Início Rápido: Criar um conjunto do Apache Spark sem servidor no Azure Synapse Analytics com ferramentas Web
Neste início rápido, irá aprender a criar um conjunto do Apache Spark sem servidor no Azure Synapse com ferramentas Web. Em seguida, irá aprender a ligar ao conjunto do Apache Spark e a executar consultas SQL do Spark em ficheiros e tabelas. O Apache Spark permite uma análise de dados e computação de clusters rápidas através do processamento dentro da memória. Para obter informações sobre o Spark no Azure Synapse, veja Descrição geral: Apache Spark no Azure Synapse.
Importante
A faturação de instâncias do Spark é proporcional por minuto, quer esteja a utilizá-las ou não. Certifique-se de que encerra a instância do Spark depois de a utilizar ou defina um curto tempo limite. Para obter mais informações, consulte a secção Limpar recursos deste artigo.
Se não tiver uma subscrição do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Precisará de uma subscrição do Azure. Se necessário, crie uma conta gratuita do Azure
- Área de trabalho do Synapse Analytics
- Conjunto do Apache Spark sem servidor
Iniciar sessão no portal do Azure
Inicie sessão no portal do Azure.
Se não tiver uma subscrição do Azure, crie uma conta gratuita do Azure antes de começar.
Criar um bloco de notas
Um bloco de notas é um ambiente interativo que suporta várias linguagens de programação. O bloco de notas permite-lhe interagir com os seus dados, combinar código com markdown, texto e executar visualizações simples.
Na vista do portal do Azure para a área de trabalho do Azure Synapse que pretende utilizar, selecione Iniciar o Synapse Studio.
Assim que o Synapse Studio for iniciado, selecione Desenvolver. Em seguida, selecione o ícone "+" para adicionar um novo recurso.
A partir daí, selecione Bloco de Notas. É criado e aberto um novo bloco de notas com um nome gerado automaticamente.

Na janela Propriedades , forneça um nome para o bloco de notas.
Na barra de ferramentas, clique em Publicar.
Se existir apenas um conjunto do Apache Spark na área de trabalho, está selecionado por predefinição. Utilize o menu pendente para selecionar o conjunto do Apache Spark correto se nenhum estiver selecionado.
Clique em Adicionar código. O idioma predefinido é
Pyspark. Vai utilizar uma mistura de Pyspark e Spark SQL, pelo que a opção predefinida é boa. Outros idiomas suportados são Scala e .NET para Spark.Em seguida, vai criar um objeto DataFrame do Spark simples para manipular. Neste caso, vai criá-lo a partir do código. Existem três linhas e três colunas:
new_rows = [('CA',22, 45000),("WA",35,65000) ,("WA",50,85000)] demo_df = spark.createDataFrame(new_rows, ['state', 'age', 'salary']) demo_df.show()Agora, execute a célula com um dos seguintes métodos:
Prima SHIFT + ENTER.
Selecione o ícone de reprodução azul à esquerda da célula.
Selecione o botão Executar tudo na barra de ferramentas.
Se a instância do conjunto do Apache Spark ainda não estiver em execução, será iniciada automaticamente. Pode ver o estado da instância do conjunto do Apache Spark abaixo da célula que está a executar e também no painel de estado na parte inferior do bloco de notas. Consoante o tamanho do conjunto, o início deve demorar entre 2 a 5 minutos. Assim que o código terminar de ser executado, as informações abaixo da célula mostram quanto tempo demorou a ser executado e a respetiva execução. Na célula de saída, verá o resultado.
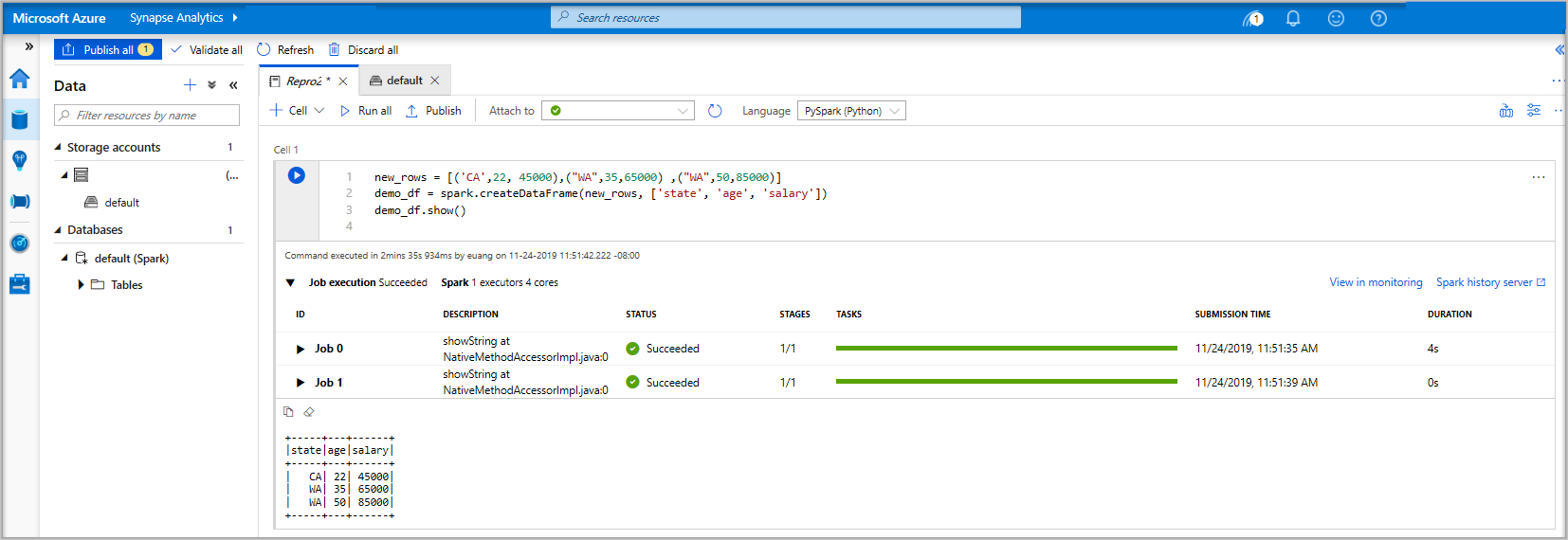
Os dados já existem num DataFrame a partir daí, pode utilizar os dados de várias formas diferentes. Vai precisar dele em formatos diferentes para o resto deste início rápido.
Introduza o código abaixo noutra célula e execute-o, isto cria uma tabela do Spark, um CSV e um ficheiro Parquet com cópias dos dados:
demo_df.createOrReplaceTempView('demo_df') demo_df.write.csv('demo_df', mode='overwrite') demo_df.write.parquet('abfss://<<TheNameOfAStorageAccountFileSystem>>@<<TheNameOfAStorageAccount>>.dfs.core.windows.net/demodata/demo_df', mode='overwrite')Se utilizar o explorador de armazenamento, é possível ver o impacto das duas formas diferentes de escrever um ficheiro utilizado acima. Quando não é especificado nenhum sistema de ficheiros, a predefinição é utilizada, neste caso
default>user>trusted-service-user>demo_df. Os dados são guardados na localização do sistema de ficheiros especificado.Repare que nos formatos "csv" e "parquet", as operações de escrita são criadas num diretório com muitos ficheiros particionados.


Executar instruções SQL do Spark
linguagem SQL (Structured Query Language) (SQL) é a linguagem mais comum e amplamente utilizada para consultar e definir dados. O Spark SQL funciona como uma extensão do Apache Spark para o processamento de dados estruturados e utiliza a sintaxe familiar do SQL Server.
Cole o seguinte código numa célula vazia e, em seguida, execute o código. O comando lista as tabelas no conjunto.
%%sql SHOW TABLESQuando utiliza um Bloco de Notas com o conjunto do Apache Spark do Azure Synapse, obtém uma predefinição
sqlContextque pode utilizar para executar consultas com o Spark SQL.%%sqlindica ao bloco de notas para utilizar a predefiniçãosqlContextpara executar a consulta. A consulta obtém as 10 principais linhas de uma tabela de sistema fornecida com todos os conjuntos do Apache Spark do Azure Synapse por predefinição.Execute outra consulta para ver os dados no
demo_df.%%sql SELECT * FROM demo_dfO código produz duas células de saída, uma que contém dados resulta na outra, que mostra a vista de tarefa.
Por predefinição, a vista de resultados mostra uma grelha. Contudo, existe um comutador de vista por baixo da grelha que permite que a vista alterne entre as vistas de grelha e gráfico.

No comutador Ver , selecione Gráfico.
Selecione o ícone Ver opções no lado direito.
No campo Tipo de gráfico , selecione "gráfico de barras".
No campo de coluna do eixo X, selecione "estado".
No campo coluna eixo Y, selecione "salário".
No campo Agregação , selecione "AVG".
Selecione Aplicar.

É possível obter a mesma experiência de execução do SQL, mas sem ter de mudar de idiomas. Pode fazê-lo ao substituir a célula SQL acima por esta célula PySpark. A experiência de saída é a mesma porque é utilizado o comando de apresentação :
display(spark.sql('SELECT * FROM demo_df'))Cada uma das células executadas anteriormente tinha a opção de aceder ao Servidor de Histórico e Monitorização. Clicar nas ligações leva-o a diferentes partes da Experiência de Utilizador.
Nota
Parte da documentação oficial do Apache Spark baseia-se na utilização da consola do Spark, que não está disponível no Synapse Spark. Em alternativa, utilize o bloco de notas ou as experiências do IntelliJ .
Limpar os recursos
O Azure Synapse guarda os seus dados no Azure Data Lake Storage. Pode permitir que uma instância do Spark seja encerrada em segurança quando não estiver a ser utilizada. É-lhe cobrado um conjunto do Apache Spark sem servidor, desde que esteja em execução, mesmo quando não está a ser utilizado.
Uma vez que os custos do conjunto são muitas vezes mais do que os custos de armazenamento, faz sentido económico permitir que as instâncias do Spark sejam encerradas quando não estão a ser utilizadas.
Para garantir que a instância do Spark está encerrada, termine todas as sessões ligadas (blocos de notas). O conjunto é encerrado quando o tempo de inatividade especificado no conjunto do Apache Spark é atingido. Também pode selecionar a sessão de fim na barra de estado na parte inferior do bloco de notas.
Passos seguintes
Neste início rápido, aprendeu a criar um conjunto do Apache Spark sem servidor e a executar uma consulta SQL básica do Spark.