Atividade do Power Query no Azure Data Factory
A atividade do Power Query permite-lhe criar e executar mash-ups do Power Query para executar disputas de dados em escala num pipeline do Data Factory. Pode criar um novo mash-up do Power Query a partir da opção do menu Novos recursos ou adicionando uma Atividade de Energia ao seu pipeline.
Pode trabalhar diretamente dentro do editor de mash-up do Power Query para executar a exploração interativa de dados e, em seguida, guardar o seu trabalho. Depois de concluído, pode pegar na sua atividade do Power Query e adicioná-la a um pipeline. O Azure Data Factory irá dimensioná-lo automaticamente e operacionalizar sua disputa de dados usando o ambiente Spark de fluxo de dados do Azure Data Factory.
Criar uma atividade do Power Query com a IU
Para utilizar uma atividade do Power Query num pipeline, conclua os seguintes passos:
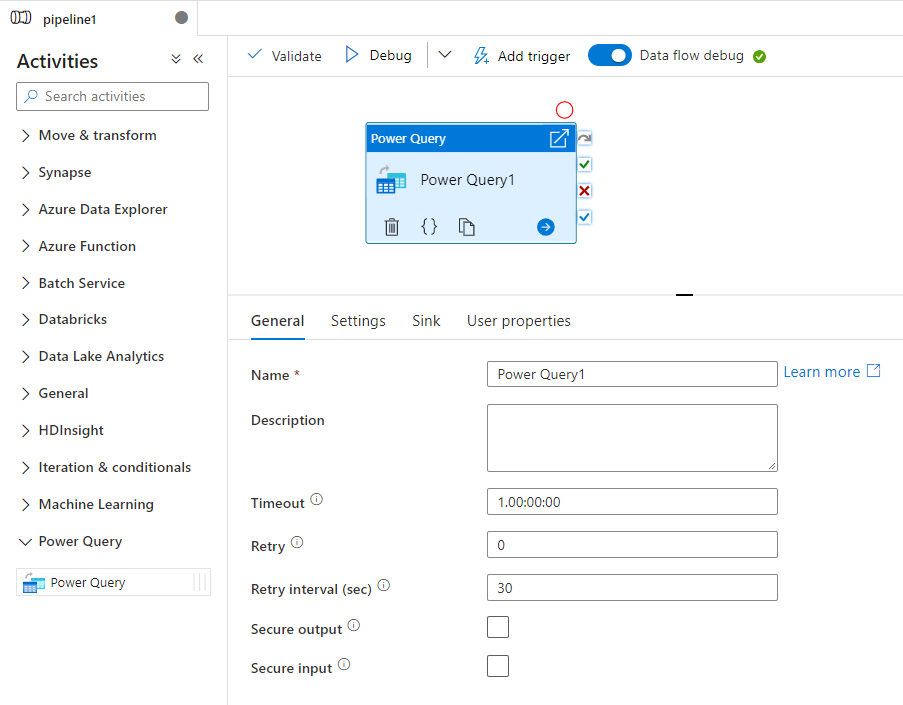
Procure o Power Query no painel Atividades do pipeline e arraste uma atividade do Power Query para a tela do pipeline.
Selecione a nova atividade do Power Query na tela, se ainda não estiver selecionada, e a guia Configurações para editar seus detalhes.
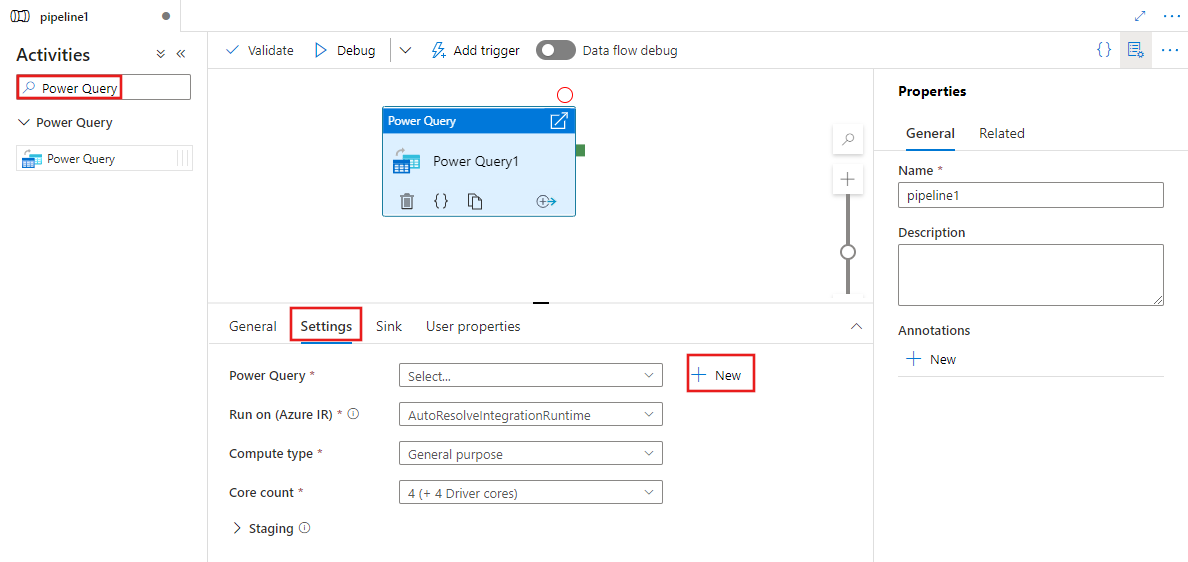
Selecione um Power Query existente e selecione Abrir, ou selecione o botão Novo para criar um novo Power Query, abrindo o editor do Power Query.
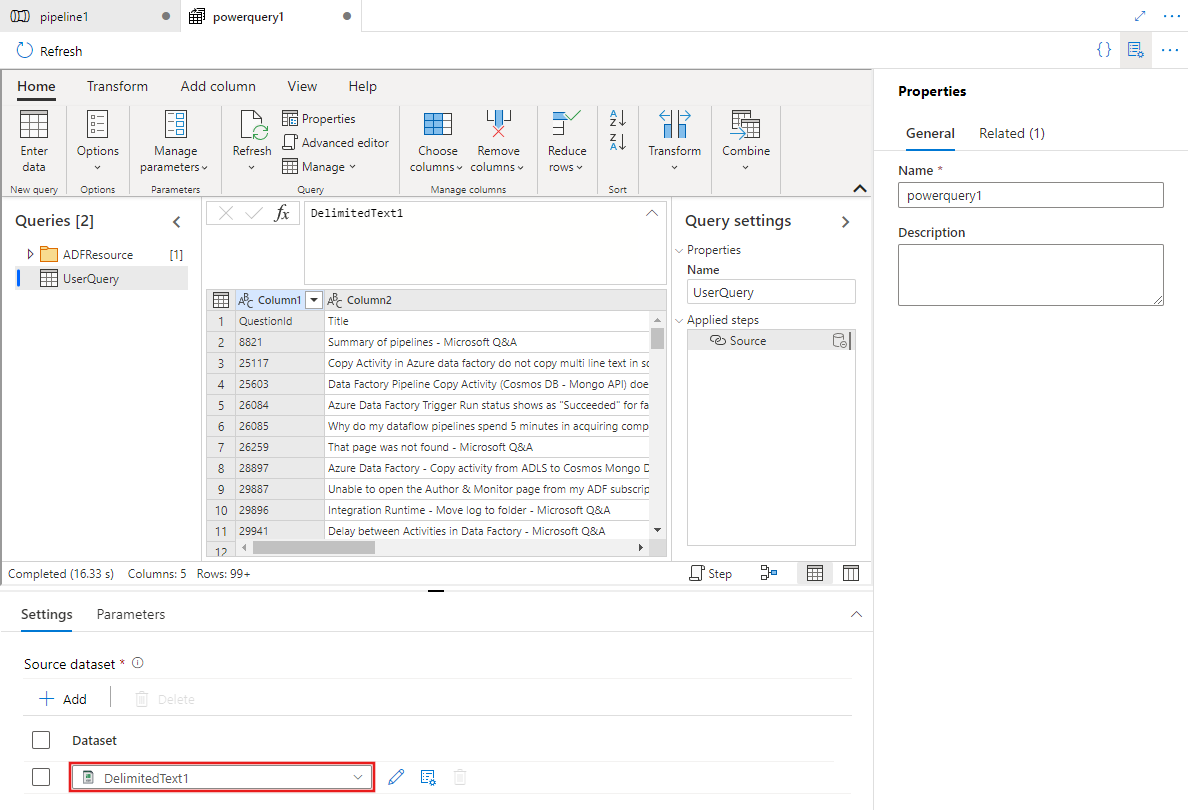
Selecione um conjunto de dados existente ou selecione Novo para definir um novo. Utilize as funcionalidades avançadas do Power Query diretamente na experiência de edição de pipeline para transformar o conjunto de dados da forma que necessitar. Você pode adicionar várias consultas de vários conjuntos de dados no editor e usá-las posteriormente.
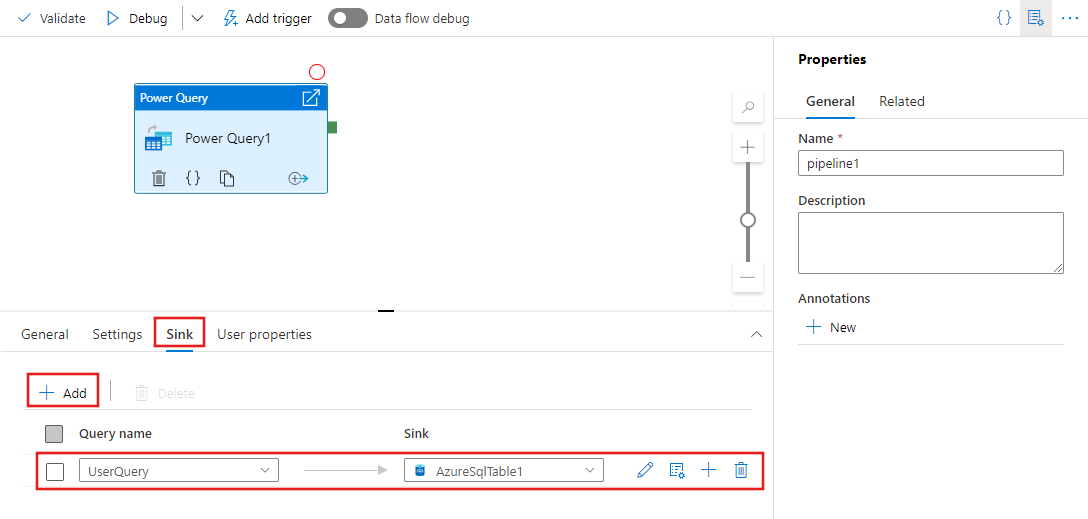
Depois de definir uma ou mais Consultas de Energia na etapa anterior, você também pode designar locais de coletor para qualquer/todos/nenhum deles, na guia Coletor para a atividade do Power Query.
Também pode utilizar a saída da sua atividade do Power Query como entradas para outras atividades. Eis um exemplo de uma atividade For Each que faz referência à saída do Power Query previamente definida para a sua propriedade Items. Os seus Itens suportam conteúdo dinâmico, onde pode referenciar quaisquer saídas do Power Query utilizadas como entrada.
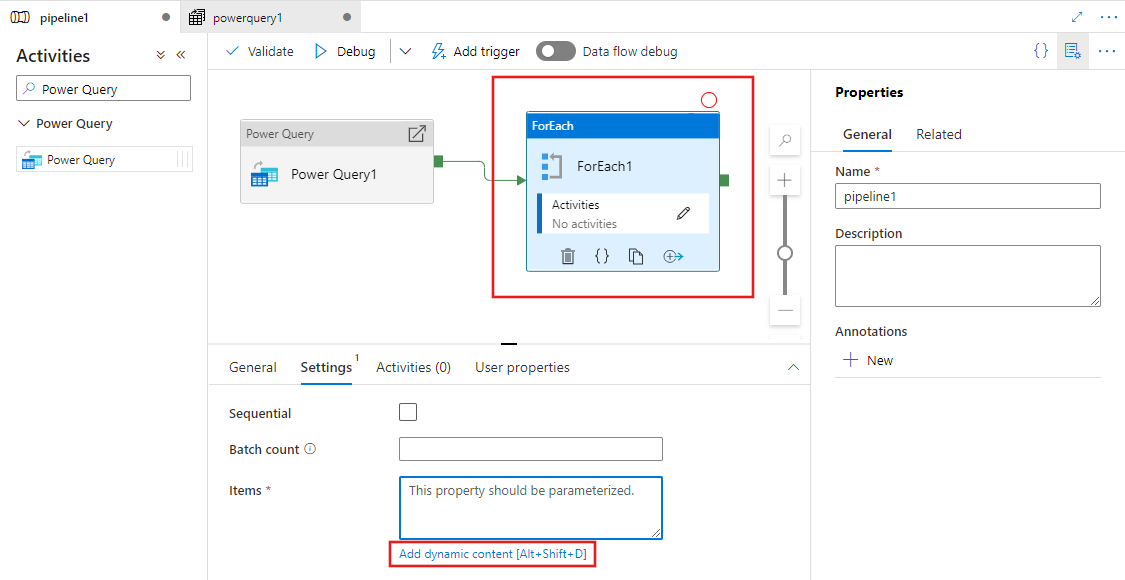
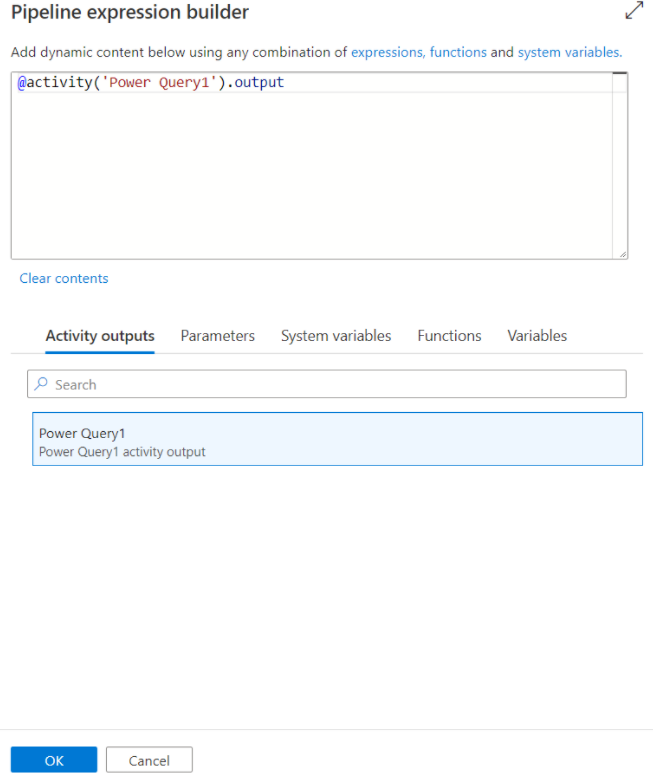
Todas as saídas de atividade são exibidas e podem ser usadas ao definir seu conteúdo dinâmico selecionando-as no painel Construtor de expressões de pipeline.
Tradução para script de fluxo de dados
Para obter escala com a sua atividade do Power Query, o Azure Data Factory traduz o seu script num script de fluxo de dados para que possa executar o Power Query em escala utilizando o M ambiente Spark de fluxo de dados do Azure Data Factory. Crie seu fluxo de dados de disputa usando a preparação de dados sem código. Para obter a lista de funções disponíveis, consulte funções de transformação.
Definições
- Power Query: Escolha um Power Query existente para executar ou crie um novo.
- Executar no IR do Azure: escolha e exista o Tempo de Execução de Integração do Azure para definir o ambiente de computação para o Power Query ou crie um novo.
- Tipo de computação: Se escolher o tempo de execução de integração de resolução automática predefinido, pode selecionar o tipo de computação a aplicar à computação de cluster do Spark para a execução do Power Query.
- Contagem de núcleos: Se escolher o tempo de execução de integração de resolução automática predefinido, pode selecionar o número de núcleos a aplicar à computação do cluster Spark para a execução do Power Query.
Sink
Escolha o conjunto de dados que pretende utilizar para aterrar os dados transformados depois de o script Power Query M ter sido executado no Spark. Para obter mais detalhes sobre a configuração de coletores, visite a documentação para coletores de fluxo de dados.
Você tem a opção de afundar sua saída para vários destinos. Clique no botão de adição (+) para adicionar mais coletores à sua consulta. Também pode direcionar cada saída de consulta individual da sua atividade do Power Query para destinos diferentes.
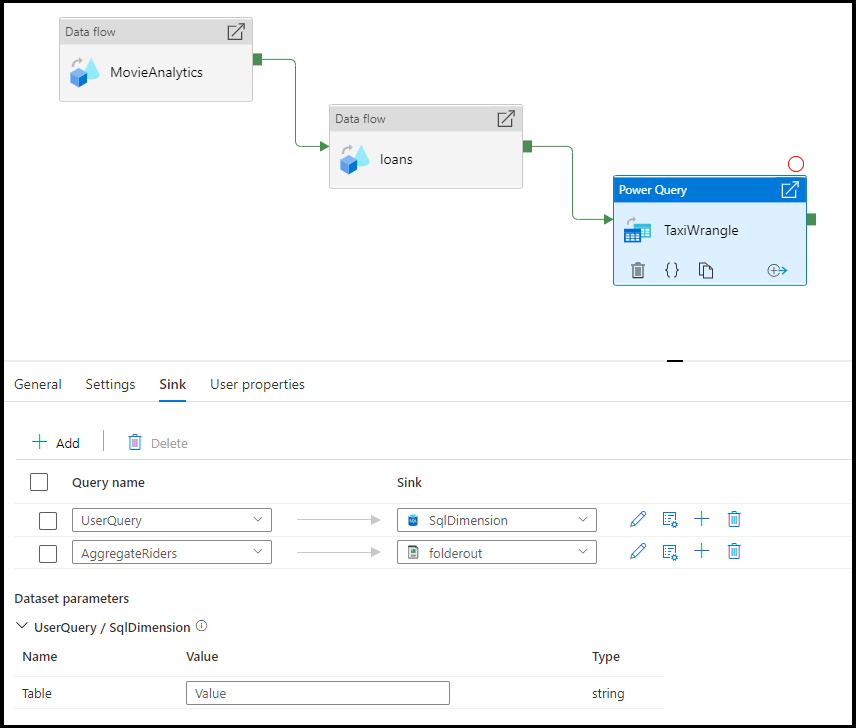
Mapeamento
No separador Mapeamento, pode configurar o mapeamento de colunas desde a saída da sua atividade do Power Query até ao esquema de destino do coletor escolhido. Leia mais sobre o mapeamento de colunas na documentação de mapeamento do coletor de fluxo de dados.
Conteúdos relacionados
Saiba mais sobre conceitos de disputa de dados usando o Power Query no Azure Data Factory