Управление ресурсами в базе данных SQL Azure
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
В статье представлены общие сведения об управлении ресурсами в базе данных SQL Azure. Узнайте о том, что происходит при достижении ограничений ресурсов, и какие есть механизмы управления ресурсами, которые используются для соблюдения этих ограничений.
Сведения о конкретных ограничениях ресурсов на ценовую категорию для отдельных баз данных см. в разделе .
- Ограничения ресурсов отдельной базы данных на основе DTU
- Ограничения ресурсов отдельной базы данных на основе виртуальных ядер
Ограничения ресурсов эластичного пула см. в следующих параметрах:
- Ограничения ресурсов эластичного пула на основе DTU
- Ограничения ресурсов эластичного пула на основе виртуальных ядер
Ограничения выделенного пула SQL в Azure Synapse Analytics см. в статье:
- Ограничения емкости
- Ограничения памяти и параллелизма.
Ограничения виртуальных ядер подписки на регион
Начиная с марта 2024 г. подписки имеют следующие ограничения виртуальных ядер для каждого региона для каждой подписки:
| Тип подписки | Ограничения виртуальных ядер по умолчанию |
|---|---|
| Соглашение Enterprise (EA) | 2000 |
| Бесплатные пробные версии | 10 |
| Корпорация Майкрософт для стартапов | 100 |
| MSDN/ MPN / Imagine / AzurePass / Azure для учащихся | 40 |
| Оплата по мере использования | 150 |
Рассмотрим следующий пример.
- Эти ограничения применимы к новым и существующим подпискам.
- Базы данных и эластичные пулы, подготовленные с помощью модели приобретения DTU, учитываются в квоте виртуальных ядер и наоборот. Каждое используемое виртуальное ядро считается эквивалентным 100 единиц DTU, потребляемых для квоты на уровне сервера.
- Ограничения по умолчанию включают как виртуальные ядра, настроенные для подготовленных вычислительных баз данных или эластичных пулов, так и максимальные виртуальные ядра, настроенные для бессерверных баз данных.
- Вы можете использовать вызов REST API для определения текущего использования виртуальных ядер для подписки.
- Чтобы запросить более высокую квоту виртуальных ядер, чем по умолчанию, отправьте новый запрос на поддержку в портал Azure. Дополнительные сведения см. в статье Запрос на увеличение квоты для базы данных SQL Azure.
Ограничения логического сервера
| Ресурс | Ограничение |
|---|---|
| Количество баз данных на один логический сервер | 5000 |
| Количество логических серверов по умолчанию на подписку в регионе | 250 |
| Максимальное количество логических серверов по умолчанию на подписку в регионе | 250 |
| Максимальное количество эластичных пулов на один логический сервер | ограничено числом DTU или виртуальных ядер Например, если каждый пул поддерживает 1000 DTU, тогда один сервер может поддерживать 54 пула. |
Внимание
По мере приближения количества баз данных к пороговому значению для логического сервера может произойти следующее:
- Увеличение задержки при выполнении запросов к
masterбазе данных. Сюда входят представления статистических данных использования ресурсов, такие какsys.resource_stats. - Увеличение задержки при управлении и отображении для точек наблюдения портала, включая перечисление баз данных на сервере.
Что происходит при достижении ограничения ресурсов?
Вычислительные ресурсы ЦП
Когда загрузка ЦП вычислений базы данных становится высокой, задержка запросов увеличивается, а запросы могут даже истекает. В этих условиях запросы могут быть помещены в очередь службой и предоставляются ресурсы для выполнения по мере того, как ресурсы становятся свободными.
Если вы наблюдаете высокую загрузку вычислительных ресурсов, к ним относятся следующие варианты:
- Увеличение объема вычислительных ресурсов базы данных или эластичного пула для предоставления базе данных дополнительных вычислительных ресурсов. См. разделы Масштабирование ресурсов отдельной базы данных и Масштабирование ресурсов эластичного пула.
- Оптимизация запросов для уменьшения использования ресурсов ЦП каждым запросом. Дополнительные сведения см. в разделе Настройка запросов и указания на них.
Хранилище
Если объем используемых данных достигает максимального предельного размера данных на уровне базы данных или на уровне эластичного пула, вставки и обновления, увеличивающие размер данных, завершаются ошибкой, а клиенты получают сообщение об ошибке. Инструкции SELECT и DELETE выполняются без изменений.
На уровнях служб "Премиум" и "Критически важный для бизнеса" клиенты также получают сообщение об ошибке, если совокупный объем хранилища, используемый данными, журналом транзакций и базой данных tempdb для одной базы данных или эластичного пула, превышает максимальный размер локального хранилища. Дополнительные сведения см. в разделе Управление местом для хранения.
Если вы наблюдаете высокую загрузку дискового пространства, возможны следующие варианты:
- Увеличьте максимальный размер данных для базы данных или эластичного пула либо вертикально увеличьте масштаб до цели служб с большим максимальным размером данных. См. разделы Масштабирование ресурсов отдельной базы данных и Масштабирование ресурсов эластичного пула.
- Если база данных находится в эластичном пуле, то в качестве альтернативы ее можно переместить за пределы пула, чтобы ее дисковое пространство не использовалось совместно с другими базами данных.
- Сжатие базы данных для освобождения неиспользуемого пространства. Дополнительные сведения см. в статье об управлении файловым пространством в Базе данных SQL Azure.
- В эластичных пулах сжатие базы данных обеспечивает больший объем хранилища для других баз данных в пуле.
- Проверьте, связан ли высокий уровень использования пространства с пиковым размером постоянного хранилища версий (PVS). PVS является частью каждой базы данных и используется для реализации Ускоренного восстановления баз данных. Сведения об определении текущего размера PVS см. в разделе об устранении неполадок PVS. Распространенной причиной увеличения размера PVS является транзакция, которая открыта в течение длительного времени (нескольких часов), что мешает выполнению очистки записи старых версий в PVS.
- Для баз данных и эластичных пулов в уровнях служб Premium и критически важный для бизнеса, которые используют большие объемы хранилища, может возникнуть ошибка вне места, даже если используемое пространство в базе данных или эластичном пуле превышает максимальный размер данных. Это может произойти, если
tempdbили файлы журнала транзакций используют большое количество хранилища по отношению к максимальному ограничению локального хранилища. Выполните отработку отказа базы данных или эластичного пула, чтобы сброситьtempdbдо исходного меньшего размера, или сожмите журнал транзакций, чтобы уменьшить потребление локального хранилища.
Сеансы, рабочие роли и запросы
Определения сеансов, рабочих ролей и запросов:
- Сеанс представляет собой процесс, подключенный к ядру СУБД.
- Запрос — логическое представление запроса или пакета. Запрос инициируется клиентом, подключенным к сеансу. С течением времени несколько запросов можно выдавать в одном сеансе.
- Рабочий поток, также известный как рабочая роль или поток, является логическим представлением потока операционной системы. Запрос может иметь много рабочих ролей при выполнении с параллельным планом выполнения запросов или одной рабочей роли при выполнении с помощью последовательного (однопоточного) плана выполнения. Рабочие роли также должны поддерживать и другие действия, помимо выполнения запросов: например, рабочая роль должна обрабатывать запрос на вход при подключении сеанса.
Дополнительные сведения об этих понятиях см. в статье Руководство по архитектуре потоков и задач.
Максимальное количество рабочих ролей определяется уровнем служб и размером вычислительных ресурсов. При достижении ограничения числа сеансов или рабочих ролей новые запросы отклоняются, а клиенты получают сообщение об ошибке. Хотя приложение может управлять числом подключений, число параллельных рабочих ролей зачастую существенно труднее оценивать и контролировать. Это особенно сильно проявляется в периоды пиковой нагрузки, когда достигаются ограничения ресурсов базы данных и рабочие роли накапливаются из-за увеличенной длительности выполнения запросов, крупных блокирующих цепочек или чрезмерного параллелизма запросов.
Примечание.
В первоначальном предложении для Базы данных SQL Azure поддерживались только запросы с одним потоком. В то время число запросов всегда было равнозначно числу рабочих ролей. Сообщение об ошибке 10928 в База данных SQL Azure содержит только слово The request limit for the database is *N* and has been reached для обратной совместимости. Фактически, достигнутое ограничение представляет собой число рабочих ролей.
Если параметр max degree of parallelism (MAXDOP) равен нулю или больше одного, число рабочих ролей может быть гораздо выше числа запросов, и ограничение может быть достигнуто гораздо раньше, чем когда MAXDOP равен одному.
- Дополнительные сведения об ошибке 10928 см. в разделе Ошибки управления ресурсами.
- Дополнительные сведения об исчерпании ограничений запросов см. в ошибках 10928 и 10936.
Вы можете снизить вероятность достижения ограничений на число рабочих ролей или сеансов следующим образом:
- Повышение уровня служб или объема вычислительных ресурсов базы данных или эластичного пула. См. разделы Масштабирование ресурсов отдельной базы данных и Масштабирование ресурсов эластичного пула.
- Оптимизация запросов для сокращения использования ресурсов, если число рабочих ролей увеличилось из-за состязания за вычислительные ресурсы. Дополнительные сведения см. в разделе Настройка запросов и указания на них.
- Оптимизация рабочей нагрузки запросов для сокращения числа повторов и длительности блокировки запросов. Дополнительные сведения см. в статье Изучение и устранение проблем блокировок в Azure SQL.
- Уменьшение значения параметра MAXDOP, если это возможно.
Сведения об ограничениях рабочих ролей и сеансов с учетом уровня служб и объема вычислительных ресурсов см. в следующих статьях:
- Ограничения ресурсов для отдельных баз данных с использованием модели приобретения виртуального ядра
- Ограничения ресурсов для эластичных пулов в рамках модели приобретения на основе виртуальных ядер
- Resource limits for single databases using the DTU purchasing model (Ограничения ресурсов для отдельных баз данных при использовании модели приобретения DTU)
- Ограничения ресурсов для эластичных пулов в модели приобретения на основе единиц DTU
Дополнительные сведения об устранении определенных ошибок, связанных с ограничениями сеанса и рабочих ролей, см. в разделе Ошибки управления ресурсами.
Внешние отношения
Число одновременных подключений к внешним конечным точкам, выполненных через sp_invoke_external_rest_endpoint , ограничено до 10 % рабочих потоков с жестким ограничением максимум 150 рабочих ролей.
Память
В отличие от других ресурсов (ЦП, рабочих ролей, хранилища), достижение предела памяти не негативно влияет на производительность запросов и не приводит к ошибкам и сбоям. Как подробно описано в руководстве по архитектуре управления памятью, ядро СУБД часто использует всю доступную память. Память используется преимущественно для кэширования данных, чтобы ускорить доступ к хранилищу. Таким образом, более высокий уровень использования памяти обычно повышает производительность запросов за счет более быстрых операций чтения из памяти, а не за счет медленных операций чтения из хранилища.
После запуска ядра СУБД, когда рабочая нагрузка начинает считывать данные из хранилища, ядро СУБД активно кэширует данные в памяти. После этого начального периода расширения обычно avg_memory_usage_percent отображаются и avg_instance_memory_percent столбцы в sys.dm_db_resource_stats, а sql_instance_memory_percent метрика Azure Monitor будет близка к 100 %, особенно для баз данных, которые не являются неактивными, и не полностью вписываются в память.
Примечание.
sql_instance_memory_percent Метрика отражает общее потребление памяти ядром СУБД. Эта метрика может не достигать 100 % даже при выполнении рабочих нагрузок высокой интенсивности. Это связано с тем, что небольшая часть доступной памяти зарезервирована для критически важных выделений памяти, отличных от кэша данных, таких как стеки потоков и исполняемые модули.
Помимо кэша данных, память используется в других компонентах ядра СУБД. При наличии спроса на память и всю доступную память используется кэшем данных, ядро СУБД уменьшает размер кэша данных, чтобы сделать память доступной для других компонентов, и динамически увеличивает кэш данных при выпуске других компонентов.
В редких случаях достаточно требуемая рабочая нагрузка может привести к нехватке памяти, что приводит к ошибкам вне памяти. Ошибки вне памяти могут возникать на любом уровне использования памяти от 0 до 100 %. Ошибки вне памяти чаще возникают при меньших размерах вычислительных ресурсов, которые имеют пропорционально меньшие ограничения памяти и (или) с рабочими нагрузками, использующими большую память для обработки запросов, например в плотных эластичных пулах.
Если вы получаете ошибки вне памяти, варианты устранения рисков включают следующее:
- Просмотрите сведения о состоянии нехватки памяти в статье о sys.dm_os_out_of_memory_events.
- Повышение уровня служб или объема вычислительных ресурсов базы данных или эластичного пула. См. разделы Масштабирование ресурсов отдельной базы данных и Масштабирование ресурсов эластичного пула.
- Оптимизация запросов и конфигурации для уменьшения использования памяти. В следующей таблице описаны распространенные решения.
| Решение | Description |
|---|---|
| Уменьшение размера временно предоставляемого буфера памяти | Дополнительные сведения о грантах памяти см. в записи блога о предоставлении памяти SQL Server. Распространенным решением для предотвращения временно предоставляемого буфера памяти чрезмерно большого размера является поддержка актуальности статистики. Это приводит к более точным оценкам потребления памяти подсистемой запросов, избегая больших объемов ресурсов памяти. По умолчанию в базах данных с уровнем совместимости 140 и более поздних версий ядро СУБД может автоматически настраивать размер предоставления памяти с помощью обратной связи о предоставлении памяти в режиме пакетной службы. Подобным образом, в базах данных, использующих уровень совместимости 150 и выше, ядро СУБД использует обратную связь о временно предоставляемом буфере памяти в строковом режиме для более распространенных запросов в строковом режиме. Эта встроенная функция помогает избежать ошибок без памяти из-за больших объемов памяти. |
| Сокращение размера кэша планов запросов | Ядро СУБД кэширует планы запросов в памяти, чтобы избежать компиляции плана запроса для каждого выполнения запроса. Чтобы избежать превышения кэша планов запросов, вызванного планами кэширования, которые используются только один раз, обязательно используйте параметризованные запросы и рассмотрите возможность включения OPTIMIZE_FOR_AD_HOC_WORKLOADS конфигурации уровня базы данных. |
| Сокращение размера памяти блокировки | Ядро СУБД использует память для блокировок. По возможности избегайте больших транзакций, которые могут получить большое количество блокировок и привести к большому потреблению памяти блокировки. |
Потребление ресурсов по рабочим нагрузкам пользователей и внутренним процессам
База данных SQL Azure требует вычислительных ресурсов для реализации основных функций службы, таких как высокий уровень доступности и аварийное восстановление, резервное копирование и восстановление базы данных, мониторинг, хранилище запросов, автоматическая настройка и т. д. Система выделяет ограниченную часть общих ресурсов для этих внутренних процессов с помощью механизмов управления ресурсами, что делает оставшуюся часть ресурсов доступными для рабочих нагрузок пользователей. Иногда, когда внутренние процессы не используют вычислительные ресурсы, система предоставляет к ним доступ пользовательским рабочим нагрузкам.
Общее использование ЦП и памяти пользовательскими рабочими нагрузками и внутренними процессами указывается в представлениях sys.dm_db_resource_stats и sys.resource_stats в столбцах avg_instance_cpu_percent и avg_instance_memory_percent. Эти данные также отображаются в метриках Azure Monitor sql_instance_cpu_percent и sql_instance_memory_percent для отдельных баз данных и эластичных пулов на уровне пула.
Примечание.
sql_instance_cpu_percent sql_instance_memory_percent Метрики Azure Monitor доступны с июля 2023 года. Они полностью эквивалентны ранее доступным sqlserver_process_core_percent и sqlserver_process_memory_percent метрикам соответственно. Последние две метрики остаются доступными, но будут удалены в будущем. Чтобы избежать прерывания мониторинга базы данных, не используйте старые метрики.
Эти метрики недоступны для баз данных с использованием целей службы Basic, S1 и S2. Те же данные доступны в следующих динамических административных представлениях.
Использование ЦП и памяти пользовательскими рабочими нагрузками в каждой базе данных указывается в представлениях sys.dm_db_resource_stats и sys.resource_stats в столбцах avg_cpu_percent и avg_memory_usage_percent. Для эластичных пулов потребление ресурсов уровня пула сообщается в представлении sys.elastic_pool_resource_stats (для исторических сценариев отчетности) и в sys.dm_elastic_pool_resource_stats для мониторинга в режиме реального времени. Показатель загрузки ЦП пользовательской рабочей нагрузкой также отображается в метрике Azure Monitor cpu_percent для отдельных баз данных и эластичных пулов на уровне пула.
Более подробную разбивку недавнего потребления ресурсов по пользовательским рабочим нагрузкам и внутренним процессам можно найти в представлениях sys.dm_resource_governor_resource_pools_history_ex и sys.dm_resource_governor_workload_groups_history_ex. Дополнительные сведения о пулах ресурсов и группах рабочих нагрузок, указанных в этих представлениях, см. в разделе Управление ресурсами. В этих представлениях содержатся сведения об использовании ресурсов пользовательскими рабочими нагрузками и конкретными внутренними процессами в связанных пулах ресурсов и группах рабочей нагрузки.
Совет
При мониторинге или устранении неполадок с производительностью рабочей нагрузки важно учитывать потребление ЦП пользователей (avg_cpu_percent, и cpu_percentобщее потребление ЦП по рабочим нагрузкам пользователей и внутренним процессам (avg_instance_cpu_percent,).sql_instance_cpu_percent Производительность может заметно повлиять, если любой из этих метрик находится в диапазоне от 70 до 100 %.
Потребление ЦП пользователей определяется в процентах по отношению к ограничению ЦП рабочей нагрузки пользователя в каждой цели службы. Аналогичным образом общее потребление ЦП определяется как процент в сторону ограничения ЦП для всех рабочих нагрузок. Поскольку два ограничения отличаются, пользователь и общее потребление ЦП измеряется по разным шкалам и не сравниваются напрямую друг с другом.
Если потребление ЦП пользователя достигает 100%, это означает, что рабочая нагрузка пользователя полностью использует емкость ЦП, доступную для нее в выбранной цели службы, даже если общее потребление ЦП остается ниже 100 %.
Когда общее потребление ЦП достигает диапазона 70–100%, можно увидеть увеличение пропускной способности рабочей нагрузки пользователей и увеличение задержки запросов, даже если потребление ЦП пользователя остается значительно ниже 100 %. Чаще всего это происходит при использовании минимальных целей обслуживания с умеренным выделением вычислительных ресурсов, но с относительно ресурсоемкими пользовательскими рабочими нагрузками, например в эластичных пулах с высокой плотностью. Такая ситуация также может возникать при использовании минимальных целей обслуживания, когда внутренним процессам временно требуются дополнительные ресурсы, например при создании новой реплики базы данных или резервной копии базы данных.
Аналогичным образом, когда потребление ЦП пользователя достигает диапазона 70–100 %, пропускная способность рабочей нагрузки пользователя будет увеличиваться, и задержка запросов увеличится, даже если общее потребление ЦП значительно ниже его предела.
Если потребление ЦП пользователя или общее потребление ЦП является высоким, варианты устранения рисков совпадают, как указано в разделе "Вычислительные ЦП", а также включают увеличение целевой нагрузки службы и (или) оптимизацию рабочей нагрузки пользователя.
Примечание.
Даже в полной простой базе данных или эластичном пуле общий объем ресурсов ЦП никогда не равен нулю из-за фоновых действий ядра СУБД. Он может колебаться в широком диапазоне в зависимости от конкретных фоновых действий, размера вычислений и предыдущей рабочей нагрузки пользователя.
Управление ресурсами
Чтобы применить ограничения ресурсов, База данных SQL Azure использует реализацию управления ресурсами, основанную на компоненте SQL Server Resource Governor, который изменен и расширен для запуска в облаке. В Базе данных SQL несколько пулов ресурсов и групп рабочей нагрузки с ограничениями ресурсов, заданными на уровнях пула и группы, формируют сбалансированию базу данных как услугу. Пользовательская рабочая нагрузка и внутренние рабочие нагрузки делятся на отдельные пулы ресурсов и группы рабочей нагрузки. Пользовательская рабочая нагрузка на первичной реплике и вторичной реплике для чтения, включая геореплики, классифицируется в пул ресурсов SloSharedPool1 и группы рабочих нагрузок UserPrimaryGroup.DBId[N], где [N] — это значение идентификатора базы данных. Кроме того, для различных внутренних рабочих нагрузок существует несколько пулов ресурсов и групп рабочей нагрузки.
Кроме использования Resource Governor для управления ресурсами в ядре СУБД, База данных SQL Azure применяет объекты заданий Windows для управления ресурсами на уровне процесса и Диспетчер ресурсов файлового сервера (FSRM) Windows для управления квотами на хранилище.
Управление ресурсами Базы данных SQL Azure носит иерархический характер. Целиком и полностью ограничения применяются на уровне ОС и на уровне тома хранилища с помощью механизмов управления ресурсами операционной системы и Resource Governor, затем — на уровне пула ресурсов с помощью Resource Governor, а затем — на уровне группы рабочей нагрузки с помощью Resource Governor. Ограничения управления ресурсами, действующие для текущей базы данных или эластичного пула, отображаются в представлении sys.dm_user_db_resource_governance.
Управление операциями ввода-вывода данных
Управление операциями ввода-вывода данных — это процесс в Базе данных SQL Azure, который позволяет ограничивать физические операции чтения и записи ввода-вывода для файлов данных базы данных. Ограничения операций ввода-вывода в секунду устанавливаются для каждого уровня обслуживания, чтобы свести к минимуму эффект "шумного соседа", обеспечить справедливость распределения ресурсов в мультитенантной службе и оставаться в пределах возможностей базового оборудования и хранилища.
Для отдельных баз данных ограничения групп рабочих нагрузок применяются во всем операциям ввода-вывода хранилища для базы данных. Для эластичных пулов ограничения групп рабочих нагрузок применяются к каждой базе данных в пуле. Кроме того, ограничение пула ресурсов дополнительно применяется к совокупным операциям ввода-вывода эластичного пула. В tempdbрежиме ввода-вывода применяется ограничения группы рабочих нагрузок, за исключением уровня служб "Базовый", "Стандартный" и "Общего назначения", где применяются более высокие tempdb ограничения ввода-вывода. Как правило, ограничения пула ресурсов могут не достичь рабочей нагрузки для базы данных (отдельной или пулной), так как ограничения группы рабочих нагрузок ниже ограничений пула ресурсов и ограничения операций ввода-вывода в секунду или пропускной способности раньше. Однако ограничения пула можно достичь с помощью объединенной рабочей нагрузки для нескольких баз данных в одном пуле.
Например, если запрос создает 1000 операций ввода-вывода без управления ресурсами ввода-вывода, но максимальный предел операций ввода-вывода рабочей нагрузки равен 900 операций ввода-вывода в секунду, запрос не может создать более 900 операций ввода-вывода. Однако если максимальное количество операций ввода-вывода в пуле ресурсов равно 1500 операций ввода-вывода, а общее количество операций ввода-вывода из всех групп рабочих нагрузок, связанных с пулом ресурсов, превышает 1500 операций ввода-вывода в секунду, то число операций ввода-вывода одного запроса может быть сокращено ниже ограничения в 900 операций ввода-вывода.
Максимальные значения операций ввода-вывода в секунду и пропускной способности, возвращаемые представлением sys.dm_user_db_resource_governance, действуют как ограничения, а не как гарантии. Более того, управление ресурсами не гарантирует какую-либо конкретную задержку хранилища. Максимально достижимые показатели задержки, количества операций ввода-вывода в секунду и пропускной способности для указанной пользовательской рабочей нагрузки зависят не только от ограничений управления ресурсами ввода-вывода, но и от используемого сочетания размеров операций ввода-вывода, а также возможностей базового хранилища. База данных SQL использует операции ввода-вывода, которые отличаются размером от 512 байт до 4 МБ. В целях применения ограничений операций ввода-вывода все операции ввода-вывода учитываются независимо от его размера, за исключением баз данных с файлами данных в служба хранилища Azure. В этом случае операции ввода-вывода с размером свыше 256 КБ считаются как несколько операций ввода-вывода по 256 КБ, что соответствует требованиям к операциям ввода-вывода службы хранилища Azure.
Для баз данных уровня "Базовый", "Стандартный" и "Общее назначение", которые используют файлы данных в служба хранилища Azure, значение может не быть достижимым, primary_group_max_io если база данных не имеет достаточно файлов данных, чтобы обеспечить это число операций ввода-вывода в секунду или если данные не распределяются равномерно между файлами, или если уровень производительности базовых БОЛЬШИХ двоичных объектов ограничивает количество операций ввода-вывода в секунду или пропускную способность ниже ограничений управления ресурсами. Аналогичным образом, при работе с небольшими операциями ввода-вывода журнала, создаваемыми частыми фиксациями транзакций, primary_max_log_rate значение может не достичь рабочей нагрузки из-за ограничения операций ввода-вывода в базовый служба хранилища Azure BLOB-объект. В база данных с хранилищем Azure класса Premium База данных SQL Azure использует достаточно большие BLOB-объекты хранилища для получения необходимого количества операций ввода-вывода в секунду или нужной емкости пропускной способности независимо от размера базы данных. Для больших баз данных создается несколько файлов данных в целях увеличения общего количества операций ввода-вывода в секунду или емкости пропускной способности.
Такие значения использования ресурсов, как avg_data_io_percent и avg_log_write_percent, сообщаемые в sys.dm_db_resource_stats, sys.resource_stats, sys.dm_elastic_pool_resource_stats и sys.elastic_pool_resource_stats представлениях, вычисляются в процентах от максимальных ограничений управления ресурсами. Таким образом, если количество операций ввода-вывода в секунду и емкость пропускной способности ограничиваются факторами, отличными от управления ресурсами, то при увеличении рабочей нагрузки можно наблюдать снижение количества операций ввода-вывода в секунду и емкости пропускной способности, даже если показатель использования ресурса остается ниже 100 %.
Для отслеживания операций чтения и записи операций ввода-вывода в секунду, пропускной способности и задержки для каждого файла базы данных используйте функцию sys.dm_io_virtual_file_stats(). Эта функция отображает все операции ввода-вывода в базе данных, включая фоновые операции ввода-вывода, которые не учитываются avg_data_io_percent, но используют операции ввода-вывода и пропускную способность базового хранилища, а также могут повлиять на наблюдаемую задержку хранения. Функция сообщает дополнительную задержку, которая может быть представлена управлением ресурсами ввода-вывода для операций чтения и записи в io_stall_queued_read_ms столбцах соответственно io_stall_queued_write_ms .
Управление скоростью журнала транзакций
Управление скоростью журнала транзакций — это процесс в Базе данных SQL Azure, который используется для ограничения высоких скоростей приема для таких рабочих нагрузок, как массовая вставка, SELECT INTO и построение индекса. Эти ограничения отслеживаются и применяются на уровне подсекунда до скорости создания записей журнала, что ограничивает пропускную способность независимо от количества операций ввода-вывода для файлов данных. Скорость создания журнала транзакций в настоящее время линейно масштабируется до точки, которая зависит от оборудования и уровня обслуживания.
Тарифы журналов устанавливаются таким образом, чтобы их можно было достичь и поддерживать в различных сценариях, в то время как общая система может поддерживать ее функциональные возможности с минимальным воздействием на нагрузку пользователя. Управление скоростью создания журнала гарантирует, что резервные копии журналов транзакций остаются в рамках опубликованных соглашений SLA о возможности восстановления. Это управление также предотвращает чрезмерную невыполненную работу во вторичных репликах, которые в противном случае могут привести к более длительному времени простоя во время отработки отказа.
Фактические физические IOs для файлов журнала транзакций не регулируются или ограничены. По мере создания записей журнала каждая операция анализируется и оценивается на предмет необходимости ее задержки для поддержки максимальной желаемой скорости ведения журнала (МБ/с). Задержки не добавляются, когда записи журнала заносятся в хранилище, скорее при создании скорости ведения журнала применяется управление скоростью создания журнала.
Фактические показатели создания журналов, введенные во время выполнения, также влияют на механизмы обратной связи, временно уменьшая допустимые частоты журналов, чтобы система может стабилизировать. Временно снизить общие ограничения системы можно с помощью управления пространством файлов журнала, которое предотвращает возникновение ситуаций с нехваткой места в журнале, и механизмов репликации данных.
Формирование трафика регулятора скорости создания журнала осуществляется с помощью следующих типов ожидания (которые доступны в представлениях sys.dm_exec_requests и sys.dm_os_wait_stats):
| Тип ожидания | Примечания. |
|---|---|
LOG_RATE_GOVERNOR |
Ограничение базы данных |
POOL_LOG_RATE_GOVERNOR |
Ограничение пула |
INSTANCE_LOG_RATE_GOVERNOR |
Ограничение уровня экземпляра |
HADR_THROTTLE_LOG_RATE_SEND_RECV_QUEUE_SIZE |
Управление обратной связью, физическая репликация группы доступности в категории "Премиум" или "Критически важный для бизнеса" не соответствует потребностям |
HADR_THROTTLE_LOG_RATE_LOG_SIZE |
Управление обратной связью, ограничивающее скорости во избежание возникновения условия нехватки пространства журнала |
HADR_THROTTLE_LOG_RATE_MISMATCHED_SLO |
Управление обратной связью с георепликацией, ограничивающее скорость ведения журнала во избежание высокой задержки данных и недоступности вторичных реплик с георепликацией |
Если вы столкнулись с ограничением скорости создания журнала, которое препятствует желаемой масштабируемости, рассмотрите следующие варианты устранения проблемы.
- Выполните масштабирование до более высокого уровня обслуживания, чтобы получить максимальную скорость создания журнала для уровня обслуживания, или переключитесь на другой уровень обслуживания. Уровень служб "Гипермасштабирование " предоставляет скорость 100 МБ/с для каждой базы данных и 125 МБ/с на эластичном пуле независимо от выбранного уровня обслуживания. Скорость создания журналов составляет 150 МБ/с, доступна как предварительная версия функции. Дополнительные сведения и согласие на 150 МБ/с см . в блоге: усовершенствования гипермасштабирования за ноябрь 2024 г.
- Если загружаемые данные являются временными, например промежуточные данные в процессе ETL, их можно загрузить в базу данных
tempdb(с минимальным ведением журнала). - Для аналитических сценариев загрузите данные в кластерную таблицу columnstore или таблицу с индексами, в которой используется сжатие данных. Требуемая скорость создания журнала будет сокращена. Этот метод увеличивает загрузку ЦП и применяется только к наборам данных, которые используют преимущества кластеризованных индексов columnstore или сжатия данных.
Управление местом для хранения
В уровнях служб "Премиум" и критически важный для бизнеса данные клиента, включая файлы данных, файлы журнала транзакций и tempdb файлы, хранятся в локальном хранилище SSD компьютера с базой данных или эластичным пулом. Локальное хранилище на основе SSD обеспечивает большое количество операций ввода-вывода в секунду и высокую пропускную способность, а также низкие задержки операций ввода-вывода. Помимо хранения данных клиентов, локальное хранилище используется для операционной системы, программного обеспечения управления, данных и журналов мониторинга, а также других файлов, необходимых для работы системы.
Размер локального хранилища ограничен и зависит от аппаратных возможностей, которые определяют максимальный размер локального хранилища, либо локальное хранилище резервируется для данных клиентов. Это ограничение устанавливается, чтобы максимально увеличить объем хранилища данных клиентов, обеспечивая безопасную и надежную работу системы. Чтобы узнать значение максимального размера локального хранилища для каждой цели служб, изучите документацию по ограничениям ресурсов для отдельных баз данных и эластичных пулов.
Кроме того, узнать это значение и объем локального хранилища, используемого заданной базой данных или эластичным пулом, можно с помощью следующего запроса:
SELECT server_name, database_name, slo_name, user_data_directory_space_quota_mb, user_data_directory_space_usage_mb
FROM sys.dm_user_db_resource_governance
WHERE database_id = DB_ID();
| Столбец | Description |
|---|---|
server_name |
Имя логического сервера |
database_name |
Имя базы данных |
slo_name |
Имя цели служб, включая поколение оборудования |
user_data_directory_space_quota_mb |
Максимальный размер локального хранилища (МБ) |
user_data_directory_space_usage_mb |
Текущий объем локального хранилища (МБ), используемый файлами данных, файлами журналов транзакций и файлами tempdb. Обновляется каждые пять минут. |
Этот запрос должен выполняться в пользовательской базе данных, а не в master базе данных. Для эластичных пулов запрос может выполняться в любой базе данных в пуле. Полученные значения применяются ко всему пулу.
Внимание
На уровнях служб "Премиум" и "Критически важный для бизнеса", если рабочая нагрузка пытается увеличить совокупный объем локального хранилища, используемый файлами данных, файлами журналов транзакций и файлами tempdb, сверх максимального размера локального хранилища, происходит ошибка нехватки памяти. Это произойдет, даже если используемое пространство в файле базы данных не достигло максимального размера файла.
Локальное хранилище SSD также используется базами данных на уровнях служб, отличных от уровня "Премиум" и критически важный для бизнеса для tempdb базы данных и кэша RBPEX с гипермасштабированием. По мере создания и удаления баз данных, а также увеличения или уменьшения их размера, общее потребление локального хранилища на компьютере с течением времени меняется. Если система обнаруживает, что доступное локальное хранилище на компьютере низко, а база данных или эластичные пулы подвержены риску нехватки места, она перемещает базу данных или эластичные пулы на другой компьютер с достаточным локальным хранилищем.
Такое перемещение происходит по сети и аналогично операции масштабирования базы данных. Оно оказывает схожее воздействие, включая кратковременную (несколько секунд) отработку отказа в конце операции. Эта отработка отказа завершает открытые подключения и откатывает транзакции, потенциально влияя на приложения, использующие базу данных в то время.
Так как все данные копируются в локальные тома хранилища на разных компьютерах, перемещение больших баз данных в уровнях служб "Премиум" и критически важный для бизнеса может потребовать значительного времени. Если в течение этого времени происходит быстрое увеличение объема локального пространства, используемого базой данных, эластичным пулом либо базой данных tempdb, возрастает риск нехватки пространства. Система инициирует сбалансированное перемещение базы данных, чтобы минимизировать ошибки нехватки пространства и избежать ненужных отработок отказа.
tempdb Размеры
Границы размера tempdb в Базе данных SQL Azure зависят от модели приобретения и развертывания.
Чтобы узнать больше, просмотрите границы размера tempdb для следующих компонентов:
- модель приобретения на основе виртуальных ядер: отдельные базы данных, базы данных в пуле;
- модель приобретения на основе DTU: отдельные базы данных, базы данных в пуле.
Доступное ранее оборудование
В этом разделе содержатся сведения о доступном ранее оборудовании.
- Оборудование 4-го поколения было прекращено и недоступно для подготовки, масштабирования или уменьшения масштабирования. Перенос базы данных в поддерживаемое поколение оборудования для более широкого диапазона масштабируемости виртуальных ядер и хранилища, ускорения сети, оптимальной производительности операций ввода-вывода и минимальной задержки. Дополнительные сведения см. в статье о завершении поддержки оборудования 4-го поколения на База данных SQL Azure.
Обозреватель Azure Resource Graph можно использовать для идентификации всех База данных SQL Azure ресурсов, которые в настоящее время используют оборудование 4-го поколения, или проверить оборудование, используемое ресурсами для определенного логического сервера в портал Azure.
Чтобы просмотреть результаты в обозревателе ресурсов Azure, необходимо иметь по крайней мере read разрешения на объект или группу объектов Azure.
Чтобы использовать обозреватель resource Graph для идентификации ресурсов SQL Azure, которые по-прежнему используют оборудование 4-го поколения, выполните следующие действия.
Переход на портал Azure.
Resource graphНайдите в поле поиска и выберите службу обозревателя ресурсов из результатов поиска.В окне запроса введите следующий запрос и выберите команду "Выполнить запрос".
resources | where type contains ('microsoft.sql/servers') | where sku['family'] == "Gen4"На панели результатов отображаются все развернутые в настоящее время ресурсы в Azure, использующие оборудование 4-го поколения.
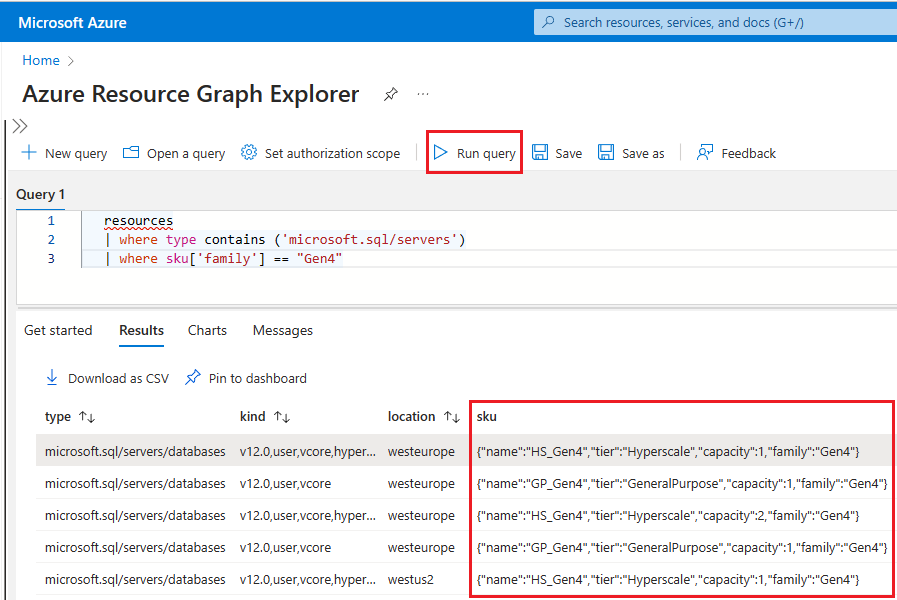
Чтобы проверить оборудование, используемое ресурсами для определенного логического сервера в Azure, выполните следующие действия.
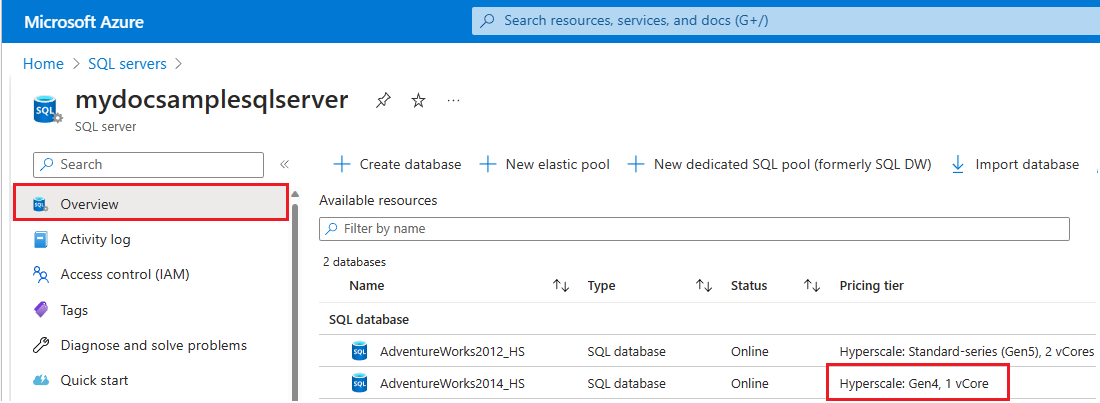
- Переход на портал Azure.
SQL serversНайдите в поле поиска и выберите серверы SQL из результатов поиска, чтобы открыть страницу серверов SQL и просмотреть все серверы для выбранных подписок.- Выберите нужный сервер, чтобы открыть страницу обзора сервера.
- Прокрутите вниз до доступных ресурсов и проверьте столбец ценовой категории для ресурсов, использующих оборудование 4-го поколения.
Чтобы перенести ресурсы на оборудование стандартной серии, ознакомьтесь с разделом "Изменение оборудования".
Связанный контент
- Сведения об общих ограничениях Azure см. в разделе Подписка Azure, границы, квоты и ограничения службы.
- Сведения о DTU и eDTU см. в разделе Общие сведения об обычных единицах передачи данных (DTU) и единицах передачи данных в эластичной базе данных (eDTU).
- Сведения о границах размера
tempdbсм. в статьях об отдельных базах данных с моделью приобретения на основе виртуальных ядер, базах данных в пуле с моделью приобретения на основе виртуальных ядер, отдельных базах данных с моделью приобретения на основе DTU и базах данных в пуле с моделью приобретения на основе DTU.