Use Apache Zeppelin notebooks with Apache Spark cluster on Azure HDInsight (Использование записных книжек Apache Zeppelin с кластером Apache Spark в Azure HDInsight)
Кластеры HDInsight Spark включают в себя записные книжки Apache Zeppelin. Используйте записные книжки для запуска заданий Apache Spark. Из этой статьи вы узнаете, как использовать записную книжку Zeppelin в кластере HDInsight.
Необходимые компоненты
- Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark.
- Схема универсального кода ресурса (URI) для основного хранилища кластеров. Для службы хранилища BLOB-объектов этой схемой будет
wasb://, для Azure Data Lake Storage 2-го поколения —abfs://илиadl://для Azure Data Lake Storage 1-го поколения. Если для службы хранилища BLOB-объектов включено безопасное перемещение, URI будет таким:wasbs://. Дополнительные сведения см. в статье Обязательное безопасное перемещение в службе хранилища Azure.
Запуск записной книжки Apache Zeppelin
В разделе Обзор кластера Spark выберите Записная книжка Zeppelin в разделе Панели мониторинга кластера. Введите учетные данные администратора для кластера.
Примечание.
Также можно открыть Zeppelin Notebook для своего кластера, открыв следующий URL-адрес в браузере. Замените CLUSTERNAME именем кластера:
https://CLUSTERNAME.azurehdinsight.net/zeppelinСоздайте новую записную книжку. На панели заголовка перейдите в раздел Записная книжка>Создать новую заметку.

Введите имя для записной книжки и щелкните Создать заметку.
Убедитесь, что в заголовке записной книжки отображается состояние "Подключено". Оно обозначается зеленой точкой в правом верхнем углу.
Загрузите демонстрационные данные во временную таблицу. При создании кластера Spark в HDInsight файл с демонстрационными данными
hvac.csvкопируется в связанную учетную запись хранения по следующему пути:\HdiSamples\SensorSampleData\hvac.В пустой абзац, созданный по умолчанию в новой записной книжке, вставьте следующий фрагмент кода.
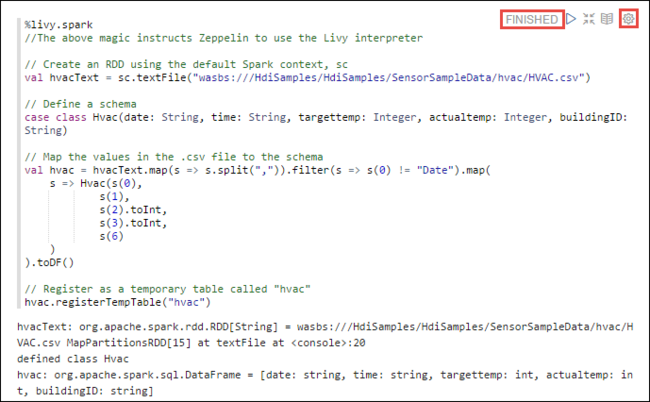
%livy2.spark //The above magic instructs Zeppelin to use the Livy Scala interpreter // Create an RDD using the default Spark context, sc val hvacText = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") // Define a schema case class Hvac(date: String, time: String, targettemp: Integer, actualtemp: Integer, buildingID: String) // Map the values in the .csv file to the schema val hvac = hvacText.map(s => s.split(",")).filter(s => s(0) != "Date").map( s => Hvac(s(0), s(1), s(2).toInt, s(3).toInt, s(6) ) ).toDF() // Register as a temporary table called "hvac" hvac.registerTempTable("hvac")Нажмите клавиши SHIFT + ВВОД или кнопку Воспроизведение для абзаца, чтобы выполнить фрагмент кода. Состояние, которое отображается в правом верхнем углу абзаца, должно изменяться в следующей последовательности: READY (ГОТОВО), PENDING (ОЖИДАЕТ), RUNNING (ВЫПОЛНЯЕТСЯ) и FINISHED (ЗАВЕРШЕНО). Выходные данные отображаются в нижней части того же абзаца. Снимок экрана выглядит следующим образом.
Можно указать заголовок для каждого абзаца. В правом углу абзаца нажмите на значок параметров (звездочка), а затем щелкните Показать заголовок.
Примечание.
Интерпретатор %spark2 не поддерживается в блокнотах Zeppelin во всех версиях HDInsight, а интерпретатор %sh не поддерживается в HDInsight версии 4.0 и выше.
Теперь вы можете выполнить инструкции Spark SQL для таблицы
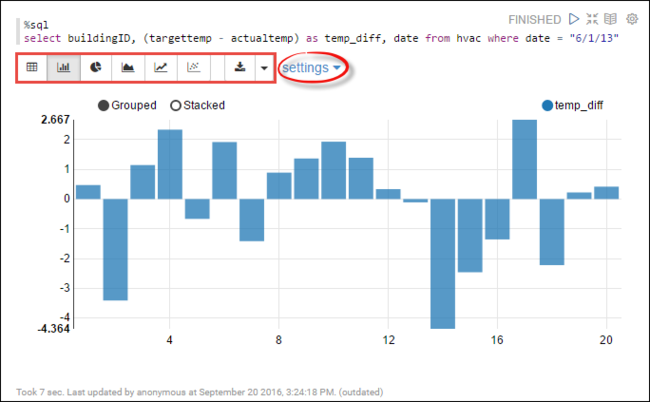
hvac. Вставьте следующий запрос в новый абзац. Запрос извлекает идентификатор здания, а также разницу между целевой и фактической температурами для каждого здания в указанный день. Нажмите SHIFT + ВВОД.%sql select buildingID, (targettemp - actualtemp) as temp_diff, date from hvac where date = "6/1/13"Инструкция %sql в начале сообщает записной книжке, что необходимо использовать интерпретатор Livy Scala.
Щелкните значок линейчатой диаграммы, чтобы изменить режим отображения. Параметры отображаются после выбора линейчатой диаграммы, что позволяет выбирать ключи и значения. Выходные данные показаны на снимке экрана ниже.
Можно также запустить инструкции Spark SQL с помощью переменных в запросе. В следующем фрагменте кода показано, как определить переменную
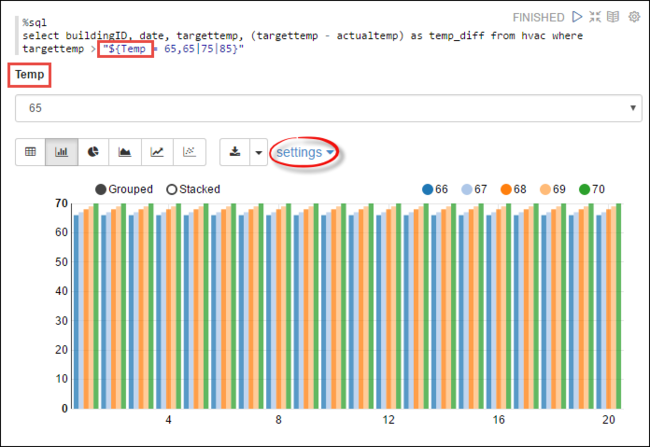
Tempв запросе с возможными значениями, с которыми необходимо выполнить запрос. При первом выполнении запроса раскрывающийся список автоматически заполняется значениями, указанными для переменной.%sql select buildingID, date, targettemp, (targettemp - actualtemp) as temp_diff from hvac where targettemp > "${Temp = 65,65|75|85}"Вставьте этот фрагмент кода в новый абзац и нажмите клавиши SHIFT + ВВОД. Затем выберите 65 в раскрывающемся списке Темп..
Щелкните значок линейчатой диаграммы, чтобы изменить режим отображения. Затем выберите Параметры и внесите следующие изменения.
Группы. Добавьте targettemp.
Значения: 1. Удалите date. 2. Добавьте temp_diff. 3. Измените агрегатор с SUM на AVG.
Выходные данные показаны на снимке экрана ниже.
Использование внешних пакетов с записной книжкой
Записная книжка Zeppelin в кластере Apache Spark в HDInsight может использовать внешние, предоставленные сообществом пакеты, которые не включены в кластер. Полный список доступных пакетов можно найти в репозитории Maven. Его также можно получить из других источников. Например, полный список предоставленных сообществом пакетов можно найти в разделе Пакеты Spark.
В этой статье показано, как использовать пакет spark-csv с Jupyter Notebook.
Откройте параметры интерпретатора. В правом верхнем углу щелкните имя вошедшего в систему пользователя и выберите Интерпретатор.
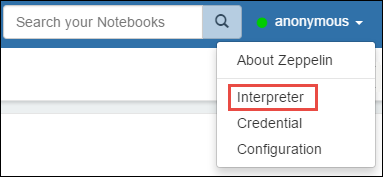
Прокрутите до livy2, а затем выберите Изменить.
Перейдите к ключу
livy.spark.jars.packagesи задайте его значение в форматеgroup:id:version. Если вы хотите использовать пакет spark-csv, для ключа необходимо задать значениеcom.databricks:spark-csv_2.10:1.4.0.
Нажмите кнопку Сохранить, а затем OK, чтобы перезапустить интерпретатор Livy.
Вот как можно получить значение указанного выше ключа.
a. Найдите пакет в репозитории Maven. В этой статье мы использовали spark-csv.
b. В репозитории найдите значения для параметров GroupId, ArtifactId и Version.
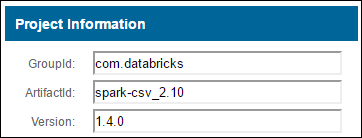
c. Объедините три значения, разделив их двоеточием (:).
com.databricks:spark-csv_2.10:1.4.0
Место сохранения записных книжек Zeppelin
Записные книжки Zeppelin сохраняются на головных узлах кластера. Поэтому при удалении кластера записные книжки также будут удалены. Если вы хотите сохранить записные книжки для последующего использования в других кластерах, необходимо экспортировать их после выполнения заданий. Чтобы экспортировать записную книжку, щелкните значок Экспорт, как показано на рисунке ниже.

Это действие сохраняет записную книжку в формате JSON в расположение для скачивания.
Примечание.
В HDI 4.0 путь к каталогу записной книжки zeppelin имеет следующий вид:
/usr/hdp/<version>/zeppelin/notebook/<notebook_session_id>/Например, /usr/hdp/4.1.17.10/zeppelin/2JMC9BZ8X/
Где как в HDI 5.0 и выше этот путь отличается
/usr/hdp/<version>/zeppelin/notebook/<Kernel_name>/Например, /usr/hdp/5.1.4.5/zeppelin/notebook/Scala/
Имя файла, хранящееся, отличается в HDI 5.0. Он хранится как
<notebook_name>_<sessionid>.zplnНапример, testzeppelin_2JJK53XQA.zpln
В HDI 4.0 имя файла только note.json хранится в каталоге session_id.
Например, /2JMC9BZ8X/note.json
HDI Zeppelin всегда сохраняет записную книжку в пути
/usr/hdp/<version>/zeppelin/notebook/к локальному диску hn0.Если вы хотите, чтобы записная книжка была доступна даже после удаления кластера, можно попытаться использовать хранилище файлов Azure (с помощью протокола S МБ) и связать его с локальным путем. Дополнительные сведения см. в статье "Подключение S МБ общую папку Azure в Linux"
После подключения вы можете изменить конфигурацию zeppelin.notebook.dir на подключенный путь в пользовательском интерфейсе Ambari.
- Файловый ресурс S МБ как хранилище GitNotebookRepo не рекомендуется для zeppelin версии 0.10.1
Использование Shiro для настройки доступа к интерпретаторам Zeppelin в кластерах с Корпоративным пакетом безопасности (ESP)
Как отмечалось выше, интерпретатор %sh не поддерживается в версии HDInsight 4.0 и выше. Более того, поскольку интерпретатор %sh создает потенциальные проблемы безопасности, такие как файлы доступа keytab с помощью команд оболочки, он также был удален из кластеров ESP HDInsight 3.6. Это означает, что интерпретатор %sh недоступен при нажатии кнопки Создать новую заметку или в пользовательском интерфейсе интерпретатора по умолчанию.
Пользователи привилегированного домена могут использовать файл Shiro.ini для управления доступом к пользовательскому интерфейсу интерпретатора. Только эти пользователи могут создавать новые интерпретаторы %sh и устанавливать разрешения для каждого нового интерпретатора %sh. Чтобы управлять доступом с помощью файла shiro.ini, выполните следующие действия.
Определите новую роль, используя существующее имя группы домена. В следующем примере
adminGroupName— это группа привилегированных пользователей в AAD. Не используйте в имени группы специальные символы и пробелы. Символы после=предоставляют разрешения для этой роли.*означает, что группа имеет все разрешения.[roles] adminGroupName = *Добавьте новую роль для доступа к интерпретаторам Zeppelin. В следующем примере всем пользователям в
adminGroupNameпредоставляется доступ к интерпретаторам Zeppelin, и они могут создавать новые интерпретаторы. Можно разместить несколько ролей в скобках вroles[], разделяя их запятыми. Затем пользователи, имеющие необходимые разрешения, могут получить доступ к интерпретаторам Zeppelin.[urls] /api/interpreter/** = authc, roles[adminGroupName]
Пример shiro.ini для нескольких групп доменов:
[main]
anyofrolesuser = org.apache.zeppelin.utils.AnyOfRolesUserAuthorizationFilter
[roles]
group1 = *
group2 = *
group3 = *
[urls]
/api/interpreter/** = authc, anyofrolesuser[group1, group2, group3]
Управление сеансом Livy
При выполнении первого абзаца кода в записной книжке Zeppelin в кластере HDInsight Spark создается новый сеанс Livy. Этот сеанс будет общим в записных книжках Zeppelin, которые вы создадите позже. Если по какой-либо причине сеанс Livy будет прерван, задания не будут выполняться из записной книжки Zeppelin.
В этом случае перед началом выполнения заданий из записной книжки Zeppelin необходимо сделать следующее.
Перезапустите интерпретатор Livy из записной книжки Zeppelin. Для этого откройте параметры интерпретатора: щелкните имя вошедшего в систему пользователя в правом верхнем углу и нажмите кнопку Интерпретатор.
Прокрутите до livy2, а затем выберите перезапустить.
Запустите ячейку кода из имеющейся записной книжки Zeppelin. Этот код создает сеанс Livy в кластере HDInsight.
Общая информация
Проверка службы
Чтобы проверить службу из Ambari, перейдите в https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, где CLUSTERNAME — имя вашего кластера.
Чтобы проверить службу из командной строки, подключитесь к головному узлу по протоколу SSH. Переключитесь на пользователя Zeppelin с помощью команды sudo su zeppelin. Команды состояния:
| Команда | Description |
|---|---|
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh status |
Состояние службы. |
/usr/hdp/current/zeppelin-server/bin/zeppelin-daemon.sh --version |
Версия службы. |
ps -aux | grep zeppelin |
Определите PID. |
Журнал местоположений
| Service | Путь |
|---|---|
| zeppelin-server | /usr/hdp/current/zeppelin-server/ |
| Журналы сервера | /var/log/zeppelin |
Интерпретатор конфигурации, Shirosite.xml, log4j |
/usr/hdp/current/zeppelin-server/conf или /etc/zeppelin/conf |
| Каталог PID | /var/run/zeppelin |
Включение ведения журнала отладки
Перейдите по адресу
https://CLUSTERNAME.azurehdinsight.net/#/main/services/ZEPPELIN/summary, где CLUSTERNAME — это имя вашего кластера.Перейдите в раздел CONFIGS>Advanced zeppelin-log4j-properties>log4j_properties_content.
Измените
log4j.appender.dailyfile.Threshold = INFOнаlog4j.appender.dailyfile.Threshold = DEBUG.Добавьте
log4j.logger.org.apache.zeppelin.realm=DEBUG.Сохраните изменения и перезапустите службу.