Функции для оптимизации производительности действий копирования
ОБЛАСТЬ ПРИМЕНЕНИЯ:  Фабрика данных Azure Azure Synapse Analytics
Фабрика данных Azure Azure Synapse Analytics
Совет
Попробуйте использовать фабрику данных в Microsoft Fabric, решение для аналитики с одним интерфейсом для предприятий. Microsoft Fabric охватывает все, от перемещения данных до обработки и анализа данных в режиме реального времени, бизнес-аналитики и отчетности. Узнайте, как бесплатно запустить новую пробную версию !
В этой статье описаны функции, которые можно использовать в конвейерах Фабрики данных Azure и Synapse для оптимизации производительности действий Copy.
Настройка функций производительности с помощью пользовательского интерфейса
Когда вы выберете действие Copy на холсте редактора конвейера и вкладку "Настройки" в области конфигурации действия под холстом, то увидите параметры для настройки всех функций производительности, подробно описанных ниже.
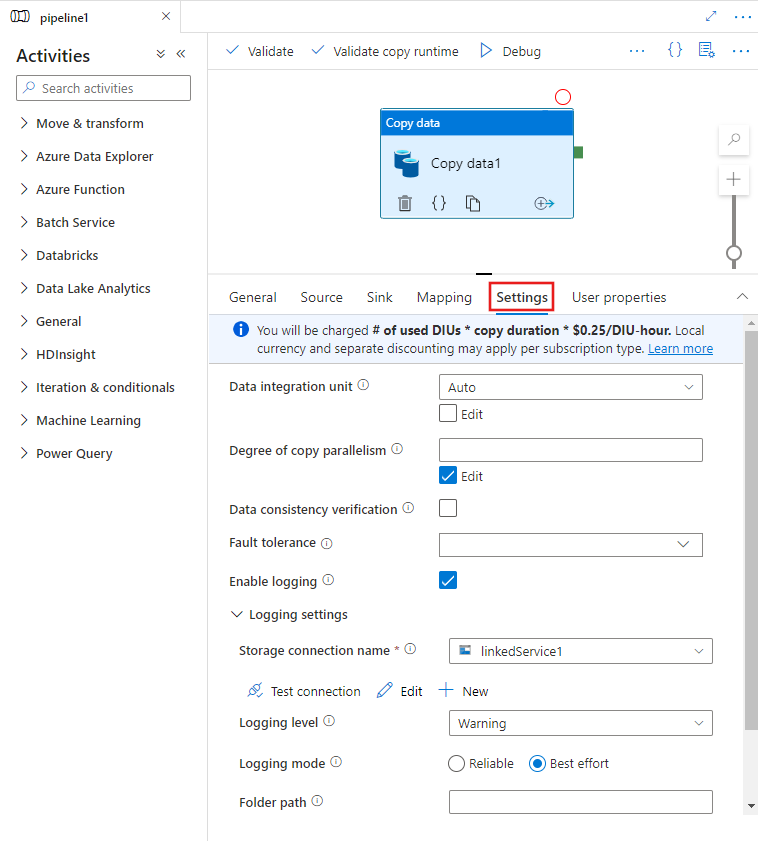
Единицы интеграции данных
Единица интеграции данных (DIU) — это мера, отражающая мощность (сочетания выделенных ресурсов ЦП, ОЗУ и сети) одной единицы в службе. Она применима только к среде выполнения интеграции Azure, но не к локальной среде выполнения интеграции.
Допустимые diUs для расширения возможностей выполнения действия копирования — от 4 до 256. Если число UI не указано или в пользовательском интерфейсе выбрано значение "Авто", служба в динамическом режиме выбирает оптимальное число DIU, исходя из пары "источник — приемник" и шаблона данных. В таблице ниже приведены поддерживаемые диапазоны числа DIU и логика работы по умолчанию в различных сценариях копирования.
| Сценарий копирования | Поддерживаемый диапазон числа DIU | Число единиц интеграции данных, устанавливаемое по умолчанию службой |
|---|---|---|
| Между файловыми хранилищами | - Копирование из одного файла или в один файл: 4 - Копирование из нескольких файлов: 4–256 в зависимости от количества и размера файлов Например, если копировать данные из папки с 4 большими файлами, выбрав режим сохранения иерархии, то максимальное эффективное число DIU будет равно 16, а если выбрать объединение файла, то максимальное эффективное число DIU будет равно 4. |
От 4 до 32 в зависимости от числа и размера файлов. |
| Из файлового хранилища в нефайловое | - Копирование из одного файла: 4 - Копирование из нескольких файлов: 4–256 в зависимости от количества и размера файлов Например, если копировать данные из папки с 4 большими файлами, максимальное эффективное число DIU будет равно 16. |
- Копирование в Базу данных SQL Azure или Azure Cosmos DB: от 4 до 16 в зависимости от уровня приемника (DTU/RU) и шаблона исходного файла. - Копирование в Azure Synapse Analytics с помощью PolyBase или оператора COPY: 2 – Другой сценарий: 4 |
| Из нефайлового хранилища в файловое | - Копирование из хранилищ данных с поддержкой параметра секции (включая База данных Azure для PostgreSQL, База данных SQL Azure, Управляемый экземпляр SQL Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Server и Teradata): 4–256 при записи в папку и 4 при записи в один файл. Примечание: до 4 DIU на каждый исходный раздел данных. - Другие сценарии: 4 |
- Копирование из источника по протоколу REST или HTTP: 1. - Копирование из Amazon Redshift с помощью ВЫГРУЗКИ: 4 - Другой сценарий: 4. |
| Между нефайловыми хранилищами | - Копирование из хранилищ данных с поддержкой параметра секции (включая База данных Azure для PostgreSQL, База данных SQL Azure, Управляемый экземпляр SQL Azure, Azure Synapse Analytics, Oracle, Netezza, SQL Server и Teradata): 4–256 при записи в папку и 4 при записи в один файл. Примечание: до 4 DIU на каждый исходный раздел данных. - Другие сценарии: 4 |
- Копирование из источника по протоколу REST или HTTP: 1. - Другой сценарий: 4. |
Число DIU, используемое для каждого действия Copy, можно увидеть в представлении мониторинга соответствующего действия или в его выводе. Дополнительные сведения см. в статье "Мониторинг действий Copy". Чтобы переопределить это значение по умолчанию, задайте значение свойства dataIntegrationUnits, как показано ниже. Фактическое число единиц интеграции данных, используемых при копировании, не превышает заданного значения, в зависимости от формата данных.
С вас будет взиматься плата # использованных DIU * продолжительность копирования * цена за единицу/DIU/час. Текущие цены см. здесь. Местная валюта и отдельные скидки могут применяться в зависимости от типа подписки.
Пример:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Масштабируемость локальной среды выполнения интеграции
Если вы хотите добиться более высокой пропускной способности, можно вертикально или горизонтально увеличить масштаб локальной среды IR:
- Если ЦП и доступная память на узле локальной среды IR используются не в полной мере, но при выполнении параллельных заданий достигается лимит, следует вертикально увеличить масштаб, увеличив число параллельных заданий, которые могут выполняться на узле. Инструкции см. здесь.
- Если же на узле локальной среды IR высока загрузка ЦП или мало доступной памяти, можно добавить еще один узел, чтобы горизонтально увеличить масштаб для распределения нагрузки между несколькими узлами. Инструкции см. здесь.
Обратите внимание, что в перечисленных ниже сценариях при выполнении одного действия Copy может задействоваться несколько узлов локальной среды IR:
- Копирование данных из файловых хранилищ (в зависимости от числа и размера файлов).
- Копирование данных из хранилища с поддержкой разделов, включая Базу данных SQL Azure, Управляемый экземпляр SQL Azure, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server и Teradata (в зависимости от числа разделов данных).
Параллельное копирование
Можно задать параллельную копию (свойство parallelCopies в определении JSON действия Copy или параметр Degree of parallelism на вкладке Параметры свойств действия Copy в пользовательском интерфейсе) для действия копирования, чтобы указать параллелизм, который будет использоваться действием Copy. Свойство parallelCopies можно интерпретировать как максимальное число потоков, которые могут параллельно считывать данные из хранилища-источника или записывать их в хранилища-приемники данных в рамках действия Copy.
Число параллельных операций копирования ортогонально числу единиц интеграции данных и числу узлов локальной среды IR. Он считается по всем DIU и всем узлам локальной среды IR.
По умолчанию для каждого выполнения действия Copy служба в динамическом режиме выбирает оптимальное число параллельных операций копирования, исходя из пары "источник — приемник" и шаблона данных.
Совет
Заданная по умолчанию логика параллельного копирования обычно обеспечивает наилучшую пропускную способность, которая определяется службой автоматически, исходя из пары "источник — приемник", шаблона данных и числа DIU или объема ресурсов ЦП, памяти и числа узлов локальной среды IR. О том, когда следует настраивать параллельное копирование, см. в статье "Устранение проблем с производительностью действий Copy".
Логика параллельного копирования систематизирована в следующей таблице.
| Сценарий копирования | Логика параллельного копирования |
|---|---|
| Между файловыми хранилищами | Свойство parallelCopies определяет степень параллелизма на уровне файлов. Разбиение каждого файла на блоки происходит автоматически и прозрачным образом. Используется наиболее подходящий размер блока для заданного типа хранилища данных, чтобы организовать параллельную загрузку данных. Фактическое число параллельных операций копирования во время выполнения действия Copy не превышает числа имеющихся у вас файлов. Если выбрано копирование в файловый приемник в режиме mergeFile, то при выполнении действия Copy параллелизм на уровне файлов не поддерживается. |
| Из файлового хранилища в нефайловое | – При копировании данных в Базу данных SQL Azure или Azure Cosmos DB число параллельных операций копирования по умолчанию зависит также от уровня приемника (числа DTU/RU). – При копировании данных в таблицу Azure число параллельных операций копирования по умолчанию равно 4. |
| Из нефайлового хранилища в файловое | – При копировании данных из хранилища с поддержкой разделов (включая Базу данных SQL Azure, Управляемый экземпляр SQL Azure, Azure Synapse Analytics, Oracle, Amazon RDS для Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS для SQL Server и Teradata) параллельная копия по умолчанию — 4. Фактическое число параллельных операций копирования во время выполнения действия Copy не превышает числа имеющихся у вас разделов. Обратите внимание, что в случае использования локальной среды выполнения интеграции при копировании в BLOB-объект или репозиторий ADLS 2-го поколения Azure максимальное эффективное число операций параллельного копирования равно 4 или 5 на каждый узел среды IR. – В других сценариях параметр числа операций параллельного копирования недействителен. Даже если степень параллелизма задана, она не соблюдается фактически. |
| Между нефайловыми хранилищами | – При копировании данных в Базу данных SQL Azure или Azure Cosmos DB число параллельных операций копирования по умолчанию зависит также от уровня приемника (числа DTU/RU). – При копировании данных из хранилища с поддержкой разделов (включая Базу данных SQL Azure, Управляемый экземпляр SQL Azure, Azure Synapse Analytics, Oracle, Amazon RDS для Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS для SQL Server и Teradata) параллельная копия по умолчанию — 4. – При копировании данных в таблицу Azure число параллельных операций копирования по умолчанию равно 4. |
Для регулирования нагрузки компьютеров, на которых размещены хранилища данных, или настройки производительности копирования можно переопределить заданное по умолчанию значение свойства parallelCopies. Значение должно быть целым числом больше или равно 1. Во время выполнения действия Copy для достижения наилучшей производительности выбирается значение, меньшее или равное заданному.
Задавая значение свойства parallelCopies, учитывайте повышение нагрузки на хранилище-источник и хранилище-приемник данных. Кроме того, необходимо учесть повышение нагрузки на локальную среду выполнения интеграции, если она используется для выполнения действия Copy. Это особенно актуально при наличии нескольких действий или параллельного выполнения одинаковых действий с одним и тем же хранилищем данных. Если вы замечаете, что хранилище данных или локальная среда выполнения интеграции перегружены, уменьшите значение свойства parallelCopies, чтобы снизить нагрузку.
Пример:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
промежуточное копирование
При копировании данных из хранилища-источника в хранилище-приемник можно для промежуточного хранения использовать Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения. Промежуточное хранилище очень удобно в следующих ситуациях.
- Требуется получать данные из различных хранилищ данных в Azure Synapse Analytics через PolyBase, копировать данные из Snowflake или в Snowflake, либо принимать данные из Amazon RedShift/HDFS с высокой производительностью. Дополнительные сведения см. в следующем разделе:
- В соответствии с корпоративными ИТ-политиками не рекомендуется открывать на брандмауэре какие-либо порты, кроме 80 и 443. Например, при копировании данных из локального хранилища данных в Базу данных SQL Azure или Azure Synapse Analytics необходимо разрешить исходящие TCP-подключения через порт 1433 как на брандмауэре Windows, так и на корпоративном брандмауэре. В этом случае при промежуточном копировании можно будет воспользоваться локальной средой выполнения интеграции, сначала скопировав данные в промежуточное хранилище по протоколу HTTP или HTTPS через порт 443, а уже оттуда загрузив их Базу данных SQL или Azure Synapse Analytics. В таком сценарии не нужно включать порт 1433.
- Иногда гибридное перемещение данных (т. е. копирование данных из локального в облачное хранилище данных) занимает достаточно продолжительное время из-за низкой скорости сетевого подключения. Чтобы на перемещение данных в облачное промежуточное хранилище уходило меньше времени, можно настроить сжатие данных в локальном хранилище при промежуточном копировании. Когда данные окажутся в промежуточном хранилище, их можно будет распаковать перед загрузкой в целевое хранилище данных.
Принцип промежуточного копирования
Если включено промежуточное копирование, данные сначала копируются из исходного хранилища в промежуточное (Хранилище BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения). Оттуда данные копируются в хранилище-приемник данных. При выполнении действия Copy управление этим двухэтапным процессом происходит автоматически, а когда перемещение данных завершается, временные данные автоматически удаляются из промежуточного хранилища.

Необходимо предоставить разрешение на удаление Фабрика данных Azure в промежуточном хранилище, чтобы временные данные можно было очистить после выполнения действия копирования.
При запуске перемещения данных с использованием промежуточного хранилища вы можете указать, следует ли сжимать данные перед перемещением из хранилища-источника в промежуточное хранилище, а затем распаковывать перед перемещением оттуда в хранилище-приемник данных.
В настоящее время не поддерживается копирование данных между двумя хранилищами, подключенными через разные локальные среды IR — ни с промежуточным копированием, ни без него. Для такого сценария можно настроить два действия Copy, объединив их явным образом в цепочку: в первом действии данные будут копироваться из источника в промежуточное хранилище, а во втором — из промежуточного хранилища в приемник.
Настройка
Задайте значение параметра enableStaging действия Copy, чтобы указать, следует ли копировать данные в промежуточное хранилище перед их загрузкой в хранилище-приемник данных. Если для параметра enableStaging задано значение TRUE, задайте дополнительные свойства, перечисленные в таблице ниже.
| Свойство | Описание: | Default value | Обязательное поле |
|---|---|---|---|
| enableStaging | Укажите, следует ли копировать данные в промежуточное хранилище. | False | No |
| linkedServiceName | Задайте имя службы, связанной с Хранилищем BLOB-объектов Azure или Azure Data Lake Storage 2-го поколения, т. е. имя экземпляра службы хранилища, который вы используете для промежуточного хранения. | Н/П | Да, если для параметра enableStaging задано значение true |
| path | Задайте путь, по которому должна располагаться область промежуточного хранения данных. Если не задавать путь, служба создаст контейнер для хранения временных данных. | Н/П | Нет (Да, если storageIntegration указан соединитель Snowflake) |
| enableCompression | Указывает, следует ли сжимать данные перед их копированием в место назначения. Этот параметр позволяет уменьшить объем передаваемых данных. | False | No |
Примечание.
Если вы используете промежуточное копирование со сжатием, то для службы, связанной с промежуточным хранилищем BLOB-объектов, не поддерживаются субъект-служба и проверка подлинности MSI.
Ниже приведен пример определения действия Copy со свойствами, описанными в предыдущей таблице.
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Принцип выставления счетов за промежуточное копирование
Плата с вас взимается по двум статьям: длительность копирования и тип копирования.
- Если вы используете промежуточное хранилище при облачном копировании (т. е. при копировании данных между облачными хранилищами, когда оба этапа выполняются с помощью среды выполнения интеграции Azure), плата рассчитывается по следующей формуле: [сумма длительности копирования для этапов 1 и 2] x [цена за единицу облачного копирования].
- Если вы используете промежуточное хранилище при гибридном копировании (т. е. при копировании данных из локального хранилища данных в облачное, когда один из этапов выполняется с помощью локальной среды выполнения интеграции), плата рассчитывается по следующей формуле: [длительность гибридного копирования] x [цена за единицу гибридного копирования] + [длительность облачного копирования] x [цена за единицу облачного копирования].
Связанный контент
См. другие статьи о действии копирования:
- Общие сведения о действии копирования
- Руководство по производительности и масштабируемости действия копирования
- Устранение проблем с производительностью действий копирования
- Перенос данных из озера данных или хранилища данных с помощью Фабрики данных Azure
- Перенос данных из Amazon S3 в служба хранилища Azure