Анализ журналов веб-сайтов с помощью пользовательской библиотеки Python и кластера Apache Spark в HDInsight
Данная записная книжка показывает, как анализировать данные журналов с помощью настраиваемой библиотеки с кластером Apache Spark в HDInsight. В качестве пользовательской библиотеки используется библиотека Python с именем iislogparser.py.
Необходимые компоненты
Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
Сохранение необработанных данных в формате RDD
В этом разделе мы используем записную книжку Jupyter, связанную с кластером Apache Spark в HDInsight, для выполнения заданий, которые обрабатывают необработанные демонстрационные данные и сохраняют их как таблицу Hive. В качестве демонстрационных данных выступает CSV-файл (hvac.csv), доступный на всех кластерах по умолчанию.
После сохранения данных в виде таблицы Apache Hive можно переходить к следующему разделу и подключиться к таблице Hive с помощью средств бизнес-аналитики, таких как Power BI и Tableau.
В веб-браузере перейдите на страницу
https://CLUSTERNAME.azurehdinsight.net/jupyter, гдеCLUSTERNAME— это имя вашего кластера.Создайте новую записную книжку. Выберите команду Создать, а затем — пункт PySpark.
 Notebook" border="true":::
Notebook" border="true":::Будет создана и открыта записная книжка с именем Untitled.pynb. Выберите имя записной книжки в верхней части страницы и введите понятное имя.
Так как записная книжка была создана с помощью ядра PySpark, задавать контексты явно необязательно. Контексты Spark и Hive будут созданы автоматически при выполнении первой ячейки кода. Можно начать с импорта различных типов, необходимых для этого сценария. Вставьте следующий фрагмент кода в пустую ячейку и нажмите клавиши Shift + Ввод.
from pyspark.sql import Row from pyspark.sql.types import *Создайте RDD, используя пример данных журнала, уже доступных в кластере. Данные учетной записи хранения по умолчанию, связанной с кластером, доступны по адресу
\HdiSamples\HdiSamples\WebsiteLogSampleData\SampleLog\909f2b.log. Выполните следующий код.logs = sc.textFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b.log')Извлеките пример набора журналов и убедитесь в том, что описанный выше шаг успешно выполнен.
logs.take(5)Должен отобразиться результат, аналогичный приведенному ниже:
[u'#Software: Microsoft Internet Information Services 8.0', u'#Fields: date time s-sitename cs-method cs-uri-stem cs-uri-query s-port cs-username c-ip cs(User-Agent) cs(Cookie) cs(Referer) cs-host sc-status sc-substatus sc-win32-status sc-bytes cs-bytes time-taken', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32', u'2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step4.png X-ARR-LOG-ID=4bea5b3d-8ac9-46c9-9b8c-ec3e9500cbea 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 72177 871 47']
Анализ данных журнала с помощью пользовательской библиотеки Python
В приведенном выше примере выходных данных первые несколько строк содержат сведения о заголовке, а все последующие строки соответствуют схеме, описанной в этом заголовке. Анализ таких журналов может быть сложным, поэтому мы используем настраиваемую библиотеку Python (iislogparser.py), которая делает эту задачу намного проще. По умолчанию эта библиотека включена в кластер Spark в HDInsight по адресу
/HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py.Однако в
PYTHONPATHэта библиотека не входит, поэтому использовать ее с помощью такого оператора импорта, какimport iislogparser, нельзя. Чтобы использовать эту библиотеку, необходимо распространить ее на все рабочие узлы. Выполните следующий фрагмент кода.sc.addPyFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/iislogparser.py')iislogparserпредоставляет функциюparse_log_line, которая возвращаетNone, если строка журнала является строкой заголовка, или экземпляр классаLogLineпри обнаружении строки журнала. КлассLogLineпозволяет извлечь только строки журнала из RDD:def parse_line(l): import iislogparser return iislogparser.parse_log_line(l) logLines = logs.map(parse_line).filter(lambda p: p is not None).cache()Выведите на экран несколько извлеченных строк журнала и убедитесь в том, что это действие выполнено успешно.
logLines.take(2)Должен быть получен примерно такой результат:
[2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step2.png X-ARR-LOG-ID=2ec4b8ad-3cf0-4442-93ab-837317ece6a1 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 53175 871 46, 2014-01-01 02:01:09 SAMPLEWEBSITE GET /blogposts/mvc4/step3.png X-ARR-LOG-ID=9eace870-2f49-4efd-b204-0d170da46b4a 80 - 1.54.23.196 Mozilla/5.0+(Windows+NT+6.3;+WOW64)+AppleWebKit/537.36+(KHTML,+like+Gecko)+Chrome/31.0.1650.63+Safari/537.36 - http://weblogs.asp.net/sample/archive/2007/12/09/asp-net-mvc-framework-part-4-handling-form-edit-and-post-scenarios.aspx www.sample.com 200 0 0 51237 871 32]В свою очередь, класс
LogLineвключает несколько полезных методов, например методis_error(), который возвращается, если запись журнала содержит код ошибки. С помощью этого класса вы можете вычислить количество ошибок в извлеченных строках журналов, а затем записать все ошибки в отдельный файл.errors = logLines.filter(lambda p: p.is_error()) numLines = logLines.count() numErrors = errors.count() print 'There are', numErrors, 'errors and', numLines, 'log entries' errors.map(lambda p: str(p)).saveAsTextFile('wasbs:///HdiSamples/HdiSamples/WebsiteLogSampleData/SampleLog/909f2b-2.log')Результат должен выглядеть следующим образом:
There are 30 errors and 646 log entries.Кроме того, для визуализации данных вы можете использовать Matplotlib . Например, если вы хотите установить причину длительного выполнения некоторых запросов, найдите файлы с наибольшим средним временем обработки. Код в представленном ниже фрагменте выдает первые 25 ресурсов с максимальным временем обработки запросов.
def avgTimeTakenByKey(rdd): return rdd.combineByKey(lambda line: (line.time_taken, 1), lambda x, line: (x[0] + line.time_taken, x[1] + 1), lambda x, y: (x[0] + y[0], x[1] + y[1]))\ .map(lambda x: (x[0], float(x[1][0]) / float(x[1][1]))) avgTimeTakenByKey(logLines.map(lambda p: (p.cs_uri_stem, p))).top(25, lambda x: x[1])Должны отобразиться подобные выходные данные:
[(u'/blogposts/mvc4/step13.png', 197.5), (u'/blogposts/mvc2/step10.jpg', 179.5), (u'/blogposts/extractusercontrol/step5.png', 170.0), (u'/blogposts/mvc4/step8.png', 159.0), (u'/blogposts/mvcrouting/step22.jpg', 155.0), (u'/blogposts/mvcrouting/step3.jpg', 152.0), (u'/blogposts/linqsproc1/step16.jpg', 138.75), (u'/blogposts/linqsproc1/step26.jpg', 137.33333333333334), (u'/blogposts/vs2008javascript/step10.jpg', 127.0), (u'/blogposts/nested/step2.jpg', 126.0), (u'/blogposts/adminpack/step1.png', 124.0), (u'/BlogPosts/datalistpaging/step2.png', 118.0), (u'/blogposts/mvc4/step35.png', 117.0), (u'/blogposts/mvcrouting/step2.jpg', 116.5), (u'/blogposts/aboutme/basketball.jpg', 109.0), (u'/blogposts/anonymoustypes/step11.jpg', 109.0), (u'/blogposts/mvc4/step12.png', 106.0), (u'/blogposts/linq8/step0.jpg', 105.5), (u'/blogposts/mvc2/step18.jpg', 104.0), (u'/blogposts/mvc2/step11.jpg', 104.0), (u'/blogposts/mvcrouting/step1.jpg', 104.0), (u'/blogposts/extractusercontrol/step1.png', 103.0), (u'/blogposts/sqlvideos/sqlvideos.jpg', 102.0), (u'/blogposts/mvcrouting/step21.jpg', 101.0), (u'/blogposts/mvc4/step1.png', 98.0)]Кроме того, эти сведения вы можете представить в виде графика. Чтобы создать график, для начала создадим временную таблицу AverageTime. Таблица группирует журналы по времени и показывает все необычные пики задержек за определенный период времени.
avgTimeTakenByMinute = avgTimeTakenByKey(logLines.map(lambda p: (p.datetime.minute, p))).sortByKey() schema = StructType([StructField('Minutes', IntegerType(), True), StructField('Time', FloatType(), True)]) avgTimeTakenByMinuteDF = sqlContext.createDataFrame(avgTimeTakenByMinute, schema) avgTimeTakenByMinuteDF.registerTempTable('AverageTime')После этого можно выполнить следующий запрос SQL, чтобы получить все записи таблицы AverageTime .
%%sql -o averagetime SELECT * FROM AverageTimeВолшебное слово
%%sql, за которым следует-o averagetime, гарантирует, что вывод запроса сохраняется локально на сервере Jupyter (обычно это головной узел кластера). Выходные данные сохраняются в кадре данных Pandas с именем averagetime.Вы должны увидеть подобные выходные данные:
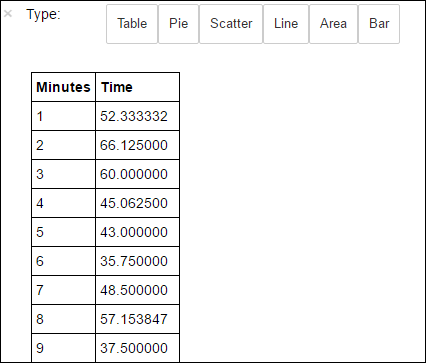 yter sql query output" border="true":::
yter sql query output" border="true":::Дополнительные сведения о магической команде
%%sqlсм. в разделе Параметры, поддерживаемые волшебной командой %%sql.Теперь можно создать график с помощью Matplotlib, библиотеки, используемой для визуализации данных. Так как диаграмма должна создаваться из локально сохраненного кадра данных averagetime, фрагмент кода должен начинаться с волшебного слова
%%local. Это гарантирует, что код будет выполняться локально на сервере Jupyter.%%local %matplotlib inline import matplotlib.pyplot as plt plt.plot(averagetime['Minutes'], averagetime['Time'], marker='o', linestyle='--') plt.xlabel('Time (min)') plt.ylabel('Average time taken for request (ms)')Вы должны увидеть подобные выходные данные:
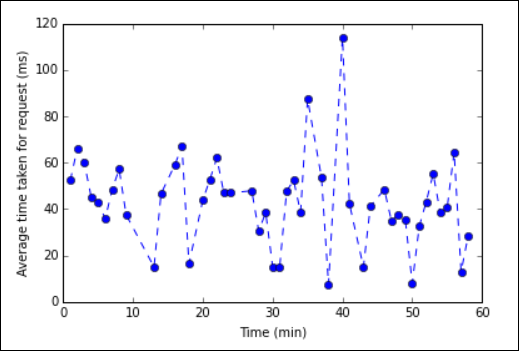 График анализа журналов eb" border="true":::
График анализа журналов eb" border="true":::Завершив работу с приложением, следует закрыть записную книжку, чтобы освободить ресурсы. Для этого в меню File (Файл) записной книжки выберите пункт Close and Halt (Закрыть и остановить). Это действие завершает работу записной книжки и закрывает ее.
Следующие шаги
Ознакомьтесь со следующими статьями: