Копирование данных из Amazon RDS для Oracle с помощью Фабрики данных Azure или Azure Synapse Analytics
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описывается, как с помощью действия Copy в Фабрике данных Azure копировать данные из базы данных Amazon RDS для Oracle. Она составлена на основе статьи Действие Copy в Фабрике данных Azure.
Поддерживаемые возможности
Данный соединитель Amazon RDS для Amazon RDS для Oracle поддерживается для следующих возможностей:
| Поддерживаемые возможности | IR |
|---|---|
| Действие копирования (источник/-) | (1) (2) |
| Действие поиска | (1) (2) |
① Среда выполнения интеграции Azure ② Локальная среда выполнения интеграции
Список хранилищ данных, которые поддерживаются в качестве источников и приемников для действия копирования, приведен в таблице Поддерживаемые хранилища данных и форматы.
В частности, этот соединитель Amazon RDS для Oracle поддерживает:
- Следующие версии базы данных Amazon RDS для Oracle:
- Amazon RDS для Oracle 19c R1 (19.1) и более поздних версий;
- Amazon RDS для Oracle 18c R1 (18.1) и более поздних версий;
- Amazon RDS для Oracle 12c R1 (12.1) и более поздних версий;
- Amazon RDS для Oracle 11c R1 (11.1) и более поздних версий.
- Параллельное копирование из источника Amazon RDS для Oracle. Дополнительные сведения см. в разделе Параллельное копирование из Amazon RDS для Oracle.
Примечание.
Прокси-сервер Amazon RDS для Oracle не поддерживается.
Необходимые компоненты
Если хранилище данных размещено в локальной сети, виртуальной сети Azure или виртуальном частном облаке Amazon, для подключения к нему нужно настроить локальную среду выполнения интеграции.
Если же хранилище данных представляет собой управляемую облачную службу данных, можно использовать Azure Integration Runtime. Если доступ предоставляется только по IP-адресам, утвержденным в правилах брандмауэра, вы можете добавить IP-адреса Azure Integration Runtime в список разрешений.
Вы также можете использовать функцию среды выполнения интеграции в управляемой виртуальной сети в Фабрике данных Azure для доступа к локальной сети без установки и настройки локальной среды выполнения интеграции.
Дополнительные сведения о вариантах и механизмах обеспечения сетевой безопасности, поддерживаемых Фабрикой данных, см. в статье Стратегии получения доступа к данным.
Среда выполнения интеграции содержит встроенный драйвер Amazon RDS для Oracle. Поэтому вам не нужно вручную устанавливать драйвер при копировании данных из базы данных Amazon RDS для Oracle.
Начать
Чтобы выполнить действие копирования с конвейером, можно воспользоваться одним из приведенных ниже средств или пакетов SDK:
- средство копирования данных;
- Портал Azure
- Пакет SDK для .NET
- Пакет SDK для Python
- Azure PowerShell
- The REST API
- шаблон Azure Resource Manager.
Создание связанной службы для Amazon RDS для Oracle с помощью пользовательского интерфейса
Выполните следующие действия, чтобы создать связанную службу для Amazon RDS для Oracle в пользовательском интерфейсе портала Azure.
Перейдите на вкладку "Управление" в рабочей области Фабрики данных Azure или Synapse и выберите "Связанные службы", после чего нажмите "Создать":
Найдите Amazon RDS для Oracle и выберите соединитель Amazon RDS для Oracle.
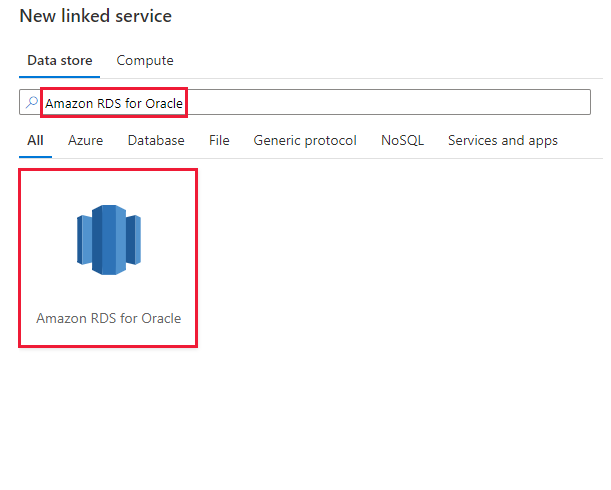
Настройте сведения о службе, проверьте подключение и создайте связанную службу.
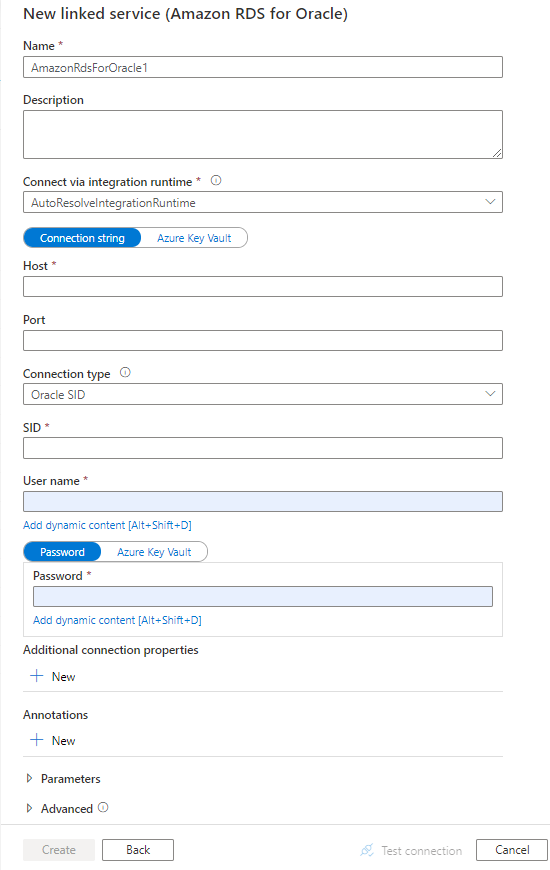
Сведения о конфигурации соединителя
Следующие разделы содержат сведения о свойствах, которые используются для определения сущностей, характерных для соединителя Amazon RDS для Oracle.
Свойства связанной службы
Связанная служба Amazon RDS для Oracle поддерживает следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type необходимо задать значение AmazonRdsForOracle. | Да |
| connectionString | Указывает сведения, необходимые для подключения к экземпляру базы данных Amazon RDS для Oracle. Вы можете также поместить пароль в Azure Key Vault и извлечь конфигурацию password из строки подключения. Ознакомьтесь с приведенными ниже примерами и подробными сведениями в статье Хранение учетных данных в Azure Key Vault. Поддерживаемые типы подключений: вы можете использовать ИД безопасности Amazon RDS для Oracle или имя службы Amazon RDS для Oracle для идентификации базы данных. — Если вы используете идентификатор безопасности, используйте этот код для подключения: Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;— Если вы используете имя службы, используйте этот код: Host=<host>;Port=<port>;ServiceName=<servicename>;User Id=<username>;Password=<password>;Чтобы получить доступ к расширенным собственным параметрам подключения Amazon RDS для Oracle, добавьте запись в файл TNSNAMES.ORA на сервере Amazon RDS для Oracle и в связанной службе Amazon RDS для Oracle, используйте тип соединения по имени службы Amazon RDS для Oracle и настройте соответствующее имя службы. |
Да |
| connectVia | Среда выполнения интеграции, используемая для подключения к хранилищу данных. Дополнительные сведения см. в разделе Предварительные условия. Если не указано другое, по умолчанию используется интегрированная Azure Integration Runtime. | No |
При наличии нескольких экземпляров Amazon RDS для Oracle для сценария отработки отказа можно создать связанную службу Amazon RDS для Oracle и указать основной узел, порт, имя пользователя, пароль и т. д., а также добавить новое значение "Дополнительные свойства подключения" с именем свойства AlternateServers и значением (HostName=<secondary host>:PortNumber=<secondary port>:ServiceName=<secondary service name>) — не пропускайте скобки и обращайте внимание на двоеточия (:) в качестве разделителя. Например, следующее значение альтернативных серверов определяет два альтернативных сервера баз данных для отработки отказа подключения: (HostName=AccountingAmazonRdsForOracleServer:PortNumber=1521:SID=Accounting,HostName=255.201.11.24:PortNumber=1522:ServiceName=ABackup.NA.MyCompany).
Дополнительные свойства подключения, которые можно задать в строке подключения в зависимости от сценария
| Свойство | Description | Допустимые значения |
|---|---|---|
| ArraySize | Число байтов, которое соединитель может получить в одном круговом пути сети. Например, ArraySize=10485760.Чем больше значение, тем больше пропускная способность, поскольку получать данные из сети приходится реже. Чем меньше значение, тем меньше время отклика, так как передача данных с сервера выполняется быстрее. |
Целое число от 1 до 4294967296 (4 ГБ). Значение по умолчанию: 60000. Значение 1 не определяет число байтов, а указывает на выделение пространства только для одной строки данных. |
Включить шифрование для подключения Amazon RDS для Oracle можно двумя способами:
Чтобы использовать шифрование 3DES и AES, на стороне сервера Amazon RDS для Oracle перейдите к Oracle Advanced Security (OAS) и настройте соответствующие параметры. Дополнительные сведения см. в этой документации по Oracle. Соединитель Amazon RDS для Oracle Application Development Framework (ADF) автоматически согласовывает метод шифрования таким образом, чтобы при установлении соединения с Amazon RDS для Oracle использовался тот метод шифрования, который вы настроили в OAS.
Использование TLS:
Получите сведения о TLS/SSL-сертификате. Получите сведения о SSL-сертификате в кодировке Distinguished Encoding Rules( DER) и сохраните выходные данные (----- Begin Certificate … End Certificate -----) как текстовый файл.
openssl x509 -inform DER -in [Full Path to the DER Certificate including the name of the DER Certificate] -textПример. Извлеките сведения о сертификате из файла DERcert.cer и сохраните выходные данные в файле cert.txt.
openssl x509 -inform DER -in DERcert.cer -text Output: -----BEGIN CERTIFICATE----- XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX XXXXXXXXX -----END CERTIFICATE-----Создайте
keystoreилиtruststore. Следующая команда создает файлtruststore, с паролем или без него, в формате PKCS-12.openssl pkcs12 -in [Path to the file created in the previous step] -out [Path and name of TrustStore] -passout pass:[Keystore PWD] -nokeys -exportПример. Создайте файл
truststoreв формате PKCS-12 с именем MyTrustStoreFile и паролем.openssl pkcs12 -in cert.txt -out MyTrustStoreFile -passout pass:ThePWD -nokeys -exportПоместите файл
truststoreна компьютер в локальной среде IR. Например, по адресу C:\MyTrustStoreFile.В службе настройте строку подключения Amazon RDS для Oracle с помощью
EncryptionMethod=1и соответствующего значенияTrustStore/TrustStorePassword. Например,Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;EncryptionMethod=1;TrustStore=C:\\MyTrustStoreFile;TrustStorePassword=<trust_store_password>.
Пример:
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;Password=<password>;"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Пример: хранение пароля в Azure Key Vault
{
"name": "AmazonRdsForOracleLinkedService",
"properties": {
"type": "AmazonRdsForOracle",
"typeProperties": {
"connectionString": "Host=<host>;Port=<port>;Sid=<sid>;User Id=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Свойства набора данных
В этом разделе содержится список свойств, поддерживаемых набором данных Amazon RDS для Oracle. Полный список разделов и свойств, доступных для определения наборов данных, см. в разделе Наборы данных в фабрике данных Azure.
Чтобы скопировать данные из базы данных Amazon RDS для Oracle или в нее, установите для свойства type набора данных значение AmazonRdsForOracleTable. Поддерживаются следующие свойства.
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Для свойства type набора данных необходимо задать значение AmazonRdsForOracleTable. |
Да |
| schema | Имя схемы. | No |
| table | Имя таблицы или представления. | No |
| tableName | Имя таблицы или представления со схемой. Это свойство поддерживается только для обеспечения обратной совместимости. Для новой рабочей нагрузки используйте schema и table. |
No |
Пример:
{
"name": "AmazonRdsForOracleDataset",
"properties":
{
"type": "AmazonRdsForOracleTable",
"schema": [],
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"linkedServiceName": {
"referenceName": "<Amazon RDS for Oracle linked service name>",
"type": "LinkedServiceReference"
}
}
}
Свойства действия копирования
В этом разделе содержится список свойств, поддерживаемых источником Amazon RDS для Oracle. Полный список разделов и свойств, доступных для определения действий, см. в разделе Конвейеры и действия в фабрике данных Azure.
Использование Amazon RDS для Oracle в качестве источника
Совет
Чтобы эффективно загружать данные из Amazon RDS для Oracle с использованием секционирования данных, изучите дополнительные сведения из статьи Параллельное копирование из Amazon RDS для Oracle.
Чтобы копировать данные из Amazon RDS для Oracle, установите в действии Copy тип источника AmazonRdsForOracleSource. В разделе source действия копирования поддерживаются следующие свойства:
| Свойство | Описание: | Обязательное поле |
|---|---|---|
| type | Свойству type источника действия копирования необходимо задать значение AmazonRdsForOracleSource. |
Да |
| oracleReaderQuery | Используйте пользовательский SQL-запрос для чтения данных. Например, "SELECT * FROM MyTable".При включении секционированной нагрузки необходимо привязать все соответствующие встроенные параметры раздела в запросе. Примеры см. в разделе Параллельное копирование из Amazon RDS для Oracle. |
No |
| partitionOptions | Задает параметры секционирования данных, используемые для загрузки данных из Amazon RDS для Oracle. Допустимые значения: Нет (по умолчанию), PhysicalPartitionsOfTable и DynamicRange. Если параметр секционирования включен (любое значение, кроме None), степень параллелизма для одновременной загрузки данных из базы данных Amazon RDS для Oracle управляется параметром parallelCopies в действии Copy. |
No |
| partitionSettings | Позволяет указать группу параметров для секционирования данных. Применяется, если параметр секционирования имеет значение, отличное от None. |
No |
| partitionNames | Список физических секций, которые необходимо скопировать. Применяется, если параметр секции имеет значение PhysicalPartitionsOfTable. Если для получения исходных данных используется запрос, подключите ?AdfTabularPartitionName в предложении WHERE. Пример см. в разделе Параллельное копирование из Amazon RDS для Oracle. |
No |
| partitionColumnName | Укажите имя исходного столбца целочисленного типа, который будет использоваться для секционирования по диапазонам при параллельном копировании. Если значение не указано, автоматически определяется первичный ключ таблицы, который используется в качестве столбца секционирования. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionColumnName в предложении WHERE. Пример см. в разделе Параллельное копирование из Amazon RDS для Oracle. |
No |
| partitionUpperBound | Максимальное значение столбца секционирования для копирования данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionUpbound в предложении WHERE. Пример см. в разделе Параллельное копирование из Amazon RDS для Oracle. |
No |
| partitionLowerBound | Минимальное значение столбца секционирования для копирования данных. Применяется, если параметр секции имеет значение DynamicRange. Если для получения исходных данных используется запрос, подключите ?AdfRangePartitionLowbound в предложении WHERE. Пример см. в разделе Параллельное копирование из Amazon RDS для Oracle. |
No |
Пример: копирование данных с помощью простого запроса без секции
"activities":[
{
"name": "CopyFromAmazonRdsForOracle",
"type": "Copy",
"inputs": [
{
"referenceName": "<Amazon RDS for Oracle input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AmazonRdsForOracleSource",
"oracleReaderQuery": "SELECT * FROM MyTable"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Параллельное копирование из Amazon RDS для Oracle
Соединитель Amazon RDS для Oracle обеспечивает встроенное секционирование данных для копирования данных из Amazon RDS для Oracle в параллельном режиме. Параметры секционирования данных можно найти на вкладке Источник действия Copy.
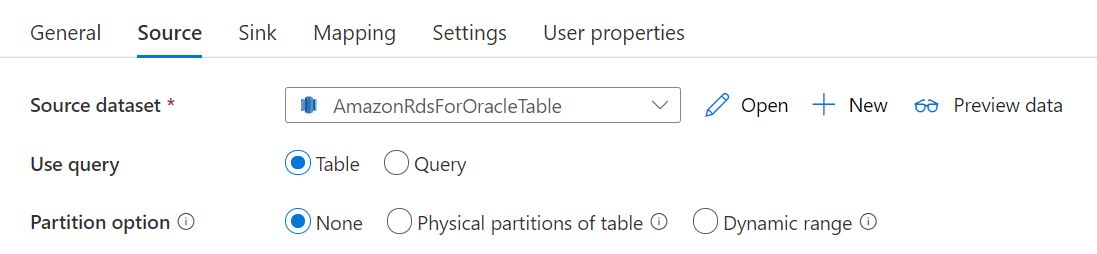
Если включено копирование с секционированием, служба выполняет параллельные запросы к источнику Amazon RDS для Oracle для загрузки данных по секциям. Степень параллелизма определяется с помощью параметра parallelCopies для действия копирования. Например, если parallelCopies имеет значение 4, служба одновременно создаст и выполнит четыре запроса с учетом указанного способа и параметров секционирования, где каждый запрос извлекает часть данных из базы данных Amazon RDS для Oracle.
Рекомендуется включить параллельное копирование с секционированием данных, особенно при загрузке большого объема данных из Amazon RDS для Oracle. Ниже приведены рекомендуемые конфигурации для разных сценариев. Если копирование данных выполняется в файловое хранилище данных, мы рекомендуем сохранять данные в папку несколькими файлами (указывая только имя папки), так как производительность в таком случае будет выше, чем при записи в один файл.
| Сценарий | Предлагаемые параметры |
|---|---|
| Полная загрузка из большой таблицы с физическими секциями. | Параметр секционирования. Физические секции таблицы. Во время выполнения служба автоматически определяет физические секции и копирует данные по секциям. |
| Полная загрузка из большой таблицы без физических секций, когда таблица содержит столбец целочисленного типа для секционирования данных. | Параметры секции: секция динамического диапазона. Столбец секционирования: укажите столбец, используемый для секционирования данных. Если значение не указано, то используется столбец с первичным ключом. |
| Загрузка большого объема данных с помощью пользовательского запроса с физическими секциями. | Параметр секционирования. Физические секции таблицы. Запрос: SELECT * FROM <TABLENAME> PARTITION("?AdfTabularPartitionName") WHERE <your_additional_where_clause>.Имя секции: укажите имена секций, из которых следует копировать данные. Если не указано, служба автоматически обнаруживает физические секции в таблице, указанной в наборе данных Amazon RDS для Oracle. Во время выполнения служба данных заменяет ?AdfTabularPartitionName фактическим именем секции и отправляет данные в Amazon RDS для Oracle. |
| Загрузка большого объема данных пользовательским запросом без использования физических секций, однако с использованием столбца целочисленного типа для секционирования данных. | Параметры секции: секция динамического диапазона. Запрос: SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>.Столбец секционирования: укажите столбец, используемый для секционирования данных. Секционирование можно выполнять по столбцу с целочисленным типом данных. Верхняя граница секции и Нижняя граница секции: укажите эти значения, если нужно добавить фильтрацию по столбцу секционирования, чтобы получить данные только в пределах между нижним и верхним значениями. В ходе выполнения служба заменяет ?AdfRangePartitionColumnName, ?AdfRangePartitionUpbound и ?AdfRangePartitionLowbound фактическим именем столбца и диапазонами значений для каждой секции и отправляет в Amazon RDS для Oracle. Например, если указан столбец секционирования ID с нижней границей 1 и верхней границей 80 при этом для параллельного копирования указано значение 4, служба будет извлекать данные по 4 секциям. Для них будут применены следующие диапазоны значений идентификаторов: [1, 20], [21, 40], [41, 60] и [61, 80]. |
Совет
При копировании данных из несекционированной таблицы можно использовать параметр секции "Динамический диапазон" для секционирования по целочисленному столбцу. Если в исходных данных нет такого типа столбца, можно использовать функцию ORA_HASH в исходном запросе, чтобы создать столбец и использовать его в качестве столбца секционирования.
Пример: запрос с физической секцией
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> PARTITION(\"?AdfTabularPartitionName\") WHERE <your_additional_where_clause>",
"partitionOption": "PhysicalPartitionsOfTable",
"partitionSettings": {
"partitionNames": [
"<partitionA_name>",
"<partitionB_name>"
]
}
}
Пример: запрос с секционированием по динамическому диапазону
"source": {
"type": "AmazonRdsForOracleSource",
"query": "SELECT * FROM <TABLENAME> WHERE ?AdfRangePartitionColumnName <= ?AdfRangePartitionUpbound AND ?AdfRangePartitionColumnName >= ?AdfRangePartitionLowbound AND <your_additional_where_clause>",
"partitionOption": "DynamicRange",
"partitionSettings": {
"partitionColumnName": "<partition_column_name>",
"partitionUpperBound": "<upper_value_of_partition_column>",
"partitionLowerBound": "<lower_value_of_partition_column>"
}
}
Свойства действия поиска
Подробные сведения об этих свойствах см. в разделе Действие поиска.
Связанный контент
Список хранилищ данных, поддерживаемых в рамках функции копирования в качестве источников и приемников, см. в разделе Поддерживаемые хранилища данных.