Руководство. Создание приложения Scala Maven для Apache Spark в HDInsight с помощью IntelliJ
Из этого руководства вы узнаете, как создать приложение Apache Spark на языке Scala в Apache Maven с помощью IntelliJ IDEA. В примере из этой статьи в качестве системы сборки используется Apache Maven, а в качестве основы используется существующий архетип Maven для Scala, предоставляемый IntelliJ IDEA. Создание приложения Scala в IntelliJ IDEA включает в себя следующие этапы:
- использование Maven в качестве системы сборки;
- обновление файла объектной модели проектов для разрешения зависимостей модуля Spark;
- написание приложения на языке Scala;
- создание JAR-файла, который можно отправить в кластеры HDInsight Spark;
- запуск приложений с помощью Livy в кластере Spark.
В этом руководстве описано следующее:
- Установка подключаемого модуля Scala для IntelliJ IDEA
- Разработка приложения Scala Maven с помощью IntelliJ.
- Создание автономного проекта Scala
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Комплект разработчика Oracle Java. В этом руководстве используется Java версии 8.0.202.
Java IDE. В этой статье используется среда IntelliJ IDEA версии 2018.3.4.
Azure Toolkit for IntelliJ. Дополнительные сведения см. в статье Установка набора средств Azure для IntelliJ.
Установка подключаемого модуля Scala для IntelliJ IDEA
Чтобы установить подключаемый модуль Scala, сделайте следующее:
Откройте IntelliJ IDEA.
На экране приветствия выберите Configure (Настройка)>Plugins (Подключаемые модули), чтобы открыть окно подключаемых модулей.
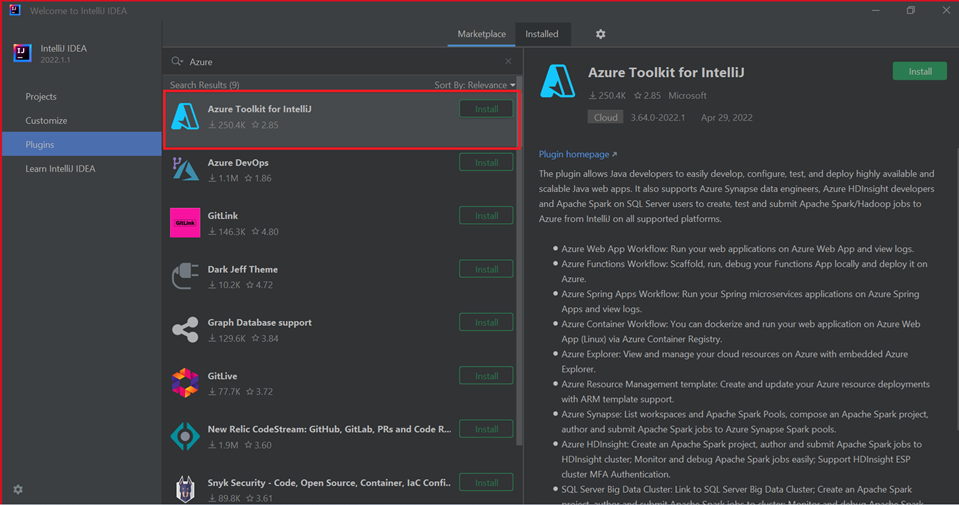
Выберите Установить для Azure Toolkit for IntelliJ.
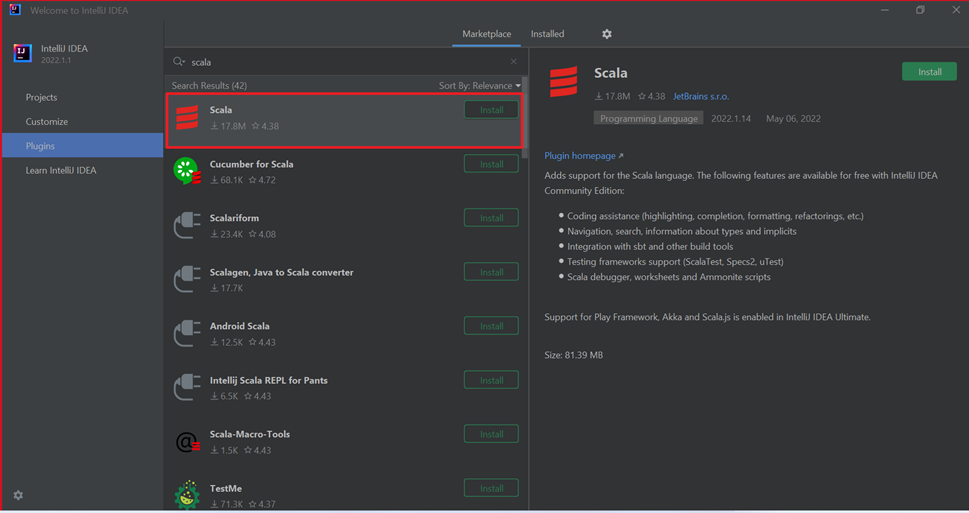
Выберите Install (Установить) в области подключаемого модуля Scala в новом окне.
После успешной установки подключаемого модуля необходимо перезапустить интегрированную среду разработки.
Создание приложения с помощью IntelliJ
Запустите IntelliJ IDEA и выберите Create New Project (Создать проект), чтобы открыть окно New Project (Новый проект).
На панели слева выберите Azure Spark/HDInsight.
В главном окне выберите Spark Project (Scala) (Проект Spark (Scala)).
Из раскрывающегося списка Build tool (Инструмент сборки) выберите одно из следующих значений:
- Maven для поддержки мастера создания проекта Scala.
- SBT для управления зависимостями и создания проекта Scala.
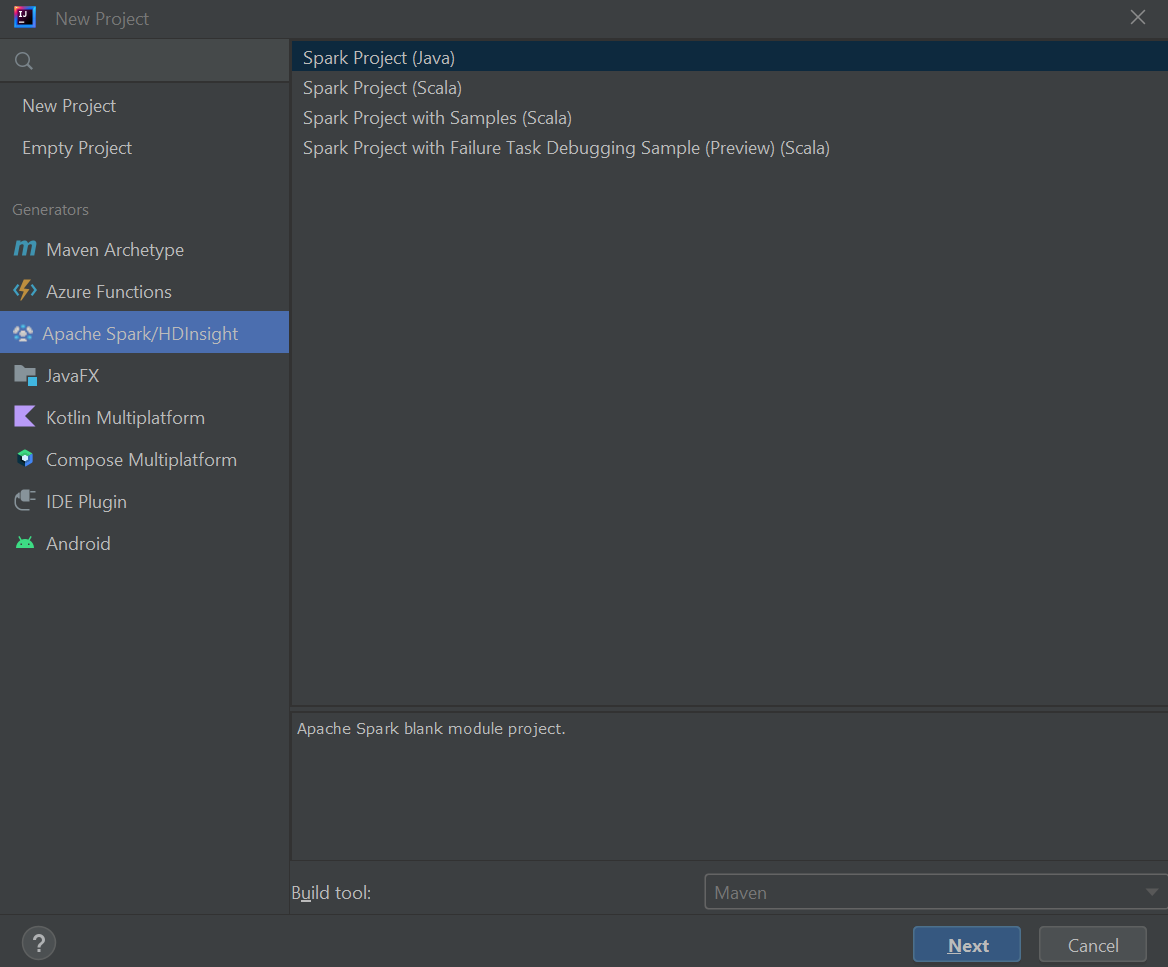
Выберите Далее.
В окне New Project (Новый проект) укажите следующую информацию:
Свойство Description Имя проекта Введите имя. Расположение проекта Введите расположение для сохранения проекта. Project SDK (Пакет SDK проекта) При первом использовании IDEA это поле будет пустым. Выберите New... (Создать...) и перейдите к JDK. Версия Spark Мастер создания интегрирует правильную версию пакетов SDK для Spark и Scala. Если используется версия кластера Spark более ранняя, чем 2.0, выберите Spark 1.x. В противном случае выберите Spark 2.x. В этом примере используется Spark 2.3.0 (Scala 2.11.8). 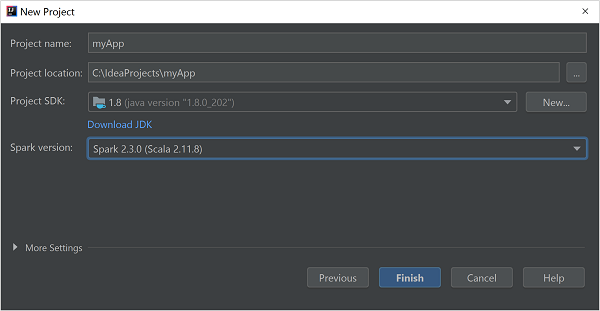
Выберите Готово.
Создание автономного проекта Scala
Запустите IntelliJ IDEA и выберите Create New Project (Создать проект), чтобы открыть окно New Project (Новый проект).
Выберите Maven в левой области.
Выберите пакет в поле Project SDK (Пакет SDK проекта). Если это поле пусто, щелкните New... (Создать...) и перейдите к каталогу установки Java.
Установите флажок Create from archetype (Создать на основе архетипа).
В списке архетипов выберите
org.scala-tools.archetypes:scala-archetype-simple. Этот архетип создает структуру каталога и скачивает зависимости по умолчанию, необходимые для написания программы Scala.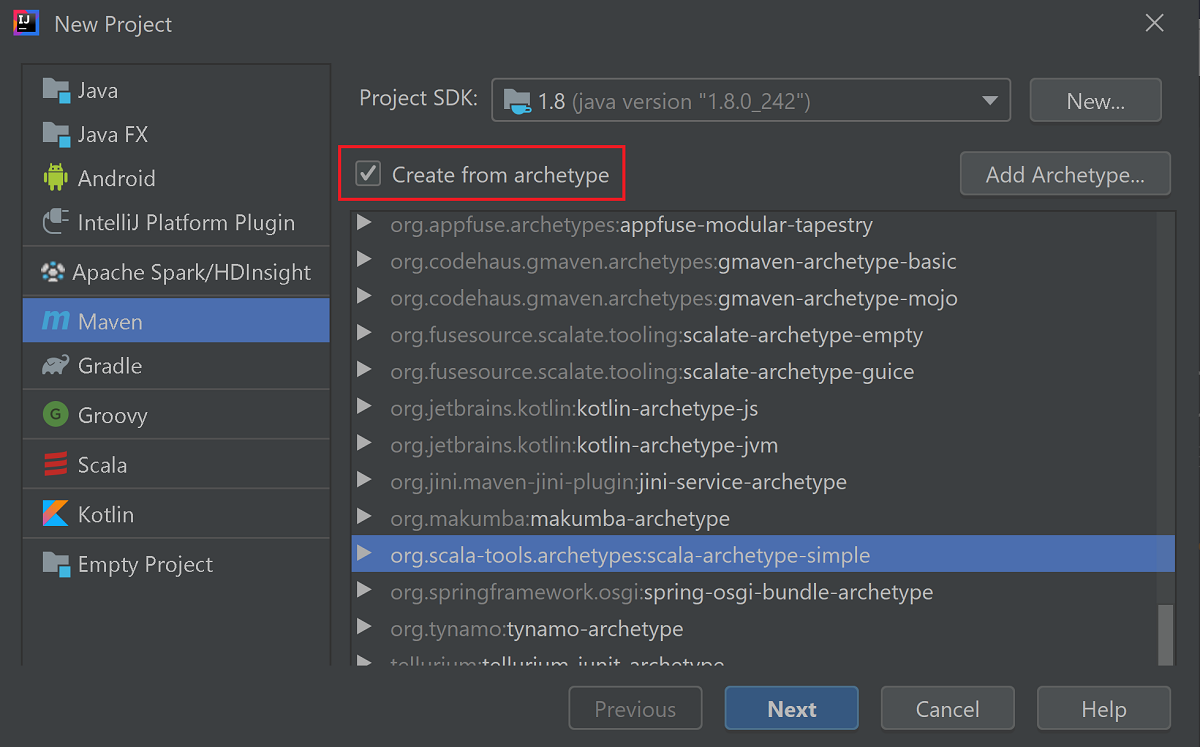
Выберите Далее.
Разверните Координаты артефакта. Введите соответствующие значения для параметров GroupId и ArtifactId. Значения Name (Имя) и Location (Расположение) заполнятся автоматически. В этом руководстве используются представленные ниже значения.
- GroupId: com.microsoft.spark.example;
- ArtifactId: SparkSimpleApp
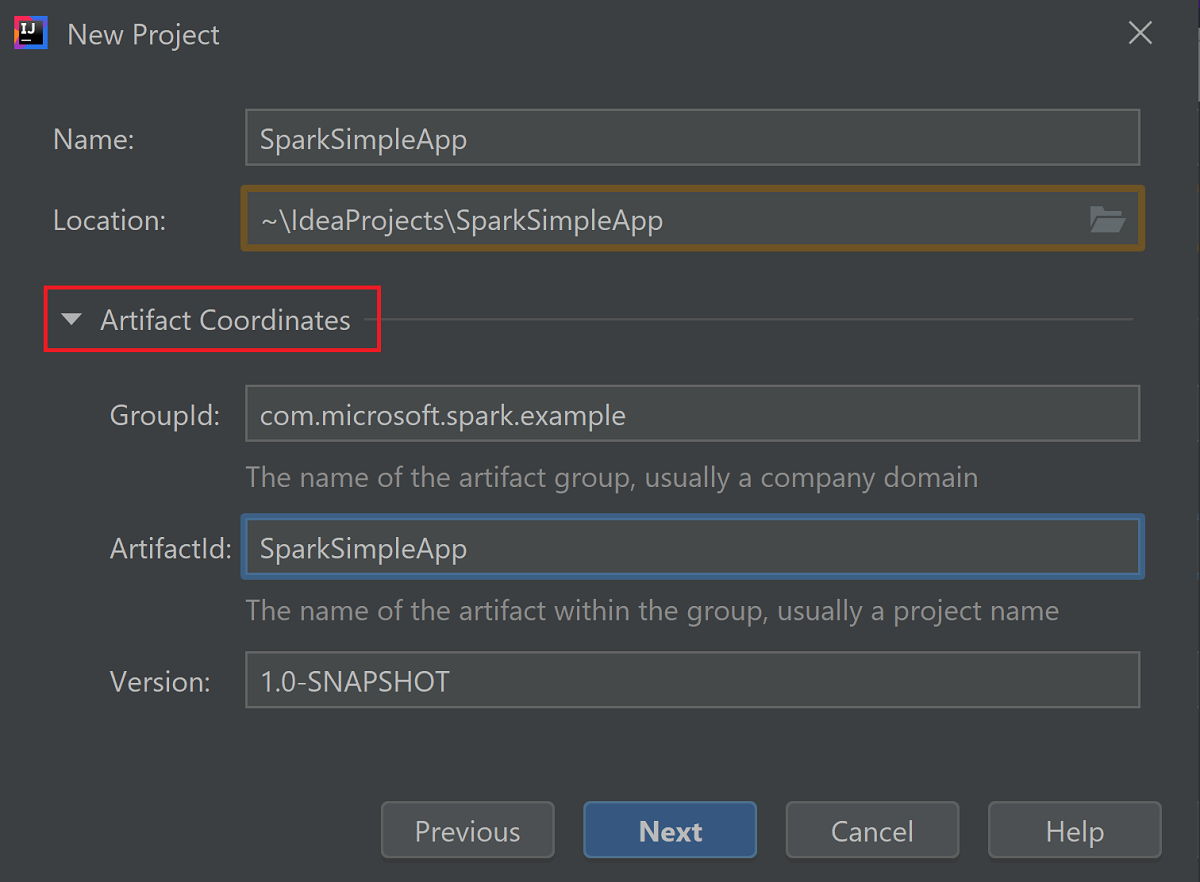
Выберите Далее.
Проверьте параметры и нажмите кнопку Next (Далее).
Проверьте имя и расположение проекта, а затем выберите Finish (Готово). Импорт этого проекта займет несколько минут.
После импорта проекта в области слева выберите SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Щелкните MySpec правой кнопкой мыши и выберите "Удалить...". Этот файл не нужен для приложения. Нажмите кнопку ОК в диалоговом окне.
На следующих шагах описывается обновление файла pom.xml для определения зависимостей приложения Spark Scala. Чтобы автоматически скачать эти зависимости и разрешить их, необходимо настроить Maven.
В меню File (Файл) выберите Settings (Параметры), чтобы открыть окно параметров.
В окне Settings (Параметры) выберите Build, Execution, Deployment (Сборка, выполнение, развертывание)>Build Tools (Средства сборки)>Maven>Importing (Импорт).
Установите флажок Import Maven projects automatically(Импортировать проекты Maven автоматически).
Нажмите кнопку Apply (Применить), а затем нажмите кнопку ОК. Затем вы вернетесь обратно в окно проекта.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::В области слева выберите src>main>scala>com.microsoft.spark.example, а затем двойным щелчком выберите App (Приложение), чтобы открыть App.scala.
Замените имеющийся пример кода кодом ниже, а затем сохраните изменения. Этот код считывает данные из файла HVAC.csv (доступного для всех кластеров Spark в HDInsight). Извлекает строки, у которых в шестом столбце только одна цифра, и записывает выходные данные в /HVACOut в контейнере хранилища по умолчанию для кластера.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }В левой области дважды щелкните pom.xml.
Добавьте следующие сегменты в файл
<project>\<properties>:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Добавьте следующие сегменты в файл
<project>\<dependencies>:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Создайте JAR-файл. IntelliJ IDEA позволяет создавать JAR-файлы в качестве артефактов проекта. Выполните следующие действия.
В меню File (Файл) выберите Project Structure... (Структура проекта...).
В окне Project Structure (Структура проекта) выберите Artifacts (Артефакты)>символ "плюс" +>JAR>From modules with dependencies... (Из модулей с зависимостями...).
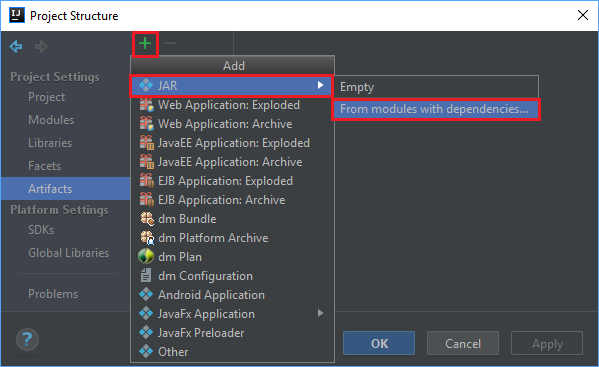
В окне Create JAR from Modules (Создание JAR-файла на основе модулей) выберите значок папки в текстовом поле Main Class (Основной класс).
В окне Select Main Class (Выбор основного класса) выберите класс, который отображается по умолчанию, и щелкните ОК.
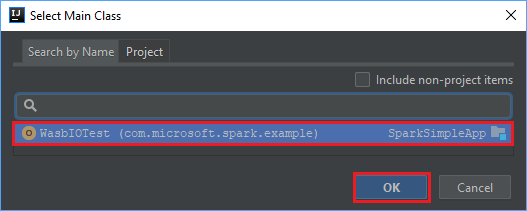
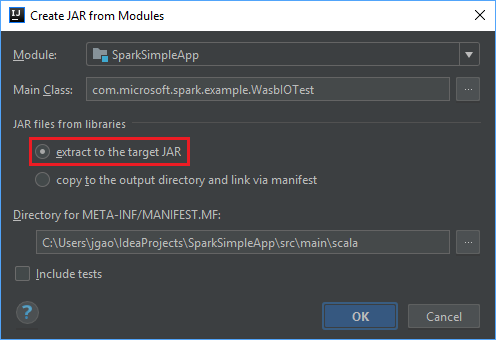
В окне Create JAR from Modules (Создание JAR-файла на основе модулей) выберите вариант extract to the target JAR (Извлечь в целевой JAR-файл) и щелкните ОК. В результате будет создан один JAR-файл, содержащий все зависимости.
На вкладке Макет выходных данных содержится список всех JAR-файлов, которые включены в проект Maven. Здесь можно выбрать и удалить файлы, от которых не зависит работа приложения Scala. Из создаваемого приложения можно удалить все файлы, кроме последнего (SparkSimpleApp compile output (Выходные данные компиляции SparkSimpleApp)). Выберите JAR-файлы, которые нужно удалить, и щелкните значок минус -.
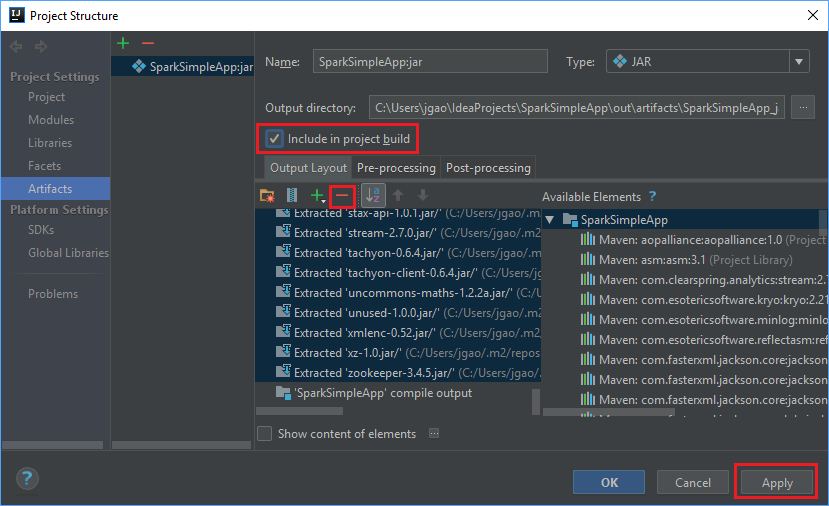
Убедитесь, что установлен флажок Include in project build (Включить в сборку проекта). Это гарантирует, что JAR-файл будет создаваться при каждом создании и обновлении проекта. Нажмите кнопку Apply (Применить), а затем — ОК.
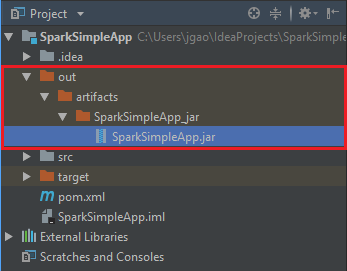
Чтобы создать JAR-файл, выберите Build (Сборка)>Build Artifacts (Артефакты сборки) >Build (Сборка). Компиляция проекта займет около 30 секунд. Выходной JAR-файл будет создан в разделе \out\artifacts.
Запуск приложения в кластере Apache Spark
Чтобы запустить приложение в кластере, можно использовать следующие методы:
Скопируйте приложение JAR в большой двоичный объект службы хранилища Azure, связанный с кластером. Вы можете использовать для этого служебную программу командной строки AzCopy. Кроме того, для отправки данных можно использовать множество других клиентов. Дополнительные сведения о них см. в статье Отправка данных для заданий Apache Hadoop в HDInsight.
Используйте Apache Livy для удаленной отправки задания приложения в кластер Spark. В кластерах HDInsight Spark есть сервер Livy, который использует конечные точки REST для удаленной отправки заданий Spark. Дополнительные сведения см. в статье об удаленной отправке заданий Apache Spark с помощью Apache Livy и кластеров Spark в HDInsight .
Очистка ресурсов
Если вы не собираетесь использовать это приложение в дальнейшем, удалите созданный кластер, сделав следующее:
Войдите на портал Azure.
В поле Поиск в верхней части страницы введите HDInsight.
Выберите Кластеры HDInsight в разделе Службы.
В списке кластеров HDInsight, который отобразится, выберите ... рядом с кластером, созданным при работе с этим учебником.
Выберите команду Удалить. Выберите Да.
Следующий шаг
Из этой статьи вы узнали, как создать приложение Apache Spark на языке Scala. Из следующей статьи вы узнаете, как запустить это приложение на кластере HDInsight Spark, используя Livy.