Alta disponibilidade de escalonamento do SAP HANA com arquivos NetApp do Azure no RHEL
Este artigo descreve como configurar a Replicação do Sistema SAP HANA na implantação em expansão, quando os sistemas de arquivos HANA são montados via NFS, usando os Arquivos NetApp do Azure. Nas configurações de exemplo e comandos de instalação, o número de instância 03 e o ID de sistema HANA HN1 são usados. A replicação do sistema SAP HANA consiste em um nó primário e pelo menos um nó secundário.
Quando as etapas deste documento são marcadas com os seguintes prefixos, o significado é o seguinte:
- [R]: A etapa se aplica a todos os nós
- [1]: O passo aplica-se apenas ao nó1
- [2]: A etapa aplica-se apenas ao nó2
Pré-requisitos
Leia primeiro as seguintes notas e documentos do SAP:
- SAP Note 1928533, que tem:
- A lista de tamanhos de máquina virtual (VM) do Azure com suporte para a implantação do software SAP.
- Informações de capacidade importantes para tamanhos de VM do Azure.
- O software SAP suportado e as combinações de sistema operacional (SO) e banco de dados.
- A versão necessária do kernel SAP para Windows e Linux no Microsoft Azure.
- SAP Note 2015553 lista os pré-requisitos para implantações de software SAP suportadas pelo SAP no Azure.
- O SAP Note 405827 lista os sistemas de arquivos recomendados para ambientes HANA.
- O SAP Note 2002167 recomendou as configurações do sistema operacional para o Red Hat Enterprise Linux.
- O SAP Note 2009879 tem as diretrizes do SAP HANA para Red Hat Enterprise Linux.
- O SAP Note 3108302 tem as diretrizes do SAP HANA para o Red Hat Enterprise Linux 9.x.
- O SAP Note 2178632 tem informações detalhadas sobre todas as métricas de monitoramento relatadas para SAP no Azure.
- O SAP Note 2191498 tem a versão necessária do SAP Host Agent para Linux no Azure.
- O SAP Note 2243692 tem informações sobre o licenciamento SAP no Linux no Azure.
- O SAP Note 1999351 tem mais informações de solução de problemas para a Extensão de Monitoramento Avançado do Azure para SAP.
- O SAP Community Wiki tem todas as notas SAP necessárias para Linux.
- Planejamento e implementação de Máquinas Virtuais do Azure para SAP no Linux
- Implantação de Máquinas Virtuais do Azure para SAP no Linux
- Implantação de DBMS de Máquinas Virtuais do Azure para SAP no Linux
- Replicação do sistema SAP HANA no cluster Pacemaker
- Documentação geral do Red Hat Enterprise Linux (RHEL):
- Visão geral do complemento de alta disponibilidade
- Administração de complementos de alta disponibilidade
- Referência de complemento de alta disponibilidade
- Configurar a replicação do sistema SAP HANA em expansão em um cluster de marcapasso quando os sistemas de arquivos HANA estiverem em compartilhamentos NFS
- Documentação RHEL específica do Azure:
- Políticas de suporte para clusters de alta disponibilidade RHEL - Máquinas virtuais do Microsoft Azure como membros do cluster
- Instalando e configurando um cluster de alta disponibilidade do Red Hat Enterprise Linux 7.4 (e posterior) no Microsoft Azure
- Configure a replicação do sistema de scale-up do SAP HANA em um cluster Pacemaker quando os sistemas de arquivos HANA estiverem em compartilhamentos NFS
- Volumes NFS v4.1 no Azure NetApp Files para SAP HANA
Descrição geral
Tradicionalmente, em um ambiente de expansão, todos os sistemas de arquivos para SAP HANA são montados a partir do armazenamento local. A configuração de alta disponibilidade (HA) do SAP HANA System Replication no Red Hat Enterprise Linux foi publicada em set up SAP HANA System Replication on RHEL.
Para obter o SAP HANA HA de um sistema de expansão em compartilhamentos NFS do Azure NetApp Files , precisamos de mais alguma configuração de recursos no cluster, para que os recursos HANA se recuperem, quando um nó perde o acesso aos compartilhamentos NFS nos Arquivos NetApp do Azure. O cluster gerencia as montagens NFS, permitindo monitorar a integridade dos recursos. As dependências entre as montagens do sistema de arquivos e os recursos do SAP HANA são impostas.
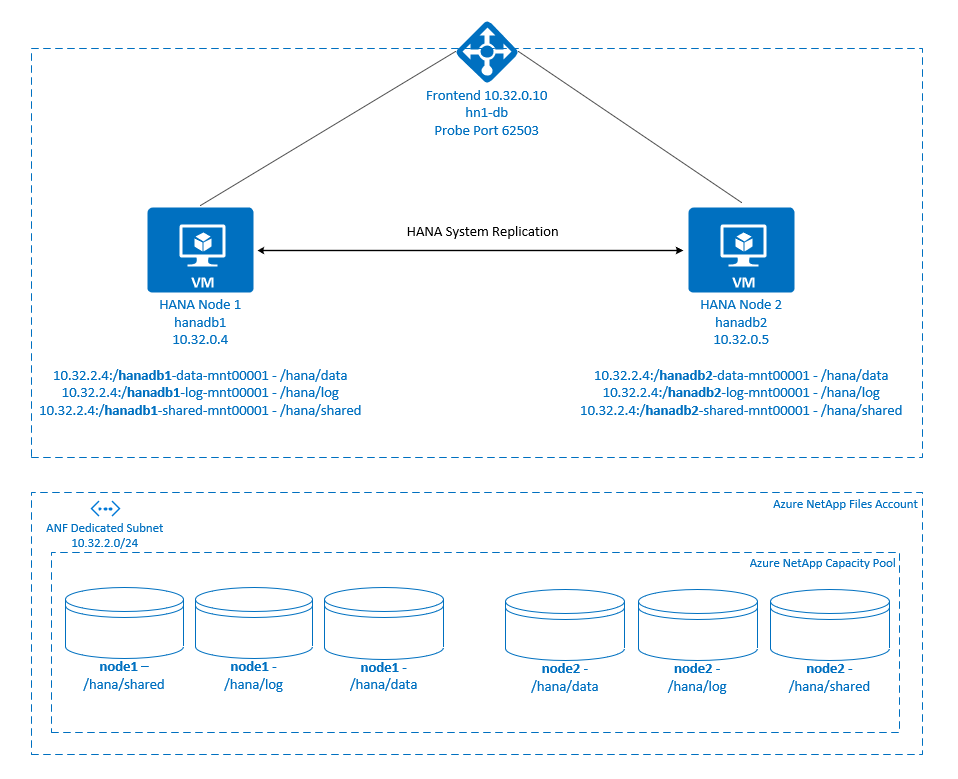 .
.
Os sistemas de arquivos SAP HANA são montados em compartilhamentos NFS usando os Arquivos NetApp do Azure em cada nó. Sistemas de arquivos /hana/data, /hana/loge /hana/shared são exclusivos para cada nó.
Montado no nó1 (hanadb1):
- 10.32.2.4:/hanadb1-data-mnt00001 em /hana/data
- 10.32.2.4:/hanadb1-log-mnt00001 em /hana/log
- 10.32.2.4:/hanadb1-shared-mnt00001 em /hana/shared
Montado no nó2 (hanadb2):
- 10.32.2.4:/hanadb2-data-mnt00001 em /hana/data
- 10.32.2.4:/hanadb2-log-mnt00001 em /hana/log
- 10.32.2.4:/hanadb2-shared-mnt00001 em /hana/shared
Nota
Sistemas de arquivos /hana/shared, /hana/datae /hana/log não são compartilhados entre os dois nós. Cada nó de cluster tem seus próprios sistemas de arquivos separados.
A configuração do SAP HANA System Replication usa um nome de host virtual dedicado e endereços IP virtuais. No Azure, um balanceador de carga é necessário para usar um endereço IP virtual. A configuração mostrada aqui tem um balanceador de carga com:
- Endereço IP front-end: 10.32.0.10 para hn1-db
- Porta da sonda: 62503
Configurar a infraestrutura do Azure NetApp Files
Antes de prosseguir com a configuração da infraestrutura do Azure NetApp Files, familiarize-se com a documentação do Azure NetApp Files.
Os Arquivos NetApp do Azure estão disponíveis em várias regiões do Azure. Verifique se a região do Azure selecionada oferece Arquivos NetApp do Azure.
Para obter informações sobre a disponibilidade dos Arquivos NetApp do Azure por região do Azure, consulte Disponibilidade dos Arquivos NetApp do Azure por região do Azure.
Considerações importantes
Ao criar seus volumes do Azure NetApp Files para sistemas de expansão do SAP HANA, esteja ciente das considerações importantes documentadas nos volumes NFS v4.1 no Azure NetApp Files for SAP HANA.
Dimensionamento do banco de dados HANA em arquivos NetApp do Azure
A taxa de transferência de um volume de Arquivos NetApp do Azure é uma função do tamanho do volume e do nível de serviço, conforme documentado em Nível de serviço para Arquivos NetApp do Azure.
Ao projetar a infraestrutura do SAP HANA no Azure com os Arquivos NetApp do Azure, esteja ciente das recomendações nos volumes NFS v4.1 nos Arquivos NetApp do Azure para SAP HANA.
A configuração neste artigo é apresentada com volumes simples do Azure NetApp Files.
Importante
Para sistemas de produção, onde o desempenho é uma chave, recomendamos que você avalie e considere o uso do grupo de volumes de aplicativos Arquivos NetApp do Azure para SAP HANA.
Implantar recursos do Azure NetApp Files
As instruções a seguir pressupõem que você já implantou sua rede virtual do Azure. Os recursos e VMs dos Arquivos NetApp do Azure, onde os recursos dos Arquivos NetApp do Azure serão montados, devem ser implantados na mesma rede virtual do Azure ou em redes virtuais do Azure emparelhadas.
Crie uma conta NetApp na região do Azure selecionada seguindo as instruções em Criar uma conta NetApp.
Configure um pool de capacidade de Arquivos NetApp do Azure seguindo as instruções em Configurar um pool de capacidade de Arquivos NetApp do Azure.
A arquitetura HANA mostrada neste artigo usa um único pool de capacidade de Arquivos NetApp do Azure no nível de serviço Ultra . Para cargas de trabalho HANA no Azure, recomendamos usar um Nível de serviço Azure NetApp Files Ultra ou Premium.
Delegue uma sub-rede aos Arquivos NetApp do Azure, conforme descrito nas instruções em Delegar uma sub-rede aos Arquivos NetApp do Azure.
Implante volumes de Arquivos NetApp do Azure seguindo as instruções em Criar um volume NFS para Arquivos NetApp do Azure.
Ao implantar os volumes, certifique-se de selecionar a versão NFSv4.1. Implante os volumes na sub-rede designada Arquivos NetApp do Azure. Os endereços IP dos volumes NetApp do Azure são atribuídos automaticamente.
Lembre-se de que os recursos dos Arquivos NetApp do Azure e as VMs do Azure devem estar na mesma rede virtual do Azure ou em redes virtuais do Azure emparelhadas. Por exemplo,
hanadb1-data-mnt00001ehanadb1-log-mnt00001são os nomes de volume enfs://10.32.2.4/hanadb1-data-mnt00001enfs://10.32.2.4/hanadb1-log-mnt00001são os caminhos de arquivo para os volumes de Arquivos NetApp do Azure.Em hanadb1:
- Volume hanadb1-data-mnt00001 (nfs://10.32.2.4:/hanadb1-data-mnt00001)
- Volume hanadb1-log-mnt00001 (nfs://10.32.2.4:/hanadb1-log-mnt00001)
- Volume hanadb1-shared-mnt00001 (nfs://10.32.2.4:/hanadb1-shared-mnt00001)
Em hanadb2:
- Volume hanadb2-data-mnt00001 (nfs://10.32.2.4:/hanadb2-data-mnt00001)
- Volume hanadb2-log-mnt00001 (nfs://10.32.2.4:/hanadb2-log-mnt00001)
- Volume hanadb2-shared-mnt00001 (nfs://10.32.2.4:/hanadb2-shared-mnt00001)
Nota
Todos os comandos a serem montados /hana/shared neste artigo são apresentados para volumes NFSv4.1 /hana/shared .
Se você implantou os /hana/shared volumes como volumes NFSv3, não se esqueça de ajustar os comandos mount para /hana/shared NFSv3.
Preparar a infraestrutura
O Azure Marketplace contém imagens qualificadas para SAP HANA com o complemento de Alta Disponibilidade, que você pode usar para implantar novas VMs usando várias versões do Red Hat.
Implantar VMs Linux manualmente por meio do portal do Azure
Este documento pressupõe que você já tenha implantado um grupo de recursos, uma rede virtual do Azure e uma sub-rede.
Implante VMs para SAP HANA. Escolha uma imagem RHEL adequada que seja compatível com o sistema HANA. Você pode implantar uma VM em qualquer uma das opções de disponibilidade: conjunto de escala de máquina virtual, zona de disponibilidade ou conjunto de disponibilidade.
Importante
Certifique-se de que o sistema operacional selecionado é certificado SAP para SAP HANA nos tipos específicos de VM que você planeja usar em sua implantação. Você pode procurar tipos de VM certificados pelo SAP HANA e suas versões de SO em plataformas IaaS certificadas pelo SAP HANA. Certifique-se de examinar os detalhes do tipo de VM para obter a lista completa de versões do sistema operacional suportadas pelo SAP HANA para o tipo de VM específico.
Configurar o balanceador de carga do Azure
Durante a configuração da VM, você tem uma opção para criar ou selecionar o balanceador de carga de saída na seção de rede. Siga as etapas abaixo para configurar o balanceador de carga padrão para configuração de alta disponibilidade do banco de dados HANA.
Siga as etapas em Criar balanceador de carga para configurar um balanceador de carga padrão para um sistema SAP de alta disponibilidade usando o portal do Azure. Durante a configuração do balanceador de carga, considere os seguintes pontos:
- Configuração de IP Frontend: Crie um IP front-end. Selecione a mesma rede virtual e o mesmo nome de sub-rede que suas máquinas virtuais de banco de dados.
- Pool de back-end: crie um pool de back-end e adicione VMs de banco de dados.
- Regras de entrada: crie uma regra de balanceamento de carga. Siga as mesmas etapas para ambas as regras de balanceamento de carga.
- Endereço IP frontend: Selecione um IP front-end.
- Pool de back-end: selecione um pool de back-end.
- Portas de alta disponibilidade: selecione esta opção.
- Protocolo: Selecione TCP.
- Sonda de integridade: crie uma sonda de integridade com os seguintes detalhes:
- Protocolo: Selecione TCP.
- Porta: Por exemplo, 625<instância-não.>
- Intervalo: Digite 5.
- Limite da sonda: Digite 2.
- Tempo limite de inatividade (minutos): Digite 30.
- Ativar IP flutuante: selecione esta opção.
Nota
A propriedade numberOfProbesde configuração da sonda de integridade, também conhecida como Limite não íntegro no portal, não é respeitada. Para controlar o número de testes consecutivos bem-sucedidos ou com falha, defina a propriedade probeThreshold como 2. Atualmente, não é possível definir essa propriedade usando o portal do Azure, portanto, use a CLI do Azure ou o comando PowerShell.
Para obter mais informações sobre as portas necessárias para o SAP HANA, leia o capítulo Conexões com bancos de dados de locatários no guia Bancos de dados de locatários do SAP HANA ou no SAP Note 2388694.
Nota
Quando VMs sem endereços IP públicos são colocadas no pool de back-end de uma instância interna (sem endereço IP público) do Balanceador de Carga do Azure Padrão, não há conectividade de saída com a Internet, a menos que mais configuração seja executada para permitir o roteamento para pontos de extremidade públicos. Para obter mais informações sobre como obter conectividade de saída, consulte Conectividade de ponto de extremidade público para máquinas virtuais usando o Balanceador de Carga do Azure Padrão em cenários de alta disponibilidade SAP.
Importante
Não habilite carimbos de data/hora TCP em VMs do Azure colocadas atrás do Balanceador de Carga do Azure. Habilitar carimbos de data/hora TCP pode fazer com que os testes de integridade falhem. Defina o parâmetro net.ipv4.tcp_timestamps como 0. Para obter mais informações, consulte Sondas de integridade do balanceador de carga e SAP Note 2382421.
Monte o volume de Arquivos NetApp do Azure
[A] Crie pontos de montagem para os volumes do banco de dados HANA.
sudo mkdir -p /hana/data sudo mkdir -p /hana/log sudo mkdir -p /hana/shared[A] Verifique a configuração do domínio NFS. Verifique se o domínio está configurado como o domínio padrão dos Arquivos NetApp do Azure, ou seja, defaultv4iddomain.com, e se o mapeamento está definido como ninguém.
sudo cat /etc/idmapd.confSaída de exemplo:
[General] Domain = defaultv4iddomain.com [Mapping] Nobody-User = nobody Nobody-Group = nobodyImportante
Certifique-se de definir o domínio NFS na
/etc/idmapd.confVM para corresponder à configuração de domínio padrão nos Arquivos NetApp do Azure: defaultv4iddomain.com. Se houver uma incompatibilidade entre a configuração de domínio no cliente NFS (ou seja, a VM) e o servidor NFS (ou seja, a configuração dos Arquivos NetApp do Azure), as permissões para arquivos nos volumes do Azure NetApp Files montados nas VMs serão exibidas comonobody.[1] Monte os volumes específicos do nó no nó1 (hanadb1).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb1-data-mnt00001 /hana/data[2] Monte os volumes específicos do nó no nó2 (hanadb2).
sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-shared-mnt00001 /hana/shared sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-log-mnt00001 /hana/log sudo mount -o rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys 10.32.2.4:/hanadb2-data-mnt00001 /hana/data[A] Verifique se todos os volumes HANA estão montados com a versão NFSv4 do protocolo NFSv4.
sudo nfsstat -mVerifique se o sinalizador
versestá definido como 4.1. Exemplo de hanadb1:/hana/log from 10.32.2.4:/hanadb1-log-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/data from 10.32.2.4:/hanadb1-data-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4 /hana/shared from 10.32.2.4:/hanadb1-shared-mnt00001 Flags: rw,noatime,vers=4.1,rsize=262144,wsize=262144,namlen=255,hard,proto=tcp,timeo=600,retrans=2,sec=sys,clientaddr=10.32.0.4,local_lock=none,addr=10.32.2.4[A] Verifique nfs4_disable_idmapping. Deve ser definido como Y. Para criar a estrutura de diretórios onde nfs4_disable_idmapping está localizado, execute o comando mount. Você não pode criar manualmente o diretório em
/sys/modulesporque o acesso é reservado para o kernel e drivers.Consulte
nfs4_disable_idmapping.sudo cat /sys/module/nfs/parameters/nfs4_disable_idmappingSe você precisar definir
nfs4_disable_idmappingpara:sudo echo "Y" > /sys/module/nfs/parameters/nfs4_disable_idmappingTorne a configuração permanente.
sudo echo "options nfs nfs4_disable_idmapping=Y" >> /etc/modprobe.d/nfs.confPara obter mais informações sobre como alterar o
nfs_disable_idmappingparâmetro, consulte a Base de Conhecimento Red Hat.
Instalação do SAP HANA
[A] Configure a resolução de nome de host para todos os hosts.
Você pode usar um servidor DNS ou modificar o
/etc/hostsarquivo em todos os nós. Este exemplo mostra como usar o/etc/hostsarquivo. Substitua o endereço IP e o nome do host nos seguintes comandos:sudo vi /etc/hostsInsira as seguintes linhas no
/etc/hostsficheiro. Altere o endereço IP e o nome do host para corresponder ao seu ambiente.10.32.0.4 hanadb1 10.32.0.5 hanadb2[A] Prepare o SO para executar o SAP HANA no Azure NetApp com NFS, conforme descrito em SAP Note 3024346 - Linux Kernel Settings for NetApp NFS. Crie o arquivo
/etc/sysctl.d/91-NetApp-HANA.confde configuração para as definições de configuração da NetApp.sudo vi /etc/sysctl.d/91-NetApp-HANA.confAdicione as seguintes entradas no arquivo de configuração.
net.core.rmem_max = 16777216 net.core.wmem_max = 16777216 net.ipv4.tcp_rmem = 4096 131072 16777216 net.ipv4.tcp_wmem = 4096 16384 16777216 net.core.netdev_max_backlog = 300000 net.ipv4.tcp_slow_start_after_idle=0 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_moderate_rcvbuf = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_sack = 1[A] Crie o arquivo de
/etc/sysctl.d/ms-az.confconfiguração com mais configurações de otimização.sudo vi /etc/sysctl.d/ms-az.confAdicione as seguintes entradas no arquivo de configuração.
net.ipv6.conf.all.disable_ipv6 = 1 net.ipv4.tcp_max_syn_backlog = 16348 net.ipv4.conf.all.rp_filter = 0 sunrpc.tcp_slot_table_entries = 128 vm.swappiness=10Gorjeta
Evite definir
net.ipv4.ip_local_port_rangeenet.ipv4.ip_local_reserved_portsexplicitamente nos arquivos desysctlconfiguração para permitir que o SAP Host Agent gerencie os intervalos de portas. Para obter mais informações, consulte SAP Note 2382421.[A] Ajuste as
sunrpcconfigurações, conforme recomendado no SAP Note 3024346 - Linux Kernel Settings for NetApp NFS.sudo vi /etc/modprobe.d/sunrpc.confInsira a seguinte linha:
options sunrpc tcp_max_slot_table_entries=128[A] Execute a configuração do RHEL OS para HANA.
Configure o SO conforme descrito nas seguintes Notas SAP com base na sua versão RHEL:
- 2292690 - SAP HANA DB: Configurações recomendadas do sistema operacional para RHEL 7
- 2777782 - SAP HANA DB: Configurações recomendadas do sistema operacional para RHEL 8
- 2455582 - Linux: Executando aplicativos SAP compilados com GCC 6.x
- 2593824 - Linux: Executando aplicativos SAP compilados com GCC 7.x
- 2886607 - Linux: Executando aplicativos SAP compilados com GCC 9.x
[A] Instale o SAP HANA.
A partir do HANA 2.0 SPS 01, o MDC é a opção padrão. Quando você instala o sistema HANA, SYSTEMDB e um locatário com o mesmo SID são criados juntos. Em alguns casos, você não quer o locatário padrão. Se você não quiser criar um locatário inicial junto com a instalação, siga o SAP Note 2629711.
Execute o programa hdblcm a partir do DVD HANA. Insira os seguintes valores no prompt:
- Escolha a instalação: Digite 1 (para instalação).
- Selecione mais componentes para instalação: Digite 1.
- Digite o caminho de instalação [/hana/shared]: Selecione Enter para aceitar o padrão.
- Digite o Nome do Host Local [..]: Selecione Enter para aceitar o padrão. Deseja adicionar mais hosts ao sistema? (s/n) [n]: n.
- Insira o ID do sistema SAP HANA: digite HN1.
- Digite o número da instância [00]: digite 03.
- Selecione Modo de banco de dados / Enter Index [1]: Selecione Enter para aceitar o padrão.
- Selecione Uso do sistema / Enter Index [4]: Digite 4 (para personalizado).
- Insira o local dos volumes de dados [/hana/data]: selecione Enter para aceitar o padrão.
- Insira o local dos volumes de log [/hana/log]: selecione Enter para aceitar o padrão.
- Restringir a alocação máxima de memória? [n]: Selecione Enter para aceitar o padrão.
- Digite o nome do host do certificado para o host '...' [...]: Selecione Enter para aceitar o padrão.
- Digite a senha do usuário do SAP Host Agent (sapadm): digite a senha do usuário do host agent.
- Confirme a senha do usuário do SAP Host Agent (sapadm): insira a senha do usuário do host agent novamente para confirmar.
- Digite a senha do administrador do sistema (hn1adm): digite a senha do administrador do sistema.
- Confirme a senha do administrador do sistema (hn1adm): digite a senha do administrador do sistema novamente para confirmar.
- Digite System Administrator Home Directory [/usr/sap/HN1/home]: Selecione Enter para aceitar o padrão.
- Digite System Administrator Login Shell [/bin/sh]: Selecione Enter para aceitar o padrão.
- Digite o ID de usuário do administrador do sistema [1001]: Selecione Enter para aceitar o padrão.
- Digite ID do Grupo de Usuários (sapsys) [79]: Selecione Enter para aceitar o padrão.
- Digite a senha do usuário do banco de dados (SYSTEM): insira a senha do usuário do banco de dados.
- Confirmar senha do usuário do banco de dados (SYSTEM): digite a senha do usuário do banco de dados novamente para confirmar.
- Reiniciar o sistema após a reinicialização da máquina? [n]: Selecione Enter para aceitar o padrão.
- Quer continuar? (s/n): Valide o resumo. Digite y para continuar.
[A] Atualize o SAP Host Agent.
Faça o download do arquivo mais recente do SAP Host Agent no SAP Software Center e execute o seguinte comando para atualizar o agente. Substitua o caminho para o arquivo morto para apontar para o arquivo que você baixou:
sudo /usr/sap/hostctrl/exe/saphostexec -upgrade -archive <path to SAP Host Agent SAR>[A] Configure um firewall.
Crie a regra de firewall para a porta de investigação do Azure Load Balancer.
sudo firewall-cmd --zone=public --add-port=62503/tcp sudo firewall-cmd --zone=public --add-port=62503/tcp –permanent
Configurar a replicação do sistema SAP HANA
Siga as etapas em Configurar a replicação do sistema SAP HANA para configurar a replicação do sistema SAP HANA.
Configuração do cluster
Esta seção descreve as etapas necessárias para que um cluster opere perfeitamente quando o SAP HANA é instalado em compartilhamentos NFS usando os Arquivos NetApp do Azure.
Criar um cluster de marcapasso
Siga as etapas em Configurar o Pacemaker no Red Hat Enterprise Linux no Azure para criar um cluster básico do Pacemaker para este servidor HANA.
Importante
Com o SAP Startup Framework baseado em sistema, as instâncias do SAP HANA agora podem ser gerenciadas pelo systemd. A versão mínima necessária do Red Hat Enterprise Linux (RHEL) é o RHEL 8 for SAP. Conforme descrito na Nota 3189534 do SAP, quaisquer novas instalações do SAP HANA SPS07 revisão 70 ou superior, ou atualizações dos sistemas HANA para HANA 2.0 SPS07 revisão 70 ou superior, o framework SAP Startup será automaticamente registrado no systemd.
Ao usar soluções HA para gerenciar a replicação do sistema SAP HANA em combinação com instâncias SAP HANA habilitadas para sistema (consulte SAP Note 3189534), etapas adicionais são necessárias para garantir que o cluster HA possa gerenciar a instância SAP sem interferência do sistema. Portanto, para o sistema SAP HANA integrado ao systemd, etapas adicionais descritas no Red Hat KBA 7029705 devem ser seguidas em todos os nós do cluster.
Implementar o gancho de replicação do sistema Python SAPHanaSR
Esta etapa é importante para otimizar a integração com o cluster e melhorar a deteção quando um failover de cluster é necessário. É altamente recomendável que você configure o gancho SAPHanaSR Python. Siga as etapas em Implementar o gancho de replicação do sistema Python SAPHanaSR.
Configurar recursos do sistema de arquivos
Neste exemplo, cada nó de cluster tem seus próprios sistemas /hana/sharedde arquivos HANA NFS , /hana/datae /hana/log.
[1] Coloque o cluster no modo de manutenção.
sudo pcs property set maintenance-mode=true[1] Crie os recursos do sistema de ficheiros para as montagens hanadb1 .
sudo pcs resource create hana_data1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_log1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs sudo pcs resource create hana_shared1 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb1-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb1_nfs[2] Crie os recursos do sistema de ficheiros para as montagens hanadb2 .
sudo pcs resource create hana_data2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-data-mnt00001 directory=/hana/data fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_log2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-log-mnt00001 directory=/hana/log fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfs sudo pcs resource create hana_shared2 ocf:heartbeat:Filesystem device=10.32.2.4:/hanadb2-shared-mnt00001 directory=/hana/shared fstype=nfs options=rw,nfsvers=4.1,hard,timeo=600,rsize=262144,wsize=262144,noatime,lock,_netdev,sec=sys op monitor interval=20s on-fail=fence timeout=120s OCF_CHECK_LEVEL=20 --group hanadb2_nfsO
OCF_CHECK_LEVEL=20atributo é adicionado à operação do monitor para que cada monitor execute um teste de leitura/gravação no sistema de arquivos. Sem esse atributo, a operação do monitor apenas verifica se o sistema de arquivos está montado. Isso pode ser um problema porque quando a conectividade é perdida, o sistema de arquivos pode permanecer montado apesar de estar inacessível.O
on-fail=fenceatributo também é adicionado à operação do monitor. Com essa opção, se a operação do monitor falhar em um nó, esse nó será imediatamente cercado. Sem essa opção, o comportamento padrão é parar todos os recursos que dependem do recurso com falha, reiniciar o recurso com falha e, em seguida, iniciar todos os recursos que dependem do recurso com falha.Esse comportamento não só pode levar muito tempo quando um recurso SAPHana depende do recurso com falha, mas também pode falhar completamente. O recurso SAPHana não pode parar com êxito se o servidor NFS que contém os executáveis HANA estiver inacessível.
Os valores de tempo limite sugeridos permitem que os recursos do cluster suportem a pausa específica do protocolo, relacionada às renovações de concessão do NFSv4.1. Para obter mais informações, consulte NFS em NetApp Best practice. Os tempos limite na configuração anterior podem precisar ser adaptados à configuração específica do SAP.
Para cargas de trabalho que exigem uma taxa de transferência mais alta, considere usar a
nconnectopção mount, conforme descrito em volumes NFS v4.1 no Azure NetApp Files for SAP HANA. Verifique senconnecté suportado pelos Arquivos NetApp do Azure na sua versão do Linux.[1] Configurar restrições de localização.
Configure restrições de local para garantir que os recursos que gerenciam montagens exclusivas do hanadb1 nunca possam ser executados no hanadb2 e vice-versa.
sudo pcs constraint location hanadb1_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb2 sudo pcs constraint location hanadb2_nfs rule score=-INFINITY resource-discovery=never \#uname eq hanadb1A
resource-discovery=neveropção é definida porque as montagens exclusivas para cada nó compartilham o mesmo ponto de montagem. Por exemplo,hana_data1usa o ponto/hana/datade montagem ehana_data2também usa o ponto/hana/datade montagem. Compartilhar o mesmo ponto de montagem pode causar um falso positivo para uma operação de teste, quando o estado do recurso é verificado na inicialização do cluster e, por sua vez, pode causar um comportamento de recuperação desnecessário. Para evitar esse cenário, definaresource-discovery=never.[1] Configurar recursos de atributos.
Configure recursos de atributos. Esses atributos serão definidos como true se todas as montagens NFS de um nó (
/hana/data,/hana/log, e/hana/data) estiverem montadas. Caso contrário, eles serão definidos como false.sudo pcs resource create hana_nfs1_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs1_active sudo pcs resource create hana_nfs2_active ocf:pacemaker:attribute active_value=true inactive_value=false name=hana_nfs2_active[1] Configurar restrições de localização.
Configure restrições de local para garantir que o recurso de atributo do hanadb1 nunca seja executado no hanadb2 e vice-versa.
sudo pcs constraint location hana_nfs1_active avoids hanadb2 sudo pcs constraint location hana_nfs2_active avoids hanadb1[1] Criar restrições de ordenação.
Configure restrições de ordenação para que os recursos de atributo de um nó sejam iniciados somente depois que todas as montagens NFS do nó forem montadas.
sudo pcs constraint order hanadb1_nfs then hana_nfs1_active sudo pcs constraint order hanadb2_nfs then hana_nfs2_activeGorjeta
Se sua configuração incluir sistemas de arquivos, fora do grupo
hanadb1_nfsouhanadb2_nfs, inclua a opção parasequential=falseque não haja dependências de ordenação entre os sistemas de arquivos. Todos os sistemas de arquivos devem começar anteshana_nfs1_activedo , mas não precisam ser iniciados em nenhuma ordem em relação uns aos outros. Para obter mais informações, consulte Como configurar a replicação do sistema SAP HANA em escalabilidade escalável em um cluster Pacemaker quando os sistemas de arquivos HANA estão em compartilhamentos NFS
Configurar recursos de cluster do SAP HANA
Siga as etapas em Criar recursos de cluster do SAP HANA para criar os recursos do SAP HANA no cluster. Depois que os recursos do SAP HANA são criados, você precisa criar uma restrição de regra de local entre os recursos do SAP HANA e os sistemas de arquivos (montagens NFS).
[1] Configure restrições entre os recursos do SAP HANA e as montagens NFS.
As restrições da regra de localização são definidas para que os recursos do SAP HANA possam ser executados em um nó somente se todas as montagens NFS do nó estiverem montadas.
sudo pcs constraint location SAPHanaTopology_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueNo RHEL 7.x:
sudo pcs constraint location SAPHana_HN1_03-master rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne trueNo RHEL 8.x/9.x:
sudo pcs constraint location SAPHana_HN1_03-clone rule score=-INFINITY hana_nfs1_active ne true and hana_nfs2_active ne true[1] Configure restrições de ordenação para que os recursos SAP em um nó parem antes de uma parada para qualquer uma das montagens NFS.
pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHanaTopology_HN1_03-clone then stop hanadb2_nfsNo RHEL 7.x:
pcs constraint order stop SAPHana_HN1_03-master then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-master then stop hanadb2_nfsNo RHEL 8.x/9.x:
pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb1_nfs pcs constraint order stop SAPHana_HN1_03-clone then stop hanadb2_nfsTire o cluster do modo de manutenção.
sudo pcs property set maintenance-mode=falseVerifique o status do cluster e todos os recursos.
Nota
Este artigo contém referências a um termo que a Microsoft já não utiliza. Quando o termo for removido do software, iremos removê-lo deste artigo.
sudo pcs statusSaída de exemplo:
Online: [ hanadb1 hanadb2 ] Full list of resources: rsc_hdb_azr_agt(stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem):Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem):Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem):Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1
Configurar a replicação do sistema ativo/habilitado para leitura do HANA no cluster do Pacemaker
A partir do SAP HANA 2.0 SPS 01, o SAP permite configurações ativas/habilitadas para leitura para o SAP HANA System Replication, onde os sistemas secundários do SAP HANA System Replication podem ser usados ativamente para cargas de trabalho de leitura intensa. Para suportar essa configuração em um cluster, é necessário um segundo endereço IP virtual, que permite que os clientes acessem o banco de dados secundário SAP HANA habilitado para leitura.
Para garantir que o local de replicação secundária ainda possa ser acessado após a ocorrência de uma aquisição, o cluster precisa mover o endereço IP virtual com o secundário do recurso SAPHana.
A configuração extra, que é necessária para gerenciar a replicação do sistema ativa/habilitada para leitura do HANA em um cluster Red Hat HA com um segundo IP virtual, é descrita em Configurar a replicação do sistema ativa/habilitada para leitura do HANA no cluster do Pacemaker.
Antes de prosseguir, verifique se você configurou totalmente o Red Hat High Availability Cluster gerenciando o banco de dados SAP HANA, conforme descrito nas seções anteriores da documentação.
Testar a configuração do cluster
Esta seção descreve como você pode testar sua configuração.
Antes de iniciar um teste, certifique-se de que o Pacemaker não tem nenhuma ação com falha (via status do pcs), não há restrições de local inesperadas (por exemplo, sobras de um teste de migração) e que a replicação do sistema HANA está em estado sincronizado, por exemplo, com
systemReplicationStatus:sudo su - hn1adm -c "python /usr/sap/HN1/HDB03/exe/python_support/systemReplicationStatus.py"Verifique a configuração do cluster para um cenário de falha quando um nó perde o acesso ao compartilhamento NFS (
/hana/shared).Os agentes de recursos do SAP HANA dependem de binários armazenados para
/hana/sharedexecutar operações durante o failover. O sistema/hana/sharedde arquivos é montado sobre NFS no cenário apresentado.É difícil simular uma falha em que um dos servidores perde o acesso ao compartilhamento NFS. Como teste, você pode remontar o sistema de arquivos como somente leitura. Essa abordagem valida que o cluster pode fazer failover, se o acesso a
/hana/sharedfor perdido no nó ativo.Resultado esperado: ao criar
/hana/sharedcomo um sistema de arquivos somente leitura, oOCF_CHECK_LEVELatributo do recursohana_shared1, que executa operações de leitura/gravação em sistemas de arquivos, falha. Ele não é capaz de escrever nada no sistema de arquivos e executa failover de recursos HANA. O mesmo resultado é esperado quando o nó HANA perde o acesso aos compartilhamentos NFS.Estado do recurso antes de iniciar o teste:
sudo pcs statusSaída de exemplo:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb1 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_log1 (ocf::heartbeat:Filesystem): Started hanadb1 hana_shared1 (ocf::heartbeat:Filesystem): Started hanadb1 Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Started hanadb1 hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb1 hanadb2 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb1 ] Slaves: [ hanadb2 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb1 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb1Você pode colocar
/hana/sharedno modo somente leitura no nó de cluster ativo usando este comando:sudo mount -o ro 10.32.2.4:/hanadb1-shared-mnt00001 /hana/sharedhanadbserá reinicializado ou desligado com base na ação definida emstonith(pcs property show stonith-action). Quando o servidor (hanadb1) estiver inativo, o recurso HANA será movido parahanadb2. Você pode verificar o status do cluster emhanadb2.sudo pcs statusSaída de exemplo:
Full list of resources: rsc_hdb_azr_agt (stonith:fence_azure_arm): Started hanadb2 Resource Group: hanadb1_nfs hana_data1 (ocf::heartbeat:Filesystem): Stopped hana_log1 (ocf::heartbeat:Filesystem): Stopped hana_shared1 (ocf::heartbeat:Filesystem): Stopped Resource Group: hanadb2_nfs hana_data2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_log2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_shared2 (ocf::heartbeat:Filesystem): Started hanadb2 hana_nfs1_active (ocf::pacemaker:attribute): Stopped hana_nfs2_active (ocf::pacemaker:attribute): Started hanadb2 Clone Set: SAPHanaTopology_HN1_03-clone [SAPHanaTopology_HN1_03] Started: [ hanadb2 ] Stopped: [ hanadb1 ] Master/Slave Set: SAPHana_HN1_03-master [SAPHana_HN1_03] Masters: [ hanadb2 ] Stopped: [ hanadb1 ] Resource Group: g_ip_HN1_03 nc_HN1_03 (ocf::heartbeat:azure-lb): Started hanadb2 vip_HN1_03 (ocf::heartbeat:IPaddr2): Started hanadb2Recomendamos que você teste completamente a configuração do cluster SAP HANA executando também os testes descritos em Configurar a replicação do sistema SAP HANA no RHEL.