Validação de entrada em consultas do Azure Stream Analytics
A validação de entrada é uma técnica a ser usada para proteger a lógica de consulta principal contra eventos malformados ou inesperados. A consulta é atualizada para processar e verificar registros explicitamente para que eles não possam quebrar a lógica principal.
Para implementar a validação de entrada, adicionamos duas etapas iniciais a uma consulta. Primeiro, certificamo-nos de que o esquema submetido à lógica de negócios principal corresponde às suas expectativas. Em seguida, triamos exceções e, opcionalmente, encaminhamos registros inválidos para uma saída secundária.
Uma consulta com validação de entrada será estruturada da seguinte forma:
WITH preProcessingStage AS (
SELECT
-- Rename incoming fields, used for audit and debugging
field1 AS in_field1,
field2 AS in_field2,
...
-- Try casting fields in their expected type
TRY_CAST(field1 AS bigint) as field1,
TRY_CAST(field2 AS array) as field2,
...
FROM myInput TIMESTAMP BY myTimestamp
),
triagedOK AS (
SELECT -- Only fields in their new expected type
field1,
field2,
...
FROM preProcessingStage
WHERE ( ... ) -- Clauses make sure that the core business logic expectations are satisfied
),
triagedOut AS (
SELECT -- All fields to ease diagnostic
*
FROM preProcessingStage
WHERE NOT (...) -- Same clauses as triagedOK, opposed with NOT
)
-- Core business logic
SELECT
...
INTO myOutput
FROM triagedOK
...
-- Audit output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- To a storage adapter that doesn't require strong typing, here blob/adls
FROM triagedOut
Para ver um exemplo abrangente de uma consulta configurada com validação de entrada, consulte a seção: Exemplo de consulta com validação de entrada.
Este artigo ilustra como implementar essa técnica.
Contexto
Os trabalhos do Azure Stream Analytics (ASA) processam dados provenientes de fluxos. Fluxos são sequências de dados brutos que são transmitidos serializados (CSV, JSON, AVRO...). Para ler a partir de um fluxo, um aplicativo precisará saber o formato de serialização específico usado. No ASA, o formato de serialização de eventos deve ser definido ao configurar uma entrada de streaming.
Uma vez que os dados são desserializados, um esquema precisa ser aplicado para dar-lhes significado. Por esquema, queremos dizer a lista de campos no fluxo e seus respetivos tipos de dados. Com o ASA, o esquema dos dados de entrada não precisa ser definido no nível de entrada. Em vez disso, o ASA suporta esquemas de entrada dinâmicos nativamente. Ele espera que a lista de campos (colunas) e seus tipos mudem entre eventos (linhas). O ASA também inferirá tipos de dados quando nenhum for fornecido explicitamente e tentará converter tipos implicitamente quando necessário.
A manipulação dinâmica de esquemas é um recurso poderoso, fundamental para o processamento de fluxo. Os fluxos de dados geralmente contêm dados de várias fontes, com vários tipos de eventos, cada um com um esquema exclusivo. Para encaminhar, filtrar e processar eventos em tais fluxos, o ASA tem que ingeri-los todos, seja qual for o seu esquema.
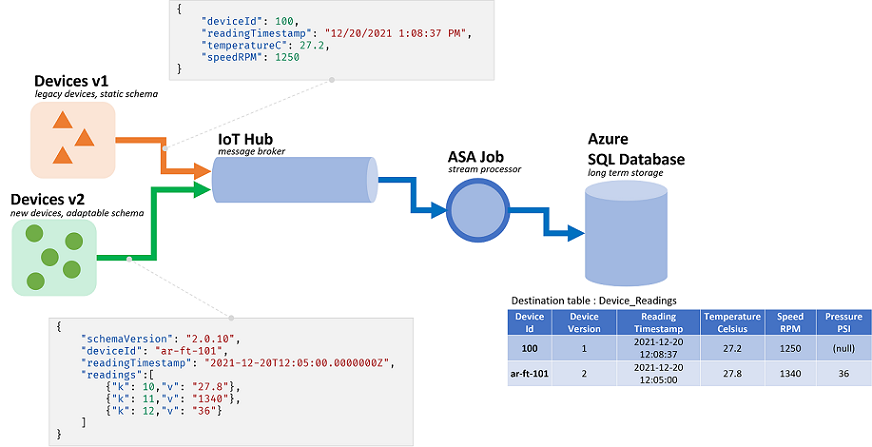
Mas os recursos oferecidos pela manipulação dinâmica de esquemas vêm com uma desvantagem potencial. Eventos inesperados podem fluir através da lógica de consulta principal e quebrá-la. Como exemplo, podemos usar ROUND em um campo do tipo NVARCHAR(MAX). ASA irá implicitamente lançá-lo para flutuar para corresponder à assinatura de ROUND. Aqui esperamos, ou esperamos, que este campo contenha sempre valores numéricos. Mas quando recebemos um evento com o campo definido como "NaN", ou se o campo estiver totalmente ausente, o trabalho pode falhar.
Com a validação de entrada, adicionamos etapas preliminares à nossa consulta para lidar com esses eventos malformados. Usaremos principalmente WITH e TRY_CAST para implementá-lo.
Cenário: validação de entrada para produtores de eventos não confiáveis
Criaremos um novo trabalho ASA que ingerirá dados de um único hub de eventos. Como acontece na maioria das vezes, não somos responsáveis pelos produtores de dados. Aqui, os produtores são dispositivos IoT vendidos por vários fornecedores de hardware.
Reunindo-nos com as partes interessadas, acordamos um formato de serialização e um esquema. Todos os dispositivos enviarão essas mensagens para um hub de eventos comum, a entrada do trabalho ASA.
O contrato de esquema é definido da seguinte forma:
| Nome do campo | Tipo de campo | Descrição do campo |
|---|---|---|
deviceId |
Número inteiro | Identificador exclusivo do dispositivo |
readingTimestamp |
Datetime | Tempo de mensagem, gerado por um gateway central |
readingStr |
String | |
readingNum |
Numérico | |
readingArray |
Matriz de String |
O que, por sua vez, nos dá a seguinte mensagem de exemplo em serialização JSON:
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7,
"readingArray" : ["A","B"]
}
Já podemos ver uma discrepância entre o contrato do esquema e sua implementação. No formato JSON, não há nenhum tipo de dados para datetime. Ele será transmitido como uma string (veja readingTimestamp acima). O ASA pode facilmente resolver o problema, mas mostra a necessidade de validar e transmitir explicitamente os tipos. Ainda mais para dados serializados em CSV, uma vez que todos os valores são transmitidos como string.
Há outra discrepância. O ASA usa seu próprio sistema de tipo que não corresponde ao de entrada. Se o ASA tiver tipos internos para inteiros (bigint), datetime, string (nvarchar(max)) e matrizes, ele só suporta numéricos via float. Essa incompatibilidade não é um problema para a maioria dos aplicativos. Mas, em certos casos extremos, pode causar ligeiras derrapagens na precisão. Nesse caso, converteríamos o valor numérico como string em um novo campo. Então, a jusante, usaríamos um sistema que suporta decimal fixo para detetar e corrigir desvios potenciais.
Voltando à nossa consulta, aqui pretendemos:
- Passar
readingStrpara um UDF JavaScript - Contar o número de registros na matriz
- Arredondar
readingNumpara a segunda casa decimal - Inserir os dados em uma tabela SQL
A tabela SQL de destino tem o seguinte esquema:
CREATE TABLE [dbo].[readings](
[Device_Id] int NULL,
[Reading_Timestamp] datetime2(7) NULL,
[Reading_String] nvarchar(200) NULL,
[Reading_Num] decimal(18,2) NULL,
[Array_Count] int NULL
) ON [PRIMARY]
É uma boa prática mapear o que acontece com cada campo ao longo do trabalho:
| Campo | Entrada (JSON) | Tipo hereditário (ASA) | Saída (Azure SQL) | Comentário |
|---|---|---|---|---|
deviceId |
Número | bigint | integer | |
readingTimestamp |
string | nvarchar(MAX) | datetime2 | |
readingStr |
string | nvarchar(MAX) | Nvarchar(200) | utilizado pela UDF |
readingNum |
Número | flutuante | decimal(18,2) | a arredondar |
readingArray |
matriz(string) | matriz de nvarchar (MAX) | integer | a contar |
Pré-requisitos
Desenvolveremos a consulta no Visual Studio Code usando a extensão ASA Tools . Os primeiros passos deste tutorial irão guiá-lo através da instalação dos componentes necessários.
No VS Code, usaremos execuções locais com entrada/saída local para não incorrer em nenhum custo e aceleraremos o loop de depuração. Não precisaremos configurar um hub de eventos ou um Banco de Dados SQL do Azure.
Consulta base
Vamos começar com uma implementação básica, sem validação de entrada. Vamos adicioná-lo na próxima seção.
No VS Code, criaremos um novo projeto ASA
input Na pasta, criaremos um novo arquivo JSON chamado data_readings.json e adicionaremos os seguintes registros a ele:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingStr" : "Another String",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : -4.85436,
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : ["G","G"]
}
]
Em seguida, definiremos uma entrada local, chamada readings, fazendo referência ao arquivo JSON que criamos acima.
Uma vez configurado, deve ter a seguinte aparência:
{
"InputAlias": "readings",
"Type": "Data Stream",
"Format": "Json",
"FilePath": "data_readings.json",
"ScriptType": "InputMock"
}
Com dados de visualização, podemos observar que nossos registros são carregados corretamente.
Vamos criar um novo JavaScript UDF chamado udfLen clicando com o botão direito do Functions mouse na pasta e selecionando ASA: Add Function. O código que usaremos é:
// Sample UDF that returns the length of a string for demonstration only: LEN will return the same thing in ASAQL
function main(arg1) {
return arg1.length;
}
Em execuções locais, não precisamos definir saídas. Nem precisamos usar INTO , a menos que haja mais de uma saída. .asaql No arquivo, podemos substituir a consulta existente por:
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
FROM readings AS r TIMESTAMP BY r.readingTimestamp
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
Vamos analisar rapidamente a consulta que enviamos:
- Para contar o número de registros em cada matriz, primeiro precisamos descompactá-los. Usaremos CROSS APPLY e GetArrayElements() (mais exemplos aqui)
- Fazendo isso, apresentamos dois conjuntos de dados na consulta: a entrada original e os valores da matriz. Para garantir que não misturamos campos, definimos aliases (
AS r) e os usamos em todos os lugares - Então, para realmente
COUNTos valores da matriz, precisamos agregar com GROUP BY - Para isso, temos de definir uma janela temporal. Aqui, como não precisamos de um para nossa lógica, a janela de instantâneo é a escolha certa
- Fazendo isso, apresentamos dois conjuntos de dados na consulta: a entrada original e os valores da matriz. Para garantir que não misturamos campos, definimos aliases (
- Temos também para
GROUP BYtodos os campos, e projetá-los todos noSELECT. A projeção explícita de campos é uma boa prática, poisSELECT *permitirá que os erros fluam da entrada para a saída- Se definirmos uma janela de tempo, podemos querer definir um carimbo de data/hora com TIMESTAMP BY. Aqui não é necessário que a nossa lógica funcione. Para execuções locais, sem
TIMESTAMP BYque todos os registros sejam carregados em um único carimbo de data/hora, a hora de início da execução.
- Se definirmos uma janela de tempo, podemos querer definir um carimbo de data/hora com TIMESTAMP BY. Aqui não é necessário que a nossa lógica funcione. Para execuções locais, sem
- Usamos o UDF para filtrar leituras onde
readingStrtem menos de dois caracteres. Deveríamos ter usado LEN aqui. Estamos usando um UDF apenas para fins de demonstração
Podemos iniciar uma corrida e observar os dados que estão sendo processados:
| deviceId | leituraCarimbo de data/hora | leituraStr | leituraNum | arrayCount |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Uma cadeia de caracteres | 1,71 | 2 |
| 2 | 2021-12-10T10:01:00 | Outra String | 2.38 | 1 |
| 3 | 2021-12-10T10:01:20 | Uma terceira cadeia de caracteres | -4.85 | 3 |
| 1 | 2021-12-10T10:02:10 | Uma quarta corda | 1.21 | 2 |
Agora que sabemos que nossa consulta está funcionando, vamos testá-la em relação a mais dados. Vamos substituir o conteúdo do data_readings.json pelos seguintes registros:
[
{
"deviceId" : 1,
"readingTimestamp" : "2021-12-10T10:00:00",
"readingStr" : "A String",
"readingNum" : 1.7145,
"readingArray" : ["A","B"]
},
{
"deviceId" : 2,
"readingTimestamp" : "2021-12-10T10:01:00",
"readingNum" : 2.378,
"readingArray" : ["C"]
},
{
"deviceId" : 3,
"readingTimestamp" : "2021-12-10T10:01:20",
"readingStr" : "A Third String",
"readingNum" : "NaN",
"readingArray" : ["D","E","F"]
},
{
"deviceId" : 4,
"readingTimestamp" : "2021-12-10T10:02:10",
"readingStr" : "A Forth String",
"readingNum" : 1.2126,
"readingArray" : {}
}
]
Aqui podemos ver as seguintes questões:
- O dispositivo #1 fez tudo certo
- O dispositivo #2 esqueceu-se de incluir um
readingStr - Dispositivo #3 enviado
NaNcomo um número - O dispositivo #4 enviou um registro vazio em vez de uma matriz
Executar o trabalho agora não deve terminar bem. Receberemos uma das seguintes mensagens de erro:
O Dispositivo 2 nos dará:
[Error] 12/22/2021 10:05:59 PM : **System Exception** Function 'udflen' resulted in an error: 'TypeError: Unable to get property 'length' of undefined or null reference' Stack: TypeError: Unable to get property 'length' of undefined or null reference at main (Unknown script code:3:5)
[Error] 12/22/2021 10:05:59 PM : at Microsoft.EventProcessing.HostedRuntimes.JavaScript.JavaScriptHostedFunctionsRuntime.
O Dispositivo 3 nos dará:
[Error] 12/22/2021 9:52:32 PM : **System Exception** The 1st argument of function round has invalid type 'nvarchar(max)'. Only 'bigint', 'float' is allowed.
[Error] 12/22/2021 9:52:32 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Arithmetics.Round(CompilerPosition pos, Object value, Object length)
O dispositivo 4 nos dará:
[Error] 12/22/2021 9:50:41 PM : **System Exception** Cannot cast value of type 'record' to type 'array' in expression 'r . readingArray'. At line '9' and column '30'. TRY_CAST function can be used to handle values with unexpected type.
[Error] 12/22/2021 9:50:41 PM : at Microsoft.EventProcessing.SteamR.Sql.Runtime.Cast.ToArray(CompilerPosition pos, Object value, Boolean isUserCast)
Cada vez que os registros malformados podiam fluir da entrada para a lógica de consulta principal sem serem validados. Agora percebemos o valor da validação de entrada.
Implementando a validação de entrada
Vamos estender nossa consulta para validar a entrada.
A primeira etapa da validação de entrada é definir as expectativas de esquema da lógica de negócios principal. Olhando para o requisito original, a nossa lógica principal é:
- Passe
readingStrpara um UDF JavaScript para medir seu comprimento - Contar o número de registros na matriz
- Arredondar
readingNumpara a segunda casa decimal - Inserir os dados em uma tabela SQL
Para cada ponto podemos elencar as expectativas:
- O UDF requer um argumento do tipo string (nvarchar(max) aqui) que não pode ser nulo
GetArrayElements()requer um argumento do tipo array ou um valor nuloRoundrequer um argumento do tipo bigint ou float, ou um valor nulo- Em vez de confiar na transmissão implícita do ASA, devemos fazê-lo nós mesmos e lidar com conflitos de tipo na consulta
Um caminho a seguir é adaptar a lógica principal para lidar com essas exceções. Mas, neste caso, acreditamos que a nossa lógica principal é perfeita. Então, vamos validar os dados recebidos.
Primeiro, vamos usar WITH para adicionar uma camada de validação de entrada como a primeira etapa da consulta. Usaremos TRY_CAST para converter campos para o tipo esperado e defini-los se NULL a conversão falhar:
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
)
-- For debugging only
SELECT * FROM readingsValidated
Com o último arquivo de entrada que usamos (aquele com erros), esta consulta retornará o seguinte conjunto:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | leituraCarimbo de data/hora | leituraStr | leituraNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00 | Uma cadeia de caracteres | 1.7145 | ["A","B"] | 1 | 2021-12-10T10:00:00.0000000Z | Uma cadeia de caracteres | 1.7145 | ["A","B"] |
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULL | 2.378 | ["C"] |
| 3 | 2021-12-10T10:01:20 | Uma terceira cadeia de caracteres | NaN | ["D","E","F"] | 3 | 2021-12-10T10:01:20.0000000Z | Uma terceira cadeia de caracteres | NULO | ["D","E","F"] |
| 4 | 2021-12-10T10:02:10 | Uma quarta corda | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Uma quarta corda | 1.2126 | NULO |
Já podemos ver dois dos nossos erros a serem corrigidos. Nós nos transformamos NaN e {} em NULL. Agora estamos confiantes de que esses registros serão inseridos corretamente na tabela SQL de destino.
Agora temos que decidir como lidar com os registros com valores ausentes ou inválidos. Depois de alguma discussão, decidimos rejeitar registros com um vazio/inválido readingArray ou um ausente readingStr.
Assim, adicionamos uma segunda camada que fará a triagem dos registros entre a validação e a lógica principal:
WITH readingsValidated AS (
...
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- For debugging only
SELECT * INTO Debug1 FROM readingsToBeProcessed
SELECT * INTO Debug2 FROM readingsToBeRejected
É uma boa prática escrever uma única WHERE cláusula para ambas as saídas e usar NOT (...) na segunda. Dessa forma, nenhum registro pode ser excluído das saídas e perdido.
Agora temos duas saídas. Debug1 tem os registros que serão enviados para a lógica principal:
| deviceId | leituraCarimbo de data/hora | leituraStr | leituraNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Uma cadeia de caracteres | 1.7145 | ["A","B"] |
| 3 | 2021-12-10T10:01:20.0000000Z | Uma terceira cadeia de caracteres | NULL | ["D","E","F"] |
Debug2 tem os registros que serão rejeitados:
| in_deviceId | in_readingTimestamp | in_readingStr | in_readingNum | in_readingArray | deviceId | leituraCarimbo de data/hora | leituraStr | leituraNum | readingArray |
|---|---|---|---|---|---|---|---|---|---|
| 2 | 2021-12-10T10:01:00 | NULL | 2.378 | ["C"] | 2 | 2021-12-10T10:01:00.0000000Z | NULO | 2.378 | ["C"] |
| 4 | 2021-12-10T10:02:10 | Uma quarta corda | 1.2126 | {} | 4 | 2021-12-10T10:02:10.0000000Z | Uma quarta corda | 1.2126 | NULO |
O passo final é adicionar nossa lógica principal de volta. Também adicionaremos a saída que reúne rejeições. Aqui é melhor usar um adaptador de saída que não imponha digitação forte, como uma conta de armazenamento.
A consulta completa pode ser encontrada na última seção.
WITH
readingsValidated AS (...),
readingsToBeProcessed AS (...),
readingsToBeRejected AS (...)
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
SELECT
*
INTO BlobOutput
FROM readingsToBeRejected
O que nos dará o seguinte conjunto para SQLOutput, sem erro possível:
| deviceId | leituraCarimbo de data/hora | leituraStr | leituraNum | readingArray |
|---|---|---|---|---|
| 1 | 2021-12-10T10:00:00.0000000Z | Uma cadeia de caracteres | 1.7145 | 2 |
| 3 | 2021-12-10T10:01:20.0000000Z | Uma terceira cadeia de caracteres | NULL | 3 |
Os outros dois registros são enviados para um BlobOutput para revisão humana e pós-processamento. A nossa consulta está agora segura.
Exemplo de consulta com validação de entrada
WITH readingsValidated AS (
SELECT
-- Rename incoming fields, used for audit and debugging
deviceId AS in_deviceId,
readingTimestamp AS in_readingTimestamp,
readingStr AS in_readingStr,
readingNum AS in_readingNum,
readingArray AS in_readingArray,
-- Try casting fields in their expected type
TRY_CAST(deviceId AS bigint) as deviceId,
TRY_CAST(readingTimestamp AS datetime) as readingTimestamp,
TRY_CAST(readingStr AS nvarchar(max)) as readingStr,
TRY_CAST(readingNum AS float) as readingNum,
TRY_CAST(readingArray AS array) as readingArray
FROM readings TIMESTAMP BY readingTimestamp
),
readingsToBeProcessed AS (
SELECT
deviceId,
readingTimestamp,
readingStr,
readingNum,
readingArray
FROM readingsValidated
WHERE
readingStr IS NOT NULL
AND readingArray IS NOT NULL
),
readingsToBeRejected AS (
SELECT
*
FROM readingsValidated
WHERE -- Same clauses as readingsToBeProcessed, opposed with NOT
NOT (
readingStr IS NOT NULL
AND readingArray IS NOT NULL
)
)
-- Core business logic
SELECT
r.deviceId,
r.readingTimestamp,
SUBSTRING(r.readingStr,1,200) AS readingStr,
ROUND(r.readingNum,2) AS readingNum,
COUNT(a.ArrayValue) AS arrayCount
INTO SQLOutput
FROM readingsToBeProcessed AS r
CROSS APPLY GetArrayElements(r.readingArray) AS a
WHERE UDF.udfLen(r.readingStr) >= 2
GROUP BY
System.Timestamp(), --snapshot window
r.deviceId,
r.readingTimestamp,
r.readingStr,
r.readingNum
-- Rejected output. For human review, correction, and manual re-insertion downstream
SELECT
*
INTO BlobOutput -- to a storage adapter that doesn't require strong typing, here blob/adls
FROM readingsToBeRejected
Estendendo a validação de entrada
GetType pode ser usado para verificar explicitamente se há um tipo. Funciona bem com CASE na projeção, ou WHERE no nível definido. GetType também pode ser usado para verificar dinamicamente o esquema de entrada em relação a um repositório de metadados. O repositório pode ser carregado através de um conjunto de dados de referência.
O teste de unidade é uma boa prática para garantir que nossa consulta seja resiliente. Vamos construir uma série de testes que consistem em arquivos de entrada e sua saída esperada. Nossa consulta terá que corresponder à saída que gera para passar. No ASA, o teste de unidade é feito através do módulo npm asa-streamanalytics-cicd . Casos de teste com vários eventos malformados devem ser criados e testados no pipeline de implantação.
Finalmente, podemos fazer alguns testes de integração leve no VS Code. Podemos inserir registros na tabela SQL através de uma execução local para uma saída ao vivo.
Obter suporte
Para obter mais assistência, experimente a nossa página de perguntas e respostas da Microsoft para o Azure Stream Analytics.
Próximos passos
- Configurar pipelines de CI/CD e testes de unidade usando o pacote npm
- Visão geral do Stream Analytics local é executado no Visual Studio Code com ASA Tools
- Testar consultas do Stream Analytics localmente com dados de exemplo usando o Visual Studio Code
- Testar consultas do Stream Analytics localmente em relação à entrada de fluxo ao vivo usando o Visual Studio Code
- Explore os trabalhos do Azure Stream Analytics com o Visual Studio Code (visualização)