Основные понятия набора навыков в поиске ИИ Azure
Эта статья предназначена для разработчиков, которые нуждаются в более глубоком понимании концепций набора навыков и композиции, и предполагает знакомство с высокоуровневыми понятиями примененного ИИ в поиске ИИ Azure.
Набор навыков — это многократно используемый объект в поиске ИИ Azure, подключенный к индексатору. Он содержит один или несколько навыков, которые вызывают встроенный ИИ или внешнюю пользовательскую обработку документов, полученных из внешнего источника данных.
На следующей схеме показан базовый поток данных выполнения набора навыков.
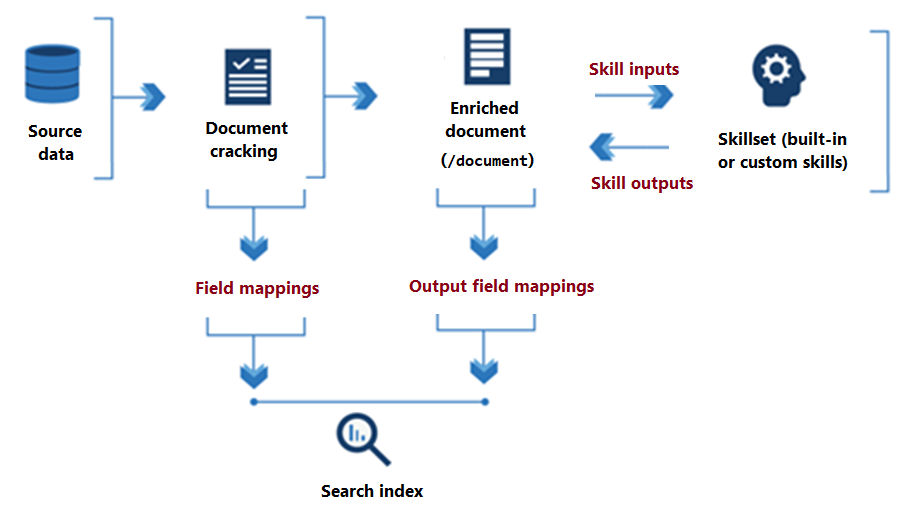
С начала обработки набора навыков до его вывода навыки считываются и записываются в обогащенный документ , который существует в памяти. Изначально обогащенный документ — это просто необработанное содержимое, извлеченное из источника данных (сформулированное как корневой "/document" узел). При каждом выполнении навыка обогащенный документ получает структуру и вещество, так как каждый навык записывает его выходные данные в виде узлов в графе.
После завершения выполнения набора навыков выходные данные обогащенного документа находят свой путь к индексу с помощью сопоставлений полей вывода, определяемых пользователем. Любое необработанное содержимое, которое требуется передать без изменений из источника в индекс, определяется с помощью сопоставлений полей.
Чтобы настроить примененный ИИ, укажите параметры в наборе навыков и индексаторе.
Определение набора навыков
Набор навыков — это массив одного или нескольких навыков , которые выполняют обогащение, например преобразование текста или оптического распознавания символов (OCR) в файле изображения. Навыки могут быть встроенными навыками от Корпорации Майкрософт или пользовательскими навыками для обработки логики, размещенной на внешних серверах. Набор навыков создает обогащенные документы, которые используются во время индексирования или проецируются в хранилище знаний.
Навыки имеют контекст, входные данные и выходные данные:
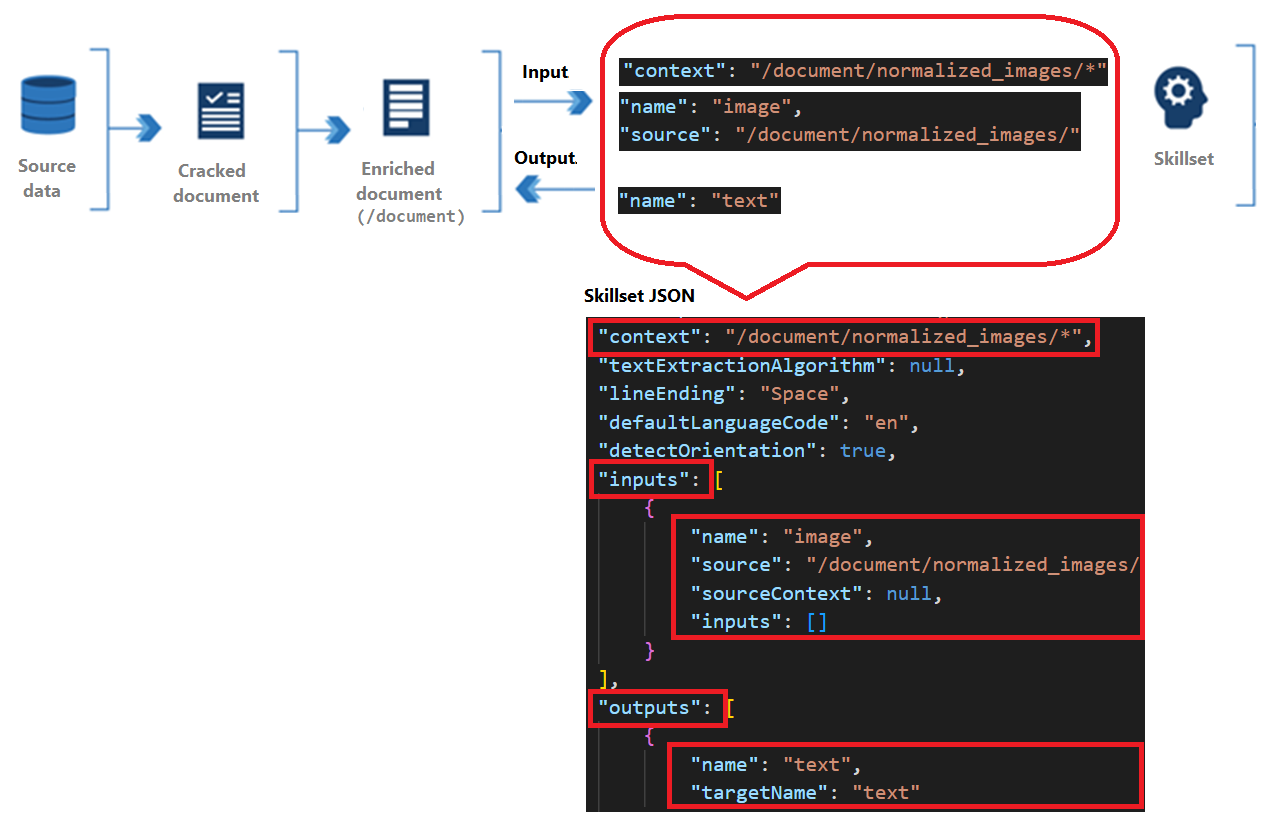
Контекст ссылается на область операции, которая может быть один раз в документе или один раз для каждого элемента в коллекции.
Входные данные возникают из узлов в обогащенном документе, где "источник" и "имя" определяют заданный узел.
Выходные данные отправляются обратно в обогащенный документ в качестве нового узла. Значения — это содержимое узла "имя" и содержимое узла. Если имя узла дублируется, можно задать целевое имя для диамбигуации.
Контекст навыка
У каждого навыка есть контекст, которым может быть весь документ (/document) или узел ниже в дереве (/document/countries/*).
Контекст определяет следующие характеристики.
Количество выполнения навыка по одному значению (один раз на поле, в документе) или для коллекции, при добавлении
/*результатов вызова навыка для каждого экземпляра в коллекции.Объявление выходных данных или место в дереве обогащения, куда добавляются выходные данные навыков. Выходные данные всегда добавляются в дерево как дочерние узлы для узла контекста.
Форма входных данных. Для многоуровневых коллекций настройка контекста родительской коллекции влияет на форму входных данных для навыка. Например, если у вас есть дерево обогащения со списком стран или регионов, каждый из которых обогащен списком состояний, содержащих список ZIP-кодов, то как задать контекст определяет, как интерпретируются входные данные.
Контекст Входные данные Форма входных данных Вызов навыка /document/countries/*/document/countries/*/states/*/zipcodes/*Список всех почтовых индексов в стране или регионе По одному разу для страны или региона /document/countries/*/states/*/document/countries/*/states/*/zipcodes/*Список почтовых индексов в штате, области или крае Один раз для каждого сочетания страны или региона и штата, области или края
Зависимости навыка
Навыки могут выполняться независимо и параллельно или последовательно, если вы передаете выходные данные одного навыка в другой навык. В следующем примере показаны два встроенных навыка, которые выполняются в последовательности :
Навык #1 — это навык разделения текста, который принимает содержимое исходного поля "reviews_text" в качестве входных данных и разбивает содержимое на "страницы" из 5000 символов в качестве выходных данных. Разделение большого текста на небольшие блоки может привести к улучшению результатов для навыков, таких как обнаружение тональности.
навык №2 — это навык обнаружения тональности, где в качестве входных данных применяются "страницы". С его помощью создается новое поле "Тональность", которое играет роль выходных данных и содержит результаты анализа тональности.
Обратите внимание, что выходные данные первого навыка ("страниц") используются в анализе тональности, где "/document/reviews_text/pages/*" — это контекст и входные данные. Дополнительные сведения о формулировке пути см. в разделе "Как ссылаться на обогащения".
{
"skills": [
{
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
},
{
"@odata.type": "#Microsoft.Skills.Text.SentimentSkill",
"name": "#2",
"description": null,
"context": "/document/reviews_text/pages/*",
"defaultLanguageCode": "en",
"inputs": [
{
"name": "text",
"source": "/document/reviews_text/pages/*",
}
],
"outputs": [
{
"name": "sentiment",
"targetName": "sentiment"
},
{
"name": "confidenceScores",
"targetName": "confidenceScores"
},
{
"name": "sentences",
"targetName": "sentences"
}
]
}
. . .
]
}
Дерево обогащения
Обогащенный документ — это временная древовидная структура данных, созданная во время выполнения набора навыков, которая собирает все изменения, представленные с помощью навыков. В совокупности обогащения представлены как иерархия адресных узлов. Узлы также включают все незавершенные поля, передаваемые в подробном формате из внешнего источника данных.
Обогащенный документ существует в течение длительного выполнения набора навыков, но может быть кэширован или отправлен в хранилище знаний.
Изначально обогащенный документ — это просто содержимое, извлеченное из источника данных во время взлома документа, когда текст и изображения извлекаются из источника и становятся доступными для анализа языка или изображений.
Начальное содержимое — метаданные и корневой узел (document/content). Корневой узел обычно является целым документом или нормализованным изображением, извлеченным из источника данных во время взлома документов. То, как он сформирован в дереве обогащения, различается для каждого типа источника данных. В следующей таблице показано состояние документа, поступающего в конвейер обогащения для нескольких поддерживаемых источников данных.
| Источник данных и режим анализа | По умолчанию. | JSON, строки JSON и CSV |
|---|---|---|
| Хранилище BLOB-объектов | /document/content /document/normalized_images/* … |
/document/{key1} /document/{key2} … |
| Azure SQL | /document/{column1} /document/{column2} … |
Н/П |
| Azure Cosmos DB | /document/{key1} /document/{key2} … |
Н/П |
По мере выполнения навыков выходные данные добавляются в дерево обогащения как новые узлы. Если выполнение навыка выполняется по всему документу, узлы добавляются на первом уровне под корнем.
Узлы можно использовать в качестве входных данных для подчиненных навыков. Например, навыки, которые создают содержимое, например переведенные строки, могут стать входными данными для навыков, которые распознают сущности или извлекают ключевые фразы.
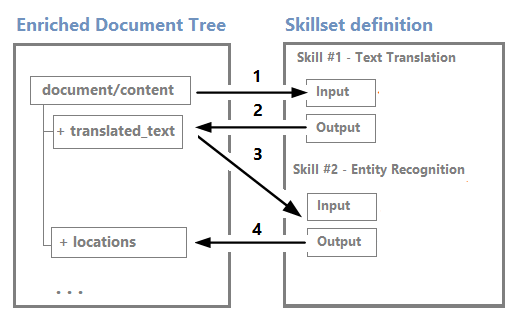
Хотя вы можете визуализировать и работать с деревом обогащения с помощью визуального редактора сеансов отладки, это в основном внутренняя структура.
Обогащения неизменяемы: после создания узлы не могут быть изменены. По мере усложнения набора навыков усложняется и дерево обогащения, но помещать все его узлы в индекс или хранилище знаний не обязательно.
Вы можете выборочно сохранить только подмножество выходных данных обогащения, чтобы сохранить только то, что вы планируете использовать. Сопоставления полей выходных данных в определении индексатора определяют, какое содержимое фактически получает прием в индексе поиска. Аналогичным образом, если вы создаете хранилище знаний, вы можете сопоставить выходные данные с фигурами , назначенными проекциям.
Примечание.
Формат дерева обогащения позволяет конвейеру обогащения присоединять метаданные даже к примитивным типам данных. Метаданные не будут допустимым объектом JSON, но могут быть проецированы в допустимый формат JSON в определениях проекций в хранилище знаний. Дополнительные сведения см. в статье Навык определения формы.
Определение индексатора
Индексатор имеет свойства и параметры, используемые для настройки выполнения индексатора. Среди этих свойств — сопоставления, которые задают путь к данным полям в индексе поиска.

Существует два набора сопоставлений:
FieldMappings сопоставляет исходное поле с полем поиска.
OutputFieldMappings сопоставляет узел в обогащенном документе с полем поиска.
Свойство sourceFieldName указывает поле в источнике данных или узле в дереве обогащения. Свойство targetFieldName указывает поле поиска в индексе, который получает содержимое.
Пример обогащения
На примере набора навыков отзывов об отелях здесь показано, как развивается дерево обогащения посредством выполнения навыков с использованием концептуальных диаграмм.
В примере также показано следующее.
- Как контекст и входные данные навыка влияют на то, сколько раз применяется навык?
- Какой будет форма входных данных, исходя из контекста?
В этом примере исходные поля из файла CSV включают отзывы клиентов об отелях ("reviews_text") и оценки ("reviews_rating"). Индексатор добавляет поля метаданных из хранилища BLOB-объектов, а навыки добавляют переведенный текст, оценки тональности и определение ключевых фраз.
В примере с отзывами об отелях "документ" в процессе обогащения представляет собой отдельный отзыв об отеле.
Совет
Вы можете создать индекс поиска и хранилище знаний для этих данных в портал Azure или REST API. Также можно использовать Сеансы отладки для понимания состава набора навыков, зависимостей и влияния на дерево обогащения. Изображения, приведенные в этой статье, взяты из сеансов отладки.
Концептуально исходное дерево обогащения выглядит следующим образом.

Корневой узел для всех результатов обогащения — "/document". При работе с индексаторами "/document" "/document/content" BLOB-объектов узел имеет дочерние узлы и "/document/normalized_images". Если данные — CSV, как в этом примере, имена столбцов сопоставляют с узлами ниже "/document".
Навык #1. Разделение навыка
Если исходное содержимое состоит из больших фрагментов текста, полезно бывает разбивать его на меньшие части, чтобы точнее определять язык, тональность и ключевые фразы. На выбор имеется два интервала: страницы и предложения. Страница состоит из примерно 5 000 символов.
Навык разделения текста, как правило, является первым в наборе навыков.
"@odata.type": "#Microsoft.Skills.Text.SplitSkill",
"name": "#1",
"description": null,
"context": "/document/reviews_text",
"defaultLanguageCode": "en",
"textSplitMode": "pages",
"maximumPageLength": 5000,
"inputs": [
{
"name": "text",
"source": "/document/reviews_text"
}
],
"outputs": [
{
"name": "textItems",
"targetName": "pages"
}
]
В контексте навыка "/document/reviews_text" этот навык применяется для reviews_text один раз. Выходные данные навыка — это список, в котором reviews_text фрагментируется до 5000 сегментов символов. Выходные данные из навыка разделения называются pages и добавляются в дерево обогащения. Признак targetName позволяет переименовать выходные данные навыка перед их добавлением в дерево обогащения.
Дерево обогащения теперь содержит новый узел, находящийся в контексте навыка. Этот узел доступен любому сопоставлению навыков, проекций или выходных полей.

Чтобы получить доступ к любому из результатов обогащения, добавленных в узел навыком, требуется полный путь для обогащения. Например, если вы хотите использовать текст из узла в pages качестве входных данных для другого навыка, укажите его как "/document/reviews_text/pages/*". Дополнительные сведения о путях см. в статье "Справочные обогащения".
Навык № 2. Определение языка
Документы с отзывами об отеле содержат отзывы клиентов на нескольких языках. Используемый язык определяется при помощи навыка определения языка. Затем результат будет передан для извлечения ключевых фраз и обнаружения тональности (как показано). Язык учитывается при выявлении тональности и фраз.
Хотя навык обнаружения языка является третьим (навык 3), определенным в наборе навыков, это следующий навык для выполнения. Он не требует входных данных, поэтому он выполняется параллельно с предыдущим навыком. Как и в случае с предыдущим навыком разделения, навык определения языка также вызывается один раз для каждого документа. Дерево обогащения теперь содержит новый узел для языка.

Навыки № 3 и № 4 (анализ тональности и определение ключевых фраз)
Отзывы клиентов отражают как положительный, так и отрицательный опыт. Навык анализа тональности анализирует обратную связь и присваивает баллы в диапазоне от отрицательных до положительных чисел или нейтральных, если тональность не определяется. Параллельно с анализом тональности обнаружение ключевых фраз идентифицирует и извлекает слова и короткие фразы, которые кажутся важными.
Учитывая контекст /document/reviews_text/pages/*, как анализ тональности, так и ключевые навыки фразы вызываются один раз для каждого элемента в pages коллекции. Результатом выполнения навыка будет узел под соответствующим элементом page.
Теперь вы должны иметь возможность посмотреть на остальные навыки в наборе навыков и визуализировать, как дерево обогащений продолжает расти с выполнением каждого навыка. Некоторые навыки, например навык слияния и навык определения формы, также создают новые узлы, но используют данные только из имеющихся узлов и не создают абсолютно новые результаты обогащения.

Цвета соединителей в дереве выше указывают на то, что обогащения были созданы различными навыками, а узлы должны быть рассмотрены по отдельности и не будут частью объекта, возвращаемого при выборе родительского узла.
Навык № 5. Навык определения формы
Если выходные данные содержат хранилище знаний, добавьте навык определения формы в качестве последнего шага. Навык определения формы создает формы данных за пределами узлов в дереве обогащения. Например, можно объединить несколько узлов в одну форму. Затем можно спроецировать эту форму как таблицу (узлы становятся столбцами в таблице), передав форму по имени в проекцию таблицы.
С навыком определения формы легко работать, поскольку он фокусируется на формировании одного навыка. В качестве альтернативы можно выбрать линейное формообразование в пределах отдельных проекций. Навык фигурного элемента не добавляет или отклоняет дерево обогащения, поэтому он не визуализирован. Вместо этого вы можете подумать о навыке фигуратора как о том, с помощью которого вы перезадаете дерево обогащения, которое у вас уже есть. Концептуально это похоже на создание представлений из таблиц в базе данных.
{
"@odata.type": "#Microsoft.Skills.Util.ShaperSkill",
"name": "#5",
"description": null,
"context": "/document",
"inputs": [
{
"name": "name",
"source": "/document/name"
},
{
"name": "reviews_date",
"source": "/document/reviews_date"
},
{
"name": "reviews_rating",
"source": "/document/reviews_rating"
},
{
"name": "reviews_text",
"source": "/document/reviews_text"
},
{
"name": "reviews_title",
"source": "/document/reviews_title"
},
{
"name": "AzureSearch_DocumentKey",
"source": "/document/AzureSearch_DocumentKey"
},
{
"name": "pages",
"sourceContext": "/document/reviews_text/pages/*",
"inputs": [
{
"name": "Sentiment",
"source": "/document/reviews_text/pages/*/Sentiment"
},
{
"name": "LanguageCode",
"source": "/document/Language"
},
{
"name": "Page",
"source": "/document/reviews_text/pages/*"
},
{
"name": "keyphrase",
"sourceContext": "/document/reviews_text/pages/*/Keyphrases/*",
"inputs": [
{
"name": "Keyphrases",
"source": "/document/reviews_text/pages/*/Keyphrases/*"
}
]
}
]
}
],
"outputs": [
{
"name": "output",
"targetName": "tableprojection"
}
]
}
Следующие шаги
Изучив введение и пример, попробуйте создать свой первый набор навыков, используя встроенные навыки.