Импорт компонента данных
В этой статье описывается компонент в конструкторе Машинного обучения Azure.
Этот компонент используется для загрузки данных в конвейер машинного обучения из существующих облачных служб данных.
Примечание.
Все функциональные возможности этого компонента доступны в хранилище данных и наборах данных на целевой странице рабочей области. Мы рекомендуем использовать хранилище данных и набор данных, который предоставляет дополнительные функции, например мониторинг данных. Дополнительные сведения см. в статьях о том, как получить доступ к данным и как зарегистрировать наборы данных. После регистрации набора данных он отобразится в категории Наборы данных->Мои наборы данных в интерфейсе конструктора. Этот компонент предназначен для пользователей Студии машинного обучения (классическая) и позволяет работать в привычном интерфейсе.
Компонент Импорт данных поддерживает чтение данных из следующих источников:
- URL-адрес по протоколу HTTP;
- Облачные хранилища Azure через хранилища данных)
- контейнер BLOB-объектов Azure;
- Общая папка Azure
- Azure Data Lake
- Azure Data Lake 2-го поколения
- База данных SQL Azure
- Azure PostgreSQL
Прежде чем использовать облачное хранилище, сначала необходимо зарегистрировать хранилище данных в рабочей области Машинного обучения Azure. Дополнительные сведения см. в статье о получении доступа к данным.
Когда вы определите нужные данные и настроите подключение к источнику, Импорт данных автоматически выведет тип данных каждого столбца по содержащимся в нем значениям и загрузит эти данные в конвейер конструктора. Выходные данные модуля Импорт данных представляют собой набор данных, который можно использовать с любым конвейером конструктора.
При изменении исходных данных можно обновить набор данных и добавить новые данные путем повторного выполнения импорта данных.
Предупреждение
Если рабочая область находится в виртуальной сети, необходимо настроить в хранилищах данных использование предоставленных конструктором возможностей визуализации. Дополнительные сведения об использовании хранилищ и наборов данных в виртуальной сети см. в статье Использование Студии машинного обучения Azure в виртуальной сети Azure.
Как настроить импорт данных
Добавьте компонент Импорт данных в конвейер. Этот компонент находится в категории Ввод и вывод данных в конструкторе.
Выберите компонент, чтобы открыть область справа.
Щелкните Источник данных и выберите тип источника данных. Это может быть HTTP или хранилище данных.
В качестве хранилища данных можно указать существующие и уже зарегистрированные в рабочей области Машинного обучения Azure хранилища данных или создать новое хранилище данных. Затем определите путь к данным для импорта в хранилище данных. Можно легко просмотреть путь, выбрав Обзор пути.

Примечание.
Компонент Импорт данных предназначен только для табличных данных. Если вам нужно однократно импортировать несколько файлов с табличными данными, должны соблюдаться приведенные ниже условия. В противном случае операция завершится ошибкой.
- Чтобы включить все файлы данных в одной папке, введите значение
folder_name/**для параметра Путь. - Все файлы данных должны иметь кодировку Юникода unicode-8.
- Все файлы данных должны иметь одинаковое количество и одинаковые имена столбцов.
- При импорте нескольких файлов данных все строки из этих файлов по порядку сцепляются в один набор.
- Чтобы включить все файлы данных в одной папке, введите значение
Выберите схему предварительного просмотра, чтобы отфильтровать нужные столбцы. Можно также определить в параметрах анализа дополнительные параметры, например разделитель.
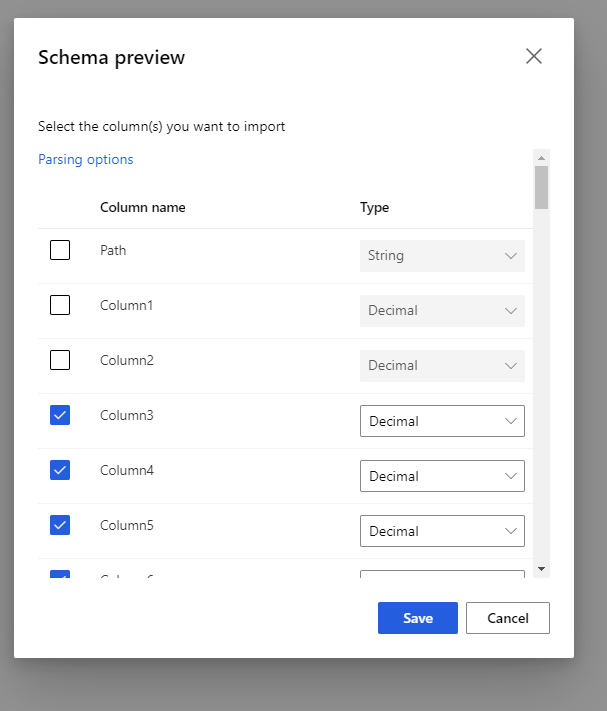
Флажок Повторно создать выходные данные определяет, следует ли запускать компонент для повторного создания выходных данных во время выполнения.
По умолчанию этот флажок не установлен. Если компонент выполнялся с теми же параметрами ранее, для сокращения времени выполнения система применит выходные данные из предыдущего запуска.
Если флажок установлен, система снова выполнит компонент для повторного создания выходных данных. Обязательно включите этот параметр, чтобы получать актуальные данные, если базовые данные в хранилище часто обновляются.
Отправьте конвейер.
Когда модуль "Импорт данных" загружает данные в конструктор, он выводит тип данных для каждого столбца на основе содержащихся в нем значений (различают числовой и категорийный типы).
Если заголовок присутствует, заголовок используется для имени столбцов выходного набора данных.
Если в данных не указаны заголовки столбцов, им присваиваются вновь созданные имена в формате col1, col2, … , coln*.

Результаты
После завершения импорта щелкните правой кнопкой мыши выходной набор данных и выберите Visualize (Визуализировать), чтобы проверить успешность операции импорта.
Если вы хотите сохранить данные для повторного использования, чтобы не импортировать новый набор данных при каждом запуске конвейера, щелкните значок Зарегистрировать набор данных на вкладке Выходные данные и журналы на правой панели окна компонента. Выберите имя для набора данных. Сохраненный набор данных сохраняет данные во время сохранения. Набор данных не обновляется при повторном запуске конвейера, даже если набор данных в конвейере изменяется. Это может быть полезно для создания моментальных снимков данных.
После импорта данных может потребоваться некоторая дополнительная подготовка к моделированию и анализу:
Модуль Изменение метаданных позволяет изменить имена столбцов, применить к столбцу другой тип данных или указать, что некоторые столбцы являются метками или признаками.
Модуль Выбор столбцов в наборе данных позволяет выбрать подмножество столбцов для преобразования или использования в моделировании. Преобразованные или удаленные столбцы можно легко присоединить обратно к исходному набору данных с помощью компонента Добавление столбцов.
Модуль Секционирование и выборка для разделения набора данных, получения выборки или первых n строк.
Ограничения
Из-за ограничений доступа к хранилищу данных в случае, если конвейер вывода содержит компонент Импорт данных, при развертывании на конечной точке для прогнозирования в реальном времени он будет автоматически удален.
Следующие шаги
Ознакомьтесь с набором доступных компонентов для машинного обучения Azure.