Copiar e transformar dados no Azure Synapse Analytics usando o Azure Data Factory ou pipelines Synapse
APLICA-SE A:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia no Azure Data Factory ou pipelines Synapse para copiar dados de e para o Azure Synapse Analytics e usar o Fluxo de Dados para transformar dados no Azure Data Lake Storage Gen2. Para saber mais sobre o Azure Data Factory, leia o artigo introdutório.
Capacidades suportadas
Este conector do Azure Synapse Analytics é suportado para as seguintes capacidades:
| Capacidades suportadas | IR | Ponto final privado gerido |
|---|---|---|
| Atividade de cópia (origem/coletor) | (1) (2) | ✓ |
| Mapeando o fluxo de dados (origem/coletor) | (1) | ✓ |
| Atividade de Pesquisa | (1) (2) | ✓ |
| Atividade GetMetadata | (1) (2) | ✓ |
| Atividade de script | (1) (2) | ✓ |
| Atividade de procedimento armazenado | (1) (2) | ✓ |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Para atividade de cópia, este conector do Azure Synapse Analytics suporta estas funções:
- Copie dados usando a autenticação SQL e a autenticação de token do Aplicativo Microsoft Entra com uma entidade de serviço ou identidades gerenciadas para recursos do Azure.
- Como fonte, recupere dados usando uma consulta SQL ou um procedimento armazenado. Você também pode optar por copiar paralelamente de uma fonte do Azure Synapse Analytics, consulte a seção Cópia paralela do Azure Synapse Analytics para obter detalhes.
- Como um coletor, carregue dados usando a instrução COPY ou PolyBase ou inserção em massa. Recomendamos a instrução COPY ou o PolyBase para um melhor desempenho de cópia. O conector também suporta a criação automática de tabela de destino com DISTRIBUTION = ROUND_ROBIN se não existir com base no esquema de origem.
Importante
Se você copiar dados usando um Tempo de Execução de Integração do Azure, configure uma regra de firewall no nível de servidor para que os serviços do Azure possam acessar o SQL Server lógico. Se você copiar dados usando um tempo de execução de integração auto-hospedado, configure o firewall para permitir o intervalo de IP apropriado. Esse intervalo inclui o IP da máquina que é usado para se conectar ao Azure Synapse Analytics.
Começar agora
Gorjeta
Para obter o melhor desempenho, use a instrução PolyBase ou COPY para carregar dados no Azure Synapse Analytics. As seções Usar o PolyBase para carregar dados no Azure Synapse Analytics e Usar a instrução COPY para carregar dados no Azure Synapse Analytics têm detalhes. Para obter um passo a passo com um caso de uso, consulte Carregar 1 TB no Azure Synapse Analytics em 15 minutos com o Azure Data Factory.
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
Criar um serviço vinculado do Azure Synapse Analytics usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado do Azure Synapse Analytics na interface do usuário do portal do Azure.
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure Synapse e selecione o conector do Azure Synapse Analytics.
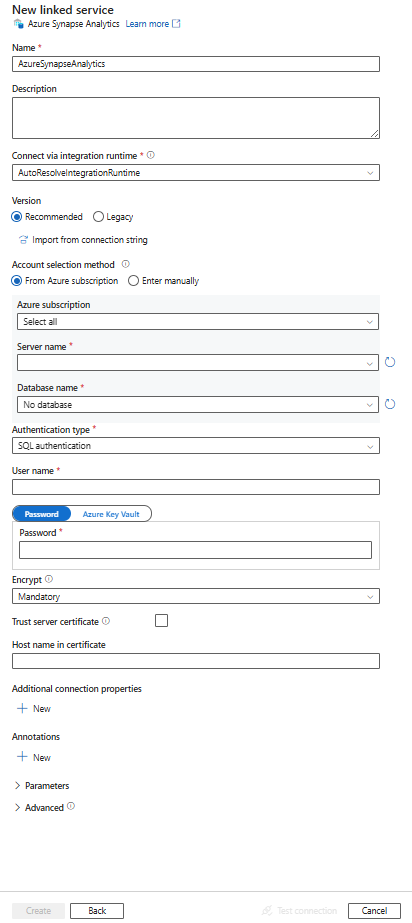
Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre propriedades que definem entidades de pipeline do Data Factory e do Synapse específicas para um conector do Azure Synapse Analytics.
Propriedades do serviço vinculado
A versão recomendada do conector do Azure Synapse Analytics suporta TLS 1.3. Consulte esta seção para atualizar sua versão do conector do Azure Synapse Analytics da versão herdada. Para obter os detalhes da propriedade, consulte as seções correspondentes.
Gorjeta
Ao criar um serviço vinculado para um pool SQL sem servidor no Azure Synapse a partir do portal do Azure:
- Para Método de seleção de conta, escolha Enter manualmente.
- Cole o nome de domínio totalmente qualificado do ponto de extremidade sem servidor. Você pode encontrar isso na página Visão geral do portal do Azure para seu espaço de trabalho Synapse, nas propriedades em Ponto de extremidade SQL sem servidor. Por exemplo,
myserver-ondemand.sql-azuresynapse.net. - Para Nome do banco de dados, forneça o nome do banco de dados no pool SQL sem servidor.
Gorjeta
Se você acertar erro com código de erro como "UserErrorFailedToConnectToSqlServer" e mensagem como "O limite de sessão para o banco de dados é XXX e foi atingido.", adicione Pooling=false à sua cadeia de conexão e tente novamente.
Versão recomendada
Estas propriedades genéricas têm suporte para um serviço vinculado do Azure Synapse Analytics quando você aplica a versão recomendada :
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureSqlDW. | Sim |
| servidor | O nome ou endereço de rede da instância do SQL Server à qual você deseja se conectar. | Sim |
| base de dados | O nome do banco de dados. | Sim |
| authenticationType | O tipo usado para autenticação. Os valores permitidos são SQL (padrão), ServicePrincipal, SystemAssignedManagedIdentity, UserAssignedManagedIdentity. Vá para a seção de autenticação relevante sobre propriedades e pré-requisitos específicos. | Sim |
| encriptar | Indique se a criptografia TLS é necessária para todos os dados enviados entre o cliente e o servidor. Opções: obrigatório (para verdadeiro, padrão)/opcional (para falso)/estrito. | Não |
| trustServerCertificate | Indique se o canal será criptografado enquanto ignora a cadeia de certificados para validar a confiança. | Não |
| hostNameInCertificate | O nome do host a ser usado ao validar o certificado do servidor para a conexão. Quando não especificado, o nome do servidor é usado para validação de certificado. | Não |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Tempo de Execução de Integração do Azure ou um tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Para obter propriedades de conexão adicionais, consulte a tabela abaixo:
| Property | Descrição | Obrigatório |
|---|---|---|
| applicationIntent | O tipo de carga de trabalho do aplicativo ao se conectar a um servidor. Os valores permitidos são ReadOnly e ReadWrite. |
Não |
| connectTimeout | O período de tempo (em segundos) para aguardar uma conexão com o servidor antes de encerrar a tentativa e gerar um erro. | Não |
| connectRetryCount | O número de reconexões tentadas após a identificação de uma falha de conexão ociosa. O valor deve ser um número inteiro entre 0 e 255. | Não |
| connectRetryInterval | A quantidade de tempo (em segundos) entre cada tentativa de reconexão após a identificação de uma falha de conexão ociosa. O valor deve ser um número inteiro entre 1 e 60. | Não |
| loadBalanceTimeout | O tempo mínimo (em segundos) para a conexão viver no pool de conexões antes que a conexão seja destruída. | Não |
| commandTimeout | O tempo de espera padrão (em segundos) antes de encerrar a tentativa de executar um comando e gerar um erro. | Não |
| Segurança integrada | Os valores permitidos são true ou false. Ao especificar false, indique se userName e password estão especificados na conexão. Ao especificar true, indica se as credenciais atuais da conta do Windows são usadas para autenticação. |
Não |
| Parceiro de failover | O nome ou endereço do servidor parceiro ao qual se conectar se o servidor primário estiver inativo. | Não |
| maxPoolSize | O número máximo de conexões permitido no pool de conexões para a conexão específica. | Não |
| minPoolSize | O número mínimo de conexões permitidas no pool de conexões para a conexão específica. | Não |
| multipleActiveResultSets | Os valores permitidos são true ou false. Quando você especifica true, um aplicativo pode manter vários conjuntos de resultados ativos (MARS). Quando você especifica false, um aplicativo deve processar ou cancelar todos os conjuntos de resultados de um lote antes de poder executar quaisquer outros lotes nessa conexão. |
Não |
| multiSubnetFailover | Os valores permitidos são true ou false. Se seu aplicativo estiver se conectando a um grupo de disponibilidade (AG) AlwaysOn em sub-redes diferentes, definir essa propriedade para true fornecer deteção e conexão mais rápidas com o servidor ativo no momento. |
Não |
| packetSize | O tamanho em bytes dos pacotes de rede usados para se comunicar com uma instância do servidor. | Não |
| Agrupamento | Os valores permitidos são true ou false. Quando você especificar true, a conexão será agrupada. Quando você especificar false, a conexão será aberta explicitamente toda vez que a conexão for solicitada. |
Não |
Autenticação do SQL
Para usar a autenticação SQL, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| nome de utilizador | O nome de usuário usado para se conectar ao servidor. | Sim |
| password | A senha para o nome de usuário. Marque este campo como SecureString para armazená-lo com segurança. Ou, você pode fazer referência a um segredo armazenado no Cofre da Chave do Azure. | Sim |
Exemplo: usando a autenticação SQL
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "SecureString",
"value": "<password>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: palavra-passe no Cofre de Chaves do Azure
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SQL",
"userName": "<user name>",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação do principal de serviço
Para usar a autenticação da entidade de serviço, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| servicePrincipalId | Especifique o ID do cliente do aplicativo. | Sim |
| servicePrincipalCredential | A credencial da entidade de serviço. Especifique a chave do aplicativo. Marque este campo como SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
| tenant | Especifique as informações do locatário (nome de domínio ou ID do locatário) sob as quais seu aplicativo reside. Você pode recuperá-lo passando o mouse no canto superior direito do portal do Azure. | Sim |
| azureCloudType | Para autenticação da entidade de serviço, especifique o tipo de ambiente de nuvem do Azure no qual seu aplicativo Microsoft Entra está registrado. Os valores permitidos são AzurePublic, AzureChina, AzureUsGovernmente AzureGermany. Por padrão, a fábrica de dados ou o ambiente de nuvem do pipeline Synapse é usado. |
Não |
Você também precisa seguir os passos abaixo:
Crie um aplicativo Microsoft Entra a partir do portal do Azure. Anote o nome do aplicativo e os seguintes valores que definem o serviço vinculado:
- ID da aplicação
- Chave de aplicação
- ID de Inquilino do
Provisione um administrador do Microsoft Entra para seu servidor no portal do Azure, se ainda não tiver feito isso. O administrador do Microsoft Entra pode ser um usuário do Microsoft Entra ou um grupo do Microsoft Entra. Se você conceder ao grupo com identidade gerenciada uma função de administrador, ignore as etapas 3 e 4. O administrador terá acesso total à base de dados.
Crie usuários de banco de dados contidos para a entidade de serviço. Conecte-se ao data warehouse do qual você deseja copiar dados usando ferramentas como o SSMS, com uma identidade do Microsoft Entra que tenha pelo menos a permissão ALTER ANY USER. Execute o seguinte T-SQL:
CREATE USER [your_application_name] FROM EXTERNAL PROVIDER;Conceda à entidade de serviço as permissões necessárias como normalmente faz para usuários SQL ou outros. Execute o código a seguir ou consulte mais opções aqui. Se você quiser usar o PolyBase para carregar os dados, saiba a permissão de banco de dados necessária.
EXEC sp_addrolemember db_owner, [your application name];Configure um serviço vinculado do Azure Synapse Analytics em um espaço de trabalho do Azure Data Factory ou Synapse.
Exemplo de serviço vinculado que usa a autenticação da entidade de serviço
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"connectionString": "Server=tcp:<servername>.database.windows.net,1433;Database=<databasename>;Connection Timeout=30",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<application key>"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Identidades gerenciadas atribuídas pelo sistema para autenticação de recursos do Azure
Um data factory ou espaço de trabalho Synapse pode ser associado a uma identidade gerenciada atribuída pelo sistema para recursos do Azure que representa o recurso. Você pode usar essa identidade gerenciada para autenticação do Azure Synapse Analytics. O recurso designado pode acessar e copiar dados de ou para seu data warehouse usando essa identidade.
Para usar a autenticação de identidade gerenciada atribuída pelo sistema, especifique as propriedades genéricas descritas na seção anterior e siga estas etapas.
Provisione um administrador do Microsoft Entra para seu servidor no portal do Azure, se ainda não tiver feito isso. O administrador do Microsoft Entra pode ser um usuário do Microsoft Entra ou um grupo do Microsoft Entra. Se você conceder ao grupo com identidade gerenciada atribuída pelo sistema uma função de administrador, ignore as etapas 3 e 4. O administrador terá acesso total à base de dados.
Crie usuários de banco de dados contidos para a identidade gerenciada atribuída ao sistema. Conecte-se ao data warehouse do qual você deseja copiar dados usando ferramentas como o SSMS, com uma identidade do Microsoft Entra que tenha pelo menos a permissão ALTER ANY USER. Execute o seguinte T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Conceda as permissões necessárias à identidade gerenciada atribuída ao sistema, como você normalmente faz para usuários SQL e outros. Execute o código a seguir ou consulte mais opções aqui. Se você quiser usar o PolyBase para carregar os dados, saiba a permissão de banco de dados necessária.
EXEC sp_addrolemember db_owner, [your_resource_name];Configure um serviço vinculado do Azure Synapse Analytics.
Exemplo:
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "SystemAssignedManagedIdentity"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Autenticação de identidade gerenciada atribuída pelo usuário
Um data factory ou espaço de trabalho Synapse pode ser associado a uma identidade gerenciada atribuída pelo usuário que representa o recurso. Você pode usar essa identidade gerenciada para autenticação do Azure Synapse Analytics. O recurso designado pode acessar e copiar dados de ou para seu data warehouse usando essa identidade.
Para usar a autenticação de identidade gerenciada atribuída pelo usuário, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| credenciais | Especifique a identidade gerenciada atribuída pelo usuário como o objeto de credencial. | Sim |
Você também precisa seguir os passos abaixo:
Provisione um administrador do Microsoft Entra para seu servidor no portal do Azure, se ainda não tiver feito isso. O administrador do Microsoft Entra pode ser um usuário do Microsoft Entra ou um grupo do Microsoft Entra. Se você conceder ao grupo com identidade gerenciada atribuída pelo usuário uma função de administrador, ignore as etapas 3. O administrador terá acesso total à base de dados.
Crie usuários de banco de dados contidos para a identidade gerenciada atribuída pelo usuário. Conecte-se ao data warehouse do qual você deseja copiar dados usando ferramentas como o SSMS, com uma identidade do Microsoft Entra que tenha pelo menos a permissão ALTER ANY USER. Execute o seguinte T-SQL.
CREATE USER [your_resource_name] FROM EXTERNAL PROVIDER;Crie uma ou várias identidades gerenciadas atribuídas pelo usuário e conceda à identidade gerenciada atribuída pelo usuário as permissões necessárias como você normalmente faz para usuários SQL e outros. Execute o código a seguir ou consulte mais opções aqui. Se você quiser usar o PolyBase para carregar os dados, saiba a permissão de banco de dados necessária.
EXEC sp_addrolemember db_owner, [your_resource_name];Atribua uma ou várias identidades gerenciadas atribuídas pelo usuário ao seu data factory e crie credenciais para cada identidade gerenciada atribuída pelo usuário.
Configure um serviço vinculado do Azure Synapse Analytics.
Exemplo
{
"name": "AzureSqlDWLinkedService",
"properties": {
"type": "AzureSqlDW",
"typeProperties": {
"server": "<name or network address of the SQL server instance>",
"database": "<database name>",
"encrypt": "<encrypt>",
"trustServerCertificate": false,
"authenticationType": "UserAssignedManagedIdentity",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Versão legada
Estas propriedades genéricas são suportadas para um serviço vinculado do Azure Synapse Analytics quando você aplica a versão herdada :
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type deve ser definida como AzureSqlDW. | Sim |
| connectionString | Especifique as informações necessárias para se conectar à instância do Azure Synapse Analytics para a propriedade connectionString . Marque este campo como um SecureString para armazená-lo com segurança. Você também pode colocar senha/chave principal de serviço no Cofre de Chaves do Azure e, se for autenticação SQL, extraia a password configuração da cadeia de conexão. Consulte o artigo Armazenar credenciais no Cofre da Chave do Azure com mais detalhes. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Tempo de Execução de Integração do Azure ou um tempo de execução de integração auto-hospedado (se seu armazenamento de dados estiver localizado em uma rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Para diferentes tipos de autenticação, consulte as seguintes seções sobre propriedades específicas e pré-requisitos, respectivamente:
- Autenticação SQL para a versão herdada
- Autenticação da entidade de serviço para a versão herdada
- Autenticação de identidade gerenciada atribuída pelo sistema para a versão herdada
- Autenticação de identidade gerenciada atribuída pelo usuário para a versão herdada
Autenticação SQL para a versão herdada
Para usar a autenticação SQL, especifique as propriedades genéricas descritas na seção anterior.
Autenticação da entidade de serviço para a versão herdada
Para usar a autenticação da entidade de serviço, além das propriedades genéricas descritas na seção anterior, especifique as seguintes propriedades:
| Property | Descrição | Obrigatório |
|---|---|---|
| servicePrincipalId | Especifique o ID do cliente do aplicativo. | Sim |
| servicePrincipalKey | Especifique a chave do aplicativo. Marque este campo como um SecureString para armazená-lo com segurança ou faça referência a um segredo armazenado no Cofre de Chaves do Azure. | Sim |
| tenant | Especifique as informações do locatário, como o nome de domínio ou ID do locatário, sob o qual seu aplicativo reside. Recupere-o passando o mouse no canto superior direito do portal do Azure. | Sim |
| azureCloudType | Para autenticação da entidade de serviço, especifique o tipo de ambiente de nuvem do Azure no qual seu aplicativo Microsoft Entra está registrado. Os valores permitidos são AzurePublic, AzureChina, AzureUsGovernment e AzureGermany. Por padrão, a fábrica de dados ou o ambiente de nuvem do pipeline Synapse é usado. |
Não |
Você também precisa seguir as etapas em Autenticação da entidade de serviço para conceder a permissão correspondente.
Autenticação de identidade gerenciada atribuída pelo sistema para a versão herdada
Para usar a autenticação de identidade gerenciada atribuída pelo sistema, siga a mesma etapa para a versão recomendada em Autenticação de identidade gerenciada atribuída pelo sistema.
Autenticação de identidade gerenciada atribuída pelo usuário para versão herdada
Para usar a autenticação de identidade gerenciada atribuída pelo usuário, siga a mesma etapa para a versão recomendada em Autenticação de identidade gerenciada atribuída pelo usuário.
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo Conjuntos de dados.
As seguintes propriedades são suportadas para o conjunto de dados do Azure Synapse Analytics:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como AzureSqlDWTable. | Sim |
| esquema | Nome do esquema. | Não para a fonte, Sim para o lavatório |
| tabela | Nome da tabela/vista. | Não para a fonte, Sim para o lavatório |
| tableName | Nome da tabela/vista com esquema. Esta propriedade é suportada para compatibilidade com versões anteriores. Para nova carga de trabalho, use schema e table. |
Não para a fonte, Sim para o lavatório |
Exemplo de propriedades de conjunto de dados
{
"name": "AzureSQLDWDataset",
"properties":
{
"type": "AzureSqlDWTable",
"linkedServiceName": {
"referenceName": "<Azure Synapse Analytics linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
}
}
}
Copiar propriedades da atividade
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pela fonte e coletor do Azure Synapse Analytics.
Azure Synapse Analytics como a origem
Gorjeta
Para carregar dados do Azure Synapse Analytics de forma eficiente usando o particionamento de dados, saiba mais em Cópia paralela do Azure Synapse Analytics.
Para copiar dados do Azure Synapse Analytics, defina a propriedade type na fonte Copy Activity como SqlDWSource. As seguintes propriedades são suportadas na seção Copiar fonte de atividade:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type da fonte Copy Activity deve ser definida como SqlDWSource. | Sim |
| sqlReaderQuery | Use a consulta SQL personalizada para ler dados. Exemplo: select * from MyTable. |
Não |
| sqlReaderStoredProcedureName | O nome do procedimento armazenado que lê dados da tabela de origem. A última instrução SQL deve ser uma instrução SELECT no procedimento armazenado. | Não |
| storedProcedureParameters | Parâmetros para o procedimento armazenado. Os valores permitidos são pares de nome ou valor. Os nomes e o invólucro dos parâmetros devem corresponder aos nomes e invólucros dos parâmetros do procedimento armazenado. |
Não |
| Nível de isolamento | Especifica o comportamento de bloqueio de transação para a fonte SQL. Os valores permitidos são: ReadCommitted, ReadUncommitted, RepeatableRead, Serializable, Snapshot. Se não for especificado, o nível de isolamento padrão do banco de dados será usado. Para obter mais informações, consulte system.data.isolationlevel. | Não |
| partitionOptions | Especifica as opções de particionamento de dados usadas para carregar dados do Azure Synapse Analytics. Os valores permitidos são: None (padrão), PhysicalPartitionsOfTable e DynamicRange. Quando uma opção de partição é habilitada (ou seja, não None), o grau de paralelismo para carregar simultaneamente dados de uma Análise Synapse do Azure é controlado pela parallelCopies configuração na atividade de cópia. |
Não |
| partitionSettings | Especifique o grupo de configurações para particionamento de dados. Aplique quando a opção de partição não Nonefor . |
Não |
Em partitionSettings: |
||
| partitionColumnName | Especifique o nome da coluna de origem no número inteiro ou no tipo data/data/hora (int, smallint, bigint, date, smalldatetimedatetimedatetime2, , ou datetimeoffset) que será usado pelo particionamento de intervalo para cópia paralela. Se não for especificado, o índice ou a chave primária da tabela é detetado automaticamente e usado como a coluna de partição.Aplique quando a opção de partição for DynamicRange. Se você usar uma consulta para recuperar os dados de origem, conecte ?DfDynamicRangePartitionCondition a cláusula WHERE. Para obter um exemplo, consulte a seção Cópia paralela do banco de dados SQL. |
Não |
| partiçãoUpperBound | O valor máximo da coluna de partição para divisão do intervalo de partições. Esse valor é usado para decidir a passada da partição, não para filtrar as linhas na tabela. Todas as linhas na tabela ou no resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detetará automaticamente o valor. Aplique quando a opção de partição for DynamicRange. Para obter um exemplo, consulte a seção Cópia paralela do banco de dados SQL. |
Não |
| partiçãoLowerBound | O valor mínimo da coluna de partição para divisão do intervalo de partições. Esse valor é usado para decidir a passada da partição, não para filtrar as linhas na tabela. Todas as linhas na tabela ou no resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detetará automaticamente o valor. Aplique quando a opção de partição for DynamicRange. Para obter um exemplo, consulte a seção Cópia paralela do banco de dados SQL. |
Não |
Observe o seguinte ponto:
- Ao usar o procedimento armazenado na origem para recuperar dados, observe se o procedimento armazenado for projetado como retornando esquema diferente quando um valor de parâmetro diferente for passado, você poderá encontrar falha ou ver um resultado inesperado ao importar esquema da interface do usuário ou ao copiar dados para o banco de dados SQL com a criação automática de tabelas.
Exemplo: usando a consulta SQL
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemplo: usando procedimento armazenado
"activities":[
{
"name": "CopyFromAzureSQLDW",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure Synapse Analytics input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlDWSource",
"sqlReaderStoredProcedureName": "CopyTestSrcStoredProcedureWithParameters",
"storedProcedureParameters": {
"stringData": { "value": "str3" },
"identifier": { "value": "$$Text.Format('{0:yyyy}', <datetime parameter>)", "type": "Int"}
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Exemplo de procedimento armazenado:
CREATE PROCEDURE CopyTestSrcStoredProcedureWithParameters
(
@stringData varchar(20),
@identifier int
)
AS
SET NOCOUNT ON;
BEGIN
select *
from dbo.UnitTestSrcTable
where dbo.UnitTestSrcTable.stringData != stringData
and dbo.UnitTestSrcTable.identifier != identifier
END
GO
Azure Synapse Analytics como coletor
Os pipelines do Azure Data Factory e do Synapse oferecem suporte a três maneiras de carregar dados no Azure Synapse Analytics.
- Usar instrução COPY
- Usar o PolyBase
- Usar inserção em massa
A maneira mais rápida e escalável de carregar dados é através da instrução COPY ou do PolyBase.
Para copiar dados para o Azure Synapse Analytics, defina o tipo de coletor em Copiar atividade como SqlDWSink. As seguintes propriedades são suportadas na seção Copiar coletor de atividade:
| Property | Descrição | Obrigatório |
|---|---|---|
| tipo | A propriedade type do coletor Copy Activity deve ser definida como SqlDWSink. | Sim |
| allowPolyBase | Indica se o PolyBase deve ser usado para carregar dados no Azure Synapse Analytics. allowCopyCommand e allowPolyBase não pode ser ambas verdadeiras. Consulte a seção Usar o PolyBase para carregar dados no Azure Synapse Analytics para obter restrições e detalhes. Os valores permitidos são True e False (padrão). |
N.º Aplique ao usar o PolyBase. |
| polyBaseSettings | Um grupo de propriedades que podem ser especificadas quando a allowPolybase propriedade é definida como true. |
N.º Aplique ao usar o PolyBase. |
| allowCopyCommand | Indica se a instrução COPY deve ser usada para carregar dados no Azure Synapse Analytics. allowCopyCommand e allowPolyBase não pode ser ambas verdadeiras. Consulte a seção Usar instrução COPY para carregar dados no Azure Synapse Analytics para obter restrições e detalhes. Os valores permitidos são True e False (padrão). |
N.º Aplique ao usar COPY. |
| copyCommandSettings | Um grupo de propriedades que podem ser especificadas quando allowCopyCommand a propriedade é definida como TRUE. |
N.º Aplique ao usar COPY. |
| writeBatchSize | Número de linhas a serem inseridas na tabela SQL por lote. O valor permitido é inteiro (número de linhas). Por padrão, o serviço determina dinamicamente o tamanho de lote apropriado com base no tamanho da linha. |
N.º Aplicar ao usar inserção em massa. |
| writeBatchTimeout | O tempo de espera para que a operação de inserção, upsert e procedimento armazenado seja concluída antes que ele atinja o tempo limite. Os valores permitidos são para o período de tempo. Um exemplo é "00:30:00" por 30 minutos. Se nenhum valor for especificado, o tempo limite será padronizado como "00:30:00". |
N.º Aplicar ao usar inserção em massa. |
| pré-CopyScript | Especifique uma consulta SQL para que a Atividade de Cópia seja executada antes de gravar dados no Azure Synapse Analytics em cada execução. Use essa propriedade para limpar os dados pré-carregados. | Não |
| tableOption | Especifica se a tabela de coletor deve ser criada automaticamente, se ela não existir, com base no esquema de origem. Os valores permitidos são: none (padrão), autoCreate. |
Não |
| disableMetricsCollection | O serviço coleta métricas como DWUs do Azure Synapse Analytics para otimização de desempenho de cópia e recomendações, que introduzem acesso adicional ao banco de dados mestre. Se você estiver preocupado com esse comportamento, especifique true para desativá-lo. |
Não (o padrão é false) |
| maxConcurrentConnections | O limite superior de conexões simultâneas estabelecidas para o armazenamento de dados durante a execução da atividade. Especifique um valor somente quando quiser limitar conexões simultâneas. | Não |
| WriteBehavior | Especifique o comportamento de gravação para a atividade de cópia para carregar dados no Azure Synapse Analytics. O valor permitido é Inserir e Upsert. Por padrão, o serviço usa inserir para carregar dados. |
Não |
| upsertSettings | Especifique o grupo de configurações para o comportamento de gravação. Aplique quando a opção WriteBehavior for Upsert. |
Não |
Em upsertSettings: |
||
| chaves | Especifique os nomes das colunas para identificação de linha exclusiva. Uma única chave ou uma série de chaves podem ser usadas. Se não for especificado, a chave primária será usada. | Não |
| interimSchemaName | Especifique o esquema provisório para a criação da tabela provisória. Nota: o usuário precisa ter a permissão para criar e excluir tabela. Por padrão, a tabela provisória compartilhará o mesmo esquema da tabela de coletores. | Não |
Exemplo 1: Coletor do Azure Synapse Analytics
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true,
"polyBaseSettings":
{
"rejectType": "percentage",
"rejectValue": 10.0,
"rejectSampleValue": 100,
"useTypeDefault": true
}
}
Exemplo 2: Dados Upsert
"sink": {
"type": "SqlDWSink",
"writeBehavior": "Upsert",
"upsertSettings": {
"keys": [
"<column name>"
],
"interimSchemaName": "<interim schema name>"
},
}
Cópia paralela do Azure Synapse Analytics
O conector do Azure Synapse Analytics na atividade de cópia fornece particionamento de dados interno para copiar dados em paralelo. Você pode encontrar opções de particionamento de dados na guia Origem da atividade de cópia.
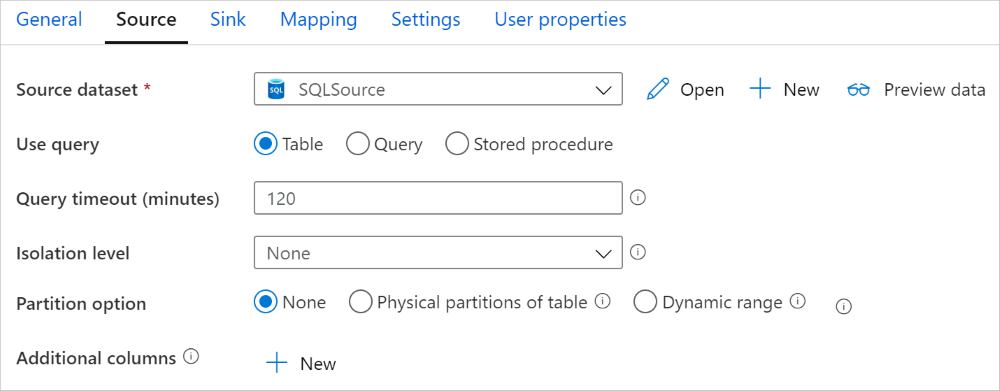
Quando você habilita a cópia particionada, a atividade de cópia executa consultas paralelas na fonte do Azure Synapse Analytics para carregar dados por partições. O grau paralelo é controlado pela parallelCopies configuração na atividade de cópia. Por exemplo, se você definir parallelCopies como quatro, o serviço gerará e executará simultaneamente quatro consultas com base na opção e nas configurações de partição especificadas, e cada consulta recuperará uma parte dos dados do Azure Synapse Analytics.
Sugere-se que habilite a cópia paralela com particionamento de dados, especialmente quando carrega uma grande quantidade de dados do Azure Synapse Analytics. A seguir estão sugeridas configurações para diferentes cenários. Ao copiar dados para o armazenamento de dados baseado em arquivo, é recomendável gravar em uma pasta como vários arquivos (especifique apenas o nome da pasta), caso em que o desempenho é melhor do que gravar em um único arquivo.
| Cenário | Configurações sugeridas |
|---|---|
| Carga completa a partir de uma mesa grande, com divisórias físicas. | Opção de partição: Partições físicas da tabela. Durante a execução, o serviço deteta automaticamente as partições físicas e copia os dados por partições. Para verificar se a sua tabela tem partição física ou não, pode consultar esta consulta. |
| Carga completa a partir de uma tabela grande, sem partições físicas, enquanto com uma coluna inteira ou datetime para particionamento de dados. | Opções de partição: Partição de intervalo dinâmico. Coluna de partição (opcional): especifique a coluna usada para particionar dados. Se não for especificado, o índice ou a coluna de chave primária será usado. Limite superior da partição e limite inferior da partição (opcional): Especifique se deseja determinar o passo da partição. Isso não é para filtrar as linhas na tabela, todas as linhas na tabela serão particionadas e copiadas. Se não for especificado, a atividade de cópia detetará automaticamente os valores. Por exemplo, se a coluna de partição "ID" tiver valores que variam de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com cópia paralela como 4, o serviço recuperará dados por 4 partições - IDs no intervalo <=20, [21, 50], [51, 80] e >=81, respectivamente. |
| Carregue uma grande quantidade de dados usando uma consulta personalizada, sem partições físicas, enquanto com uma coluna inteira ou data/data/hora para particionamento de dados. | Opções de partição: Partição de intervalo dinâmico. Consulta: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>.Coluna de partição: especifique a coluna usada para particionar dados. Limite superior da partição e limite inferior da partição (opcional): Especifique se deseja determinar o passo da partição. Isso não é para filtrar as linhas na tabela, todas as linhas no resultado da consulta serão particionadas e copiadas. Se não for especificado, a atividade de cópia detetará automaticamente o valor. Por exemplo, se a coluna de partição "ID" tiver valores que variam de 1 a 100 e você definir o limite inferior como 20 e o limite superior como 80, com cópia paralela como 4, o serviço recuperará dados por 4 partições - IDs no intervalo <=20, [21, 50], [51, 80] e >=81, respectivamente. Aqui estão mais consultas de exemplo para diferentes cenários: 1. Consulte toda a tabela: SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition2. Consulta a partir de uma tabela com seleção de colunas e filtros adicionais de cláusula where: SELECT <column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>3. Consulta com subconsultas: SELECT <column_list> FROM (<your_sub_query>) AS T WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>4. Consulta com partição em subconsulta: SELECT <column_list> FROM (SELECT <your_sub_query_column_list> FROM <TableName> WHERE ?DfDynamicRangePartitionCondition) AS T |
Práticas recomendadas para carregar dados com a opção de partição:
- Escolha uma coluna distinta como coluna de partição (como chave primária ou chave exclusiva) para evitar distorção de dados.
- Se a tabela tiver partição incorporada, use a opção de partição "Partições físicas da tabela" para obter um melhor desempenho.
- Se você usar o Tempo de Execução de Integração do Azure para copiar dados, poderá definir "Unidades de Integração de Dados (DIU)" (>4) maiores para utilizar mais recursos de computação. Verifique os cenários aplicáveis lá.
- "Grau de paralelismo de cópia" controlar os números de partição, definir este número muito grande às vezes prejudica o desempenho, recomendo definir este número como (DIU ou número de nós IR auto-hospedados) * (2 a 4).
- Observação O Azure Synapse Analytics pode executar um máximo de 32 consultas por momento, definir "Grau de paralelismo de cópia" muito grande pode causar um problema de limitação do Synapse.
Exemplo: carga completa a partir de uma mesa grande com partições físicas
"source": {
"type": "SqlDWSource",
"partitionOption": "PhysicalPartitionsOfTable"
}
Exemplo: consulta com partição de intervalo dinâmico
"source": {
"type": "SqlDWSource",
"query": "SELECT * FROM <TableName> WHERE ?DfDynamicRangePartitionCondition AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column (optional) to decide the partition stride, not as data filter>",
"partitionLowerBound": "<lower_value_of_partition_column (optional) to decide the partition stride, not as data filter>"
}
}
Exemplo de consulta para verificar a partição física
SELECT DISTINCT s.name AS SchemaName, t.name AS TableName, c.name AS ColumnName, CASE WHEN c.name IS NULL THEN 'no' ELSE 'yes' END AS HasPartition
FROM sys.tables AS t
LEFT JOIN sys.objects AS o ON t.object_id = o.object_id
LEFT JOIN sys.schemas AS s ON o.schema_id = s.schema_id
LEFT JOIN sys.indexes AS i ON t.object_id = i.object_id
LEFT JOIN sys.index_columns AS ic ON ic.partition_ordinal > 0 AND ic.index_id = i.index_id AND ic.object_id = t.object_id
LEFT JOIN sys.columns AS c ON c.object_id = ic.object_id AND c.column_id = ic.column_id
LEFT JOIN sys.types AS y ON c.system_type_id = y.system_type_id
WHERE s.name='[your schema]' AND t.name = '[your table name]'
Se a tabela tiver partição física, você verá "HasPartition" como "yes".
Usar a instrução COPY para carregar dados no Azure Synapse Analytics
Usar a instrução COPY é uma maneira simples e flexível de carregar dados no Azure Synapse Analytics com alta taxa de transferência. Para saber mais detalhes, verifique Dados de carregamento em massa usando a instrução COPY
- Se os dados de origem estiverem no Blob do Azure ou no Azure Data Lake Storage Gen2 e o formato for compatível com a instrução COPY, você poderá usar a atividade de cópia para invocar diretamente a instrução COPY para permitir que o Azure Synapse Analytics extraia os dados da origem. Para obter detalhes, consulte Cópia direta usando a instrução COPY.
- Se o armazenamento de dados de origem e o formato não forem originalmente suportados pela instrução COPY, use o recurso Cópia em etapas usando a instrução COPY. O recurso de cópia em estágios também oferece uma melhor taxa de transferência. Ele converte automaticamente os dados em formato compatível com a instrução COPY, armazena os dados no armazenamento de Blob do Azure e, em seguida, chama a instrução COPY para carregar dados no Azure Synapse Analytics.
Gorjeta
Ao usar a instrução COPY com o Azure Integration Runtime, as Unidades de Integração de Dados (DIU) efetivas são sempre 2. O ajuste da DIU não afeta o desempenho, pois o carregamento de dados do armazenamento é alimentado pelo mecanismo Azure Synapse.
Cópia direta usando a instrução COPY
A instrução COPY do Azure Synapse Analytics dá suporte diretamente ao Blob do Azure e ao Azure Data Lake Storage Gen2. Se seus dados de origem atenderem aos critérios descritos nesta seção, use a instrução COPY para copiar diretamente do armazenamento de dados de origem para o Azure Synapse Analytics. Caso contrário, use Cópia em etapas usando a instrução COPY. O serviço verifica as configurações e falha na execução da atividade de cópia se os critérios não forem atendidos.
O serviço vinculado de origem e o formato estão com os seguintes tipos e métodos de autenticação:
Tipo de armazenamento de dados de origem suportado Formato suportado Tipo de autenticação de origem suportado Azure Blob Texto delimitado Autenticação de chave de conta, autenticação de assinatura de acesso compartilhado, autenticação de entidade de serviço (usando ServicePrincipalKey), autenticação de identidade gerenciada atribuída pelo sistema Parquet Autenticação de chave de conta, autenticação de assinatura de acesso compartilhado ORC Autenticação de chave de conta, autenticação de assinatura de acesso compartilhado Azure Data Lake Storage Gen2 (Armazenamento do Azure Data Lake Gen2) Texto delimitado
Parquet
ORCAutenticação de chave de conta, autenticação de entidade de serviço (usando ServicePrincipalKey), autenticação de assinatura de acesso compartilhado, autenticação de identidade gerenciada atribuída pelo sistema Importante
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de armazenamento, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente.
- Se o seu Armazenamento do Azure estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
As configurações de formato são as seguintes:
- Para Parquet:
compressionpode ser sem compressão, Snappy ouGZip. - Para ORC:
compressionpode ser sem compressão,zlibou Snappy. - Para o texto delimitado:
rowDelimiteré explicitamente definido como caractere único ou "\r\n", o valor padrão não é suportado.nullValueé deixado como padrão ou definido como string vazia ("").encodingNameé deixado como padrão ou definido como utf-8 ou utf-16.escapeChardeve ser igual aquoteChar, e não está vazio.skipLineCounté deixado como padrão ou definido como 0.compressionpode ser sem compressão ouGZip.
- Para Parquet:
Se a origem for uma pasta,
recursivea atividade de cópia deve ser definida como true ewildcardFilenameprecisa ser*ou*.*.wildcardFolderPath,wildcardFilename(exceto*ou*.*),modifiedDateTimeStart, ,modifiedDateTimeEndprefix, eenablePartitionDiscoveryadditionalColumnsnão são especificados.
As seguintes configurações de instrução COPY são suportadas em allowCopyCommand atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| defaultValues | Especifica os valores padrão para cada coluna de destino no Azure Synapse Analytics. Os valores padrão na propriedade substituem a restrição DEFAULT definida no data warehouse, e a coluna de identidade não pode ter um valor padrão. | Não |
| opções adicionais | Opções adicionais que serão passadas para uma instrução COPY do Azure Synapse Analytics diretamente na cláusula "Com" na instrução COPY. Cote o valor conforme necessário para alinhar com os requisitos da instrução COPY. | Não |
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaCOPY",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true,
"copyCommandSettings": {
"defaultValues": [
{
"columnName": "col_string",
"defaultValue": "DefaultStringValue"
}
],
"additionalOptions": {
"MAXERRORS": "10000",
"DATEFORMAT": "'ymd'"
}
}
},
"enableSkipIncompatibleRow": true
}
}
]
Cópia em etapas usando a instrução COPY
Quando os dados de origem não forem nativamente compatíveis com a instrução COPY, habilite a cópia de dados por meio de um Blob do Azure de preparo provisório ou do Azure Data Lake Storage Gen2 (não pode ser o Armazenamento Premium do Azure). Nesse caso, o serviço converte automaticamente os dados para atender aos requisitos de formato de dados da instrução COPY. Em seguida, ele invoca a instrução COPY para carregar dados no Azure Synapse Analytics. Finalmente, ele limpa seus dados temporários do armazenamento. Consulte Cópia em etapas para obter detalhes sobre como copiar dados por meio de um preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure ou um serviço vinculado do Azure Data Lake Storage Gen2 com chave de conta ou autenticação de identidade gerenciada pelo sistema que se refere à conta de armazenamento do Azure como o armazenamento provisório.
Importante
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de preparo, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente. Você também precisa conceder permissões à identidade gerenciada do espaço de trabalho do Azure Synapse Analytics em sua conta de armazenamento de Blob do Azure ou Azure Data Lake Storage Gen2. Para saber como conceder essa permissão, consulte Conceder permissões à identidade gerenciada do espaço de trabalho.
- Se o seu Armazenamento do Azure de preparo estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
Importante
Se o Armazenamento do Azure de preparo estiver configurado com o Ponto de Extremidade Privado Gerenciado e tiver o firewall de armazenamento habilitado, você deverá usar a autenticação de identidade gerenciada e conceder permissões de Leitor de Dados de Blob de Armazenamento ao SQL Server Synapse para garantir que ele possa acessar os arquivos em estágios durante o carregamento da instrução COPY.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaCOPYstatement",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowCopyCommand": true
},
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Usar o PolyBase para carregar dados no Azure Synapse Analytics
Usar o PolyBase é uma maneira eficiente de carregar uma grande quantidade de dados no Azure Synapse Analytics com alta taxa de transferência. Você verá um grande ganho na taxa de transferência usando o PolyBase em vez do mecanismo BULKINSERT padrão.
- Se seus dados de origem estiverem no Blob do Azure ou no Azure Data Lake Storage Gen2 e o formato for compatível com PolyBase, você poderá usar a atividade de cópia para invocar diretamente o PolyBase para permitir que o Azure Synapse Analytics extraia os dados da origem. Para obter detalhes, consulte Cópia direta usando PolyBase.
- Se o armazenamento de dados e o formato de origem não forem originalmente suportados pelo PolyBase, use a cópia em estágios usando o recurso PolyBase . O recurso de cópia em estágios também oferece uma melhor taxa de transferência. Ele converte automaticamente os dados em formato compatível com PolyBase, armazena os dados no armazenamento de Blob do Azure e chama o PolyBase para carregar dados no Azure Synapse Analytics.
Gorjeta
Saiba mais sobre Práticas recomendadas para usar o PolyBase. Ao usar o PolyBase com o Azure Integration Runtime, as Unidades de Integração de Dados (DIU) eficazes para armazenamento direto ou em estágios para Synapse são sempre 2. O ajuste da DIU não afeta o desempenho, pois o carregamento de dados do armazenamento é alimentado pelo mecanismo Synapse.
As seguintes configurações do PolyBase são suportadas em polyBaseSettings atividade de cópia:
| Property | Descrição | Obrigatório |
|---|---|---|
| rejectValue | Especifica o número ou a porcentagem de linhas que podem ser rejeitadas antes que a consulta falhe. Saiba mais sobre as opções de rejeição do PolyBase na seção Argumentos de CREATE EXTERNAL TABLE (Transact-SQL). Os valores permitidos são 0 (padrão), 1, 2, etc. |
Não |
| rejectType | Especifica se a opção rejectValue é um valor literal ou uma porcentagem. Os valores permitidos são Valor (padrão) e Porcentagem. |
Não |
| rejectSampleValue | Determina o número de linhas a serem recuperadas antes que o PolyBase recalcule a porcentagem de linhas rejeitadas. Os valores permitidos são 1, 2, etc. |
Sim, se o rejectType for percentual. |
| useTypeDefault | Especifica como lidar com valores ausentes em arquivos de texto delimitados quando o PolyBase recupera dados do arquivo de texto. Saiba mais sobre essa propriedade na seção Argumentos em CREATE EXTERNAL FILE FORMAT (Transact-SQL). Os valores permitidos são True e False (padrão). |
Não |
Cópia direta usando o PolyBase
O Azure Synapse Analytics PolyBase suporta diretamente o Azure Blob e o Azure Data Lake Storage Gen2. Se seus dados de origem atenderem aos critérios descritos nesta seção, use o PolyBase para copiar diretamente do armazenamento de dados de origem para o Azure Synapse Analytics. Caso contrário, use Cópia em etapas usando PolyBase.
Gorjeta
Para copiar dados de forma eficiente para o Azure Synapse Analytics, saiba mais a partir do Azure Data Factory e torna ainda mais fácil e conveniente descobrir informações dos dados ao usar o Repositório Data Lake com o Azure Synapse Analytics.
Se os requisitos não forem atendidos, o serviço verificará as configurações e retornará automaticamente ao mecanismo BULKINSERT para a movimentação de dados.
O serviço vinculado de origem é com os seguintes tipos e métodos de autenticação:
Tipo de armazenamento de dados de origem suportado Tipo de autenticação de origem suportado Azure Blob Autenticação de chave de conta, autenticação de identidade gerenciada atribuída pelo sistema Azure Data Lake Storage Gen2 (Armazenamento do Azure Data Lake Gen2) Autenticação de chave de conta, autenticação de identidade gerenciada atribuída pelo sistema Importante
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de armazenamento, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente.
- Se o seu Armazenamento do Azure estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
O formato de dados de origem é de Parquet, ORC ou texto delimitado, com as seguintes configurações:
- O caminho da pasta não contém filtro curinga.
- O nome do arquivo está vazio ou aponta para um único arquivo. Se você especificar o nome do arquivo curinga na atividade de cópia, ele só poderá ser
*ou*.*. rowDelimiteré padrão, \n, \r\n ou \r.nullValueé deixado como padrão ou definido como string vazia (""), etreatEmptyAsNullé deixado como padrão ou definido como true.encodingNameé deixado como padrão ou definido como utf-8.quoteChar,escapeChareskipLineCountnão são especificados. O PolyBase suporta pular linha de cabeçalho, que pode ser configurada comofirstRowAsHeader.compressionpode ser sem compressão,GZipou Esvaziar.
Se a origem for uma pasta,
recursivea atividade de cópia deve ser definida como true.wildcardFolderPath,wildcardFilename, ,modifiedDateTimeStart,modifiedDateTimeEnd,prefix,enablePartitionDiscoveryeadditionalColumnsnão são especificados.
Nota
Se sua origem for uma pasta, observe que o PolyBase recupera arquivos da pasta e de todas as suas subpastas, e não recupera dados de arquivos para os quais o nome do arquivo começa com um sublinhado (_) ou um ponto (.), conforme documentado aqui - argumento LOCATION.
"activities":[
{
"name": "CopyFromAzureBlobToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "ParquetDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "ParquetSource",
"storeSettings":{
"type": "AzureBlobStorageReadSettings",
"recursive": true
}
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
}
}
}
]
Cópia em etapas usando o PolyBase
Quando os dados de origem não forem nativamente compatíveis com o PolyBase, habilite a cópia de dados por meio de um Blob do Azure de preparo provisório ou do Azure Data Lake Storage Gen2 (não pode ser o Armazenamento Premium do Azure). Nesse caso, o serviço converte automaticamente os dados para atender aos requisitos de formato de dados do PolyBase. Em seguida, ele invoca o PolyBase para carregar dados no Azure Synapse Analytics. Finalmente, ele limpa seus dados temporários do armazenamento. Consulte Cópia em etapas para obter detalhes sobre como copiar dados por meio de um preparo.
Para usar esse recurso, crie um serviço vinculado do Armazenamento de Blobs do Azure ou um serviço vinculado do Azure Data Lake Storage Gen2 com chave de conta ou autenticação de identidade gerenciada que se refira à conta de armazenamento do Azure como o armazenamento provisório.
Importante
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de preparo, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente. Você também precisa conceder permissões à identidade gerenciada do espaço de trabalho do Azure Synapse Analytics em sua conta de armazenamento de Blob do Azure ou Azure Data Lake Storage Gen2. Para saber como conceder essa permissão, consulte Conceder permissões à identidade gerenciada do espaço de trabalho.
- Se o seu Armazenamento do Azure de preparo estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
Importante
Se o Armazenamento do Azure de preparo estiver configurado com o Ponto de Extremidade Privado Gerenciado e tiver o firewall de armazenamento habilitado, você deverá usar a autenticação de identidade gerenciada e conceder permissões de Leitor de Dados de Blob de Armazenamento ao Synapse SQL Server para garantir que ele possa acessar os arquivos em estágios durante o carregamento do PolyBase.
"activities":[
{
"name": "CopyFromSQLServerToSQLDataWarehouseViaPolyBase",
"type": "Copy",
"inputs": [
{
"referenceName": "SQLServerDataset",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "AzureSQLDWDataset",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "SqlSource",
},
"sink": {
"type": "SqlDWSink",
"allowPolyBase": true
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
}
}
}
}
]
Práticas recomendadas para usar o PolyBase
As seções a seguir fornecem práticas recomendadas, além das mencionadas em Práticas recomendadas para o Azure Synapse Analytics.
Permissão de banco de dados necessária
Para usar o PolyBase, o usuário que carrega dados no Azure Synapse Analytics deve ter a permissão "CONTROL" no banco de dados de destino. Uma maneira de conseguir isso é adicionar o usuário como membro da função db_owner . Saiba como fazer isso na visão geral do Azure Synapse Analytics.
Tamanho da linha e limites de tipo de dados
As cargas do PolyBase são limitadas a linhas menores que 1 MB. Ele não pode ser usado para carregar para VARCHR(MAX), NVARCHAR(MAX) ou VARBINARY(MAX). Para obter mais informações, consulte Limites de capacidade de serviço do Azure Synapse Analytics.
Quando os dados de origem tiverem linhas maiores que 1 MB, convém dividir verticalmente as tabelas de origem em várias pequenas. Certifique-se de que o maior tamanho de cada linha não exceda o limite. As tabelas menores podem ser carregadas usando o PolyBase e mescladas no Azure Synapse Analytics.
Como alternativa, para dados com colunas tão largas, você pode usar não-PolyBase para carregar os dados desativando a configuração "permitir PolyBase".
Classe de recurso do Azure Synapse Analytics
Para obter a melhor taxa de transferência possível, atribua uma classe de recurso maior ao usuário que carrega dados no Azure Synapse Analytics via PolyBase.
Solução de problemas do PolyBase
Carregando para coluna decimal
Se seus dados de origem estiverem em formato de texto ou outros armazenamentos não compatíveis com PolyBase (usando cópia em estágios e PolyBase) e contiverem valor vazio a ser carregado na coluna decimal do Azure Synapse Analytics, você poderá obter o seguinte erro:
ErrorCode=FailedDbOperation, ......HadoopSqlException: Error converting data type VARCHAR to DECIMAL.....Detailed Message=Empty string can't be converted to DECIMAL.....
A solução é desmarcar a opção "Usar tipo padrão" (como false) no coletor de atividade de cópia -> configurações do PolyBase. "USE_TYPE_DEFAULT" é uma configuração nativa do PolyBase, que especifica como lidar com valores ausentes em arquivos de texto delimitados quando o PolyBase recupera dados do arquivo de texto.
Verifique a propriedade tableName no Azure Synapse Analytics
A tabela a seguir fornece exemplos de como especificar a propriedade tableName no conjunto de dados JSON. Ele mostra várias combinações de nomes de esquema e tabela.
| Esquema de banco de dados | Nome da tabela | propriedade tableName JSON |
|---|---|---|
| dbo | MyTable | MyTable ou dbo. MyTable ou [dbo]. [Minha Tabela] |
| DBO1 | MyTable | DBO1. MyTable ou [dbo1]. [Minha Tabela] |
| dbo | My.Table | [My.Table] ou [dbo]. [Meu.Tabela] |
| DBO1 | My.Table | [DBO1]. [Meu.Tabela] |
Se você vir o seguinte erro, o problema pode ser o valor especificado para a propriedade tableName . Consulte a tabela anterior para obter a maneira correta de especificar valores para a propriedade JSON tableName .
Type=System.Data.SqlClient.SqlException,Message=Invalid object name 'stg.Account_test'.,Source=.Net SqlClient Data Provider
Colunas com valores padrão
Atualmente, o recurso PolyBase aceita apenas o mesmo número de colunas que na tabela de destino. Um exemplo é uma tabela com quatro colunas onde uma delas é definida com um valor padrão. Os dados de entrada ainda precisam ter quatro colunas. Um conjunto de dados de entrada de três colunas produz um erro semelhante à seguinte mensagem:
All columns of the table must be specified in the INSERT BULK statement.
O valor NULL é uma forma especial do valor padrão. Se a coluna for anulável, os dados de entrada no blob dessa coluna podem estar vazios. Mas isso não pode faltar no conjunto de dados de entrada. O PolyBase insere NULL para valores ausentes no Azure Synapse Analytics.
Falha no acesso a arquivos externos
Se você receber o seguinte erro, verifique se está usando a autenticação de identidade gerenciada e concedeu permissões de Leitor de Dados de Blob de Armazenamento para a identidade gerenciada do espaço de trabalho Sinapse do Azure.
Job failed due to reason: at Sink '[SinkName]': shaded.msdataflow.com.microsoft.sqlserver.jdbc.SQLServerException: External file access failed due to internal error: 'Error occurred while accessing HDFS: Java exception raised on call to HdfsBridge_IsDirExist. Java exception message:\r\nHdfsBridge::isDirExist
Para obter mais informações, consulte Conceder permissões à identidade gerenciada após a criação do espaço de trabalho.
Mapeando propriedades de fluxo de dados
Ao transformar dados em fluxo de dados de mapeamento, você pode ler e gravar em tabelas do Azure Synapse Analytics. Para obter mais informações, consulte a transformação de origem e a transformação de coletor no mapeamento de fluxos de dados.
Transformação da fonte
As configurações específicas do Azure Synapse Analytics estão disponíveis na guia Opções de Origem da transformação de origem.
Entrada Selecione se você aponta sua fonte para uma tabela (equivalente a Select * from <table-name>) ou insere uma consulta SQL personalizada.
Habilitar preparo É altamente recomendável que você use essa opção em cargas de trabalho de produção com fontes do Azure Synapse Analytics. Ao executar uma atividade de fluxo de dados com fontes do Azure Synapse Analytics a partir de um pipeline, você será solicitado a fornecer uma conta de armazenamento de local de preparo e a usará para carregamento de dados em estágios. É o mecanismo mais rápido para carregar dados do Azure Synapse Analytics.
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de armazenamento, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente.
- Se o seu Armazenamento do Azure estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
- Quando você usa o pool SQL sem servidor do Azure Synapse como origem, não há suporte para habilitar o preparo.
Consulta: Se você selecionar Consulta no campo de entrada, insira uma consulta SQL para sua fonte. Essa configuração substitui qualquer tabela escolhida no conjunto de dados. As cláusulas Order By não são suportadas aqui, mas você pode definir uma instrução SELECT FROM completa. Você também pode usar funções de tabela definidas pelo usuário. select * from udfGetData() é um UDF em SQL que retorna uma tabela. Essa consulta produzirá uma tabela de origem que você pode usar em seu fluxo de dados. Usar consultas também é uma ótima maneira de reduzir linhas para testes ou pesquisas.
Exemplo de SQL: Select * from MyTable where customerId > 1000 and customerId < 2000
Tamanho do lote: insira um tamanho de lote para fragmentar dados grandes em leituras. Em fluxos de dados, essa configuração será usada para definir o cache colunar do Spark. Este é um campo de opção, que usará os padrões do Spark se for deixado em branco.
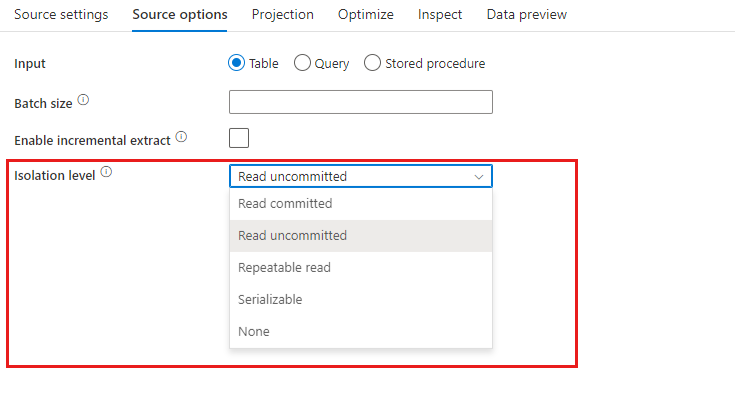
Nível de isolamento: O padrão para fontes SQL no mapeamento do fluxo de dados é ler sem confirmação. Você pode alterar o nível de isolamento aqui para um destes valores:
- Leia Comprometido
- Ler Não Comprometido
- Leitura repetível
- Serializável
- Nenhum (ignorar o nível de isolamento)
Transformação do lavatório
As configurações específicas do Azure Synapse Analytics estão disponíveis na guia Configurações da transformação do coletor.
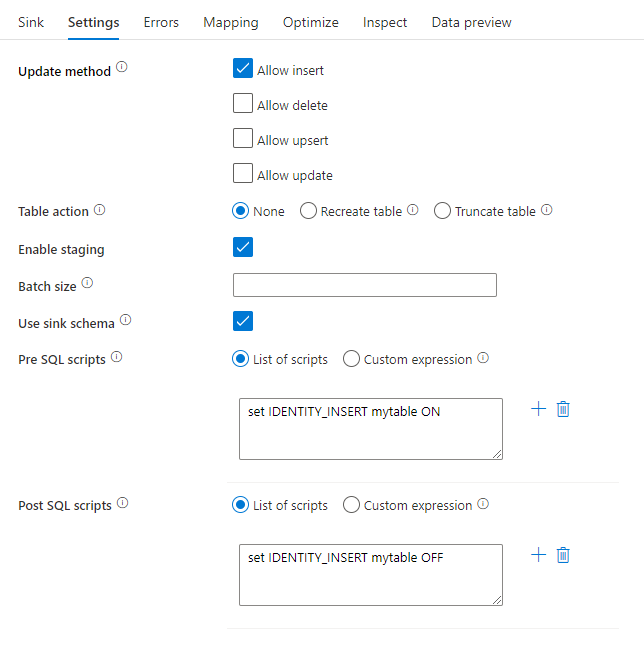
Método de atualização: determina quais operações são permitidas no destino do banco de dados. O padrão é permitir apenas inserções. Para atualizar, atualizar ou excluir linhas, uma transformação de linha de alteração é necessária para marcar linhas para essas ações. Para atualizações, upserts e exclusões, uma coluna ou colunas de chave devem ser definidas para determinar qual linha alterar.
Ação da tabela: determina se todas as linhas da tabela de destino devem ser recriadas ou removidas antes da gravação.
- Nenhuma: Nenhuma ação será feita para a mesa.
- Recriar: A tabela será descartada e recriada. Necessário se criar uma nova tabela dinamicamente.
- Truncate: Todas as linhas da tabela de destino serão removidas.
Habilitar preparo: isso permite o carregamento em SQL Pools do Azure Synapse Analytics usando o comando copy e é recomendado para a maioria dos coletores Synapse. O armazenamento de preparo é configurado na atividade Executar fluxo de dados.
- Ao usar a autenticação de identidade gerenciada para seu serviço vinculado de armazenamento, aprenda as configurações necessárias para o Blob do Azure e o Azure Data Lake Storage Gen2 , respectivamente.
- Se o seu Armazenamento do Azure estiver configurado com o ponto de extremidade do serviço VNet, você deverá usar a autenticação de identidade gerenciada com "permitir serviço confiável da Microsoft" habilitado na conta de armazenamento, consulte Impacto do uso de Pontos de Extremidade de Serviço VNet com o armazenamento do Azure.
Tamanho do lote: Controla quantas linhas estão sendo escritas em cada bucket. Lotes maiores melhoram a compactação e a otimização da memória, mas correm o risco de exceções de falta de memória ao armazenar dados em cache.
Usar esquema de coletor: Por padrão, uma tabela temporária será criada sob o esquema de coletor como preparação. Como alternativa, você pode desmarcar a opção Usar esquema de coletor e, em vez disso, em Selecionar esquema de banco de dados do usuário, especificar um nome de esquema sob o qual o Data Factory criará uma tabela de preparo para carregar dados upstream e limpá-los automaticamente após a conclusão. Verifique se você tem permissão para criar tabela no banco de dados e alterar permissão no esquema.

Scripts SQL pré e pós: insira scripts SQL de várias linhas que serão executados antes (pré-processamento) e depois que os dados (pós-processamento) forem gravados no banco de dados do Sink
Gorjeta
- Recomenda-se quebrar scripts de lote único com vários comandos em vários lotes.
- Somente instruções DDL (Data Definition Language) e DML (Data Manipulation Language) que retornam uma contagem de atualização simples podem ser executadas como parte de um lote. Saiba mais em Executando operações em lote
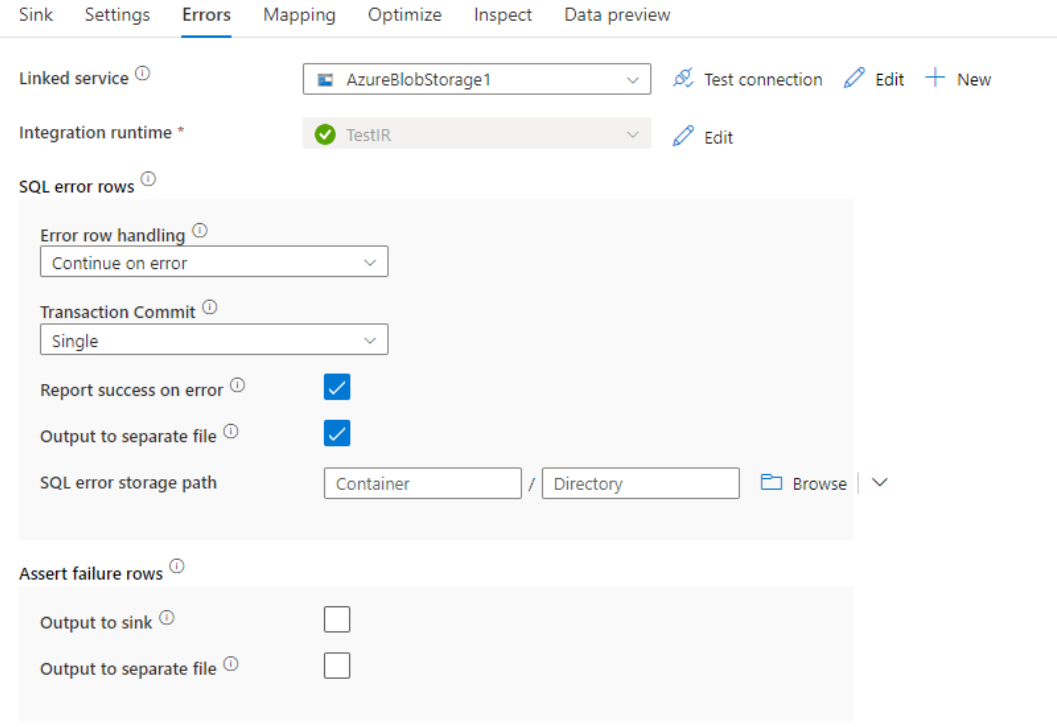
Processamento da linha de erro
Ao gravar no Azure Synapse Analytics, determinadas linhas de dados podem falhar devido a restrições definidas pelo destino. Alguns erros comuns:
- Dados binários ou de cadeia de caracteres seriam truncados na tabela
- Não é possível inserir o valor NULL na coluna
- Falha na conversão ao converter o valor em tipo de dados
Por padrão, uma execução de fluxo de dados falhará no primeiro erro que receber. Você pode optar por Continuar no erro que permite que o fluxo de dados seja concluído mesmo que linhas individuais tenham erros. O serviço fornece diferentes opções para você lidar com essas linhas de erro.
Confirmação de transação: escolha se seus dados são gravados em uma única transação ou em lotes. Uma única transação proporcionará um melhor desempenho e nenhum dado gravado será visível para outras pessoas até que a transação seja concluída. As transações em lote têm pior desempenho, mas podem funcionar para grandes conjuntos de dados.
Dados rejeitados de saída: se habilitado, você pode gerar as linhas de erro em um arquivo csv no Armazenamento de Blobs do Azure ou em uma conta do Azure Data Lake Storage Gen2 de sua escolha. Isso gravará as linhas de erro com três colunas adicionais: a operação SQL como INSERT ou UPDATE, o código de erro de fluxo de dados e a mensagem de erro na linha.
Relatar erro bem-sucedido: Se habilitado, o fluxo de dados será marcado como um sucesso, mesmo se forem encontradas linhas de erro.
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Propriedades de atividade GetMetadata
Para saber detalhes sobre as propriedades, verifique a atividade GetMetadata
Mapeamento de tipo de dados para o Azure Synapse Analytics
Quando você copia dados de ou para o Azure Synapse Analytics, os mapeamentos a seguir são usados dos tipos de dados do Azure Synapse Analytics para os tipos de dados provisórios do Azure Data Factory. Esses mapeamentos também são usados ao copiar dados de ou para o Azure Synapse Analytics usando pipelines Synapse, já que os pipelines também implementam o Azure Data Factory no Azure Synapse. Consulte Mapeamentos de esquema e tipo de dados para saber como Copiar atividade mapeia o esquema de origem e o tipo de dados para o coletor.
Gorjeta
Consulte o artigo Tipos de dados de tabela no Azure Synapse Analytics sobre os tipos de dados suportados pelo Azure Synapse Analytics e as soluções alternativas para os não suportados.
| Tipo de dados do Azure Synapse Analytics | Tipo de dados provisórios do Data Factory |
|---|---|
| bigint | Int64 |
| binário | Byte[] |
| bit | Boolean |
| char | String, Char[] |
| data | DateTime |
| Datetime | DateTime |
| datetime2 | DateTime |
| Datetimeoffset | DateTimeOffset |
| Decimal | Decimal |
| Atributo FILESTREAM (varbinary(max)) | Byte[] |
| Float | Duplo |
| image | Byte[] |
| número inteiro | Int32 |
| dinheiro | Decimal |
| Nchar | String, Char[] |
| numérico | Decimal |
| Nvarchar | String, Char[] |
| real | Única |
| versão de linha | Byte[] |
| PequenoDateTime | DateTime |
| smallint | Int16 |
| dinheiro pequeno | Decimal |
| hora | TimeSpan |
| tinyint | Byte |
| uniqueidentifier | GUID |
| Varbinary | Byte[] |
| varchar | String, Char[] |
Atualizar a versão do Azure Synapse Analytics
Para atualizar a versão do Azure Synapse Analytics, na página Editar serviço vinculado, selecione Recomendado em Versão e configure o serviço vinculado consultando as propriedades do serviço vinculado para a versão recomendada.
Diferenças entre a versão recomendada e a versão herdada
A tabela abaixo mostra as diferenças entre o Azure Synapse Analytics usando a versão recomendada e a versão herdada.
| Versão recomendada | Versão legada |
|---|---|
Suporte TLS 1.3 via encrypt como strict. |
TLS 1.3 não é suportado. |
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores por Atividade de Cópia, consulte Armazenamentos e formatos de dados suportados.