Preparar os dados
Observação
Para maior funcionalidade, o PyTorch também pode ser usado com DirectML no Windows.
Na etapa anterior deste tutorial, instalamos o PyTorch no seu computador. Agora, vamos usá-lo para configurar o código com os dados que vamos usar para criar o modelo.
Abrir um novo projeto no Visual Studio.
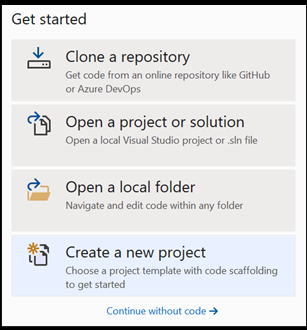
- Abra o Visual Studio e escolha
create a new project.
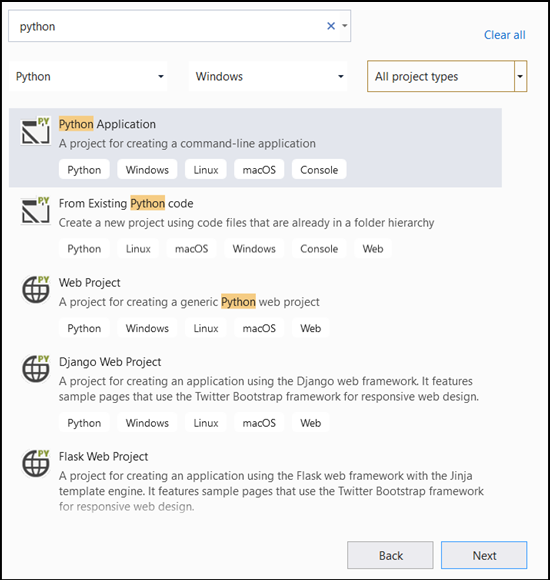
- Na barra de pesquisa, digite
Pythone selecionePython Applicationcomo o modelo de projeto.
- Na janela de configuração:
- Nomeie o projeto. Aqui o chamamos de PyTorchTraining.
- Escolha o local do projeto.
- Se você está usando o VS2019, verifique se
Create directory for solutionestá marcado. - Se você está usando o VS 2017, verifique se
Place solution and project in the same directoryestá desmarcado.

Pressione create para criar o projeto.
Criar um interpretador do Python
Você precisa definir um novo interpretador do Python. Isso deve incluir o pacote PyTorch instalado recentemente.
- Navegue até a seleção do interpretador e selecione
Add environment:
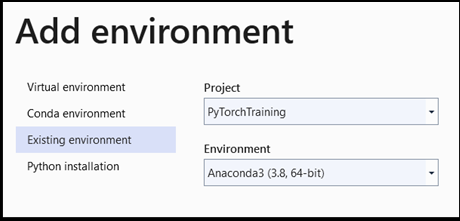
- Na janela
Add environment, selecioneExisting environmente escolhaAnaconda3 (3.6, 64-bit). Isso inclui o pacote PyTorch.
Para testar o novo interpretador do Python e o pacote PyTorch, insira o seguinte código no arquivo PyTorchTraining.py:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
A saída deve ser um tensor 5x3 aleatório semelhante ao apresentado abaixo.
Observação
Quer aprender mais? Visite o site oficial do PyTorch.
Carregar o conjunto de dados
Você vai usar a classe torchvision do PyTorch para carregar os dados.
A biblioteca Torchvision inclui vários conjuntos de dados populares, como Imagenet, CIFAR10, MNIST etc., arquiteturas de modelo e transformações de imagem comuns para a pesquisa visual computacional. Isso torna o carregamento de dados no Pytorch um processo bastante fácil.
CIFAR10
Vamos usar o conjunto de dados CIFAR10 para criar e treinar o modelo de classificação de imagem. O CIFAR10 é um conjunto de dados amplamente usado para pesquisa de machine learning. Ele consiste em 50 mil imagens de treinamento e 10 mil imagens de teste. Todas são de tamanho 3x32x32, o que significa imagens de cores de três canais com 32x32 pixels.
As imagens são divididas em 10 classes: 'avião' (0), 'automóvel' (1), 'pássaro' (2), 'gato' (3), 'veado' (4), 'cão' (5), 'sapo' (6), 'cavalo' (7), 'navio' (8), 'caminhão' (9).
Você vai seguir três etapas para carregar e ler o conjunto de dados CIFAR10 no PyTorch:
- Defina as transformações a serem aplicadas à imagem: para treinar o modelo, você precisa transformar as imagens em tensores de intervalo normalizado [-1,1].
- Crie uma instância do conjunto de dados disponível e carregue-o: para carregar os dados, você vai usar a classe
torch.utils.data.Dataset, uma classe abstrata para representar um conjunto de dados. O conjunto de dados será baixado localmente apenas na primeira vez que você executar o código. - Acesse os dados usando o DataLoader. Para obter o acesso aos dados e colocá-los na memória, você vai usar a classe
torch.utils.data.DataLoader. O DataLoader no Pytorch encapsula o conjunto de dados e fornece acesso aos dados subjacentes. Esse wrapper vai conter os lotes das imagens por tamanho de lote definido.
Repita as três etapas para os conjuntos de treinamento e de teste.
- Abra o
PyTorchTraining.py fileno Visual Studio e adicione o código a seguir. Isso lida com as três etapas acima para os conjuntos de dados de treinamento e de teste do CIFAR10.
from torchvision.datasets import CIFAR10
from torchvision.transforms import transforms
from torch.utils.data import DataLoader
# Loading and normalizing the data.
# Define transformations for the training and test sets
transformations = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
# CIFAR10 dataset consists of 50K training images. We define the batch size of 10 to load 5,000 batches of images.
batch_size = 10
number_of_labels = 10
# Create an instance for training.
# When we run this code for the first time, the CIFAR10 train dataset will be downloaded locally.
train_set =CIFAR10(root="./data",train=True,transform=transformations,download=True)
# Create a loader for the training set which will read the data within batch size and put into memory.
train_loader = DataLoader(train_set, batch_size=batch_size, shuffle=True, num_workers=0)
print("The number of images in a training set is: ", len(train_loader)*batch_size)
# Create an instance for testing, note that train is set to False.
# When we run this code for the first time, the CIFAR10 test dataset will be downloaded locally.
test_set = CIFAR10(root="./data", train=False, transform=transformations, download=True)
# Create a loader for the test set which will read the data within batch size and put into memory.
# Note that each shuffle is set to false for the test loader.
test_loader = DataLoader(test_set, batch_size=batch_size, shuffle=False, num_workers=0)
print("The number of images in a test set is: ", len(test_loader)*batch_size)
print("The number of batches per epoch is: ", len(train_loader))
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
Na primeira vez que você executar esse código, o conjunto de dados CIFAR10 será baixado no seu dispositivo.

Próximas etapas
Com os dados prontos para uso, é hora de treinar o modelo PyTorch