Уровень бессерверных вычислений для Базы данных SQL Azure
Применимо к:![]() База данных SQL Azure
База данных SQL Azure
Бессерверный — это уровень вычислений для отдельных баз данных в База данных SQL Azure, который автоматически масштабирует вычисления на основе спроса на рабочую нагрузку и счета за объем вычислительных ресурсов, используемых в секунду. Уровень бессерверных вычислений также автоматически приостанавливает базы данных в периоды отсутствия активности, когда оплачивается только хранилище, и автоматически возобновляет работу баз данных, когда активность восстанавливается. Уровень бессерверных вычислений доступен на уровне служб общего назначения и на уровне служб "Гипермасштабирование ".
Примечание.
Автоматическое приостановка и автоматическое возобновление в настоящее время поддерживается только на уровне служб общего назначения.
Обзор
Диапазон автомасштабирования вычислений и задержка автоматической приостановки являются важными параметрами для бессерверного уровня вычислений. Конфигурация этих параметров определяет производительность базы данных и стоимость вычислений.
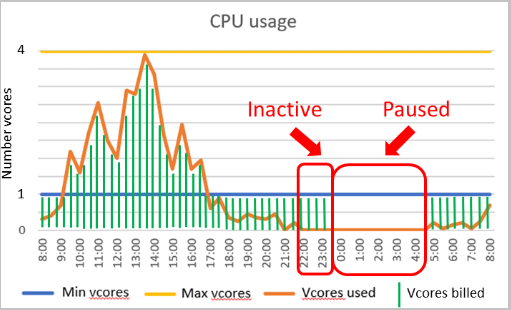
Настройка производительности
- минимальное число виртуальных ядер и максимальное число виртуальных ядер — это настраиваемые параметры, которые определяют диапазон доступных вычислений для базы данных. Ограничения памяти и операций ввода-вывода пропорциональны указанному диапазону виртуальных ядер.
- Задержка автоматической приостановки — это настраиваемый параметр, определяющий период времени, в течение которого база данных должна быть неактивной, прежде чем она будет автоматически приостановлена. Работа базы данных возобновится автоматически при следующем входе или другом действии. Кроме того, автоматическую приостановку можно отключить.
Себестоимость
- Стоимость пользования бессерверной базой данных включает плату за вычисления и хранение.
- При использовании вычислений между минимальными и максимальными ограничениями затраты на вычисления основаны на виртуальных ядрах и используемой памяти.
- Если использование вычислений ниже минимальных ограничений, затраты на вычисления основаны на минимальных виртуальных ядрах и минимальной памяти.
- При приостановке базы данных стоимость вычислений будет равна нулю, вы оплачиваете только затраты на хранение.
- Стоимость ресурсов хранения определяется так же, как и на уровне подготовленных вычислительных ресурсов.
Дополнительные сведения о затратах см. в разделе Выставление счетов.
Сценарии
Бессерверные вычисления — это рентабельное и оптимизированное для высокой производительности решение для отдельных баз данных с нестабильным и непредсказуемым использованием, для которых допустима некоторая задержка при подготовке вычислительных ресурсов после периодов простоя. В отличие от этого, подготовленная категория вычислений оптимизирована для повышения производительности отдельных баз данных или нескольких баз данных в эластичных пулах с более высоким средним использованием, которые не могут позволить себе задержку при прогревание вычислений.
Оптимальные сценарии для бессерверных вычислений
- Отдельные базы данных с нестабильным и непредсказуемым использованием с периодами бездействия и более низким средним использованием вычислительных ресурсов.
- Отдельные базы данных на уровне подготовленных вычислений, которые часто масштабируются повторно, и клиенты, которые хотят делегировать повторное масштабирование вычислительных ресурсов службе.
- Новые отдельные базы данных без журнала использования, в которых вычисление размера сложно или невозможно оценить перед развертыванием в База данных SQL Azure.
Оптимальные сценарии для подготовленных вычислений
- Отдельные базы данных с более равномерным, прогнозируемым использованием ресурсов и увеличенным средним объемом использования вычислительных ресурсов в долгосрочной перспективе.
- Базы данных, для которых недопустимо снижение производительности из-за частого ограничения ресурсов памяти или задержек автоматического возобновления работы из приостановленного состояния.
- Несколько баз данных с непостоянным и непрогнозируемым использованием, которые можно объединить в эластичные пулы для оптимизации соотношения затрат и производительности.
Сравнение уровней вычислений
В следующей таблице перечислены различия между уровнями бессерверных вычислений и подготовленных вычислений:
| Бессерверные вычисления | Подготовленные вычисления | |
|---|---|---|
| Сценарий использования баз данных | Нерегулярный и плохо прогнозируемый объем использования с более низким средним объемом использования ресурсов в долгосрочной перспективе. | Более равномерное использование ресурсов, более высокий средний объем использования ресурсов в долгосрочной перспективе или множество баз данных, использующих эластичные пулы. |
| Затраты на управление производительностью | Lower | Выше |
| Масштабирование вычислительных ресурсов | Автоматически | Руководство |
| Скорость включения вычислительных ресурсов | Низкая после периодов бездействия | Интерпретация |
| Тарификация | посекундно. | В час |
Модель приобретения и уровень служб
В следующей таблице описана бессерверная поддержка на основе модели приобретения, уровней служб и оборудования:
| Категория | Поддерживается | Не поддерживаются |
|---|---|---|
| Модель приобретения | Виртуальные ядра | DTU |
| Уровень служб | Общего назначения Гипермасштабирование |
Критически важный для бизнеса |
| Оборудование | Серия Standard (5-е поколение) | Все другое оборудование |
Автомасштабирование
Скорость масштабирования
Бессерверные базы данных выполняются на компьютере с достаточной емкостью для удовлетворения спроса на ресурсы без прерывания для любого объема вычислительных ресурсов, запрошенного в пределах максимального значения виртуальных ядер. В некоторых случаях автоматически выполняется балансировка нагрузки, если компьютер не может удовлетворить потребность в ресурсах в течение нескольких минут. Например, если спрос на ресурсы равен 4 виртуальным ядрам, но доступны только 2 виртуальных ядра, то до предоставления 4 виртуальных ядер может занять до нескольких минут. База данных остается доступной по сети во время балансировки нагрузки, кроме непродолжительного периода в конце операции, когда подключение прерывается.
Управление памятью
В уровнях служб общего назначения и гипермасштабирования память для бессерверных баз данных часто освобождается, чем для подготовленных вычислительных баз данных. Это важно для контроля над затратами при бессерверных вычислениях и может влиять на производительность.
Освобождение кэша
В отличие от подготовленных вычислительных баз данных память из кэша SQL освобождается при использовании бессерверной базы данных при низком уровне использования ЦП и активного кэша.
- Использование активного кэша считается низким, если общий размер последних использованных записей кэша ниже порогового значения в течение определенного периода времени.
- При активации освобождения кэша целевой размер кэша постепенно уменьшается до доли от прошлого размера. Освобождение продолжается только в том случае, если уровень использования остается низким.
- В случае освобождения кэша политика выбора записей в кэше для удаления остается такой же, как и политика выбора для подготовленных вычислительных баз данных с интенсивным использованием ресурсов памяти.
- Размер кэша никогда не уменьшается ниже минимального ограничения памяти, как определено минимальными виртуальными ядрами.
В бессерверных и подготовленных вычислительных базах данных записи кэша можно вытеснить, если используется все доступные памяти.
При низком уровне использования ЦП уровень использования активного кэша может оставаться высоким в зависимости от шаблона использования и функции предотвращения освобождения памяти. Кроме того, после прекращения действий пользователя и до освобождения памяти могут возникать другие задержки из-за периодических фоновых процессов, реагирующих на предыдущие действия пользователя. Например, при выполнении операций удаления и заданий по очистке хранилища запросов создаются фантомные записи, которые помечаются для удаления, но физически не удаляются до тех пор, пока не будет запущен процесс очистки фантомных записей, Очистка призрака может включать чтение страниц данных в кэш.
Расконсервация кэша
Кэш памяти SQL растет по мере получения данных с диска таким же образом и с той же скоростью, что и для подготовленных баз данных. Если база данных занята, кэш может увеличиваться без ограничений, пока есть доступная память.
Управление кэшем дисков
На уровне служб "Гипермасштабирование" для бессерверных и подготовленных уровней вычислений каждая реплика вычислений использует кэш отказоустойчивого буферного пула (RBPEX), в котором хранятся страницы данных на локальном SSD для повышения производительности операций ввода-вывода. Однако в бессерверном уровне вычислений для гипермасштабирования кэш RBPEX для каждой реплики вычислений автоматически увеличивается и уменьшается в ответ на увеличение и снижение спроса на рабочую нагрузку. Максимальный размер кэша RBPEX может увеличиваться в три раза больше памяти, настроенной для базы данных. Дополнительные сведения о максимальных ограничениях на масштабирование памяти и RBPEX в бессерверном режиме см . в бессерверных ограничениях ресурсов гипермасштабирования.
Автоматическое приостановка и автоматическое возобновление
В настоящее время бессерверная автоматическая приостановка и автоматическое возобновление поддерживаются только на уровне общего назначения.
Автоматическая приостановка
Автоматическое приостановка активируется, если во время задержки автоматической приостановки выполняются все следующие условия:
- Число сеансов — 0
- Ресурсы ЦП — 0 (для пользовательской рабочей нагрузки, выполняемой в пуле ресурсов пользователя).
При необходимости автоматическую приостановку можно отключить.
Следующие функции не поддерживают автоматическую приостановку, но поддерживают автоматическое масштабирование. Если используются какие-либо из следующих функций, автоматическое приостановка должна быть отключена, а база данных остается в сети независимо от длительности бездействия базы данных:
- Георепликация (активные группы георепликации и отработки отказа).
- Долгосрочное хранение резервных копий (LTR).
- База данных синхронизации, используемая в синхронизации данных SQL. В отличие от баз данных синхронизации базы данных концентратора, а также рядовые базы данных поддерживают автоматическую приостановку.
- Псевдоним DNS, созданный для логического сервера, содержащего бессерверную базу данных.
- Эластичные задания, автоматическая приостановка бессерверной базы данных не поддерживается в качестве базы данных заданий. Бессерверные базы данных, предназначенные для заданий эластичных баз данных, поддерживают автоматическое приостановку. Подключения заданий возобновляют базу данных.
Автоматическое приостановка временно предотвращается во время развертывания некоторых обновлений службы, для которых требуется, чтобы база данных была в сети. В таких случаях после завершения обновления службы автоматическая приостановка снова становится доступной.
Автоматическая приостановка устранения неполадок
Если включена автоматическая приостановка и функции, которые блокируют автоматическое приостановку, не используются, но база данных не приостанавливается после периода задержки, приложение или сеансы пользователей могут препятствовать автоматическому приостановке.
Чтобы узнать, подключены ли сейчас к базе данных какие-либо приложения или сеансы пользователей, подключитесь к базе данных с помощью любого клиентского средства и выполните следующий запрос.
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Совет
После выполнения запроса обязательно разорвите соединение с базой данных. В противном случае открытый сеанс, используемый запросом, не позволит выполнить автоматическую приостановку.
- Если результирующий набор не является пустым, он указывает, что в настоящее время существуют сеансы, которые препятствуют автоматическому приостановке.
- Если результирующий набор пуст, то сеансы все равно могли быть открыты (возможно, в течение короткого промежутка времени) в какой-то момент периода задержки автоматической приостановки. Чтобы проверить действие в течение периода задержки, можно использовать аудит SQL Azure и проверить данные аудита в течение соответствующего периода.
Внимание
Наличие открытых сеансов как при одновременном использовании ЦП в пуле ресурсов пользователя, так и без такового является самой распространенной причиной, по которой автоматическая приостановка бессерверной базы данных не выполняется надлежащим образом.
Автоматическое возобновление
Автоматическое возобновление выполняется, если в любой момент времени соблюдается какое-либо из следующих условий:
| Функция | Триггер автоматического возобновления |
|---|---|
| Аутентификация и авторизация | Вход |
| Обнаружение угроз | Включение и отключение параметров обнаружения угроз на уровне базы данных или сервера. Изменение параметров обнаружения угроз на уровне базы данных или сервера. |
| Обнаружение и классификация данных | Добавление, изменение, удаление или просмотр меток конфиденциальности. |
| Аудит | Просмотр записей аудита. Обновление или просмотр политик аудита. |
| Маскирование данных | Добавление, изменение, удаление или просмотр правил маскирования данных. |
| Прозрачное шифрование данных | Просмотр состояния или статуса прозрачного шифрования данных |
| Оценка уязвимостей | Спонтанное и периодическое сканирование, если включено |
| Запросы к хранилищу данных (производительность) | Изменение или просмотр параметров хранилища запросов |
| Рекомендации по повышению производительности | Просмотр или применение рекомендаций по производительности |
| Автоматическая настройка | Применение и проверка рекомендаций по автоматической настройке, включая автоматическое индексирование |
| Копирование базы данных | Создание базы данных как копии. Экспорт в BACPAC-файл. |
| Синхронизация данных SQL | Синхронизация между центральной и рядовыми базами данных, которая запускается по настраиваемому расписанию или вручную. |
| Изменение некоторых метаданных базы данных | Добавление новых тегов базы данных. Изменение максимального количества виртуальных ядер, минимальных виртуальных ядер или автоматической приостановки задержки. |
| SQL Server Management Studio (SSMS) | При использовании версий SSMS до версии 18.1 и открытии нового окна запроса для любой базы данных на сервере возобновляется автоматически приостановленная база данных на том же сервере. При использовании SSMS версии 18.1 или выше с отключенной функцией IntelliSense такое поведение недоступно. |
Мониторинг, управление или выполнение любых вышеперечисленных операций другими решениями запускает автоматическое возобновление. Автоматическое возобновление запускается также при развертывании некоторых обновлений служб, которым требуется, чтобы база данных была подключенной.
Подключение
Если бессерверная база данных приостановлена, первая попытка подключения возобновляет базу данных и возвращает ошибку, указывающую, что база данных недоступна с кодом ошибки 40613. После возобновления работы базы данных можно получить имя входа, чтобы установить подключение. Клиенты базы данных после рекомендаций по логике повторных попыток подключения не должны быть изменены . Параметры и рекомендации по логике повторных попыток подключения см. в следующей статье:
- Логика повторных попыток подключения в SqlClient
- Логика повторных попыток подключения в База данных SQL с помощью Entity Framework Core
- Логика повторных попыток подключения в База данных SQL с помощью Entity Framework 6
- Логика повторных попыток подключения в База данных SQL с помощью ADO.NET
Задержка
Задержка для автоматического возобновления и автоматической приостановки бессерверной базы данных обычно составляет примерно 1 минуту для автоматического возобновления и 1–10 минут для автоматической приостановки после окончания периода задержки при автоматической приостановке.
Прозрачное шифрование данных, управляемое клиентом (BYOK)
Удаление ключей или отзыв
Если используется управляемое клиентов прозрачное шифрование данных (BYOK) и бессерверная база данных автоматически приостанавливается при удалении или отзыве ключа, база данных остается в состоянии автоматической приостановки. В этом случае после возобновления работы базы данных она становится недоступной в течение примерно 10 минут. Как только база данных становится недоступной, процедуру восстановления можно выполнить так же, как для подготовленных вычислительных баз данных. Если бессерверная база данных в сети, когда происходит удаление или отзыв ключа, база данных также становится недоступной в течение примерно 10 минут — так же, как в случае с подготовленными вычислительными базами данных.
Смена ключей
Если используется прозрачное шифрование данных с управлением клиентом (BYOK) и автоматическое приостановка без сервера, база данных автоматически возобновляется при смене ключей и последующей автоматической приостановке при выполнении условий автоматической приостановки.
Создание бессерверной базы данных
Создание новой базы данных или перемещение существующей базы данных на уровень бессерверных вычислений выполняется аналогично созданию новой базы данных на уровне подготовленных вычислений. Этот процесс включает два этапа:
Определение цели службы. Цель службы определяет уровень служб, конфигурацию оборудования и максимальные виртуальные ядра. Сведения о параметрах цели обслуживания см. в статье ограничения для бессерверных ресурсов
При необходимости укажите минимальные виртуальные ядра и автоматическую приостановку задержки, чтобы изменить значения по умолчанию. В таблице ниже показаны доступные значения для этих параметров.
Параметр Варианты значений Default value Минимальное количество виртуальных ядер Зависит от настроенных максимальных виртуальных ядер. См . ограничения ресурсов. 0,5 виртуальных ядра Задержка автоматической приостановки Минимум: 15 минут
Максимум: 10 080 минут (7 дней)
Добавочные значения: 1 минуту
Отключение автоматической приостановки: -160 минут
В следующих примерах создается новая база данных на уровне бессерверных вычислений.
Использование портала Azure
С помощью PowerShell
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера PowerShell:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Использование Azure CLI
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера Azure CLI:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Использование Transact-SQL (T-SQL)
При использовании T-SQL для создания новой бессерверной базы данных значения по умолчанию применяются для минимальных виртуальных ядер и автоматической приостановки задержки. Их значения можно изменить с портал Azure или с помощью API, включая PowerShell, Azure CLI и REST.
Дополнительные сведения см. в разделе СОЗДАНИЕ БАЗ ДАННЫХ.
Создайте новую бессерверную базу данных общего назначения с помощью следующего примера T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Перемещение базы данных между уровнями вычислений или уровнями служб
Базу данных можно переместить между подготовленным уровнем вычислений и бессерверным уровнем вычислений.
Бессерверную базу данных также можно переместить с уровня служб общего назначения на уровень служб "Гипермасштабирование". Дополнительные сведения см. в статье "Управление базами данных гипермасштабирования".
При перемещении базы данных между уровнями вычислений укажите параметр модели вычислений либо Serverless при использовании PowerShell или Azure CLI, либо Provisioned SERVICE_OBJECTIVE при использовании T-SQL. Просмотрите ограничения ресурсов, чтобы определить соответствующую цель службы.
В следующих примерах существующая база данных перемещается из подготовленных вычислений в бессерверные.
С помощью PowerShell
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера PowerShell:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Использование Azure CLI
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера Azure CLI:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Использование Transact-SQL (T-SQL)
При использовании T-SQL для перемещения базы данных между вычислительными уровнями значения по умолчанию применяются для минимальных виртуальных ядер и автоматической приостановки задержки. Их значения можно изменить с портал Azure или с помощью API, включая PowerShell, Azure CLI и REST. Дополнительные сведения см. в статье Параметры инструкции ALTER DATABASE для файлов и файловых групп (Transact-SQL).
Переместите подготовленную базу данных общего назначения вычислений на бессерверный уровень вычислений с помощью следующего примера T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Изменение бессерверной конфигурации
С помощью PowerShell
Используйте Set-AzSqlDatabase для изменения максимального или минимального количества виртуальных ядер и автоматической приостановки задержки. MaxVcoreMinVcoreИспользуйте аргументы и AutoPauseDelayInMinutes аргументы. Бессерверная автоматическая приостановка в настоящее время не поддерживается на уровне гипермасштабирования, поэтому аргумент задержки автоматической приостановки применим только к уровню общего назначения.
Использование Azure CLI
Используйте az sql db update для изменения максимального или минимального количества виртуальных ядер и автоматической приостановки задержки. capacitymin-capacityИспользуйте аргументы и auto-pause-delay аргументы. Бессерверная автоматическая приостановка в настоящее время не поддерживается на уровне гипермасштабирования, поэтому аргумент задержки автоматической приостановки применим только к уровню общего назначения.
Azure Monitor
Используемые и тарифицируемые ресурсы
Ресурсы бессерверной базы данных включают сущности пула ресурсов приложений, экземпляра SQL и пула ресурсов пользователей.
Пакет приложения
Пакет приложения представляет внешнюю границу управления для большинства ресурсов базы данных, независимо от того, на каком уровне находится база данных (бессерверные или подготовленные вычисления). Пакет приложения содержит экземпляр SQL и внешние службы (например, полнотекстовый поиск), которые вместе определяют область применения всех пользовательских и системных ресурсов, используемых базой данных в Базе данных SQL. Экземпляр SQL обычно управляет общим использованием ресурсов в пакете приложения.
Пул пользовательских ресурсов
Пул пользовательских ресурсов представляет внутреннюю границу управления для ресурсов базы данных независимо от того, на каком уровне находится база данных (бессерверные или подготовленные вычисления). Пул ресурсов пользователей определяет область ЦП и операций ввода-вывода для рабочей нагрузки пользователя, созданной DDL (CREATE и ALTER) и DML (INSERT, UPDATE, DELETE и MERGE, и SELECT). Эти запросы обычно представляют самые распространенные операции, потребляющие ресурсы в пакете приложения.
Метрики
В следующей таблице содержатся метрики для мониторинга использования ресурсов пакета приложения и пула ресурсов пользователя бессерверной базы данных, включая все геореплики:
| Объект | Метрическая | Description | единиц(ы) |
|---|---|---|---|
| Пакет приложения | app_cpu_percent | Процент виртуальных ядер, используемых приложением относительно максимального количества виртуальных ядер, разрешенных для приложения. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. | Процентное отношение |
| Пакет приложения | app_cpu_billed | Объем вычислительных ресурсов, тарифицируемых для приложения в отчетный период. Сумма, которая насчитывается за этот период, является произведением этого показателя и стоимости виртуального ядра. Значения этой метрики определяются агрегированием максимального количества используемых ЦП и памяти, используемых каждую секунду. Если используемый объем меньше минимальной суммы, подготовленной по минимальным виртуальным ядрам и минимальной памяти, взимается минимальная сумма. Чтобы сравнить, как взимается плата за ресурсы ЦП и памяти, представьте, что объем памяти нормализуется с учетом виртуальных ядер путем преобразования объема памяти в ГБ в количество виртуальных ядер по 3 ГБ. Для бессерверного гипермасштабирования эта метрика предоставляется для основной реплики и всех именованных реплик. |
Время использования виртуальных ядер в секундах |
| Пакет приложения | app_cpu_billed_HA_replicas | Применимо только к бессерверным гипермасштабированием. Сумма вычислительных ресурсов, выставленных во всех приложениях для реплик высокого уровня доступности в течение отчетного периода. Эта сумма ограничена либо репликами высокого уровня доступности, принадлежащими основной реплике, либо репликам высокой доступности, принадлежащим заданной именованной реплике. Перед вычислением этой суммы в репликах высокого уровня доступности объем вычислительных ресурсов, выставленный для отдельной реплики высокого уровня доступности, определяется таким же образом, как для первичной реплики или именованной реплики. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. Сумма, выплачиваемая в течение отчетного периода, является продуктом этой метрики и ценой единицы виртуальных ядер. | Время использования виртуальных ядер в секундах |
| Пакет приложения | app_memory_percent | Процент памяти, используемой приложением относительно максимально допустимой памяти для приложения. Для бессерверного гипермасштабирования эта метрика предоставляется для всех основных реплик, именованных реплик и геореплик. | Процентное отношение |
| Пул пользовательских ресурсов | cpu_percent | Процент виртуальных ядер, используемых рабочей нагрузкой пользователя относительно максимального количества виртуальных ядер, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | data_IO_percent | Процент операций ввода-вывода в секунду данных, используемых рабочей нагрузкой пользователя относительно максимального количества операций ввода-вывода в секунду данных, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | log_IO_percent | Процент ведения журнала в МБ/с, используемых рабочей нагрузкой пользователя относительно максимального объема ведения журнала в МБ/с, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | workers_percent | Процент рабочих нагрузок, используемых рабочей нагрузкой пользователя относительно максимального числа рабочих нагрузок, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
| Пул пользовательских ресурсов | sessions_percent | Процент сеансов, используемых рабочей нагрузкой пользователя относительно максимального числа сеансов, разрешенных для рабочей нагрузки пользователя. | Процентное отношение |
Состояние приостановки и возобновления работы
В случае бессерверной базы данных с включенной автоматической приостановкой состояние отчета содержит следующие значения:
| Состояние | Description |
|---|---|
| Online | База данных находится в сети. |
| Приостановка | База данных переходит из сети в режим приостановки. |
| Приостановлен | База данных приостановлена. |
| Возобновление | База данных переходит из приостановленной в режим "в сети". |
Использование портала Azure
В портал Azure состояние базы данных отображается на странице обзора базы данных и на странице обзора сервера. Кроме того, в портал Azure журнал событий приостановки и возобновления бессерверной базы данных можно просмотреть в журнале действий.
С помощью PowerShell
Просмотрите текущее состояние базы данных с помощью следующего примера PowerShell:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Использование Azure CLI
Просмотрите текущее состояние базы данных с помощью следующего примера Azure CLI:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Ограничения ресурсов
См. подробнее об ограничениях ресурсов уровня бессерверных вычислений.
Выставление счетов
Объем вычислительных ресурсов, выставленных для бессерверной базы данных, — это максимальное количество используемых ЦП и памяти, используемых каждую секунду. Если объем используемой ЦП и памяти меньше минимальной суммы, подготовленной для каждого ресурса, плата взимается. Чтобы сравнить ЦП с памятью для выставления счетов, память нормализуется в единицы виртуальных ядер, изменив количество ГБ на 3 ГБ на виртуальное ядро.
- Оплачиваемые ресурсы: ЦП и память
- Сумма выставлена: цена за единицу виртуальных ядер * максимальная (минимальные виртуальные ядра, используемые виртуальные ядра, минимальный объем памяти ГБ * 1/3, используемый ГБ памяти * 1/3)
- Частота начисления оплаты: раз в секунду
Плата за виртуальное ядро — это плата за каждое виртуальное ядро в секунду.
См. подробнее на странице с ценами на Базу данных SQL Azure, где приведены цены за потребленные единицы ресурсов в заданном регионе.
Объем вычислений, выставляемых бессерверным для базы данных общего назначения, или первичной или именованной реплики гипермасштабирования предоставляется следующими метрикой:
- Показатель: app_cpu_billed (виртуальное ядро в секунду).
- Определение: максимальное (минимальное количество виртуальных ядер, используемых виртуальных ядер, минимальное количество ГБ памяти * 1/3, используемое в памяти * 1/3)
- Частота отчетов: в минуту на основе измерений в секунду, агрегированных в течение 1 минуты.
Объем вычислений, выставляемых бессерверными для реплик высокой доступности гипермасштабирования, принадлежащих основной реплике или любой именованной реплике, предоставляется следующей метрикой:
- Метрика: app_cpu_billed_HA_replicas (секунды виртуальных ядер)
- Определение: максимальная сумма (минимальные виртуальные ядра, используемые виртуальные ядра, минимальное количество ГБ памяти * 1/3, используемый в памяти * 1/3) для всех реплик высокой доступности, принадлежащих к родительскому ресурсу.
- Родительская конечная точка ресурса и метрики: первичная реплика и любая именованной реплики отдельно предоставляют эту метрику, которая измеряет вычисление, выставленное для любых связанных реплик высокой доступности.
- Частота отчетов: в минуту на основе измерений в секунду, агрегированных в течение 1 минуты.
Минимальный счет за вычислительные ресурсы
Если бессерверная база данных приостановлена, то счет за вычислительные ресурсы равен нулю. Если бессерверная база данных не приостановлена, минимальный счет за вычисления не меньше количества виртуальных ядер на основе максимального (минимальные виртуальные ядра, минимальный объем памяти ГБ * 1/3).
Примеры:
- Предположим, что бессерверная база данных на уровне общего назначения не приостановлена и настроена с 8 максимальными виртуальными ядрами и 1 минимальным виртуальным ядром, соответствующим минимальному 3,0 ГБ памяти. Затем минимальный счет за вычисления основан на максимальном (1 виртуальном ядере, 3,0 ГБ * 1 виртуальное ядро / 3 ГБ) = 1 виртуальное ядро.
- Предположим, что бессерверная база данных на уровне общего назначения не приостановлена и настроена с 4 максимальными виртуальными ядрами и 0,5 минимальными виртуальными ядрами, соответствующими 2,1 ГБ минимальной памяти. Затем минимальный счет за вычисления основан на максимуме (0,5 виртуальных ядер, 2,1 ГБ * 1 vCore / 3 ГБ) = 0,7 виртуальных ядер.
- Предположим, что бессерверная база данных на уровне гипермасштабирования имеет первичную реплику с одной репликой высокой доступности и одной именованной репликой без реплик высокой доступности. Предположим, что каждая реплика настроена с 8 максимальными виртуальными ядрами и 1 минимальным виртуальным ядром, соответствующим минимальному 3 ГБ памяти. Затем минимальный счет за вычисления для первичной реплики, реплики высокой доступности и именованной реплики зависит от максимального (1 виртуального ядра, 3 ГБ * 1 виртуального ядра / 3 ГБ) = 1 виртуального ядра.
Калькулятор цен База данных SQL Azure для бессерверных можно использовать для определения минимальной конфигурации памяти на основе числа настроенных максимальных и минимальных виртуальных ядер. Как правило, если настроенные минимальные виртуальные ядра больше 0,5 виртуальных ядер, минимальный счет за вычисления не зависит от минимальной памяти, настроенной и только на основе числа настроенных минимальных виртуальных ядер.
Примеры сценариев.
Рассмотрим бессерверную базу данных на уровне общего назначения, настроенную с 1 минимальным виртуальным ядром и 4 максимальными виртуальными ядрами. Эта конфигурация соответствует примерно 3 ГБ минимальной памяти и 12 ГБ максимальной памяти. Предположим, что задержка автоматической приостановки равна 6 часам, а рабочая нагрузка базы данных активна в течение первых 2 часов в 24-часовом периоде, а затем неактивна.
В этом случае оплачиваются вычислительные ресурсы и ресурсы хранения базы данных за первые 8 часов. Несмотря на неактивность базы данных после второго часа, счет за вычислительные ресурсы в последующие 6 часов все равно выставляется (за минимальные подготовленные вычислительные ресурсы, пока база данных в сети). В течение оставшейся части 24-часового периода, пока база данных приостановлена, оплачиваются только ресурсы хранения.
Точнее, счет за вычислительные ресурсы в этом примере выставляется следующим образом.
| Интервал времени | Число виртуальных ядер, используемых каждую секунду | ГБ, используемых каждую секунду | Измерение вычислительных ресурсов, за которые выставляется счет | Время работы виртуальных ядер в секундах за интервал времени |
|---|---|---|---|---|
| 0:00–1:00. | 4 | 9 | Использовано виртуальных ядер | 4 виртуальных ядра * 3600 секунд = 14 400 секунд работы виртуальных ядер |
| 1:00–2:00 | 1 | 12 | Используемая память | 12 ГБ * 1/3 * 3600 секунд = 14 400 секунд работы виртуальных ядер |
| 2:00–8:00. | 0 | 0 | Минимальная подготовленная память | 3 ГБ * 1/3 * 21 600 секунд = 21 600 секунд работы виртуальных ядер |
| 8:00–24:00. | 0 | 0 | Счет за вычислительные ресурсы в состоянии приостановки не выставляется | 0 секунд работы виртуальных ядер |
| Совокупное включенное в счет время работы виртуальных ядер в секундах за 24 часа | 50 400 секунд виртуальных ядер |
Предположим, что цена за единицу вычислений составляет 0,000145 долл. США/виртуальное ядро/секунда. Вычислим объем включенных в счет вычислительных ресурсов за этот 24-часовой период: умножим цену единицы вычислений на количество включенных в счет секунд работы виртуальных ядер, то есть 0,000145 доллара/виртуальное ядро/секунда * 50 400 секунд работы виртуальных ядер ~ 7,31 доллара.
Преимущество гибридного использования Azure и резервная мощность
Преимущество гибридного использования Azure и скидки на резервную мощность неприменимы к уровню бессерверных вычислений.
Доступные регионы
Бессерверные уровни общего назначения и гипермасштабирования с поддержкой до 40 максимальных виртуальных ядер доступны во всем мире, за исключением следующих регионов:
- Восточный Китай
- Северный Китай
- Центральная Германия
- Северо-Восточная Германия
- US Gov Central (Айова)
Регионы, поддерживающие 80 виртуальных ядер без зон доступности для общего назначения и гипермасштабирования
В настоящее время в следующих регионах поддерживается 80 виртуальных ядер без сервера для уровней общего назначения и гипермасштабирования:
- Центральная Австралия 1
- Центральная Австралия 2
- Восточная Австралия
- Юго-Восточная часть Австралии
- Южная Бразилия
- Юго-Восточная Бразилия
- Центральная Канада
- Восточная Канада
- Центральная часть США
- Восточный Китай 2
- Восточный Китай 3
- Северный Китай 2
- Северный Китай 3
- Восточная Азия
- Восточная часть США
- Восточная часть США 2
- Центральная Франция
- Южная Франция
- Северная Германия
- Центрально-Западная Германия
- Центральная Индия
- Южная Индия
- Израиль, центральный регион
- Северная Италия
- Восточная Япония
- Западная Япония
- Jio, Центральная Индия
- Западная Индия Jio
- Республика Корея, центральный регион
- Республика Корея, южный регион
- Саут-Майлайсия
- Центральная Мексика
- Центрально-северная часть США
- Северная Европа
- Восточная Норвегия;
- Западная Норвегия
- Центральная Польша
- Центральный Катар
- Северная часть ЮАР
- Западная часть ЮАР
- Центрально-южная часть США
- Юго-Восточная Азия
- Центральная Испания
- Центральная Швеция
- Южная Швеция
- Северная Швейцария
- Западная Швейцария
- Северный Тайвань
- Северо-западный Тайвань
- Центральная часть ОАЭ
- Северная часть ОАЭ;
- южная часть Соединенного Королевства
- западная часть Соединенного Королевства
- Восточная часть США
- US Gov Southcentral
- Юго-запад США
- Западная Европа
- Центрально-западная часть США
- Западная часть США
- западная часть США 2
- Западная часть США — 3
Регионы, поддерживающие 80 виртуальных ядер с зонами доступности для общего назначения и гипермасштабирования
В настоящее время 80 виртуальных ядер с поддержкой зоны доступности в бессерверных уровнях общего назначения и гипермасштабирования предоставляются в следующих регионах с более запланированными регионами:
- Восточная Австралия
- Южная Бразилия
- Центральная Канада
- Центральная часть США
- Восточная Азия
- Восточная часть США
- Восточная часть США 2
- Центральная Франция
- Центрально-Западная Германия
- Центральная Индия
- Восточная Япония
- Республика Корея, центральный регион
- Северная Европа
- Северная часть ЮАР;
- Центрально-южная часть США
- Юго-Восточная Азия
- Центральная Швеция
- Северная часть ОАЭ;
- южная часть Соединенного Королевства
- Восточная часть США
- Западная Европа
- западная часть США 2
- Западная часть США — 3
Связанный контент
- Сведения о начале работы см. в кратком руководстве. Создание одной базы данных — База данных SQL Azure.
- Варианты уровня бессерверных служб см. в разделе "Общего назначения " и "Гипермасштабирование".