colunas que estão presentes no fluxo de entrada atual, mas não na tabela Delta de destino, são adicionadas automaticamente ao seu esquema. Esta opção é suportada em todos os métodos de atualização.
Quando a compactação automática está ativada, após uma gravação individual, a transformação verifica se os arquivos podem ser compactados e executa um trabalho OTIMIZE rápido (com tamanhos de arquivo de 128 MB em vez de 1GB) para compactar ainda mais os arquivos para partições que têm o maior número de arquivos pequenos. A compactação automática ajuda a aglutinar um grande número de arquivos pequenos em um número menor de arquivos grandes. A compactação automática só entra em ação quando há pelo menos 50 arquivos. Uma vez que uma operação de compactação é executada, ele cria uma nova versão da tabela e grava um novo arquivo contendo os dados de vários arquivos anteriores em um formato compacto compactado.
Quando a gravação Otimize está habilitada, a transformação do coletor otimiza dinamicamente os tamanhos das partições com base nos dados reais, tentando gravar arquivos de 128 MB para cada partição de tabela. Este é um tamanho aproximado e pode variar dependendo das características do conjunto de dados. As gravações otimizadas melhoram a eficiência geral das gravações e leituras subsequentes. Ele organiza partições de tal forma que o desempenho das leituras subsequentes melhora.
Gorjeta
O processo de gravação otimizado tornará mais lento seu trabalho geral de ETL porque o Sink emitirá o comando Spark Delta Lake Otimize depois que seus dados forem processados. Recomenda-se usar a Escrita Otimizada com moderação. Por exemplo, se você tiver um pipeline de dados por hora, execute um fluxo de dados com Gravação otimizada diariamente.
Limitações conhecidas
Quando você grava em um coletor delta, há uma limitação conhecida em que o número de linhas gravadas não aparecerá na saída de monitoramento.
Conteúdos relacionados
- Crie uma transformação de origem no mapeamento do fluxo de dados.
- Crie uma transformação de coletor no mapeamento do fluxo de dados.
- Crie uma transformação de linha de alteração para marcar linhas como inserir, atualizar, atualizar ou excluir.