Tutorial: Criar pipelines de aprendizado de máquina de produção
APLICA-SE A: Python SDK azure-ai-ml v2 (atual)
Python SDK azure-ai-ml v2 (atual)
Nota
Para obter um tutorial que usa o SDK v1 para criar um pipeline, consulte Tutorial: Criar um pipeline do Azure Machine Learning para classificação de imagens
O núcleo de um pipeline de aprendizado de máquina é dividir uma tarefa completa de aprendizado de máquina em um fluxo de trabalho de várias etapas. Cada etapa é um componente gerenciável que pode ser desenvolvido, otimizado, configurado e automatizado individualmente. As etapas são conectadas através de interfaces bem definidas. O serviço de pipeline do Azure Machine Learning orquestra automaticamente todas as dependências entre as etapas do pipeline. Os benefícios do uso de um pipeline são padronizar a prática de MLOps, colaboração de equipe escalável, eficiência de treinamento e redução de custos. Para saber mais sobre os benefícios dos pipelines, consulte O que são pipelines do Azure Machine Learning.
Neste tutorial, você usa o Aprendizado de Máquina do Azure para criar um projeto de aprendizado de máquina pronto para produção, usando o SDK do Python do Azure Machine Learning v2.
Isso significa que você poderá aproveitar o SDK Python do Azure Machine Learning para:
- Obter um identificador para o seu espaço de trabalho do Azure Machine Learning
- Criar ativos de dados do Azure Machine Learning
- Criar componentes reutilizáveis do Azure Machine Learning
- Criar, validar e executar pipelines do Azure Machine Learning
Durante este tutorial, você cria um pipeline do Azure Machine Learning para treinar um modelo para previsão de padrão de crédito. O pipeline lida com duas etapas:
- Preparação de dados
- Treinamento e registro do modelo treinado
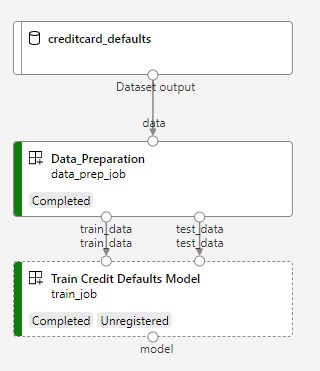
A próxima imagem mostra um pipeline simples como você o verá no estúdio do Azure depois de enviado.
As duas etapas são a primeira preparação de dados e o segundo treinamento.
Este vídeo mostra como começar no estúdio do Azure Machine Learning para que você possa seguir as etapas no tutorial. O vídeo mostra como criar um bloco de anotações, criar uma instância de computação e clonar o bloco de anotações. As etapas também são descritas nas seções a seguir.
Pré-requisitos
-
Para usar o Azure Machine Learning, você precisa de um espaço de trabalho. Se você não tiver um, conclua Criar recursos necessários para começar a criar um espaço de trabalho e saiba mais sobre como usá-lo.
Importante
Se o seu espaço de trabalho do Azure Machine Learning estiver configurado com uma rede virtual gerenciada, talvez seja necessário adicionar regras de saída para permitir o acesso aos repositórios públicos de pacotes Python. Para obter mais informações, consulte Cenário: acessar pacotes públicos de aprendizado de máquina.
-
Entre no estúdio e selecione seu espaço de trabalho se ele ainda não estiver aberto.
Conclua o tutorial Carregar, acessar e explorar seus dados para criar o ativo de dados que você precisa neste tutorial. Certifique-se de executar todo o código para criar o ativo de dados inicial. Explore os dados e revise-os se desejar, mas você só precisará dos dados iniciais neste tutorial.
-
Abra ou crie um bloco de notas na sua área de trabalho:
- Se quiser copiar e colar código em células, crie um novo bloco de anotações.
- Ou abra tutoriais/get-started-notebooks/pipeline.ipynb na seção Amostras do estúdio. Em seguida, selecione Clonar para adicionar o bloco de anotações aos seus arquivos. Para localizar blocos de notas de exemplo, consulte Aprender com blocos de notas de exemplo.
Defina seu kernel e abra no Visual Studio Code (VS Code)
Na barra superior acima do bloco de anotações aberto, crie uma instância de computação se ainda não tiver uma.

Se a instância de computação for interrompida, selecione Iniciar computação e aguarde até que ela esteja em execução.

Aguarde até que a instância de computação esteja em execução. Em seguida, certifique-se de que o kernel, encontrado no canto superior direito, é
Python 3.10 - SDK v2. Caso contrário, use a lista suspensa para selecionar este kernel.
Se você não vir esse kernel, verifique se sua instância de computação está em execução. Se estiver, selecione o botão Atualizar no canto superior direito do bloco de anotações.
Se você vir um banner dizendo que precisa ser autenticado, selecione Autenticar.
Você pode executar o bloco de anotações aqui ou abri-lo no VS Code para um ambiente de desenvolvimento integrado (IDE) completo com o poder dos recursos do Azure Machine Learning. Selecione Abrir no VS Code e, em seguida, selecione a opção Web ou desktop. Quando iniciado dessa forma, o VS Code é anexado à sua instância de computação, ao kernel e ao sistema de arquivos do espaço de trabalho.




Importante
O restante deste tutorial contém células do bloco de anotações do tutorial. Copie-os e cole-os no seu novo bloco de notas ou mude para o bloco de notas agora se o tiver clonado.
Configurar os recursos do pipeline
A estrutura do Azure Machine Learning pode ser usada a partir da CLI, Python SDK ou interface de estúdio. Neste exemplo, você usa o SDK do Python do Azure Machine Learning v2 para criar um pipeline.
Antes de criar o pipeline, você precisa dos seguintes recursos:
- O ativo de dados para treinamento
- O ambiente de software para executar o pipeline
- Um recurso de computação para onde o trabalho é executado
Criar identificador para espaço de trabalho
Antes de mergulharmos no código, você precisa de uma maneira de referenciar seu espaço de trabalho. Você criará ml_client um identificador para o espaço de trabalho. Em seguida, você usará ml_client para gerenciar recursos e trabalhos.
Na célula seguinte, introduza o ID da Subscrição, o nome do Grupo de Recursos e o nome da Área de Trabalho. Para encontrar estes valores:
- Na barra de ferramentas do estúdio do Azure Machine Learning no canto superior direito, selecione o nome do seu espaço de trabalho.
- Copie o valor do espaço de trabalho, do grupo de recursos e da ID da assinatura para o código.
- Você precisará copiar um valor, fechar a área e colar, depois voltar para o próximo.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
SUBSCRIPTION = "<SUBSCRIPTION_ID>"
RESOURCE_GROUP = "<RESOURCE_GROUP>"
WS_NAME = "<AML_WORKSPACE_NAME>"
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id=SUBSCRIPTION,
resource_group_name=RESOURCE_GROUP,
workspace_name=WS_NAME,
)
Nota
A criação do MLClient não se conectará ao espaço de trabalho. A inicialização do cliente é preguiçosa, ele vai esperar pela primeira vez que precisa fazer uma chamada (isso acontecerá na próxima célula de código).
Verifique a conexão fazendo uma chamada para ml_client. Como esta é a primeira vez que você está fazendo uma chamada para o espaço de trabalho, você pode ser solicitado a autenticar.
# Verify that the handle works correctly.
# If you ge an error here, modify your SUBSCRIPTION, RESOURCE_GROUP, and WS_NAME in the previous cell.
ws = ml_client.workspaces.get(WS_NAME)
print(ws.location, ":", ws.resource_group)
Aceder ao ativo de dados registado
Comece por obter os dados que registou anteriormente no Tutorial: Carregar, aceder e explorar os seus dados no Azure Machine Learning.
- O Azure Machine Learning usa um
Dataobjeto para registrar uma definição reutilizável de dados e consumir dados dentro de um pipeline.
# get a handle of the data asset and print the URI
credit_data = ml_client.data.get(name="credit-card", version="initial")
print(f"Data asset URI: {credit_data.path}")
Criar um ambiente de trabalho para etapas de pipeline
Até agora, você criou um ambiente de desenvolvimento na instância de computação, sua máquina de desenvolvimento. Você também precisa de um ambiente para usar para cada etapa do pipeline. Cada etapa pode ter seu próprio ambiente, ou você pode usar alguns ambientes comuns para várias etapas.
Neste exemplo, você cria um ambiente conda para seus trabalhos, usando um arquivo conda yaml. Primeiro, crie um diretório para armazenar o arquivo.
import os
dependencies_dir = "./dependencies"
os.makedirs(dependencies_dir, exist_ok=True)
Agora, crie o arquivo no diretório dependencies.
%%writefile {dependencies_dir}/conda.yaml
name: model-env
channels:
- conda-forge
dependencies:
- python=3.8
- numpy=1.21.2
- pip=21.2.4
- scikit-learn=0.24.2
- scipy=1.7.1
- pandas>=1.1,<1.2
- pip:
- inference-schema[numpy-support]==1.3.0
- xlrd==2.0.1
- mlflow== 2.4.1
- azureml-mlflow==1.51.0
A especificação contém alguns pacotes usuais, que você usa em seu pipeline (numpy, pip), juntamente com alguns pacotes específicos do Azure Machine Learning (azureml-mlflow).
Os pacotes do Azure Machine Learning não são obrigatórios para executar trabalhos do Azure Machine Learning. No entanto, adicionar esses pacotes permite que você interaja com o Azure Machine Learning para registrar métricas e registrar modelos, tudo dentro do trabalho do Azure Machine Learning. Você os usa no script de treinamento mais adiante neste tutorial.
Use o arquivo yaml para criar e registrar esse ambiente personalizado em seu espaço de trabalho:
from azure.ai.ml.entities import Environment
custom_env_name = "aml-scikit-learn"
pipeline_job_env = Environment(
name=custom_env_name,
description="Custom environment for Credit Card Defaults pipeline",
tags={"scikit-learn": "0.24.2"},
conda_file=os.path.join(dependencies_dir, "conda.yaml"),
image="mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest",
version="0.2.0",
)
pipeline_job_env = ml_client.environments.create_or_update(pipeline_job_env)
print(
f"Environment with name {pipeline_job_env.name} is registered to workspace, the environment version is {pipeline_job_env.version}"
)
Construa o pipeline de treinamento
Agora que você tem todos os ativos necessários para executar seu pipeline, é hora de construir o pipeline em si.
Os pipelines do Azure Machine Learning são fluxos de trabalho de ML reutilizáveis que geralmente consistem em vários componentes. A vida típica de um componente é:
- Escreva a especificação yaml do componente ou crie-a programaticamente usando
ComponentMethodo . - Opcionalmente, registre o componente com um nome e uma versão em seu espaço de trabalho, para torná-lo reutilizável e compartilhável.
- Carregue esse componente a partir do código do pipeline.
- Implemente o pipeline usando as entradas, saídas e parâmetros do componente.
- Envie o pipeline.
Há duas maneiras de criar uma definição de componente, programática e yaml. As próximas duas seções orientam você na criação de um componente nos dois sentidos. Você pode criar os dois componentes tentando ambas as opções ou escolher seu método preferido.
Nota
Neste tutorial para simplificar, estamos usando a mesma computação para todos os componentes. No entanto, você pode definir cálculos diferentes para cada componente, por exemplo, adicionando uma linha como train_step.compute = "cpu-cluster". Para exibir um exemplo de criação de um pipeline com cálculos diferentes para cada componente, consulte a seção Trabalho de pipeline básico no tutorial de pipeline cifar-10.
Criar componente 1: preparação de dados (usando definição programática)
Vamos começar criando o primeiro componente. Este componente lida com o pré-processamento dos dados. A tarefa de pré-processamento é executada no arquivo data_prep.py Python.
Primeiro, crie uma pasta de origem para o componente data_prep:
import os
data_prep_src_dir = "./components/data_prep"
os.makedirs(data_prep_src_dir, exist_ok=True)
Esse script executa a tarefa simples de dividir os dados em conjuntos de dados de trem e teste. O Azure Machine Learning monta conjuntos de dados como pastas para os cálculos, portanto, criamos uma função auxiliar select_first_file para acessar o arquivo de dados dentro da pasta de entrada montada.
MLFlow é usado para registrar os parâmetros e métricas durante nossa execução de pipeline.
%%writefile {data_prep_src_dir}/data_prep.py
import os
import argparse
import pandas as pd
from sklearn.model_selection import train_test_split
import logging
import mlflow
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--data", type=str, help="path to input data")
parser.add_argument("--test_train_ratio", type=float, required=False, default=0.25)
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
args = parser.parse_args()
# Start Logging
mlflow.start_run()
print(" ".join(f"{k}={v}" for k, v in vars(args).items()))
print("input data:", args.data)
credit_df = pd.read_csv(args.data, header=1, index_col=0)
mlflow.log_metric("num_samples", credit_df.shape[0])
mlflow.log_metric("num_features", credit_df.shape[1] - 1)
credit_train_df, credit_test_df = train_test_split(
credit_df,
test_size=args.test_train_ratio,
)
# output paths are mounted as folder, therefore, we are adding a filename to the path
credit_train_df.to_csv(os.path.join(args.train_data, "data.csv"), index=False)
credit_test_df.to_csv(os.path.join(args.test_data, "data.csv"), index=False)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Agora que você tem um script que pode executar a tarefa desejada, crie um Componente de Aprendizado de Máquina do Azure a partir dele.
Use a finalidade CommandComponent geral que pode executar ações de linha de comando. Esta ação de linha de comando pode chamar diretamente comandos do sistema ou executar um script. As entradas/saídas são especificadas na linha de comando através da ${{ ... }} notação.
from azure.ai.ml import command
from azure.ai.ml import Input, Output
data_prep_component = command(
name="data_prep_credit_defaults",
display_name="Data preparation for training",
description="reads a .xl input, split the input to train and test",
inputs={
"data": Input(type="uri_folder"),
"test_train_ratio": Input(type="number"),
},
outputs=dict(
train_data=Output(type="uri_folder", mode="rw_mount"),
test_data=Output(type="uri_folder", mode="rw_mount"),
),
# The source folder of the component
code=data_prep_src_dir,
command="""python data_prep.py \
--data ${{inputs.data}} --test_train_ratio ${{inputs.test_train_ratio}} \
--train_data ${{outputs.train_data}} --test_data ${{outputs.test_data}} \
""",
environment=f"{pipeline_job_env.name}:{pipeline_job_env.version}",
)
Opcionalmente, registre o componente no espaço de trabalho para reutilização futura.
# Now we register the component to the workspace
data_prep_component = ml_client.create_or_update(data_prep_component.component)
# Create (register) the component in your workspace
print(
f"Component {data_prep_component.name} with Version {data_prep_component.version} is registered"
)
Criar componente 2: treinamento (usando a definição yaml)
O segundo componente que você cria consome os dados de treinamento e teste, treina um modelo baseado em árvore e retorna o modelo de saída. Use os recursos de log do Azure Machine Learning para registrar e visualizar o progresso do aprendizado.
Você usou a CommandComponent classe para criar seu primeiro componente. Desta vez, você usa a definição yaml para definir o segundo componente. Cada método tem suas próprias vantagens. Uma definição yaml pode realmente ser verificada ao longo do código e forneceria um rastreamento de histórico legível. O uso do método CommandComponent programático pode ser mais fácil com documentação de classe interna e conclusão de código.
Crie o diretório para este componente:
import os
train_src_dir = "./components/train"
os.makedirs(train_src_dir, exist_ok=True)
Crie o script de treinamento no diretório:
%%writefile {train_src_dir}/train.py
import argparse
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import classification_report
import os
import pandas as pd
import mlflow
def select_first_file(path):
"""Selects first file in folder, use under assumption there is only one file in folder
Args:
path (str): path to directory or file to choose
Returns:
str: full path of selected file
"""
files = os.listdir(path)
return os.path.join(path, files[0])
# Start Logging
mlflow.start_run()
# enable autologging
mlflow.sklearn.autolog()
os.makedirs("./outputs", exist_ok=True)
def main():
"""Main function of the script."""
# input and output arguments
parser = argparse.ArgumentParser()
parser.add_argument("--train_data", type=str, help="path to train data")
parser.add_argument("--test_data", type=str, help="path to test data")
parser.add_argument("--n_estimators", required=False, default=100, type=int)
parser.add_argument("--learning_rate", required=False, default=0.1, type=float)
parser.add_argument("--registered_model_name", type=str, help="model name")
parser.add_argument("--model", type=str, help="path to model file")
args = parser.parse_args()
# paths are mounted as folder, therefore, we are selecting the file from folder
train_df = pd.read_csv(select_first_file(args.train_data))
# Extracting the label column
y_train = train_df.pop("default payment next month")
# convert the dataframe values to array
X_train = train_df.values
# paths are mounted as folder, therefore, we are selecting the file from folder
test_df = pd.read_csv(select_first_file(args.test_data))
# Extracting the label column
y_test = test_df.pop("default payment next month")
# convert the dataframe values to array
X_test = test_df.values
print(f"Training with data of shape {X_train.shape}")
clf = GradientBoostingClassifier(
n_estimators=args.n_estimators, learning_rate=args.learning_rate
)
clf.fit(X_train, y_train)
y_pred = clf.predict(X_test)
print(classification_report(y_test, y_pred))
# Registering the model to the workspace
print("Registering the model via MLFlow")
mlflow.sklearn.log_model(
sk_model=clf,
registered_model_name=args.registered_model_name,
artifact_path=args.registered_model_name,
)
# Saving the model to a file
mlflow.sklearn.save_model(
sk_model=clf,
path=os.path.join(args.model, "trained_model"),
)
# Stop Logging
mlflow.end_run()
if __name__ == "__main__":
main()
Como você pode ver neste script de treinamento, uma vez que o modelo é treinado, o arquivo de modelo é salvo e registrado no espaço de trabalho. Agora você pode usar o modelo registrado na inferência de pontos de extremidade.
Para o ambiente desta etapa, você usa um dos ambientes internos (com curadoria) do Azure Machine Learning. A tag azureml, diz ao sistema para usar procurar o nome em ambientes com curadoria.
Primeiro, crie o arquivo yaml descrevendo o componente:
%%writefile {train_src_dir}/train.yml
# <component>
name: train_credit_defaults_model
display_name: Train Credit Defaults Model
# version: 1 # Not specifying a version will automatically update the version
type: command
inputs:
train_data:
type: uri_folder
test_data:
type: uri_folder
learning_rate:
type: number
registered_model_name:
type: string
outputs:
model:
type: uri_folder
code: .
environment:
# for this step, we'll use an AzureML curate environment
azureml://registries/azureml/environments/sklearn-1.0/labels/latest
command: >-
python train.py
--train_data ${{inputs.train_data}}
--test_data ${{inputs.test_data}}
--learning_rate ${{inputs.learning_rate}}
--registered_model_name ${{inputs.registered_model_name}}
--model ${{outputs.model}}
# </component>
Agora crie e registre o componente. Registá-lo permite-lhe reutilizá-lo noutros pipelines. Além disso, qualquer outra pessoa com acesso ao seu espaço de trabalho pode usar o componente registrado.
# importing the Component Package
from azure.ai.ml import load_component
# Loading the component from the yml file
train_component = load_component(source=os.path.join(train_src_dir, "train.yml"))
# Now we register the component to the workspace
train_component = ml_client.create_or_update(train_component)
# Create (register) the component in your workspace
print(
f"Component {train_component.name} with Version {train_component.version} is registered"
)
Criar o pipeline a partir de componentes
Agora que ambos os componentes estão definidos e registrados, você pode começar a implementar o pipeline.
Aqui, você usa dados de entrada, proporção de divisão e nome do modelo registrado como variáveis de entrada. Em seguida, chame os componentes e conecte-os através de seus identificadores de entradas/saídas. As saídas de cada etapa podem ser acessadas através da .outputs propriedade.
As funções Python retornadas pelo load_component() trabalho como qualquer função Python regular que usamos dentro de um pipeline para chamar cada etapa.
Para codificar o pipeline, use um decorador específico @dsl.pipeline que identifique os pipelines do Azure Machine Learning. No decorador, podemos especificar a descrição do pipeline e os recursos padrão, como computação e armazenamento. Como uma função Python, os pipelines podem ter entradas. Em seguida, você pode criar várias instâncias de um único pipeline com entradas diferentes.
Aqui, usamos dados de entrada, razão de divisão e nome do modelo registrado como variáveis de entrada. Em seguida, chamamos os componentes e os conectamos através de seus identificadores de entrada/saída. As saídas de cada etapa podem ser acessadas através da .outputs propriedade.
# the dsl decorator tells the sdk that we are defining an Azure Machine Learning pipeline
from azure.ai.ml import dsl, Input, Output
@dsl.pipeline(
compute="serverless", # "serverless" value runs pipeline on serverless compute
description="E2E data_perp-train pipeline",
)
def credit_defaults_pipeline(
pipeline_job_data_input,
pipeline_job_test_train_ratio,
pipeline_job_learning_rate,
pipeline_job_registered_model_name,
):
# using data_prep_function like a python call with its own inputs
data_prep_job = data_prep_component(
data=pipeline_job_data_input,
test_train_ratio=pipeline_job_test_train_ratio,
)
# using train_func like a python call with its own inputs
train_job = train_component(
train_data=data_prep_job.outputs.train_data, # note: using outputs from previous step
test_data=data_prep_job.outputs.test_data, # note: using outputs from previous step
learning_rate=pipeline_job_learning_rate, # note: using a pipeline input as parameter
registered_model_name=pipeline_job_registered_model_name,
)
# a pipeline returns a dictionary of outputs
# keys will code for the pipeline output identifier
return {
"pipeline_job_train_data": data_prep_job.outputs.train_data,
"pipeline_job_test_data": data_prep_job.outputs.test_data,
}
Agora, use sua definição de pipeline para instanciar um pipeline com seu conjunto de dados, taxa de divisão de escolha e o nome que você escolheu para seu modelo.
registered_model_name = "credit_defaults_model"
# Let's instantiate the pipeline with the parameters of our choice
pipeline = credit_defaults_pipeline(
pipeline_job_data_input=Input(type="uri_file", path=credit_data.path),
pipeline_job_test_train_ratio=0.25,
pipeline_job_learning_rate=0.05,
pipeline_job_registered_model_name=registered_model_name,
)
Submeter o trabalho
Agora é hora de enviar o trabalho para ser executado no Azure Machine Learning. Desta vez, você usa create_or_update em ml_client.jobs.
Aqui você também passa um nome de experimento. Um experimento é um contêiner para todas as iterações que se faz em um determinado projeto. Todos os trabalhos enviados com o mesmo nome de experimento seriam listados um ao lado do outro no estúdio do Azure Machine Learning.
Uma vez concluído, o pipeline registra um modelo em seu espaço de trabalho como resultado do treinamento.
# submit the pipeline job
pipeline_job = ml_client.jobs.create_or_update(
pipeline,
# Project's name
experiment_name="e2e_registered_components",
)
ml_client.jobs.stream(pipeline_job.name)
Você pode acompanhar o progresso do seu pipeline, usando o link gerado na célula anterior. Quando você seleciona esse link pela primeira vez, você pode ver que o pipeline ainda está em execução. Quando estiver concluído, você poderá examinar os resultados de cada componente.
Clique duas vezes no componente Train Credit Defaults Model .
Há dois resultados importantes que você vai querer ver sobre o treinamento:
Veja os seus registos:
- Selecione a guia Saídas+logs .
- Abra as pastas para
user_logs>std_log.txtEsta seção mostra o script executar stdout.
Veja suas métricas: selecione a guia Métricas . Esta seção mostra diferentes métricas registradas. Neste exemplo. mlflow
autologging, registrou automaticamente as métricas de treinamento.


Implantar o modelo como um ponto de extremidade online
Para saber como implantar seu modelo em um ponto de extremidade online, consulte Implantar um modelo como um tutorial de ponto de extremidade online.
Clean up resources (Limpar recursos)
Se você planeja continuar agora para outros tutoriais, pule para Próximas etapas.
Parar instância de computação
Se você não vai usá-lo agora, pare a instância de computação:
- No estúdio, na área de navegação esquerda, selecione Computar.
- Nas guias superiores, selecione Instâncias de computação
- Selecione a instância de computação na lista.
- Na barra de ferramentas superior, selecione Parar.
Eliminar todos os recursos
Importante
Os recursos que você criou podem ser usados como pré-requisitos para outros tutoriais e artigos de instruções do Azure Machine Learning.
Se você não planeja usar nenhum dos recursos que criou, exclua-os para não incorrer em cobranças:
No portal do Azure, na caixa de pesquisa, insira Grupos de recursos e selecione-o nos resultados.
Na lista, selecione o grupo de recursos que você criou.
Na página Visão geral, selecione Excluir grupo de recursos.

Insira o nome do grupo de recursos. Em seguida, selecione Eliminar.
Próximos passos
Saiba como agendar trabalhos de pipeline de aprendizado de máquina